
ホームページ >テクノロジー周辺機器 >AI >OpenAI は、オープンソースの Transformer Debugger を正式に発表しました。コードを書く必要がなく、誰でも LLM ブラック ボックスを解読できます
OpenAI は、オープンソースの Transformer Debugger を正式に発表しました。コードを書く必要がなく、誰でも LLM ブラック ボックスを解読できます

- PHPz転載
- 2024-03-12 15:16:191247ブラウズ
AGI が本当に近づいています!
人間が AI によって殺されないようにするために、OpenAI はニューラル ネットワーク/トランスフォーマー ブラック ボックスの解読を決してやめませんでした。
昨年 5 月、OpenAI チームは衝撃的な発見を発表しました。GPT-4 は実際に GPT-2 の 300,000 個のニューロンを説明できるのです。
ネチズンは、知恵はこのようなものであることが判明したと叫びました。
 写真
写真
そしてたった今、OpenAI Super Alignment チームの責任者が、以下のソフトウェアをオープンソース化すると正式に発表しました。内部的に使用されている大きなキラー - Transformer Debugger (Transformer Debugger)。
つまり、研究者は TDB ツールを使用して Transformer の内部構造を分析し、小さなモデルの特定の動作を調査できます。
 写真
写真
つまり、この TDB ツールを使用すると、将来の AGI の分析と分析に役立ちます。
 画像
画像
Transformer デバッガーは、スパース オートエンコーダーと OpenAI によって開発された「自動解釈機能」を組み合わせます。つまり、小さなモデルを自動的に解釈します。テクノロジーを組み合わせた大型モデル。
リンク: OpenAI が新たな成果を爆発させる: GPT-4 が GPT-2 の脳をクラック! 300,000 個のニューロンはすべて、
 写真
写真
論文のアドレス: https://openaipublic.blob.core.windows を通して確認されています。 net/neuron-explainer/paper/index.html#sec-intro
研究者がコードを書かずに LLM の内部構造をすばやく調査できることは言及する価値があります。
たとえば、「なぜモデルはトークン B ではなくトークン A を出力するのか」や「なぜ注意ヘッド H はトークン T に注目するのか」などの質問に答えることができます。
 写真
写真
