
ホームページ >テクノロジー周辺機器 >AI >清華大学とハルビン工業大学は大規模モデルを 1 ビットに圧縮しており、携帯電話上で大規模モデルを実行したいという願望が実現しようとしています。
清華大学とハルビン工業大学は大規模モデルを 1 ビットに圧縮しており、携帯電話上で大規模モデルを実行したいという願望が実現しようとしています。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-03-04 14:31:291203ブラウズ
大きなモデルが業界で普及して以来、大きなモデルを圧縮したいという人々の欲求が衰えることはありません。大型モデルは多くの面で優れた機能を発揮しますが、導入コストが高いため、使用の敷居が大幅に高くなるからです。このコストは主に占有スペースと計算量から発生します。 「モデル量子化」は、大規模なモデルのパラメータを低ビット幅の表現に変換することでスペースを節約します。現在、主流の方法では、モデルのパフォーマンスをほとんど損なうことなく、既存のモデルを 4 ビットに圧縮できます。しかし、3 ビット以下の量子化は、研究者を悩ませる乗り越えられない壁のようなものです。
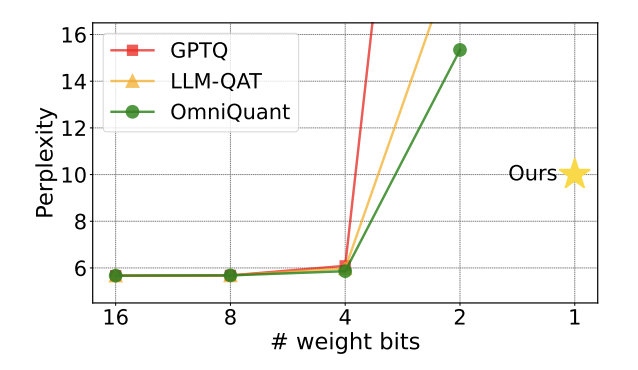
図 1: 定量的モデルの複雑さは 2 ビットで急速に増加します
最近、記事 清華大学とハルビン工業大学がarXiv上で共同発表した論文は、この障害を突破する希望をもたらし、国内外の学界で大きな注目を集めた。この論文は 1 週間前に huggingface のホットペーパーとしても掲載され、有名な論文推薦者 AK によって推奨されました。 研究チームは、モデル定量化の研究で初めて、2ビットの定量化レベルを超え、1ビットの定量化に果敢に挑戦しました。

論文タイトル: OneBit: 極低ビット大規模言語モデルに向けて
論文アドレス: https ://arxiv.org/pdf/2402.11295.pdf
