



正面からの記述と個人的な理解
近年、自動運転技術における視覚中心の 3D 認識が急速に進歩しています。さまざまな 3D 認識モデルには多くの構造的および概念的な類似点がありますが、特徴の表現、データ形式、および目標には依然としていくつかの違いがあり、統一された効率的な 3D 認識フレームワークの設計に課題をもたらしています。したがって、研究者たちは、より完全で効率的な 3D 認識システムを構築するために、さまざまなモデル間の違いをより適切に統合するためのソリューションを見つけるために懸命に取り組んでいます。この種の取り組みにより、自動運転の分野により信頼性が高く先進的な技術がもたらされ、複雑な環境、特に BEV での検出タスクや占有タスクでの能力が向上すると期待されています。これは依然として非常に難しく、不安定性と制御不能な影響により、多くのアプリケーションにとって頭痛の種となっています。 UniVision は、視覚中心の 3D 認識における 2 つの主要なタスク、つまり占有予測とオブジェクト検出を統合するシンプルで効率的なフレームワークです。コアポイントは、相補的な 2D-3D 特徴変換のための明示的-暗黙的ビュー変換モジュールであり、UniVision は、効率的かつ適応的なボクセルと BEV 特徴抽出、強化、およびインタラクションのためのローカルおよびグローバル特徴抽出および融合モジュールを提案しています。
データ強化の部分では、UniVision は、マルチタスク フレームワーク トレーニングの効率と安定性を向上させるために、共同占有検出データ強化戦略と段階的な減量調整戦略も提案しました。シーンフリー LIDAR セグメンテーション、シーンフリー検出、OpenOccupancy、Occ3D を含む 4 つの公開ベンチマークで、さまざまな認識タスクに関する広範な実験が行われています。 UniVision は、各ベンチマークでそれぞれ 1.5 mIoU、1.8 NDS、1.5 mIoU、および 1.8 mIoU のゲインで SOTA を達成しました。 UniVision フレームワークは、統合されたビジョン中心の 3D 認識タスクの高性能ベースラインとして機能します。
BEV および占有タスクに詳しくない場合は、
BEV 知覚チュートリアルおよび 占有占有ネットワーク チュートリアル をさらに学習して、技術的な詳細を学ぶこともできます。 !
3D 認識分野の現状3D 認識は自動運転システムの主なタスクであり、一連のセンサー (LIDAR など) を利用することを目的としています。 、レーダー、カメラ)取得されたデータは、走行シーンを総合的に把握し、その後の計画や意思決定に活用することができます。これまで、3D 認識の分野は、点群データから得られた正確な 3D 情報により、LIDAR ベースのモデルが主流でした。ただし、LIDAR ベースのシステムは高価で、悪天候の影響を受けやすく、導入が不便です。対照的に、ビジョンベースのシステムには、低コスト、簡単な導入、優れた拡張性など、多くの利点があります。したがって、視覚を中心とした三次元認識は研究者の間で広く注目を集めています。
最近、ビジョンベースの 3D 検出は、特徴表現変換、時間融合、教師あり信号設計を通じて大幅に改善され、LIDAR ベースのモデルとのギャップを継続的に狭めています。さらに、視覚ベースの占有タスクは近年急速に発展しています。一部のオブジェクトを表すために 3D ボックスを使用するのとは異なり、占有は、運転シーンのジオメトリとセマンティクスをより包括的に記述することができ、オブジェクトの形状やカテゴリに限定されません。
検出方法と占有方法には多くの構造的および概念的な類似点がありますが、両方のタスクを同時に処理し、それらの相互関係を調査することについては十分に研究されていません。占有モデルと検出モデルは、多くの場合、異なる特徴表現を抽出します。占有予測タスクでは、さまざまな空間位置での徹底的な意味論的および幾何学的判断が必要となるため、きめの細かい 3D 情報を保存するためにボクセル表現が広く使用されています。検出タスクでは、ほとんどのオブジェクトが同じ水平面上にあり、重なりが小さいため、BEV 表現が推奨されます。
BEV 表現と比較すると、ボクセル表現は優れていますが、効率は劣ります。さらに、多くの高度なオペレータは主に 2D フィーチャ向けに設計および最適化されているため、3D ボクセル表現との統合はそれほど単純ではありません。 BEV 表現は時間とメモリの効率が高くなりますが、高さ次元の構造情報が失われるため、密な空間予測には最適ではありません。特徴の表現に加えて、認識タスクが異なれば、データ形式と目標も異なります。したがって、マルチタスク 3D 認識フレームワークのトレーニングの均一性と効率を確保することは、大きな課題です。
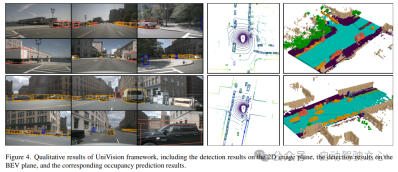
