

「コード生成」タスクを完了してください。 Fudan ら、StepCoder フレームワークをリリース: コンパイラのフィードバック信号からの強化学習

大規模言語モデル (LLM) の進歩は、コード生成の分野を大きく推進してきました。以前の研究では、強化学習 (RL) とコンパイラのフィードバック信号を組み合わせて LLM の出力空間を調査し、コード生成の品質を最適化しました。
#しかし、まだ 2 つの問題があります:
#1. 強化学習の探索は、「人間の複雑なニーズ」に直接適応するのが困難です。つまり、LLM は「長いシーケンス コード」を生成する必要があります;
2. 単体テストは複雑なコードをカバーしていない可能性があるため、未実行のコード スニペットを使用して LLM を最適化することは効果的ではありません。
これらの課題に対処するために、研究者らは、復旦大学、華中科学技術大学、王立工科大学の専門家が共同開発した StepCoder と呼ばれる新しい強化学習フレームワークを提案しました。 。 StepCoder には、コード生成の効率と品質を向上させるために設計された 2 つの主要なコンポーネントが含まれています。
#1. CCCS長いシーケンスのコード生成タスクをコード補完のサブタスク コースに分割することで、探索の課題に対処します。
2. FGO未実行のコード セグメントをマスクしてモデルを最適化し、きめ細かい最適化を実現します。

論文リンク: https://arxiv.org/pdf/2402.01391.pdf
プロジェクトリンク: https://github.com/Ablustrund/APPS_Plus
研究者らはまた、強化学習トレーニング用の APPS データセットを構築し、単体テストの正確性を確認するために手動で検証しました。
実験結果は、この方法が出力空間を探索する能力を向上させ、対応するベンチマークで最先端の方法よりも優れたパフォーマンスを発揮することを示しています。
StepCoderコード生成プロセスにおいて、通常の強化学習の探索(探索)では「報酬が希薄で遅れた環境」や「長いシーケンス」に対応することが困難です。複雑なニーズ」。
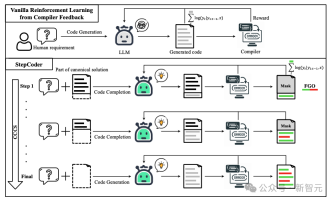
CCCS (コード補完サブタスクのカリキュラム) ステージでは、研究者は複雑な探索問題を一連のサブタスクに分解します。正規解の一部をプロンプトとして使用して、LLM は単純なシーケンスから探索を開始できます。
報酬の計算は実行可能なコードの断片のみに関連するため、コード全体 (図の赤い部分) を使用して LLM (図の灰色の部分) を最適化するのは不正確です。 。
FGO (Fine-Grained Optimization) ステージでは、研究者は単体テストで未実行のトークン (赤色の部分) をマスクし、実行されたトークン (緑色の部分) のみを使用します。損失関数を計算します。 、きめ細かい最適化を提供できます。
予備知識
 がコード生成に使用されるトレーニング データ セットであると仮定します。ここで、x、y、および u は人間のニーズ (つまり、タスクの説明)、標準ソリューション、および単体テストを表します。それぞれサンプル。
がコード生成に使用されるトレーニング データ セットであると仮定します。ここで、x、y、および u は人間のニーズ (つまり、タスクの説明)、標準ソリューション、および単体テストを表します。それぞれサンプル。
 は、標準解 yi の抽象構文ツリーを自動的に解析して得られる条件文のリストです。st と en はそれぞれ文の開始位置と終了位置を表します。 。
は、標準解 yi の抽象構文ツリーを自動的に解析して得られる条件文のリストです。st と en はそれぞれ文の開始位置と終了位置を表します。 。
人間のニーズ x について、その標準解 y は  として表現できます。コード生成段階では、人間のニーズ x が与えられた場合、最終状態は次のようになります。ユニットを通して、あなたをテストするコードのコレクション。
として表現できます。コード生成段階では、人間のニーズ x が与えられた場合、最終状態は次のようになります。ユニットを通して、あなたをテストするコードのコレクション。
メソッドの詳細
StepCoder は、CCCS と FGO という 2 つの主要コンポーネントを統合します。CCCS の目的はコースです。コード生成タスクがコード補完サブタスクに分解されることで、RL での探索の課題が軽減されます。FGO はコード生成タスク専用に設計されており、実行されたコード フラグメントの損失のみを計算することできめ細かい最適化を提供します。
CCCS
コード生成プロセスでは、人間の複雑なニーズを解決するために、ポリシー モデルは通常、相対的に複雑な長いアクションシーケンス。同時に、コンパイラーのフィードバックは遅延し、まばらになります。つまり、ポリシー モデルは、コード全体が生成された後でのみ報酬を受け取ります。この場合、探索は非常に困難です。
このメソッドの核心は、このような長い探索問題のリストを、探索しやすい一連の短いサブタスクに分解することです。研究者らは、コード生成をコード補完サブタスクに縮小しました。ここで、サブタスクはトレーニング データセット内の典型的なソリューションから自動的に構築されます。
人間のニーズ x について、CCCS の初期トレーニング段階では、探索の開始点 s* は最終状態に近い状態です。
具体的には、研究者は人間のニーズ x と標準ソリューションの前半部分  を提供し、xp を予測するためのポリシー モデルをトレーニングします)。コード。
を提供し、xp を予測するためのポリシー モデルをトレーニングします)。コード。
y^ が xp と出力軌跡 τ の結合シーケンス、つまり y^=(xp,τ) であると仮定すると、報酬モデルは、入力として y^ を持つコード フラグメント τ 報酬 r。

