
ホームページ >テクノロジー周辺機器 >AI >自動運転と軌道予測についてはこの記事を読めば十分です!
自動運転と軌道予測についてはこの記事を読めば十分です!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-28 19:20:031471ブラウズ
自動運転では軌道予測が重要な役割を果たします 自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。
導入関連の知識
1. プレビュー ペーパーにエントリーする順序はありますか?
A: まず、シーケンシャル ネットワーク、グラフ ニューラル ネットワーク、調査における評価、問題の定式化、深層学習ベースの手法を見てみましょう。
2. 挙動予測は軌道予測ですか?
カップリングと挙動は同じではありません。カップリングとは通常、ターゲット車両が実行する可能性のあるアクション (変更など) を指します。車線、駐車、追い越し、加速、左折、右折、直進。軌跡とは、将来の特定の位置を時間情報とともに参照する。
3. Argoverse データセットで言及されているデータ コンポーネントのうち、ラベルとターゲットは何を指しますか?ラベルは、予測される期間内のグラウンド トゥルースを参照していますか?
右側の表では、通常、OBJECT_TYPE 列は自動運転車自体を表します。データセットは通常、シーンごとに予測される 1 つ以上の障害物を指定し、予測されるこれらのターゲットはターゲットまたはフォーカル エージェントと呼ばれます。一部のデータセットは、車両、歩行者、自転車などの障害物ごとにセマンティック ラベルを提供します。
Q2: 車両と歩行者のデータ形式は同じですか?たとえば、1 つの点群ポイントが歩行者を表し、数十のポイントが車両を表すということですか?
A: この種の軌跡データ セットは、実際には、歩行者と車両の両方について、オブジェクトの中心点の xyz 座標を示します。
Q3: argo1 および argo2 データ セットのみが指定されています。 . 予測された障害物ですよね?マルチエージェント予測を行う場合にこれら 2 つのデータ セットを使用する方法
argo1 では障害物を 1 つだけ指定しますが、argo2 では 20 個もの障害物を指定できます。ただし、障害物が 1 つだけ指定されている場合でも、複数の障害物を予測するモデルの機能には影響しません。
4. 経路計画では通常、低速障害物と静的障害物が考慮されますが、軌道予測を組み合わせる役割は何ですか? ?主要なスナップショット?
A: 自車計画軌道として自車軌道を「予測」します。uniad
5 を参照できます。軌道予測は高い性能を持っています。車両ダイナミクスモデルの要件?正確な車両ダイナミクス モデルを確立するには、数学と自動車理論だけが必要ですか?
A: nn ネットワークは基本的に必要ありません、ルールベースにはある程度の知識が必要です
6. 漠然とした初心者ですが、どこから拡張すればよいですか? 知識 (理解できない)まだコードを書いてください)
A: まずレビューを読んで、「自動運転車の軌道予測のための機械学習: 包括的な調査、課題、および今後の研究の方向性」などのマインド マップを整理します。このレビューは、英語の原文をお読みください。
7. 予測と意思決定の関係は何ですか? なぜ予測はそれほど重要ではないと感じますか?
A1(stu): 默认预测属于感知吧,或者决策中隐含预测,反正没有预测不行。A2(stu): 决策该规控做,有行为规划,高级一点的就是做交互和博弈,有的公司会有单独的交互博弈组
8. 現在、大手企業の場合、一般的な予測は大きな認識モジュールに属するのでしょうか、それとも大きな規制モジュールに属するのでしょうか?
A: 他車の軌跡に基づいて予測を行い、自車の軌跡に基づいて制御を行いますが、両者の軌跡は相互に影響し合うため、規制に基づいて予測するのが一般的です。
Q: Xiaopeng の知覚 xnet などの一部の公開情報は、同時に予測軌跡を生成します。現時点では、予測作業は知覚モジュールの下に置かれているか、両方のモジュールにそれぞれの機能があるように感じます。モジュール、異なる目標?
A: それらは相互に影響を与えるため、予測と意思決定がグループになっている場合もあります。たとえば、自分の車が計画した軌道が他の車を圧迫することを目的としている場合、通常、他の車は道を譲ります。したがって、一部の作業では、独自の車両の計画を他の車両モデルの入力の一部とみなすことになります。 M2I (M2I: Factored Marginal Trajectory Prediction to Interactive Prediction) を参照してください。この記事にも同様のアイデアがあります。PiP のこのレーンについて学ぶことができます: Planning-informed Trajectory Prediction for Autonomous Driving 9.argoverse 車線のない交差点で中心線マップを取得するにはどうすればよいですか?