著者によって提案されたメソッドは「OneBit」と呼ばれるもので、この研究の本質を非常に適切に説明しています。大規模モデルのトレーニングは次のとおりです。実数 1 ビット に圧縮されます。この論文では、モデル パラメーターの 1 ビット表現の新しい方法と、量子化されたモデル パラメーターの初期化方法を提案し、量子化を意識したトレーニング ( QAT)。実験によると、この方法では、LLaMA モデルの少なくとも 83% のパフォーマンスを確保しながら、モデル パラメーターを大幅に圧縮できることが示されています。
著者は、モデル パラメーターが 1 ビットに圧縮されると、行列乗算の「要素乗算」が存在しなくなり、より高速な「ビット割り当て」に置き換えられると指摘しました。 」操作により、計算効率が大幅に向上します。この研究の重要性は、2 ビットの定量化ギャップを越えるだけでなく、PC やスマートフォン上で大規模なモデルを展開できるようになることです。既存の作業の制限
モデルの定量化は、主にモデルの nn.Linear 層を変換することによって行われます (Embedding 層と Lm_head を除く)レイヤー) 低精度表現のための空間圧縮を実装します。以前の研究 [1、2] の基礎は、Round-To-Nearest (RTN) 法を使用して、高精度の浮動小数点数を近くの整数グリッドに近似的にマッピングすることです。これは
# と表現できます。 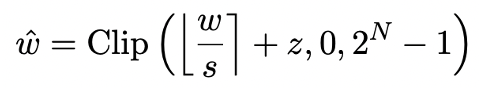
さらに、以前の研究では、1 ビット モデルがどのような構造を採用する可能性があるかについても検討されています。 BitNet に関する数か月前の研究 [3] では、モデル パラメーターを符号 (・) 関数に渡し、1/-1 に変換することで 1 ビット表現を実装しています。ただし、この方法には重大なパフォーマンスの低下と不安定なトレーニング プロセスが発生するため、実際の応用は制限されます。
OneBit フレームワーク
OneBit のメソッド フレームワークには、新しい 1 ビット レイヤー構造、SVID ベースのパラメーター初期化メソッド、および量子化を意識した知識の蒸留が含まれています。 -ベースの知識の伝達。
1. 新しい 1 ビット構造