TDB はニューロンとアテンションヘッドをサポートできるため、研究者は単一のニューロンを切除してフォワードパスに介入することができます。そして、起こる具体的な変化を観察します。
しかし、Jan Leike 氏によると、このツールはまだ初期バージョンであり、OpenAI はより多くの研究者がこのツールを使用し、既存の基盤をさらに構築できることを期待してこのツールをリリースしました。
 写真
写真
プロジェクトアドレス: https://github.com/openai/transformer-debugger
動作原理
この Transformer Debugger の動作原理を理解するには、2023 年 5 月に OpenAI によってリリースされたアライメントに関する研究を確認する必要があります。

TDB ツールは、以前に発表された 2 つの研究に基づいており、論文は公開されません
シンプルOpenAIは、より大きなパラメータとより強力な機能を備えたモデル(GPT-4)を使用して、小型モデル(GPT-2)の動作を自動的に分析し、その動作メカニズムを説明したいと考えていると述べた。
 写真
写真
当時の OpenAI 研究の予備的な結果は、パラメータが比較的少ないモデルが理解しやすいというものでしたが、モデルパラメータが増加すると、モデルが大きくなり、レイヤー数が増えると、説明の効果は急激に低下します。
 写真
写真
OpenAI は当時の研究で、GPT-4 自体は小規模モデルの動作を説明するように設計されていないと述べたため、GPT 全体としては-2 の解釈結果はまだ不十分です。
 写真
写真
モデルの動作をより適切に説明できるアルゴリズムとツールは、将来的に開発される必要があります。
現在オープンソースになっている Transformer Debugger は、翌年の OpenAI の段階的な成果です。
そして、この「より良いツール」である Transformer Debugger は、「スパース オートエンコーダー」を「大きなモデルを使用して小さなモデルを説明する」という技術ラインに組み合わせています。
その後、GPT-4 を使用して解釈可能性研究の小さなモデルを説明する以前の OpenAI プロセスはゼロコード化されていたため、研究者が開始する敷居が大幅に下がりました。
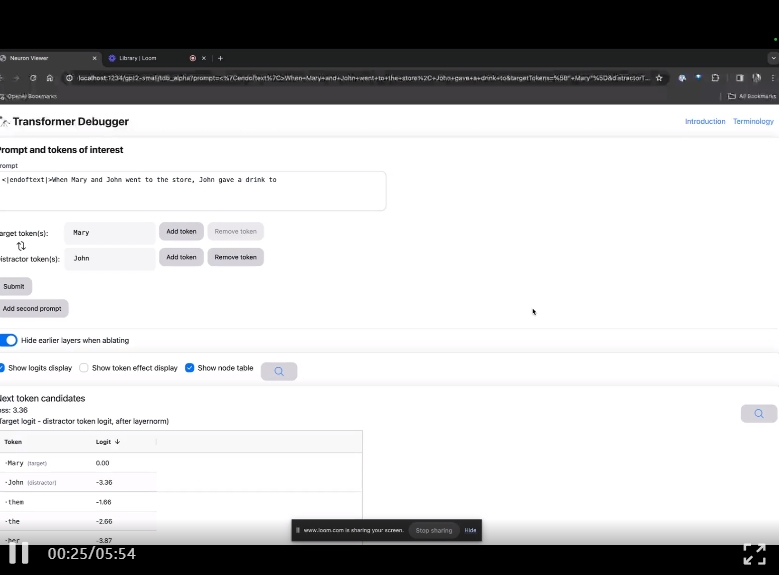
GPT-2 Small を確認しました
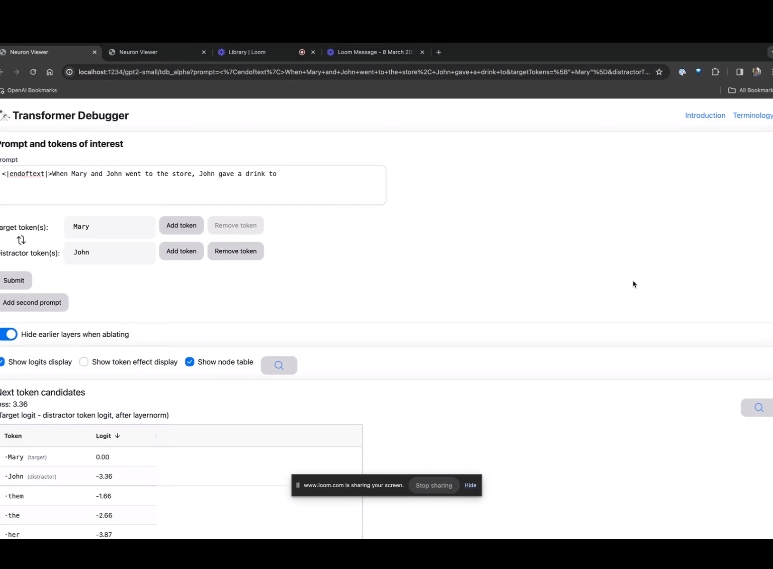
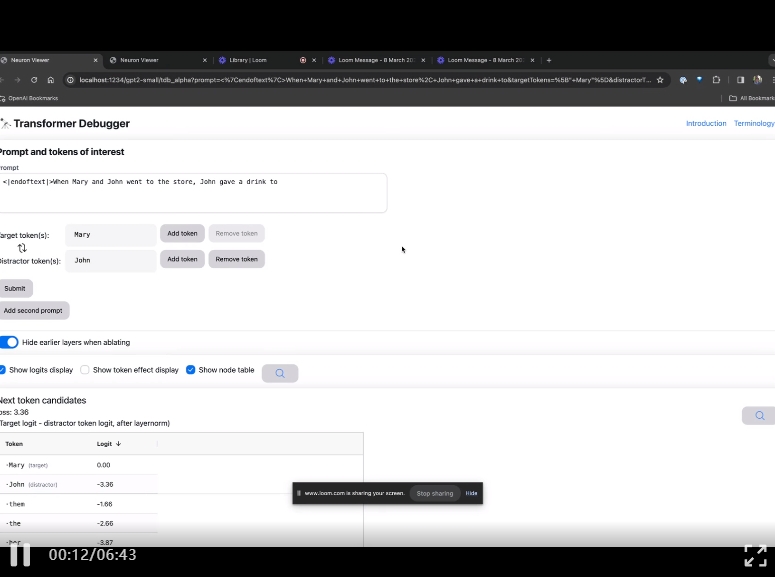