UniVision ネットワーク構造UniVision フレームワークの全体構造を図 1 に示します。このフレームワークは、周囲の N 台のカメラからのマルチビュー画像を入力として受け取り、画像特徴抽出ネットワークを通じて画像特徴を抽出します。次に、深度ガイドによる明示的な特徴強調とクエリによる暗黙的な特徴サンプリングを組み合わせた Ex-Im ビュー変換モジュールを使用して、2D 画像特徴が 3D ボクセル特徴にアップグレードされます。ボクセル特徴は、ローカル グローバル特徴抽出および融合ブロックによって処理され、ローカル コンテキスト認識ボクセル特徴とグローバル コンテキスト認識 BEV 特徴がそれぞれ抽出されます。その後、相互表現特徴相互作用モジュールを通じて、さまざまな下流の知覚タスクのためにボクセル特徴と BEV 特徴の間で情報が交換されます。トレーニング段階では、UniVision フレームワークは、Occ-Det データ強化と損失重みの段階的な調整を組み合わせて効果的にトレーニングする戦略を採用します。
1) Ex-Im View Transform
深度指向の明示的な機能強化。ここでは LSS アプローチに従います:
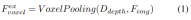
#2) クエリガイドによる暗黙的な特徴サンプリング。ただし、3D 情報の表現にはいくつかの欠点があります。の精度は、推定された深度分布の精度と高い相関があります。さらに、LSS によって生成されるポイントは均一に分配されません。ポイントはカメラの近くでは密集しており、遠くでは疎になります。したがって、クエリガイドによる特徴サンプリングをさらに使用して、上記の欠点を補います。
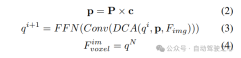
LSS から生成されたポイントと比較して、ボクセル クエリは 3D 空間に均一に分散されており、すべてのトレーニング サンプルの統計的特性から学習されます。これは深度に一致します。 LSS で使用される事前情報は無関係です。したがって、相互に補完し、ビュー変換モジュールの出力特徴としてそれらを接続します。
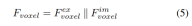
#2) ローカルおよびグローバル特徴の抽出と融合
与えられた入力ボクセル特徴を、最初に Z 軸上に特徴をオーバーレイし、畳み込み層を使用してチャネルを削減し、BEV 特徴を取得します。
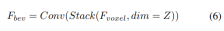
次に、モデル特徴抽出と拡張のために 2 つの並列ブランチに分割されます。ローカル特徴抽出、グローバル特徴抽出、そして最後の相互表現特徴相互作用!図 1(b) に示すように。
#3) 損失関数と検出ヘッド
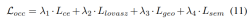
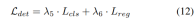

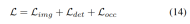
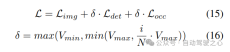
4) 結合された Occ-Det 空間データ強化
3D 検出タスクでは、一般的な画像レベルのデータ強化に加えて、空間レベルのデータ強化もモデルのパフォーマンスを向上させるのに効果的です。ただし、占有タスクに空間レベルの強化を適用するのは簡単ではありません。データ拡張 (ランダムなスケーリングや回転など) を個別の占有ラベルに適用する場合、結果として得られるボクセルのセマンティクスを判断するのは困難です。したがって、既存の方法では、占有タスクにおけるランダムな反転などの単純な空間拡張のみが適用されます。この問題を解決するために、UniVision は、フレームワーク内の 3D 検出タスクと占有タスクの同時強化を可能にする共同 Occ-Det 空間データ強化を提案しています。 3D ボックスのラベルは連続値であり、強化された 3D ボックスはトレーニング用に直接計算できるため、検出には BEVDet の強化方法に従います。占有ラベルは離散的で操作が困難ですが、ボクセル フィーチャは連続的なものとして扱うことができ、サンプリングや補間などの操作を通じて処理できます。したがって、データ拡張のために占有ラベルを直接操作するのではなく、ボクセル フィーチャを変換することをお勧めします。
具体的には、まず空間データ拡張がサンプリングされ、対応する 3D 変換行列が計算されます。占有ラベルとそのボクセル インデックス について、その 3 次元座標を計算します。次に、それを適用して正規化して、拡張ボクセル機能のボクセル インデックスを取得します :
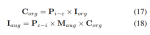
#実験結果の比較
検証には、NuScenes LiDAR セグメンテーション、NuScenes 3D オブジェクト検出、OpenOccupancy、Occ3D の複数のデータ セットを使用しました。 NuScenes LiDAR セグメンテーション: 最近の OccFormer および TPVFormer によると、カメラ画像は LIDAR セグメンテーション タスクの入力として使用され、LIDAR データは出力フィーチャをクエリするための 3D 位置を提供するためにのみ使用されます。評価指標として mIoU を使用します。 NuScenes 3D オブジェクト検出: 検出タスクには、nuScenes の公式メトリックである nuScene 検出スコア (NDS) を使用します。これは、平均 mAP と、平均変換誤差 (ATE) を含むいくつかのメトリックの加重合計です。