OneBit の最終目標は、LLM を変換することです。重み行列は 1 ビットに圧縮されます。実数 1 ビットでは、各重み値が 1 ビットでのみ表現できること、つまり、可能な状態が 2 つだけであることが必要です。著者は、大規模モデルのパラメータでは、浮動小数点数の精度の高さとパラメータ行列のランクの高さという 2 つの重要な要素を考慮する必要があると考えています。したがって、著者は、量子化による精度の損失を補うために、FP16 形式で 2 つの値ベクトルを導入します。この設計は、元の重み行列の高いランクを維持するだけでなく、値ベクトルを通じて必要な浮動小数点精度も提供するため、モデルのトレーニングと知識の伝達が容易になります。 1bit リニア層の構造と FP16 高精度リニア層の構造の比較は次のとおりです。 図 3: FP16 の比較線形層と OneBit 線形層 (a) 左側は FP16 高精度モデル構造、(b) は OneBit フレームワークの線形層です。 OneBit フレームワークでは、値ベクトル g と h のみが FP16 形式に残り、重み行列は完全に ±1 で構成されていることがわかります。このような構造は、精度とランクの両方を考慮しており、安定した高品質の学習プロセスを確保するために非常に意味があります。 OneBit はモデルをどの程度圧縮しますか?著者は論文の中で計算を示しています。 4096*4096 の線形層が圧縮されていると仮定すると、OneBit には 4096*4096 1 ビット行列と 2 つの 4096*1 16 ビット値ベクトルが必要です。ビットの総数は 16,908,288、パラメータの総数は 16,785,408 で、平均すると、各パラメータは約 1.0073 ビットしか占有しません。このような圧縮は前例がなく、まさに1ビットの大きなモデルと言えます。 2. SVID に基づいて量子化モデルを初期化します 完全にトレーニングされた元のモデルをより適切に使用するために、量子化を初期化する 著者は、「値符号独立行列分解 (SVID)」と呼ばれる新しいパラメータ行列分解方法を提案しています。この行列分解メソッドは、シンボルと絶対値を分離し、絶対値に対してランク 1 近似を実行します。