
ホームページ >テクノロジー周辺機器 >AI >ICLR 2024 | オーディオとビデオの分離に新たな視点を提供する、清華大学の胡暁林チームが RTFS-Net を立ち上げ
ICLR 2024 | オーディオとビデオの分離に新たな視点を提供する、清華大学の胡暁林チームが RTFS-Net を立ち上げ

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-03-06 18:28:13637ブラウズ
視聴覚音声分離 (AVSS) テクノロジーの主な目的は、顔情報を使用して、混合信号内の対象話者の音声を識別して分離することです。このテクノロジーは、スマート アシスタント、リモート会議、拡張現実など、複数の分野で幅広く応用されています。 AVSS テクノロジーにより、騒がしい環境での音声信号の品質が大幅に向上し、音声認識とコミュニケーションの効果が向上します。このテクノロジーの発展により、人々の日常生活や仕事に利便性がもたらされ、人々は次のことを容易に行うことができます。
従来の視聴覚音声分離方法は、通常、特に複雑なモデルと大量のコンピューティング リソースを必要とします。ノイズが多い バックグラウンドや複数のスピーカーがある状況では、そのパフォーマンスが制限されやすくなります。これらの問題を克服するために、研究者は深層学習ベースの手法の探索を開始しました。しかし、既存の深層学習技術には、計算の複雑性が高く、未知の環境への適応が難しいという課題があります。
具体的には、現行の音声・映像音声分離方式には次のような問題点があります。
タイムドメイン方式: 高品質な音声分離効果が得られますが、パラメータが多く、計算量が多く、処理速度が遅い。
時間-周波数領域手法: 計算効率は高くなりますが、歴史的には時間領域手法と比較してパフォーマンスが悪くなります。
#1. 時間と周波数の次元の独立したモデリングが欠如している。
2. 複数の受容野からの視覚的な手がかりは、モデルのパフォーマンスを向上させるために完全には活用されていません。
3. 複雑な特徴を不適切に処理すると、重要な振幅と位相の情報が失われます。
これらの課題に対処するために、清華大学の胡暁林准教授のチームの研究者は、RTFS-Net と呼ばれる新しい視聴覚音声分離モデルを提案しました。このモデルは圧縮再構成手法を採用しており、分離パフォーマンスを向上させながらモデルの計算の複雑さとパラメータの数を大幅に削減します。 RTFS-Net は、100 万未満のパラメータを使用する最初のオーディオビジュアル音声分離方法であり、時間周波数領域のマルチモーダル分離においてすべての時間領域モデルを上回る性能を発揮する最初の方法でもあります。