GitHub プロジェクトのホームページで、OpenAI のメンバーがチームは、最新の Transformer デバッガ ツールを紹介するビデオを渡しました。
Python デバッガーと同様に、TDB を使用すると、言語モデルの出力をステップ実行し、重要なアクティベーションを追跡し、上流のアクティベーションを分析できます。
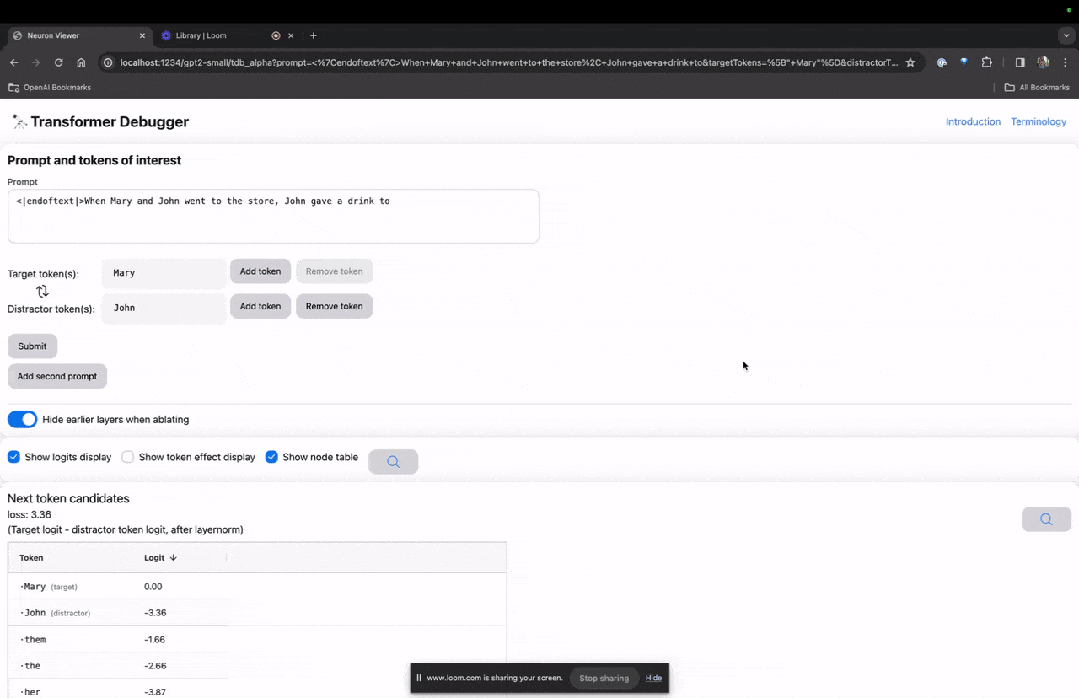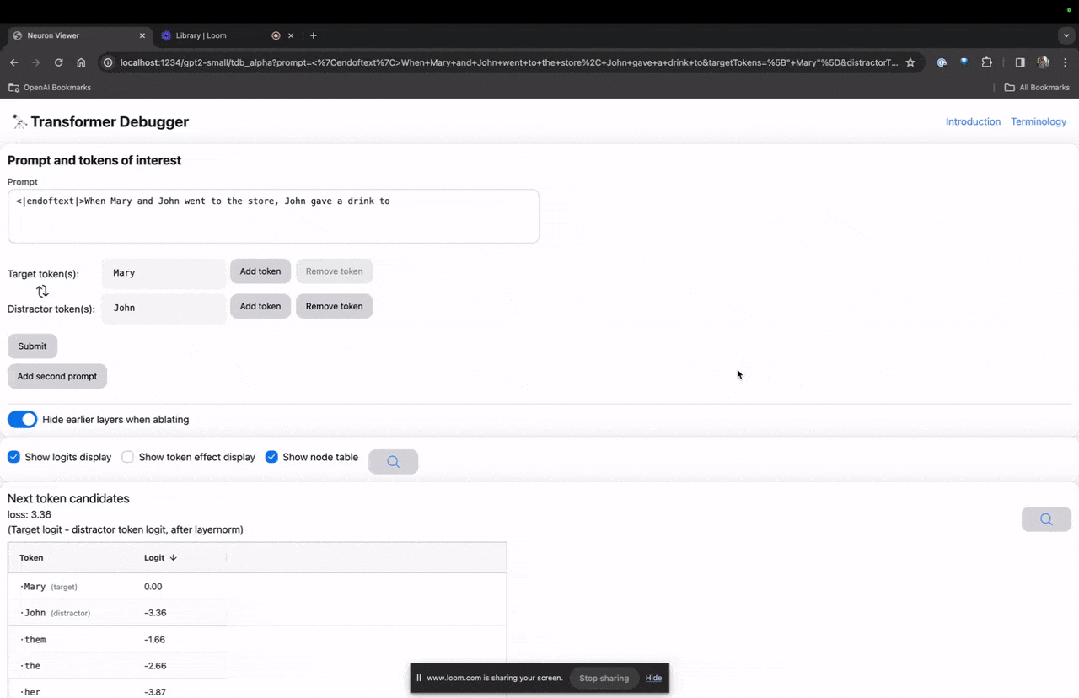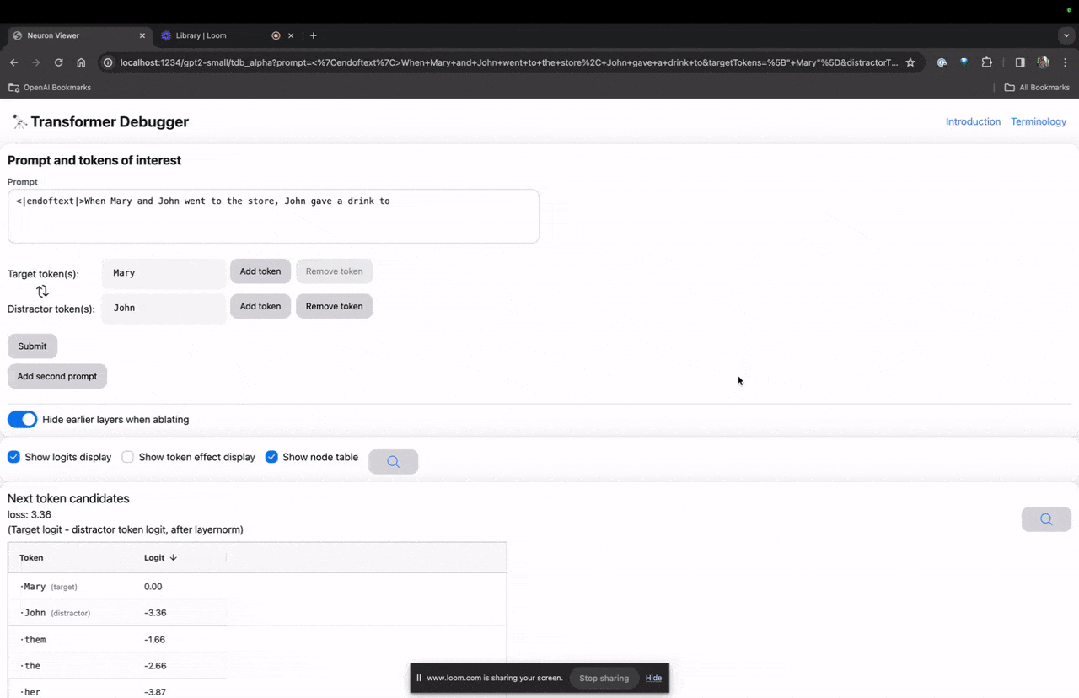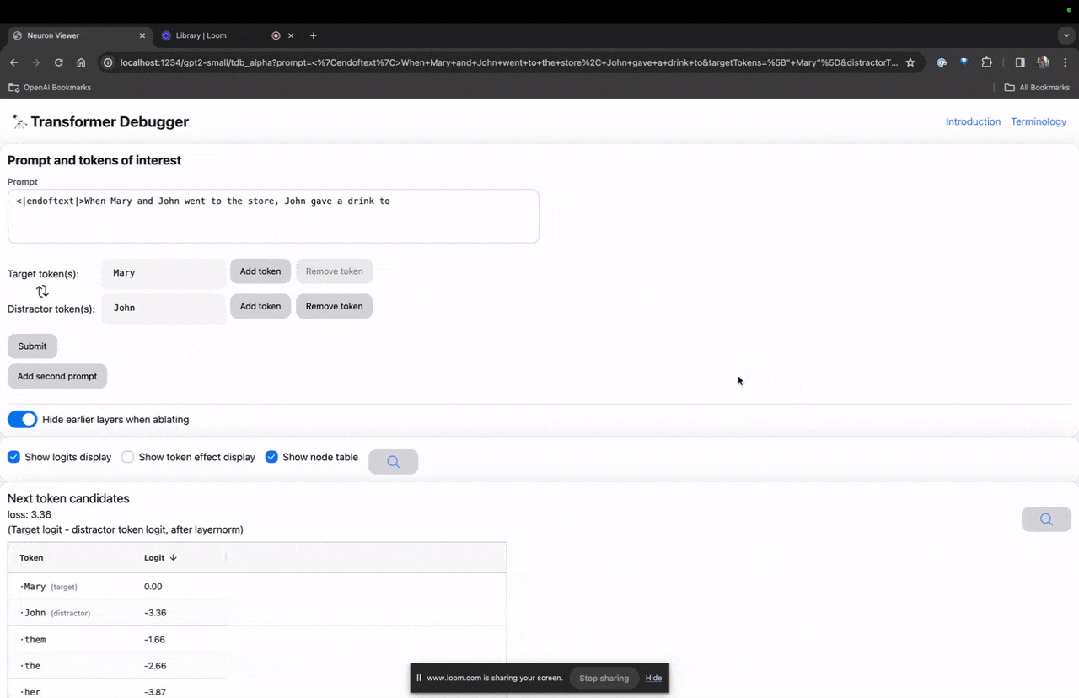
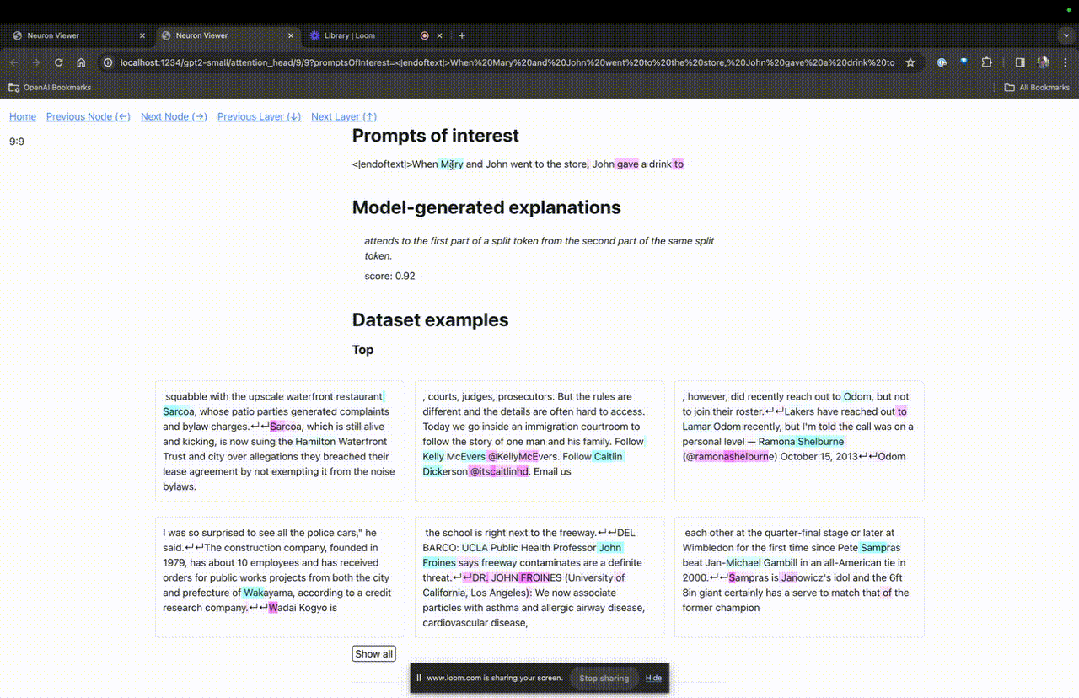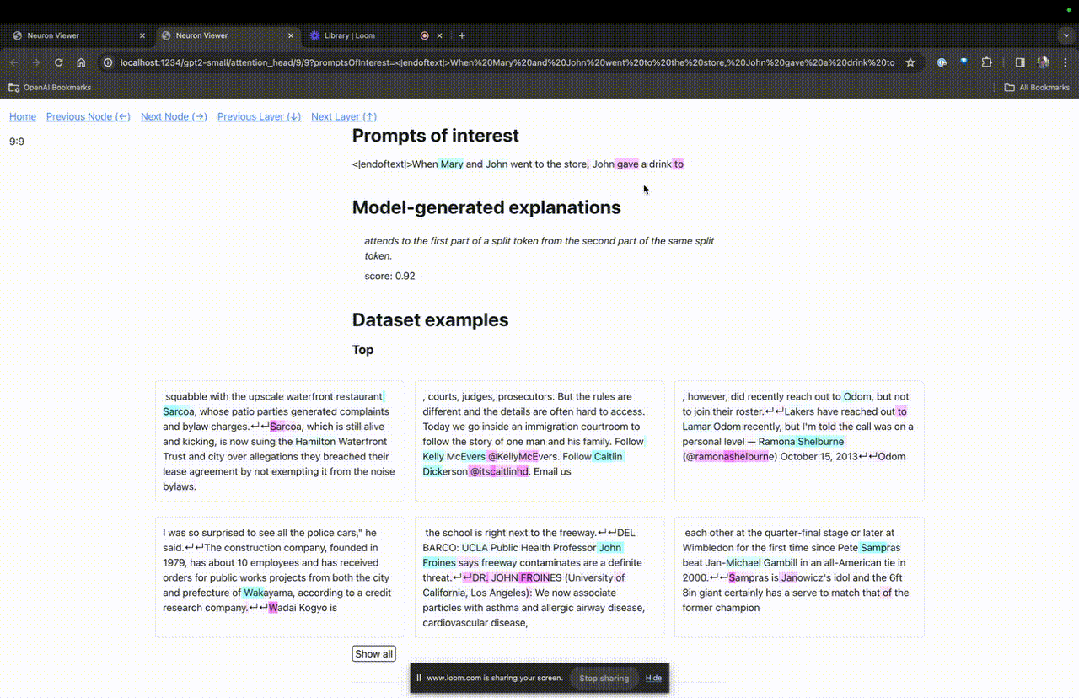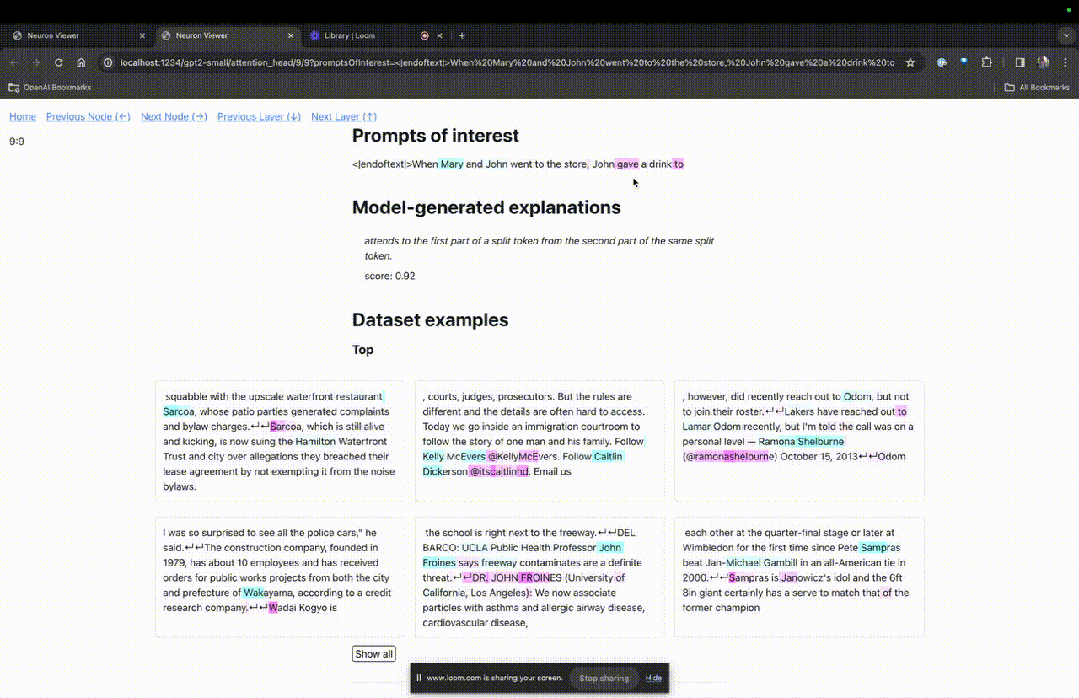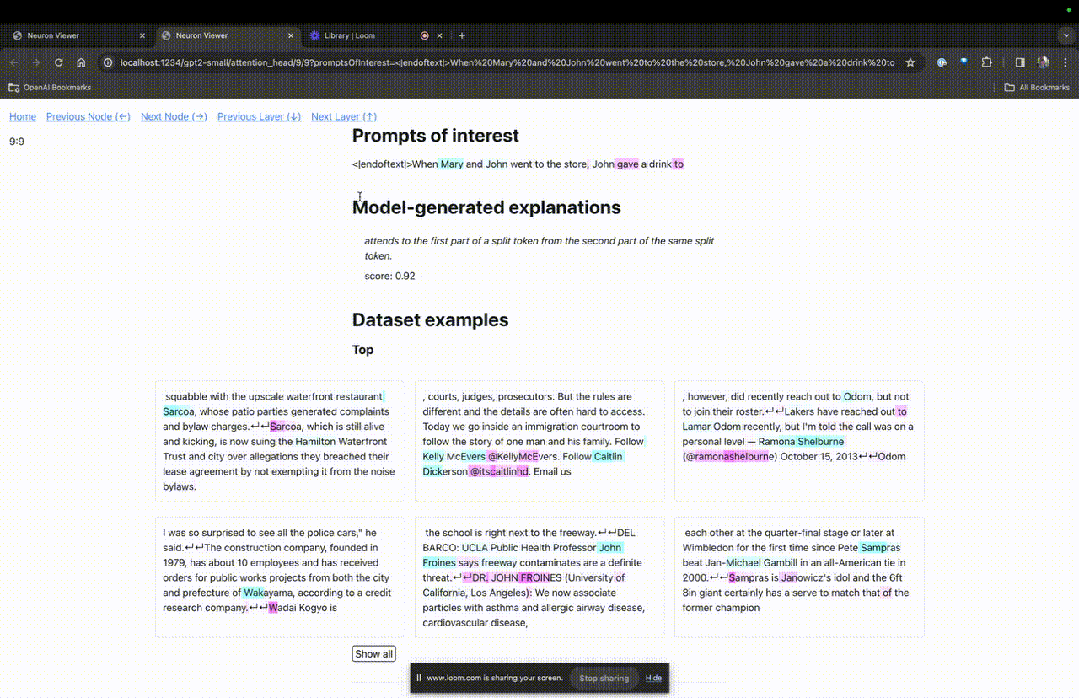
TDB ホームページに入り、最初に「プロンプト」列に入力します - プロンプトと対象のトークン:
Mary と Johon店に行き、ジョホンは飲み物を与えました....