元の行列パラメータへのアプローチは、次のように表すことができます。 ここでのランク 1 の近似は、特異値分解 (SVD) や非負値行列分解 (NMF) などの一般的な行列分解方法によって実現できます。次に、著者は、この SVID メソッドが演算順序を交換することで 1 ビット モデルのフレームワークに適合し、それによってパラメータの初期化が実現できることを数学的に示しました。さらに、この論文は、シンボリック行列が分解プロセス中に元の行列に近似する役割を果たすことも証明しています。 3. 知識の蒸留を通じて元のモデルの機能を移行する 著者は、ウルトラの問題を解決することは、 -大規模モデルの低ビット幅量子化 効果的な方法は、定量化された知覚トレーニング QAT です。 OneBit モデル構造では、知識の蒸留を使用して非量子化モデルから学習し、量子化モデルへの機能の移行を実現します。具体的には、学生モデルは主に教師モデルのロジットと隠れた状態によって導かれます。
トレーニング中に、値ベクトルと行列の値が更新されます。モデルの定量化が完了すると、記号 (・) 以降のパラメーターが直接保存され、推論およびデプロイメント時に直接使用されます。 OneBit および FP16 Transformer、古典的なポストトレーニング量子化強ベースライン GPTQ、量子化対応トレーニング強ベースライン LLM- QATと最新の2ビット重み量子化強力ベースラインOmniQuantを比較しました。また、現時点では 1 ビット重み量子化に関する研究が存在しないため、著者は OneBit フレームワークに 1 ビット重み量子化のみを使用し、他の方式では 2 ビット量子化設定を採用しています。これは、典型的な「弱い勝利」です。強い"。 表 1: OneBit とベースライン手法 (OPT モデルと LLaMA-1 モデル) の効果の比較 ##表 2: OneBit とベースライン手法の効果の比較 (LLaMA-2 モデル) 表 1 と表 2 は、OneBit と他の手法との比較を示しています。 -bit 定量化時間の利点。