研究者らは、近接政策最適化 (PPO) アルゴリズムを使用して、報酬 r と軌道 τ を利用して政策モデル πθ を最適化しました。
最適化フェーズ中、ヒントの提供に使用される正規解コード セグメント xp は、ポリシー モデル πθ 更新の勾配に影響を与えないようにマスクされます。
CCCS は、反対関数を最大化することによってポリシー モデル πθ を最適化します。ここで、π^ref は PPO の参照モデルであり、SFT モデルによって初期化されます。

学習が進むにつれて、探索の開始点 s* は標準解の開始点に向かって徐々に移動していきます。具体的には、学習サンプルごとに閾値 ρ が設定されます。 πθによって生成されたコードセグメントの累積正解率がρより大きい場合、開始点は先頭に移動します。
トレーニングの後半段階では、このメソッドの探索プロセスは元の強化学習の探索プロセス、つまり s*=0 と同等であり、ポリシー モデルは次のコードのみを生成します。人間のニーズをインプットとして。
条件文の開始位置で最初の認識点 s* をサンプリングして、残りの未記述のコード セグメントを完成させます。
具体的には、条件ステートメントが増えるほど、プログラムの独立したパスが増え、ロジックの複雑さが増します。複雑になると、トレーニングの品質を向上させるためにより頻繁なサンプリングが必要になり、プログラムの数が少なくなります。条件ステートメントは、それほど頻繁にサンプリングする必要はありません。
このサンプリング方法では、トレーニング データ セット内の複雑な意味構造と単純な意味構造の両方を考慮しながら、代表的なコード構造を均等に抽出できます。
トレーニング フェーズを高速化するために、研究者らは i 番目のサンプルのコース数を  に設定しました。ここで、Ei はそのコースの数です。条件文。 i 番目のサンプルのトレーニング コース スパンは、1 ではなく
に設定しました。ここで、Ei はそのコースの数です。条件文。 i 番目のサンプルのトレーニング コース スパンは、1 ではなく  です。
です。
CCCS の要点をまとめると次のようになります:
1. 目標に近い状態から検討を開始しやすい(つまり、最終状態);
2. 目標からさらに離れた状態から探索するのは困難ですが、既に学習した状態を利用できれば探索は容易になります。ゴールに到達する。
FGO
コード生成における報酬とアクションの関係は、他の強化学習タスク (たとえば、 Atari ) では、コード生成において、生成されたコード内の報酬の計算に関係のない一連のアクションを除外することができます。
具体的には、単体テストの場合、コンパイラのフィードバックは実行されたコード フラグメントにのみ関連しますが、通常の RL 最適化目標では、軌道上のすべてのアクションが勾配計算に関与します。 . 、勾配の計算が不正確です。
最適化の精度を向上させるために、研究者たちは単体テストで実行されなかったアクション (つまり、トークン) と戦略モデルの損失を保護しました。