A: 手動でマークされます
10. 軌道予測を使用する場合論文を書くにはどこで入手できますか? この論文のコードはベースラインとして使用できますか?
A: hivt はベースラインとして使用でき、多くの人が使用しています
11. 現在、軌道予測は基本的にマップに依存していますが、新しいマップ環境に変更すると、元のモデルは適用されなくなり、再トレーニングが必要になりますか?
A: 一定の汎化能力があり、再学習しなくても効果は悪くない
12. マルチモーダル出力の場合、最適な軌道を選択する最も高い確率値に基づいて選択する時期は?
A(stu): 选择结果最好的Q2:结果最好是根据什么来判定呢?是根据概率值大小还是根据和gt的距离A: 实际在没有ground truth的情况下,你要取“最好”的轨迹,那只能选择相信预测概率值最大的那条轨迹了Q3: 那有gt的情况下,选择最好轨迹的时候,根据和gt之间的end point或者average都可以是吗A: 嗯嗯,看指标咋定义
軌道予測基本モジュール
1. Argoverse データセットで HD マップを使用する方法? 運転シーンを構築するための入力としてモーション予測と組み合わせることができますか?グラフ、異種グラフ どのように理解すればよいでしょうか?
A: それはすべてこのコースで説明されています。第 2 章を参照してください。第 4 章でも説明されます。異種グラフと同型グラフの違い: 同型グラフのノードの種類あるノードと別のノードの間には 1 種類の接続しかありません。たとえば、ソーシャル ネットワークでは、ノードには 1 種類の「人」しかなく、エッジには 1 種類の接続「知識」しかないことが想像できます。そして人々はお互いを知っているか、知らないかのどちらかです。ただし、人、いいね、ツイートをセグメント化することもできます。そして、知り合いを通じて人々がつながったり、ツイートの「いいね!」を通じて人々がつながったり、ツイートの「いいね!」を通じて人々がつながったりするかもしれません(メタパス)。ここで、ノードとノード間の関係を多様に表現するには、異種グラフの導入が必要です。異種グラフには、さまざまな種類のノードがあります。ノード間の接続関係(エッジ)にも多くの種類があり、それらの接続関係の組み合わせ(メタパス)にもさらに多くの種類があり、これらのノード間の関係は重要度によって分類され、接続関係の種類によって異なります。さまざまな重症度にも分類されます。
2.A-A インタラクションでは、どの車両が予測された車両とインタラクトするかを考慮しますか?
A: 特定の半径内の車を選択することも、K 台の最近隣車を考慮することもできます。より高度なヒューリスティック近隣車のスクリーニング戦略を自分で考え出すこともできます。モデルに自動的に学習させます。出てくる 2 台の車は隣接していますか?
Q2: 一定の範囲を考えてみましょう。半径を選択するための原則はありますか?さらに、選択された車両はどのタイム ステップで発生しましたか?
A: 半径の選択に対して標準的な答えを持つことは困難です。これは基本的に、予測を行う際にモデルがどれだけの遠隔情報を必要とするかを尋ねることになります。コンボリューション カーネルのサイズを選択するときの 2 番目の質問については、私の個人的なルールは、オブジェクト間の相互作用をモデル化したい場合は、その時点でのオブジェクトの相対位置に基づいて近傍を選択する必要があるということです。
Q3: この場合、歴史的な時間領域をモデル化する必要がありますか?特定の範囲内の周囲の車両も、異なるタイム ステップで変化します。それとも、現時点での周囲の車両情報のみを考慮すべきでしょうか?
A: いずれにせよ、モデルの設計方法によって異なります
3. 教師の uniad エンドツーエンド モデルの予測部分の欠陥は何ですか?
A: 見てください。モーション フォーマーの操作は比較的従来的なもので、多くの論文で同様の SA と CA が見られます。現在、多くの sota モデルは比較的重いです。たとえば、デコーダには巡回リファインが行われます。
A2: 実行されるのは結合予測ではなく周辺予測です。2. 予測と計画は、明示的に考慮することなく、個別に実行されます。エゴと周囲のエージェントのインタラクティブゲーム; 3. 対称性を考慮せずにシーン中心の表現が使用され、その効果は避けられません
Q2: 限界予測とは何ですか
A: 詳細については、お問い合わせください。シーントランスフォーマーを参照してください
Q3: 3 番目の点について、シーンセントリックは対称性を考慮していません。どのように理解すればよいですか?