検証セット上のモデルの複雑さを定量化するという点では、OneBit が FP16 モデルに最も近いです。ゼロショット精度の点では、OPT モデルの個々のデータセットを除いて、OneBit 量子化モデルがほぼ最高のパフォーマンスを達成しました。残りの 2 ビット量子化方法では、両方の評価メトリクスで大きな損失が見られます。 OneBit は、モデルが大きいほどパフォーマンスが向上する傾向があることに注目してください。つまり、モデル サイズが大きくなるにつれて、FP16 精度モデルは複雑さの低減にほとんど影響を与えませんが、OneBit はより多くの複雑さの低減を示します。さらに著者らは、超低ビット幅の量子化には量子化を意識したトレーニングが必要になる可能性があるとも指摘しています。 #図 4: 常識推論タスクの比較 図 5: 世界の知識の比較 # #図 4 - 図 6 では、いくつかの種類の小型モデルのスペース占有とパフォーマンス損失も比較しています。これらのモデルは、完全にトレーニングされた 2 つのモデル Pythia-1.0B と TinyLLaMA-1.1B を含む、さまざまなチャネルを通じて取得され、低ランク LowRank を通じて取得されます。分解して得たLlamaとOneBit-7B。 OneBit-7B は平均ビット幅が最も小さく、占有スペースも最も小さいにもかかわらず、常識的な推論能力においては他のモデルよりも優れていることがわかります。著者はまた、社会科学の分野ではモデルが深刻な知識の忘却に直面していると指摘した。全体として、OneBit-7B は実用的な価値を示しています。図 7 に示すように、OneBit 量子化 LLaMA-7B モデルは、命令を微調整した後、スムーズなテキスト生成機能を示しています。
ディスカッション
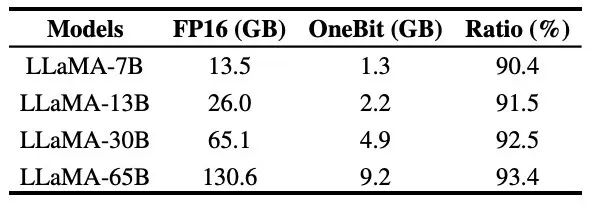
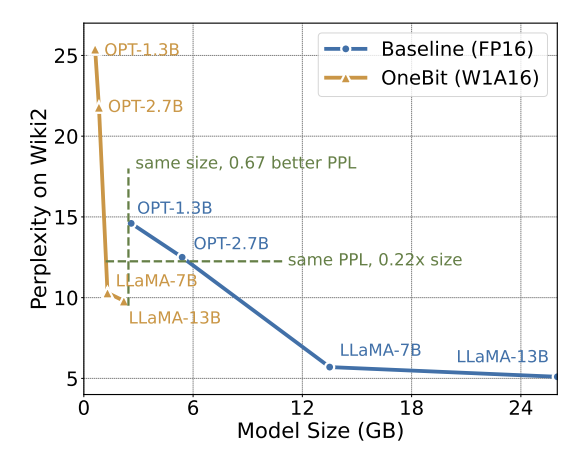
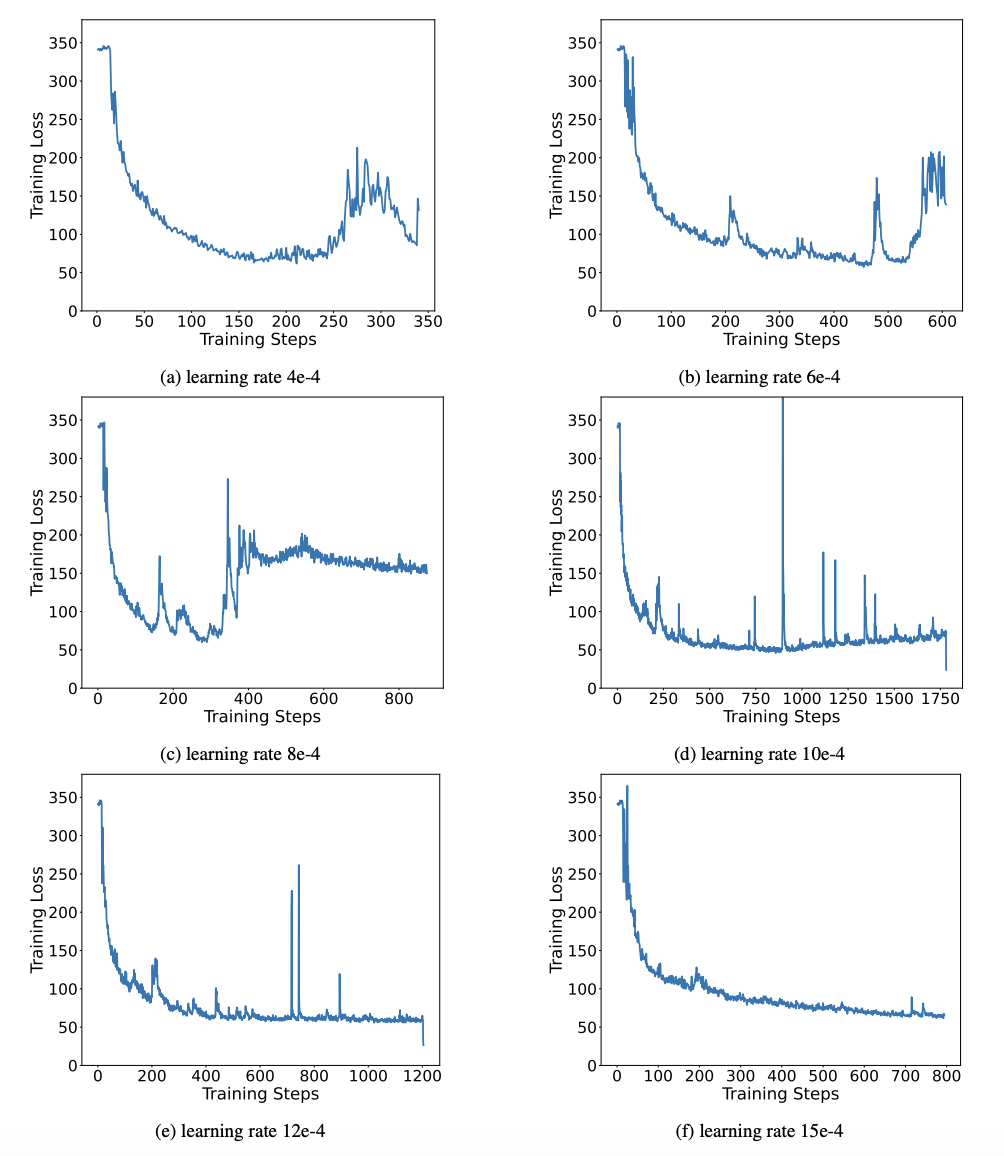