APPS データセット
強化学習には大量の高品質のトレーニング データが必要ですが、研究者らは調査中に、現在利用可能なオープンソース データセットの中で、この要件を満たしているのは APPS だけであることを発見しました。
しかし、APPS には、入力、出力、または標準ソリューションの欠落など、標準ソリューションがコンパイルまたは実行されない場合や、実行出力に違いがある場合など、正しくないインスタンスがいくつかあります。
APPS データセットを完成させるために、研究者たちは、入力、出力、または標準ソリューションが欠落しているインスタンスをフィルターで除外し、単体テストの実行を容易にするために入力と出力の形式を標準化しました。その後、各インスタンスの単体テストと手動分析が行われ、不完全または無関係なコード、構文エラー、API の誤用、またはライブラリの依存関係が欠落しているインスタンスが排除されました。
出力の違いについては、研究者が手動で問題の説明を確認し、予想される出力を修正するか、インスタンスを削除します。
最後に、7456 個のインスタンスを含む APPS データ セットが構築されました。各インスタンスには、プログラミングの問題の説明、標準ソリューション、関数名、単体テスト (つまり、入力と出力)、およびスタートアップ コード (つまり、標準溶液の始まりです)。

コード生成における他の LLM と StepCoder のパフォーマンスを評価するために、研究者は実験を行いました。 APPS データセット上で実施されました。
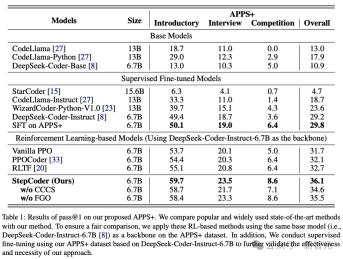
結果は、RL ベースのモデルが、基本モデルや SFT モデルを含む他の言語モデルよりも優れていることを示しています。
#研究者らは、強化学習がコンパイラーのフィードバックに基づいてモデルの出力空間をより効率的に参照することで、パフォーマンスをさらに向上させることができると推測する理由を持っています。コード生成の品質。
さらに、StepCoder は、他の RL ベースの手法を含むすべてのベースライン モデルを上回り、最高スコアを達成しました。
具体的には、この方法は 59.7%、高スコアは 23.5%、8.6% を達成しました。
他の強化学習ベースの手法と比較して、この手法は複雑なコード生成タスクをコード補完サブタスクに単純化することで出力空間の探索に優れており、FGO プロセスは Played a戦略モデルを正確に最適化する上で重要な役割を果たします。
また、同じアーキテクチャ ネットワークに基づく APPS データ セットでは、バックボーン ネットワークと比較して、微調整に関して StepCoder のパフォーマンスが教師あり LLM よりも優れていることもわかります。後者では、生成されたコードの合格率がほとんど向上しません。これは、コンパイラのフィードバックを使用してモデルを最適化することで、コード生成における次のトークンの予測よりも生成されるコードの品質を向上できることを直接示しています。
以上が「コード生成」タスクを完了してください。 Fudan ら、StepCoder フレームワークをリリース: コンパイラのフィードバック信号からの強化学習の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 ほとんどが使用されています10 Power BIチャート - 分析VidhyaApr 16, 2025 pm 12:05 PM
ほとんどが使用されています10 Power BIチャート - 分析VidhyaApr 16, 2025 pm 12:05 PMMicrosoft PowerBIチャートでデータ視覚化の力を活用する 今日のデータ駆動型の世界では、複雑な情報を非技術的な視聴者に効果的に伝えることが重要です。 データの視覚化は、このギャップを橋渡しし、生データを変換するi