A: HiVT、QCNet、MTR を見ることをお勧めします。もちろん、エンドツーエンドのモデルでは対称性が重要です。設計も簡単ではありません
A2: 入力がシーン データであることは理解できますが、ネットワーク内では次のようにモデル化されます。各ターゲットを中心的な視点として周囲のシーンを観察することで、次のことが可能になります。前方では、各ターゲットを中心としたコーディングを取得し、これらのコード間の相互作用を検討できます。
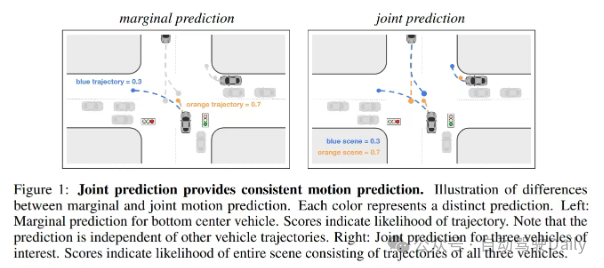
4. エージェントベースセンターとは何ですか?
A: 各エージェントには独自のローカル領域があり、そのローカル領域はこのエージェントを中心としています。
5. 軌道予測にはヨーとヘディングが混在していますか?
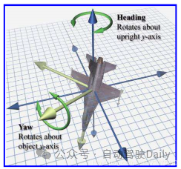
A: 車の前方の方向として理解できます
#6. の has_traffic_control 属性は何を意味しますかargument map means?
A: 実は、正しく理解できているかわかりませんが、ある車線が信号機/一時停止標識/速度制限標識の影響を受けるかどうかを指すのだと思いますが、 etc.
7. 軌道予測におけるラプラス損失とフーバー損失の長所と短所は何ですか? 1 つの車線ラインのみを予測する場合
A: 両方試してください。どちらがより効果的に機能するかには利点があります。ラプラス損失を効果的にするには、まだいくつかの詳細に注意する必要があります。
Q2: パラメーターを調整する必要があるということですか?
A: L1 損失との比較、ラプラス損失は実際にはもう 1 つのスケール パラメーターを予測します
Q3: はい、しかし、1 つの軌道しか予測しない場合、これが何の役に立つのかわかりません。冗長性のような気がします。不確実性として理解していますが、正しいかどうかはわかりません
A:如果你从零推导过最小二乘法就会知道,MSE其实是假设了方差为常数的高斯分布的NLL。同理,L1 loss也是假设了方差为常数的Laplace分布的NLL。所以说LaplaceNLL也可以理解为方差非定值的L1 loss。这个方差是模型自己预测出来的。为了使loss更低,模型会给那些拟合得不太好的样本一个比较大的方差,而给拟合得好的样本比较小的方差
Q4:那是不是可以理解为对于非常随机的数据集【轨迹数据存在缺帧 抖动】 就不太适合Laplace 因为模型需要去拟合这个方差?需要数据集质量比较高
A:这个说法我觉得不一定成立。从效果上来看,会鼓励模型优先学习比较容易拟合的样本,再去学习难学习的样本
Q5:还想请问下这句话(Laplace loss要效果好还是有些细节要注意的)如何理解 A:主要是预测scale那里。在模型上,预测location的分支和预测scale的分支要尽量解耦,不要让他们相互干扰。预测scale的分支要保证输出结果>0,一般人会用exp作为激活函数保证非负,但是我发现用ELU +1会更好。然后其实scale的下界最好不要是0,最好让scale>0.01或者>0.1啥的。以上都是个人看法。其实我开源的代码(周梓康大佬的github开源代码)里都有这些细节,不过可能大家不一定注意到。
给出链接:https://github.com/ZikangZhou/QCNet
https://github.com/ZikangZhou/HiVT
8. 有拿VAE做轨迹预测的吗,给个链接!
https://github.com/L1aoXingyu/pytorch-beginner/tree/master/08-AutoEncoder
9. 请问大伙一个问题,就是Polyline到底是啥?另外说polyline由向量Vector组成,这些Vector是相当于节点吗?