次のステップは、「次の単語」を予測することです。これには、ターゲット トークンを入力する必要があります。そして破壊的なトークン。
最終送信後、システムによって予測された次の単語候補の対数が表示されます。
以下の「ノード テーブル」は TDB の中核部分です。ここでの各行は、モデル コンポーネントをアクティブ化するノードに対応します。
 画像
画像
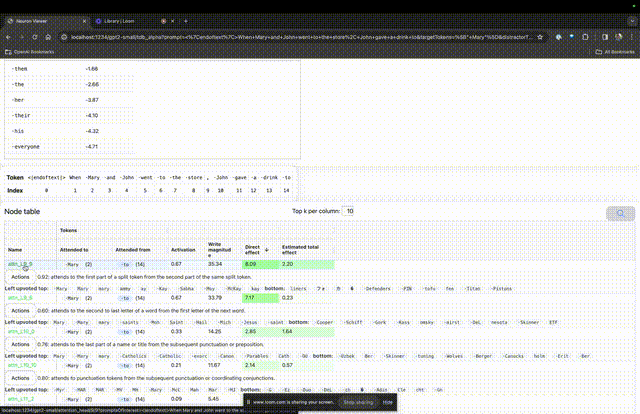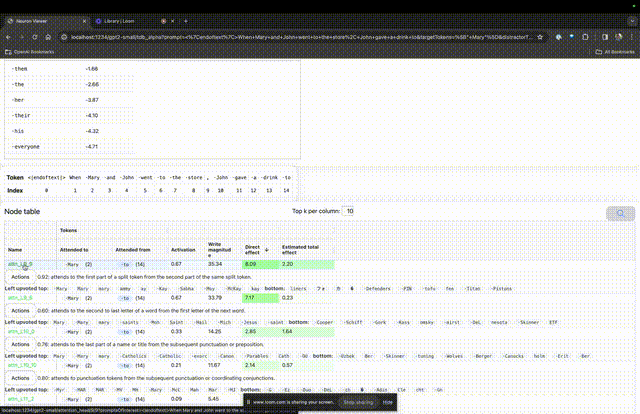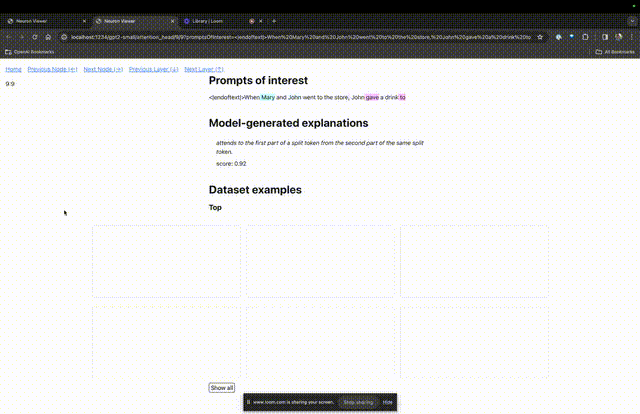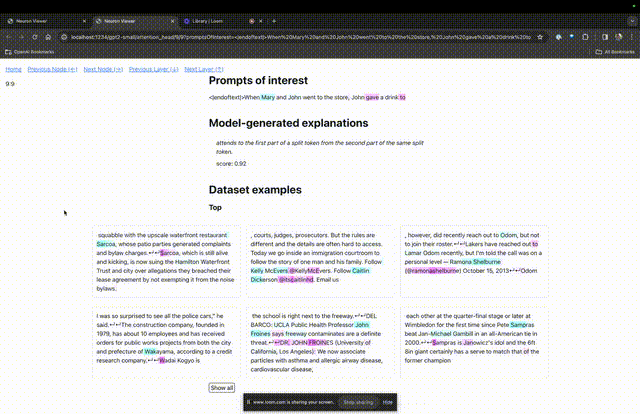
特定のプロンプトで非常に重要なアテンション ヘッドの機能を理解したい場合は、直接クリックしてくださいコンポーネント名に。
TDB は「Neuron Browser」ページを開き、前のプロンプトの単語が上部に表示されます。
 写真
写真
水色とピンクのトークンがここに表示されます。対応する色の各トークンの下で、後続のタグからこのトークンへのアテンションにより、大きなノルム ベクトルが後続のトークンに書き込まれます。
 写真
写真
他の 2 つのビデオで、研究者は TDB の概念とループ アプリケーションを理解する上でのその役割を紹介しています。同時に、同氏は、TDB が論文の結果の 1 つをどのように定性的に再現できるかについても実証しました。
OpenAI 自動解釈可能性研究
つまり、OpenAI は自動的に説明可能です。この研究は、GPT-4 にニューロンの動作を自然言語で解釈させ、このプロセスを GPT-2 に適用することです。
どうしてそんなことが可能なのでしょうか?まず、LLM を「分析」する必要があります。
脳と同様に、それらはテキスト内の特定のパターンを観察する「ニューロン」で構成されており、モデル全体が次に何を言うかを決定します。
たとえば、「どのマーベル スーパーヒーローが最も有用なスーパーパワーを持っていますか?」というようなプロンプトが表示された場合、「マーベル スーパーヒーロー ニューロン」という名前のコミックのモデルが増加する可能性があります。マーベル映画に登場するスーパーヒーロー。
OpenAI のツールは、この設定を使用してモデルを個別の部分に分解します。
ステップ 1: GPT-4 を使用して説明を生成する
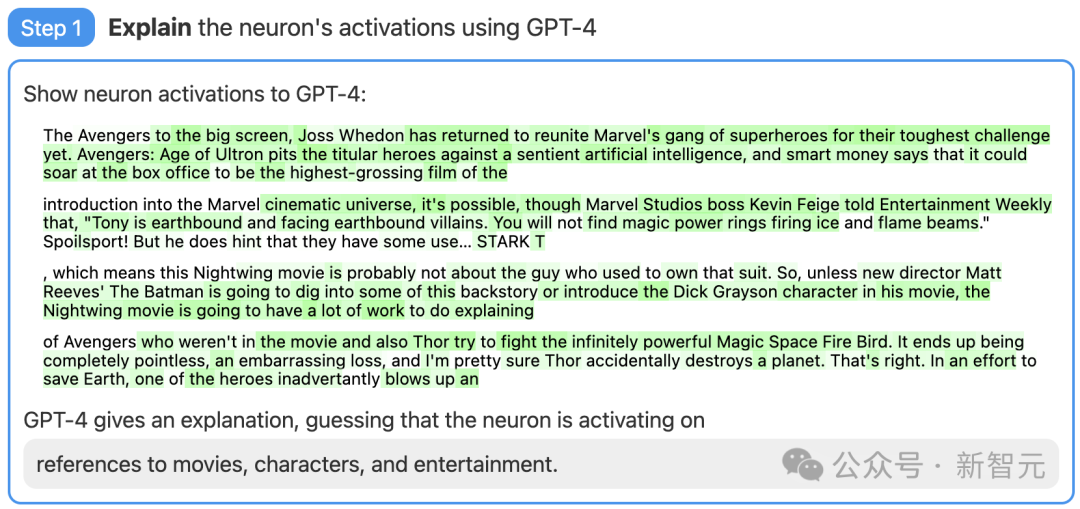
まず、GPT-2 ニューロンを見つけます。関連するテキスト シーケンスと GPT-4 のアクティベーションを示します。
次に、GPT-4 がこれらの動作に基づいて考えられる説明を生成します。
たとえば、以下の例では、GPT-4 は、このニューロンが映画、キャラクター、エンターテイメントに関連していると信じています。