 AIのエキスパートシステムApr 16, 2025 pm 12:00 PM
AIのエキスパートシステムApr 16, 2025 pm 12:00 PMエキスパートシステム:AIの意思決定力に深く飛び込みます 医療診断から財務計画まで、あらゆることに関する専門家のアドバイスにアクセスできることを想像してください。 それが人工知能の専門家システムの力です。 これらのシステムはプロを模倣します
 3人の最高の雰囲気コーダーがこのAI革命をコードで分解するApr 16, 2025 am 11:58 AM
3人の最高の雰囲気コーダーがこのAI革命をコードで分解するApr 16, 2025 am 11:58 AMまず第一に、これがすぐに起こっていることは明らかです。さまざまな企業が、現在AIによって書かれているコードの割合について話しており、これらは迅速なクリップで増加しています。すでに多くの仕事の移動があります
 滑走路AIのGen-4:AIモンタージュはどのように不条理を超えることができますかApr 16, 2025 am 11:45 AM
滑走路AIのGen-4:AIモンタージュはどのように不条理を超えることができますかApr 16, 2025 am 11:45 AM映画業界は、デジタルマーケティングからソーシャルメディアまで、すべてのクリエイティブセクターとともに、技術的な岐路に立っています。人工知能が視覚的なストーリーテリングのあらゆる側面を再構築し始め、エンターテイメントの風景を変え始めたとき
 5日間のISRO AI無料コースを登録する方法は? - 分析VidhyaApr 16, 2025 am 11:43 AM
5日間のISRO AI無料コースを登録する方法は? - 分析VidhyaApr 16, 2025 am 11:43 AMISROの無料AI/MLオンラインコース:地理空間技術の革新へのゲートウェイ インド宇宙研究機関(ISRO)は、インドのリモートセンシング研究所(IIRS)を通じて、学生と専門家に素晴らしい機会を提供しています。
 AIのローカル検索アルゴリズムApr 16, 2025 am 11:40 AM
AIのローカル検索アルゴリズムApr 16, 2025 am 11:40 AMローカル検索アルゴリズム:包括的なガイド 大規模なイベントを計画するには、効率的なワークロード分布が必要です。 従来のアプローチが失敗すると、ローカル検索アルゴリズムは強力なソリューションを提供します。 この記事では、Hill ClimbingとSimulについて説明します
 OpenaiはGPT-4.1でフォーカスをシフトし、コーディングとコスト効率を優先しますApr 16, 2025 am 11:37 AM
OpenaiはGPT-4.1でフォーカスをシフトし、コーディングとコスト効率を優先しますApr 16, 2025 am 11:37 AMこのリリースには、GPT-4.1、GPT-4.1 MINI、およびGPT-4.1 NANOの3つの異なるモデルが含まれており、大規模な言語モデルのランドスケープ内のタスク固有の最適化への動きを示しています。これらのモデルは、ようなユーザー向けインターフェイスをすぐに置き換えません
 プロンプト:ChatGptは偽のパスポートを生成しますApr 16, 2025 am 11:35 AM
プロンプト:ChatGptは偽のパスポートを生成しますApr 16, 2025 am 11:35 AMChip Giant Nvidiaは、月曜日に、AI Supercomputersの製造を開始すると述べました。これは、大量のデータを処理して複雑なアルゴリズムを実行できるマシンを初めて初めて米国内で実行します。発表は、トランプSI大統領の後に行われます


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