A:Polyline就是折线,折线就是一段一段的,每一段都可以看成是一段向量Q2:请问这个折线段和图神经网络的节点之间的边有关系吗?或者说Polyline这个折现向量相当于是图神经网络当中的节点还是边呀?A:一根折线可以理解为一个节点。轨迹预测里面没有明确定义的边,边如何定义取决于你怎么理解这个问题。Q3: VectorNet里面有很多个子图,每个子图下面有很多个Polyline,把Polyline当做向量的话,就相当于把Polyline这个节点变成了向量,相当于将节点进行特征向量化对吗?然后Polyline里面有多个Vector向量,就是相当于是构成这个节点的特征矩阵么?A: 一个地图里有很多条polyline;一个Polyline就是一个子图;一个polyline由很多段比较短的向量组成,每一段向量都是子图上的一个节点
10. 有的论文,像multipath++对于地图两个点就作为一个单元,有的像vectornet是一条线作为一个单元,这两种有什么区别吗?
A: 节点的粒度不同,要说效果的话那得看具体实现;速度的话,显然粒度越粗效率越高Q2:从效果角度看,什么时候选用哪种有没有什么原则?A: 没有原则,都可以尝试
11. スコアの滑らかさを判断する方法はありますか? どうしてもそうしなければならない場合は、
#A: 0 ~ 19 や 0 ~ 19 などの入力を入力する必要があります。 1-20 次に、フレームは 2 つのフレーム間の対応する軌跡のスコアの差の 2 乗と比較され、統計だけで十分です。Q2: トーマス氏が推奨するインジケーターは何ですか? 私が現在使用しているインジケーターを最初に挙げます。 1次導関数と2次導関数。しかし、それはあまり明らかではないようで、ほとんどの 1 次微分値と 2 次微分値は 0 付近に集中しています。 A: 連続したフレームの対応する軌跡のスコアの差の二乗で十分だと思うのですが、例えば連続した入力がn個あった場合、それらを合計してnで割ります。ただし、シーンはリアルタイムで変化するため、インタラクションが発生したり、交差点以外から交差点に移動したりするときにスコアが突然変化するはずです。 、×0.01 10? のような。分布は可能な限り 0 に近づきます。見かけたら使うだけで、使わない方法もあります。トレードオフを定義するにはどうすればよいですか?#A: データを標準化するだけです。多少は役立つかもしれませんが、おそらくあまり役に立たないでしょう13. HiVT のマップのカテゴリ属性が、埋め込み後に concat ではなく数値属性に追加されるのはなぜですか?
A: 加算と連結には大きな違いはありませんが、カテゴリ埋め込みと数値埋め込みの融合に関しては、実際には完全に同等ですQ2: 完全をどのように理解すればよいですか等価?
A: 2 つを連結してから線形レイヤーを通過させることは、実際には線形レイヤーを通じて値を埋め込み、線形レイヤーを通じてカテゴリを埋め込んでから 2 つを加算することと同じです。実際には意味がありません。線形レイヤーを介してカテゴリを埋め込む理論的には、この線形レイヤーは nn.Embeddding14 のパラメーターと統合できます。ユーザーとしては、HiVT の方が気になるかもしれません。実際の導入に必要なハードウェア要件は?
A: わかりませんが、私が得た情報によると、歩行者予測に HiVT を使用しているのが NV なのか、どの自動車メーカーなのかはわかりません。したがって、実際の導入は間違いなく実現可能です15. 職業ネットワークに基づく予測について何か特別なことはありますか?何かお勧めの紙はありますか?
A: 職業に基づいた現在の将来予測ソリューションの中で、最も有望なものはこれです: https://arxiv.org/abs/2308.0147116. 計画軌道の予測を考慮した推奨論文はありますか?他の障害物を予測する際に自車の計画軌道を考慮するためでしょうか?
A: この潜在的に公開されているデータセットは困難であり、通常、あなた自身の車両の計画された軌道を提供しません。昔、PiP、香港柯好蘭歌という記事がありました。 M2I17 など、条件付き予測に関する記事は何でも考えられると思います。予測アルゴリズムのパフォーマンス テストに適した、学習や参考にできるシミュレーション プロジェクトはありますか?
A(stu): この論文について説明します: シミュレータを賢く選択する 自動運転用オープンソース シミュレータのレビュー18. GPU メモリの量を見積もる方法必要ですか?使用する場合、Argoverse データ セットの場合、どのように計算されますか? /mp.weixin.qq.com/s/EEkr8g4w0s2zhS_jmczUiA
以上が自動運転と軌道予測についてはこの記事を読めば十分です!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。