 #図
#図
ステップ 2: シミュレーションに GPT-4 を使用する
次に、GPT-4 が生成した説明に基づいて、このように活性化されたニューロンが何を行うかをシミュレーションさせます。
#図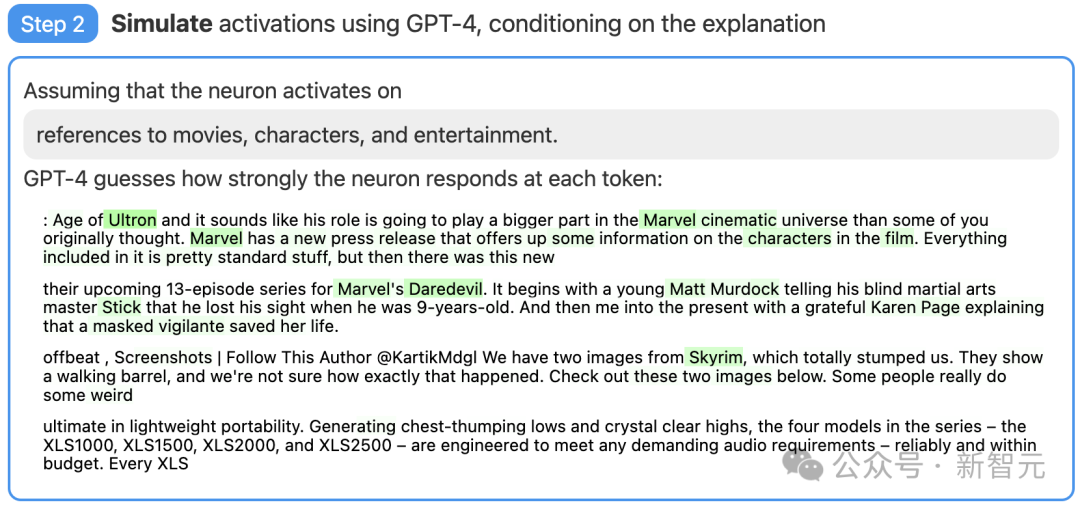
ステップ 3: 比較とスコアリング
##最後に、シミュレートされたニューロンの動作 (GPT-4) と実際のニューロンの動作 (GPT-2) を比較して、GPT-4 の推測がどの程度正確であるかを確認します。
写真
評価を通じて、OpenAI 研究者たちは、この手法がニューラル ネットワークのさまざまな部分でどのように機能するかを測定しました。おそらく、後の層は説明が難しいため、この手法は大きなモデルではうまく説明できません。
写真
現在、OpenAI は、「GPT-4 を使用して GPT-2 の 307,200 個のニューロンすべてを説明する」結果のデータセットと視覚化ツールをオープンソース化しており、これらを以下でも利用できるようにしています。 OpenAI API を介して市場に提供するコードは、既存のモデルの説明とスコアリングをコード化しており、よりスコアの高い説明を生成するより良い技術を開発するよう学術コミュニティに呼びかけています。
さらに、チームは、モデルが大きくなるほど、説明の一貫性率が高まることも発見しました。その中でGPT-4は人間に最も近いものの、まだ大きな差があります。
写真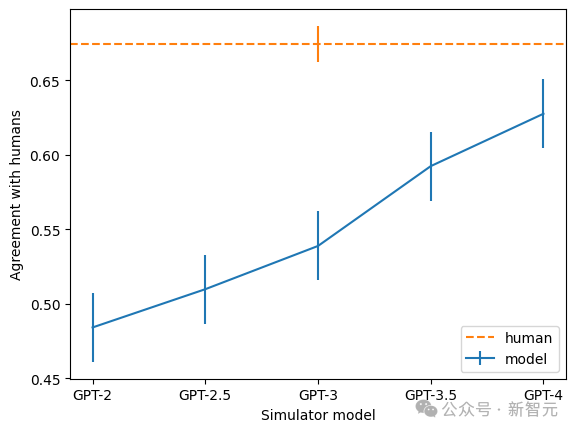
写真
写真
写真## #############写真######
スパース オートエンコーダーの設定
OpenAI で使用されるスパース オートエンコーダーは、入力端にバイアスがあるモデルであり、バイアスと ReLU を備えた A 線形層も含まれています。そして別の線形層とデコーダ用のバイアス。
研究者らは、バイアス項がオートエンコーダのパフォーマンスにとって非常に重要であることを発見しました。彼らは、入力と出力に適用されるバイアスを関連付けています。結果は、固定バイアスを減算することと同じです。すべてのアクティベーション。
研究者らは、Adam オプティマイザーを使用してオートエンコーダーをトレーニングし、MSE を使用してトランスフォーマーの MLP アクティベーションを再構築しました。 MSE 損失を使用すると、ポリセマンティクスの課題を回避でき、損失と L1 ペナルティを使用してスパース性を促進できます。
オートエンコーダーをトレーニングする場合、いくつかの原則が非常に重要です。
1 つ目はスケールです。より多くのデータでオートエンコーダーをトレーニングすると、特徴が主観的に「より鮮明」になり、より解釈しやすくなります。つまり、OpenAI はオートエンコーダーに 80 億のトレーニング ポイントを使用します。