論文のアドレス: https://arxiv.org/abs/2309.17189
論文のホームページ: https://cslikai.cn/RTFS-Net/AV-Model-Demo.html
コードアドレス: https://github.com/spkgyk/RTFS-Net (近日公開予定) ))
#手法の紹介
#RTFS-Net の全体的なネットワーク アーキテクチャを以下の図 1 に示します。
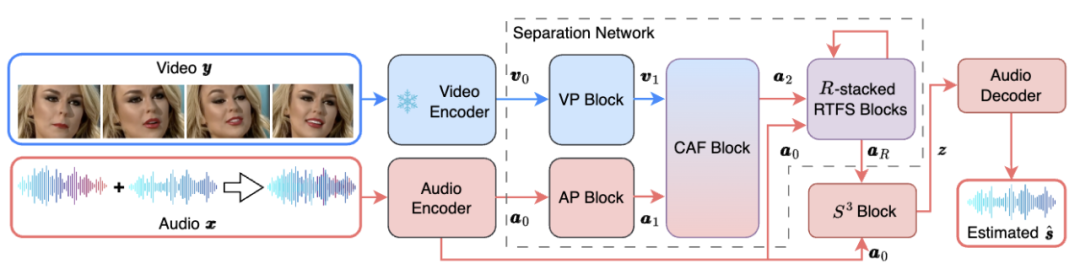 ##図 1. RTFS のネットワーク フレームワークNet
##図 1. RTFS のネットワーク フレームワークNet
その中で、RTFS ブロック (図 2 を参照) が影響を及ぼします。圧縮と独立モデリングのための音響次元 (時間と周波数) を考慮し、低複雑性の部分空間を作成しながら情報損失を最小限に抑えます。具体的には、RTFS ブロックはデュアルパス アーキテクチャを採用し、時間と周波数の両方の次元でオーディオ信号を効率的に処理します。このアプローチにより、RTFS ブロックはオーディオ信号に対する高い感度と精度を維持しながら、計算の複雑さを軽減できます。 RTFS ブロックの具体的なワークフローは次のとおりです: 1. 時間周波数圧縮: RTFS ブロックはまず、入力オーディオ特徴を時間次元と周波数次元で圧縮します。
2. 独立した次元モデリング: 圧縮の完了後、RTFS ブロックは時間と周波数の次元を独立してモデル化します。
3. 次元融合: 時間次元と周波数次元を個別に処理した後、RTFS ブロックは融合モジュールを通じて 2 つの次元の情報をマージします。
4. 再構成と出力: 最後に、融合された特徴は、一連のデコンボリューション層を通じて元の時間周波数空間に再構成されます。
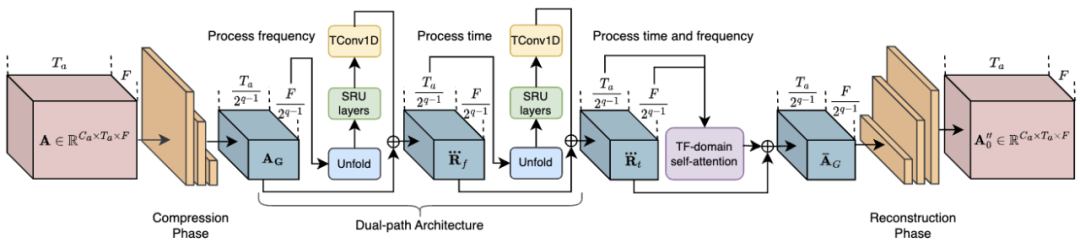 ## 図 2. RTFS ブロック
## 図 2. RTFS ブロック
# (CAF) モジュールのネットワーク構造(図 3 に示すように) 音声情報と視覚情報を効果的に融合し、音声分離効果を高め、計算量は以前の SOTA 手法のわずか 1.3% です。具体的には、CAF モジュールはまず、深さとグループ化された畳み込み演算を使用してアテンション ウェイトを生成します。これらの重みは入力特徴の重要性に基づいて動的に調整されるため、モデルは最も関連性の高い情報に焦点を当てることができます。