##表 3: さまざまな LLaMA での OneBitモデル の圧縮率 表 3 は、さまざまなサイズの LLaMA モデルに対する OneBit の圧縮率を示しています。 OneBit のモデルの圧縮率は 90% を超えており、これまでにない圧縮能力であることがわかります。モデルが増加するにつれて、OneBit の圧縮率が高くなるのは注目に値しますが、これは、量子化に関与しない Embedding 層のパラメータの割合がどんどん小さくなるためです。前述したように、モデルが大きくなるほど、OneBit によってもたらされるパフォーマンスの向上は大きくなります。これは、より大きなモデルにおける OneBit の利点を示しています。 #図 8: モデルのサイズとパフォーマンスのトレードオフ 超低ビット量子化は可能性がありますが、ある程度のパフォーマンスの低下はありますが、図 8 に示すように、サイズとパフォーマンスのバランスが取れています。著者らは、特にモバイル デバイスにモデルを展開する場合、モデル サイズの圧縮が重要であると考えています。 さらに、著者は 1 ビット量子化モデルの計算上の利点も指摘しました。パラメータは純粋にバイナリであるため、1 ビットで 0/1 で表すことができ、間違いなく多くのスペースを節約できます。高精度モデルにおける行列乗算の要素乗算を効率的なビット演算に変えることができ、ビットの割り当てと加算のみで行列積が完成するため、応用の可能性が大きい。 2. 堅牢性 バイナリ ネットワークは一般に、不安定なトレーニングと困難な収束という問題に直面します。著者が導入した高精度の値ベクトルのおかげで、モデルトレーニングの順計算、逆計算ともに非常に安定しています。 BitNet は以前に 1 ビット モデル構造を提案しましたが、この構造では完全にトレーニングされた高精度モデルから機能を転送するのが困難です。図 9 に示すように、著者は BitNet の転移学習能力をテストするためにさまざまな異なる学習率を試しましたが、教師の指導の下ではその収束が難しいことがわかりました。これは、OneBit の安定した学習価値も証明しました。 図 9: さまざまな学習率でトレーニングした後の BitNet の定量化能力 論文 最後に、著者はまた、超低ビット幅に関する将来の研究の方向性についても示唆しています。