平均スケール誤差 (ASE)、平均配向誤差 (AOE)、平均速度誤差 (AVE)、および平均属性誤差 (AAE)。 OpenOccupancy: OpenOccupancy ベンチマークは nuScenes データセットに基づいており、512×512×40 の解像度でセマンティック占有ラベルを提供します。ラベル付けされたクラスは、評価指標として mIoU を使用する LIDAR セグメンテーション タスクのクラスと同じです。 Occ3D: Occ3D ベンチマークは nuScenes データセットに基づいており、200×200×16 解像度でセマンティック占有ラベルを提供します。 Occ3D はさらに、トレーニングと評価用の可視マスクを提供します。ラベル付けされたクラスは、評価指標として mIoU を使用する LIDAR セグメンテーション タスクのクラスと同じです。1) Nuscenes LiDAR セグメンテーション
表 1 は、nuScenes LiDAR セグメンテーション ベンチマークの結果を示しています。 UniVision は、最先端のビジョンベース手法である OccFormer を 1.5% mIoU 上回り、リーダーボードにおけるビジョンベースのモデルの新記録を樹立しました。特に、UniVision は、PolarNe や DB-UNet などの一部の LIDAR ベースのモデルよりも優れたパフォーマンスを発揮します。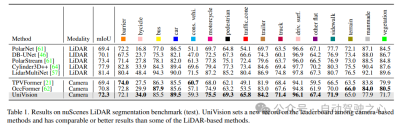
表 2 に示すように、公平な比較に同じトレーニング設定を使用する場合、 UniVision は他の方法よりも優れたパフォーマンスを発揮することが示されました。 512×1408 の画像解像度での BEVDepth と比較して、UniVision は mAP と NDS でそれぞれ 2.4% と 1.1% の向上を達成します。モデルをスケールアップし、UniVision を時間入力と組み合わせると、SOTA ベースの時間検出器を大幅に上回ります。 UniVision は、CBGS を使用せず、より小さい入力解像度でこれを実現します。
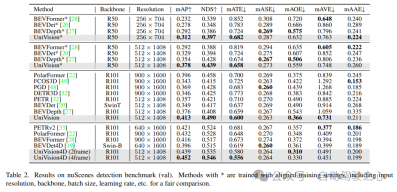
OpenOccupancy ベンチマーク テストの結果を表 3 に示します。 UniVision は、MonoScene、TPVFormer、C-CONet などの最近のビジョンベースの占有方法よりも、mIoU の点でそれぞれ 7.3%、6.5%、1.5% 大幅に優れています。さらに、UniVision は、LMSCNet や JS3C-Net などの LIDAR ベースのメソッドよりも優れたパフォーマンスを発揮します。
表 4 に、Occ3D ベンチマーク テストの結果を示します。 UniVision は、さまざまな入力画像解像度での mIoU の点で、最近のビジョンベースの手法よりも、それぞれ 2.7% および 1.8% 以上大幅に優れています。 BEVFormer と BEVDet-stereo は、事前にトレーニングされた重みをロードし、推論で時間入力を使用しますが、UniVision はそれらを使用しませんが、それでもより良いパフォーマンスを達成することに注目する価値があります。
5) 検出タスクにおけるコンポーネントの有効性
検出タスクに関するアブレーション研究を表 5 に示します。 BEV ベースのグローバル特徴抽出ブランチがベースライン モデルに挿入されると、パフォーマンスは mAP で 1.7%、NDS で 3.0% 向上します。ボクセルベースの占有タスクが補助タスクとして検出器に追加されると、モデルの mAP ゲインは 1.6% 増加します。相互表現相互作用がボクセル特徴から明示的に導入されると、モデルは最高のパフォーマンスを達成し、ベースラインと比較して mAP と NDS をそれぞれ 3.5% と 4.2% 改善します;
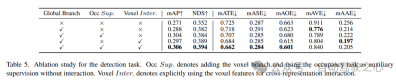
6) 占有タスクにおけるコンポーネントの有効性
占有タスクのアブレーション研究を表 6 に示します。ボクセルベースのローカル特徴抽出ネットワークにより、ベースライン モデルに対して 1.96% の mIoU ゲインの向上がもたらされます。検出タスクが補助監視信号として導入されると、モデルのパフォーマンスは 0.4%mIoU 向上します。
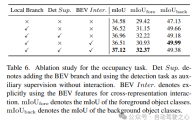
7) その他
表 5 と表 6 は、UniVision フレームワークにおいて、検出タスクと占有タスクが相互に補完していることを示しています。の。検出タスクの場合、占有監視により mAP および mATE メトリクスが改善され、ボクセルのセマンティック学習により、オブジェクトの幾何学形状、つまり中心性とスケールに対する検出器の認識が効果的に向上することが示されています。占有タスクの場合、検出監視により前景カテゴリ (つまり、検出カテゴリ) のパフォーマンスが大幅に向上し、全体的な向上が得られます。
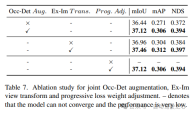