次に、生成された注意の重みを視覚および聴覚の特徴に適用することにより、CAF モジュールは多次元で重要な情報に焦点を当てることができます。このステップでは、さまざまな次元の特徴を重み付けして融合して、包括的な特徴表現を生成します。アテンション メカニズムに加えて、CAF モジュールはゲート メカニズムを採用して、さまざまなソース フィーチャの融合の程度をさらに制御することもできます。このアプローチにより、モデルの柔軟性が向上し、より詳細な情報フロー制御が可能になります。 ##図 3. CAF の概略構造図融合モジュール
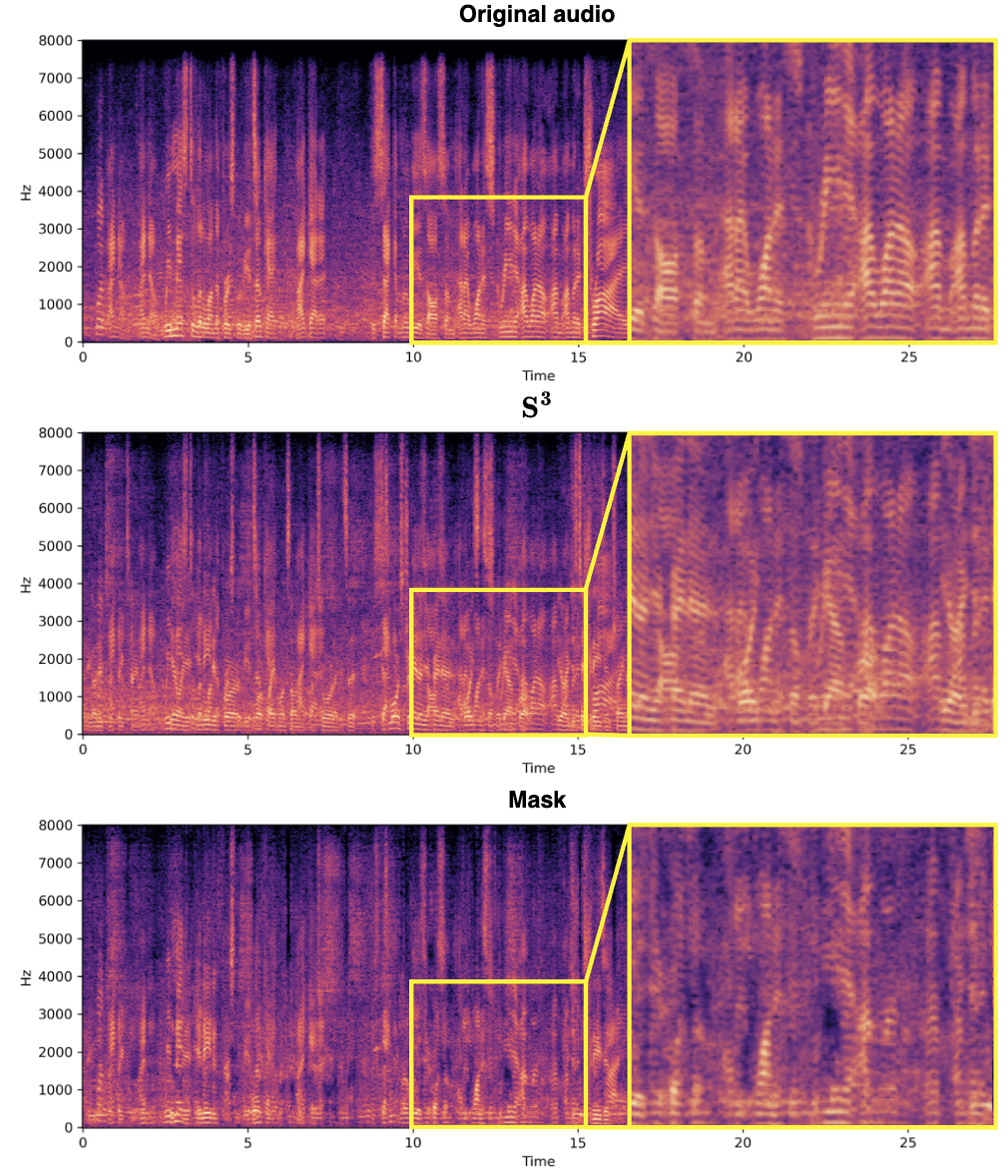
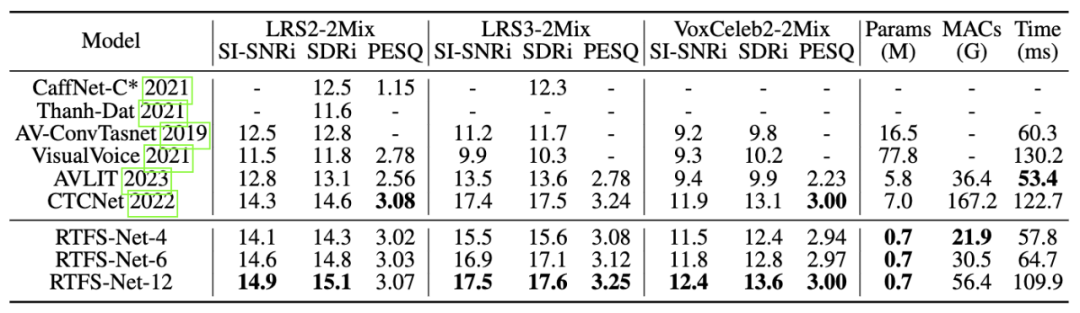
分離効果以下に示すように、3 つのベンチマーク マルチモーダル音声分離データセット (LRS2、LRS3、および VoxCeleb2) では、RTFS-Net はモデル パラメーターと計算の複雑さを大幅に削減しながら、現在の最先端のパフォーマンスに近づくか、それを超えています。効率とパフォーマンスのトレードオフは、異なる数の RTFS ブロック (4、6、12 ブロック) を使用したバリアントを通じて実証されており、RTFS-Net-6 はパフォーマンスと効率のバランスが取れています。 RTFS-Net-12 は、テストされたすべてのデータ セットで最高のパフォーマンスを示し、複雑なオーディオとビデオの同期分離タスクを処理する際の時間周波数ドメイン手法の利点を証明しました。 ミックスビデオ: 大型モデル技術の継続的な開発により、音声と映像の音声分離が可能になりました。この分野では、分離品質を向上させるための大型モデルも追求されています。ただし、これはエンドデバイスでは実現できません。 RTFS-Net は、大幅に削減された計算の複雑さとパラメータの数を維持しながら、大幅なパフォーマンスの向上を実現します。これは、AVSS パフォーマンスの向上には必ずしも大規模なモデルが必要ではなく、むしろオーディオとビジュアルのモダリティ間の複雑な相互作用をより適切に捕捉する革新的で効率的なアーキテクチャが必要であることを示しています。 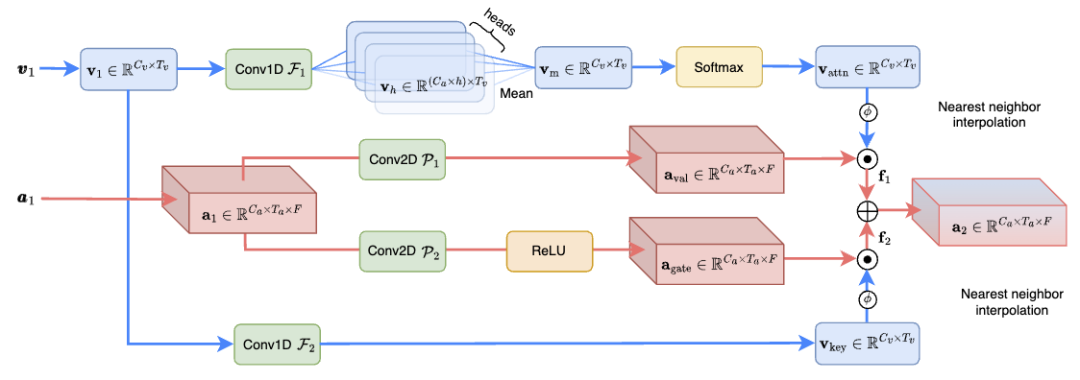



以上がICLR 2024 | オーディオとビデオの分離に新たな視点を提供する、清華大学の胡暁林チームが RTFS-Net を立ち上げの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。