たとえば、より良いパラメータ初期化方法を見つけたり、トレーニング コストを削減したり、アクティベーション値の量子化をさらに検討したりできます。 技術的な詳細については、元の論文を参照してください。 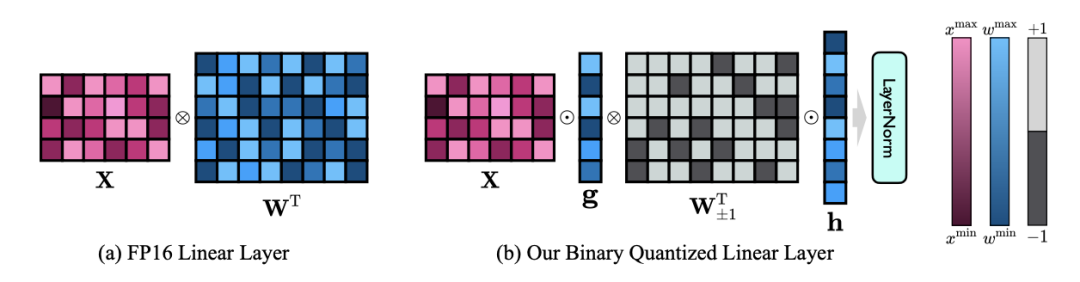
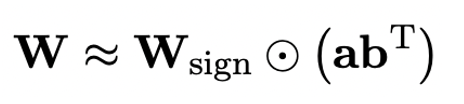
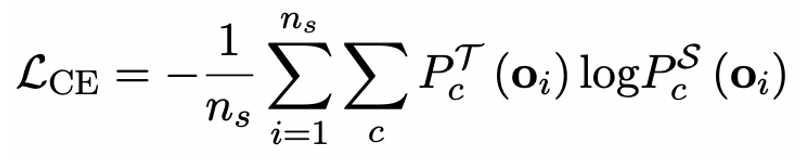
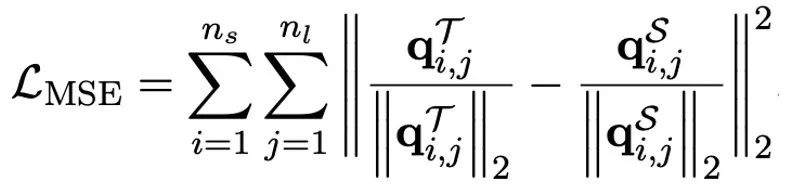
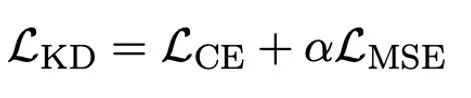 実験と結果
実験と結果
モデルの選択に関して、著者は OneBit の有効性を証明するために、1.3B から 13B までの異なるサイズのモデル、OPT、LLaMA-1/2 の異なるシリーズのモデルも選択しました。評価指標に関して、著者は、検証セットの複雑さと常識推論のゼロショット精度という、以前のモデル定量化の 2 つの主要な評価次元に従います。
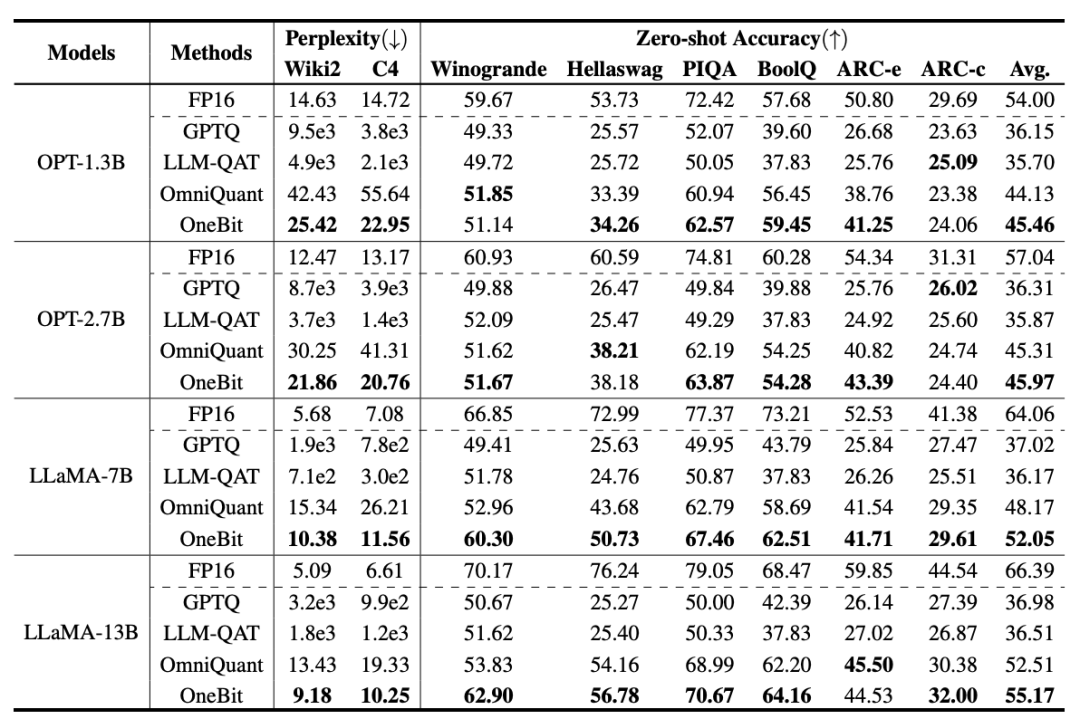
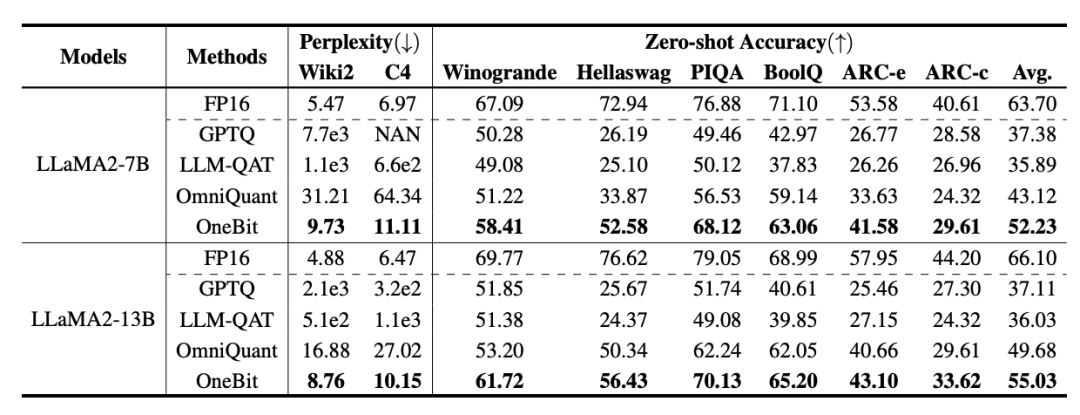
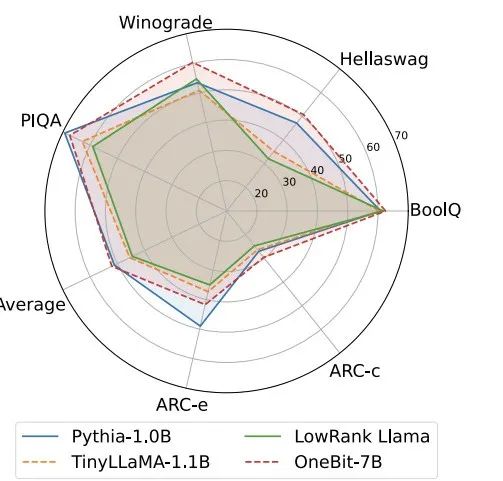
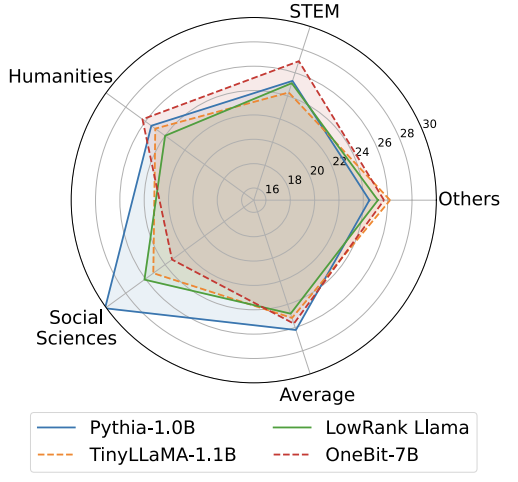
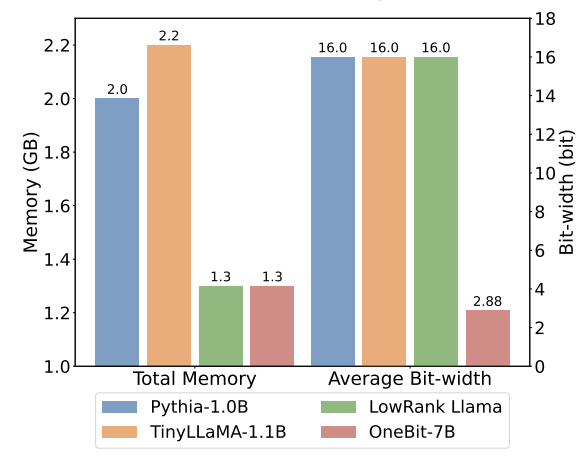
 図 7: OneBit フレームワークによって定量化された LLaMA-7B モデルの機能
図 7: OneBit フレームワークによって定量化された LLaMA-7B モデルの機能1. 効率
以上が清華大学とハルビン工業大学は大規模モデルを 1 ビットに圧縮しており、携帯電話上で大規模モデルを実行したいという願望が実現しようとしています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。