第 2 に、トレーニング中に、たとえ多数のデータ ポイントであっても、一部のニューロンが発火を停止します。
研究者らは、トレーニング中にこれらの死んだニューロンを「リサンプリング」し、モデルが特定のオートエンコーダーの隠れ層ディメンションに対してより多くの特徴を表現できるようにし、より良い結果を生み出すことができました。
判断指標
自分のやり方が効果的かどうかはどうやって判断するのでしょうか?機械学習では、単純に損失を標準として使用できますが、ここで同様の参考資料を見つけるのは簡単ではありません。
たとえば、オートエンコーダーとデータの合計情報を最小化する分解が、ある意味で最良となるように、情報ベースのメトリックを探します。
- しかし、実際には、総情報は、主観的な機能の解釈可能性やアクティベーションの希薄性とは何の関係もないことがよくあります。
最終的に、研究者はいくつかの追加の指標を組み合わせて使用しました:
ただし、研究者らは、Transformer でトレーニングされたスパース オートエンコーダから辞書学習ソリューションのより良い指標を決定したいという希望も表明しました。- 手動検査: 機能が正常に見えるかどうか説明してください。
#- 機能密度: リアルタイムの機能の数と、それらをトリガーするトークンの割合は、非常に役立つガイドです。
#- 再構築損失: オートエンコーダーが MLP アクティベーションをどの程度うまく再構築するかを示す尺度。最終的な目標は、MLP 層の機能を考慮して、MSE 損失を低く抑えることです。- 玩具モデル: すでによく理解されているモデルを使用すると、オートエンコーダーのパフォーマンスを明確に評価できます。
#参考:
#https://www.php.cn/link/133a1d4c028736d9023d335f06594a0e
以上がOpenAI は、オープンソースの Transformer Debugger を正式に発表しました。コードを書く必要がなく、誰でも LLM ブラック ボックスを解読できますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- OpenAI は新しい一貫性モデルをリリースし、GAN 速度は 18FPS に達し、リアルタイムで高品質の画像を生成できます。
- ChatGPT は、Google、Meta、OpenAI 間のチャットボット競争に焦点を当て、LeCun の不満を話題の焦点にしています
- Copilot が登場し、ChatGPT はデフォルトで Bing 検索を使用し、Microsoft と OpenAI の大きな世界がここにあります
- PHP でデシジョン ツリーとニューロン ネットワークをモデル化するにはどうすればよいですか?
- 「電子ショウジョウバエ」警報ムスク!その背後には、130,000 個のニューロンからなる全脳マップがあり、コンピューター上で実行できます。