Occ-Det 空間強調、Ex-Im ビュー変換モジュール、および漸進的損失重量調整戦略を組み合わせた効果を表 7 に示します。提案された空間拡張と提案されたビュー変換モジュールにより、mIoU、mAP、NDS メトリックに関する検出タスクと占有タスクが大幅に改善されました。減量調整戦略は、マルチタスク フレームワークを効果的にトレーニングできます。これがないと、統合フレームワークのトレーニングは収束できず、パフォーマンスが非常に低くなります。
参考
紙のリンク: https://arxiv.org/pdf/2401.06994.pdf
論文のタイトル: UniVision: ビジョン中心の 3D 認識のための統合フレームワーク
以上が比類のない UniVision: BEV 検出と Occ 統合統合フレームワーク、デュアル SOTA!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AM
Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AMジェマの範囲で言語モデルの内部の仕組みを探る AI言語モデルの複雑さを理解することは、重要な課題です。 包括的なツールキットであるGemma ScopeのGoogleのリリースは、研究者に掘り下げる強力な方法を提供します
 ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AM
ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AMビジネスの成功のロック解除:ビジネスインテリジェンスアナリストになるためのガイド 生データを組織の成長を促進する実用的な洞察に変換することを想像してください。 これはビジネスインテリジェンス(BI)アナリストの力です - GUにおける重要な役割
 SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AMSQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
 ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM
ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM導入 2人の専門家が重要なプロジェクトで協力している賑やかなオフィスを想像してください。 ビジネスアナリストは、会社の目標に焦点を当て、改善の分野を特定し、市場動向との戦略的整合を確保しています。 シム
 ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AM
ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AMExcelデータカウントと分析:カウントとカウントの機能の詳細な説明 特に大規模なデータセットを使用する場合、Excelでは、正確なデータカウントと分析が重要です。 Excelは、これを達成するためにさまざまな機能を提供し、CountおよびCounta関数は、さまざまな条件下でセルの数をカウントするための重要なツールです。両方の機能はセルをカウントするために使用されますが、設計ターゲットは異なるデータ型をターゲットにしています。 CountおよびCounta機能の特定の詳細を掘り下げ、独自の機能と違いを強調し、データ分析に適用する方法を学びましょう。 キーポイントの概要 カウントとcouを理解します
 ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AM
ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AMGoogle Chrome'sAI Revolution:パーソナライズされた効率的なブラウジングエクスペリエンス 人工知能(AI)は私たちの日常生活を急速に変換しており、Google ChromeはWebブラウジングアリーナで料金をリードしています。 この記事では、興奮を探ります
 ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AM
ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AMインパクトの再考:四重材のボトムライン 長い間、会話はAIの影響の狭い見方に支配されており、主に利益の最終ラインに焦点を当てています。ただし、より全体的なアプローチは、BUの相互接続性を認識しています
 5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM
5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM物事はその点に向かって着実に動いています。量子サービスプロバイダーとスタートアップに投資する投資は、業界がその重要性を理解していることを示しています。そして、その価値を示すために、現実世界のユースケースの数が増えています


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

Dreamweaver Mac版
ビジュアル Web 開発ツール

