
ホームページ >ソフトウェアチュートリアル >オフィスソフトウェア >PDF から 1 つ以上のページを抽出し、新しい PDF として保存します
PDF から 1 つ以上のページを抽出し、新しい PDF として保存します

- 王林転載
- 2024-02-18 13:18:07799ブラウズ
php editor Strawberry は今日、Python を使用して PDF から 1 つまたは複数のページを抽出し、新しい PDF ファイルとして保存する方法を紹介します。実際の業務でもよく使われる機能で、特にPDF文書を整理する必要がある場合に効率化が図れます。続いて、具体的な手順を見ていきましょう!
方法 1: ブラウザを使用する
edge や chrome などの一般的なブラウザが使用できます。抽出する必要がある PDF ドキュメントを右クリックし、[プログラムから開く] を選択してブラウザを選択します。ここではエッジ ブラウザを使用します。
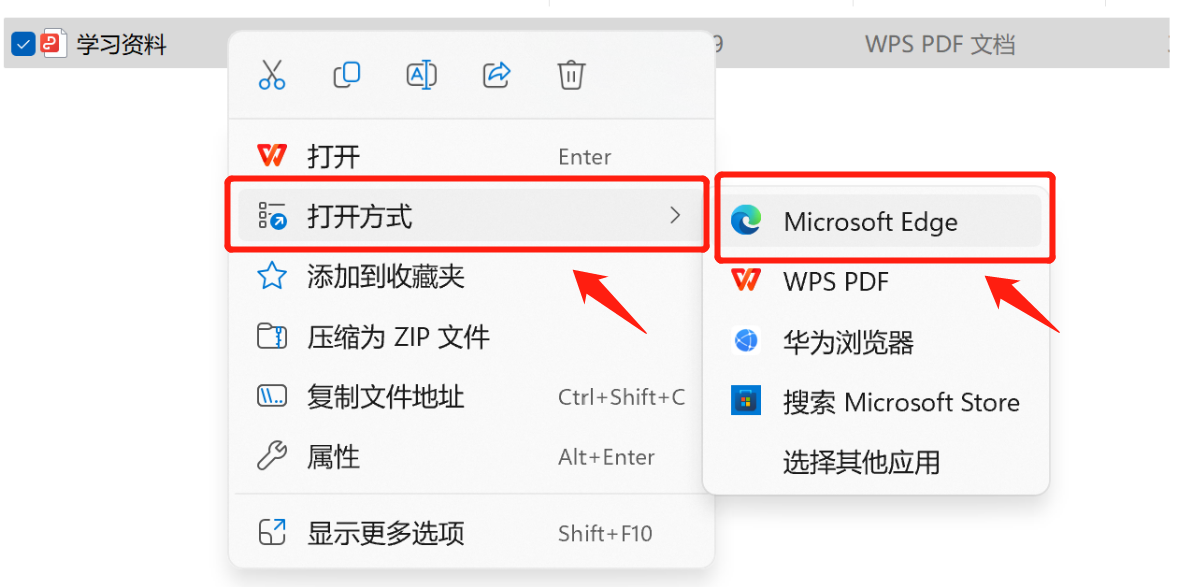
PDF ドキュメントをブラウザで開いた後、右上隅にあるプリンター アイコンをクリックします。
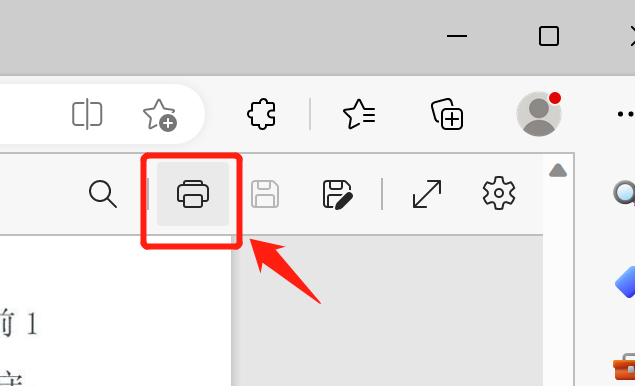
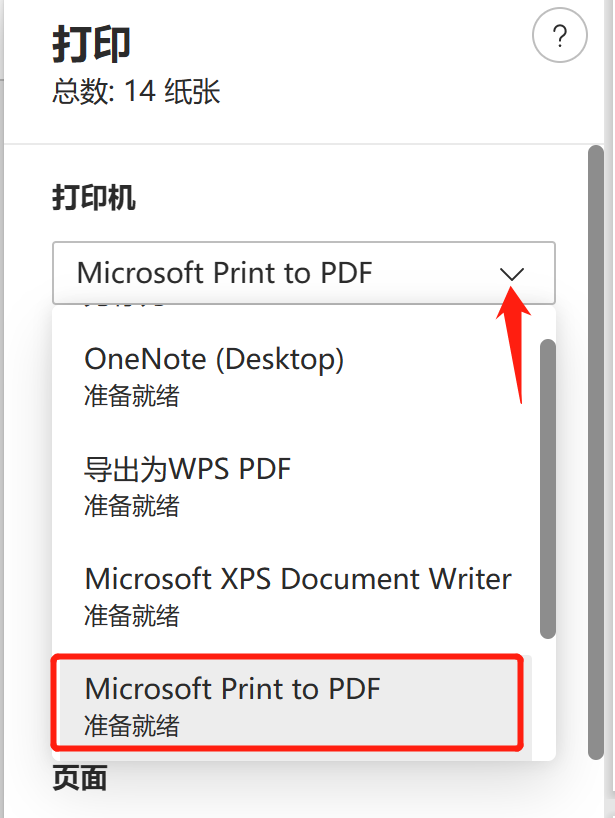
左側に表示される印刷設定インターフェイスで、ターゲット プリンターを「Microsoft Print to PDF」/「PDF として保存」として選択します。
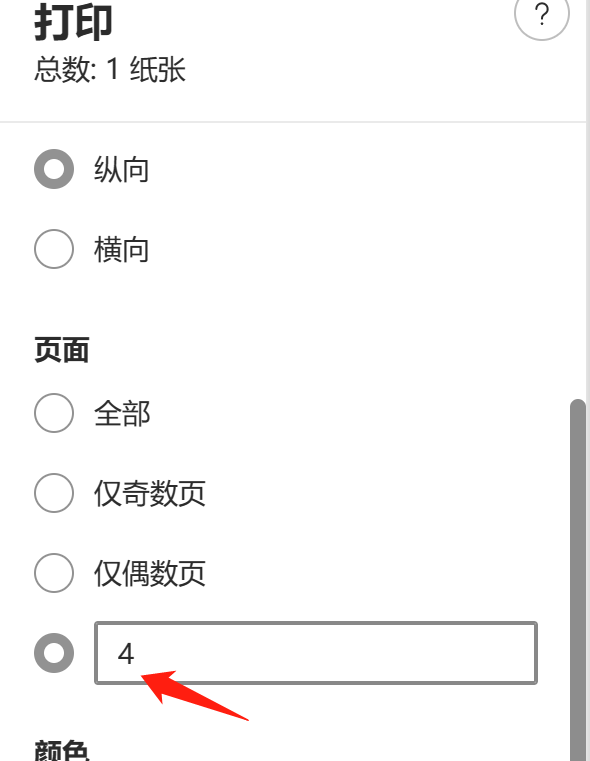
印刷「ページ」を抽出する必要があるページに設定し、「保存」をクリックして別のページを取得します。
方法 2: 専門的な PDF ツールを使用する
最も速くて簡単な方法は、Pepsi Niu PDF 変換ツールの「PDF 分割」機能を使用することです。
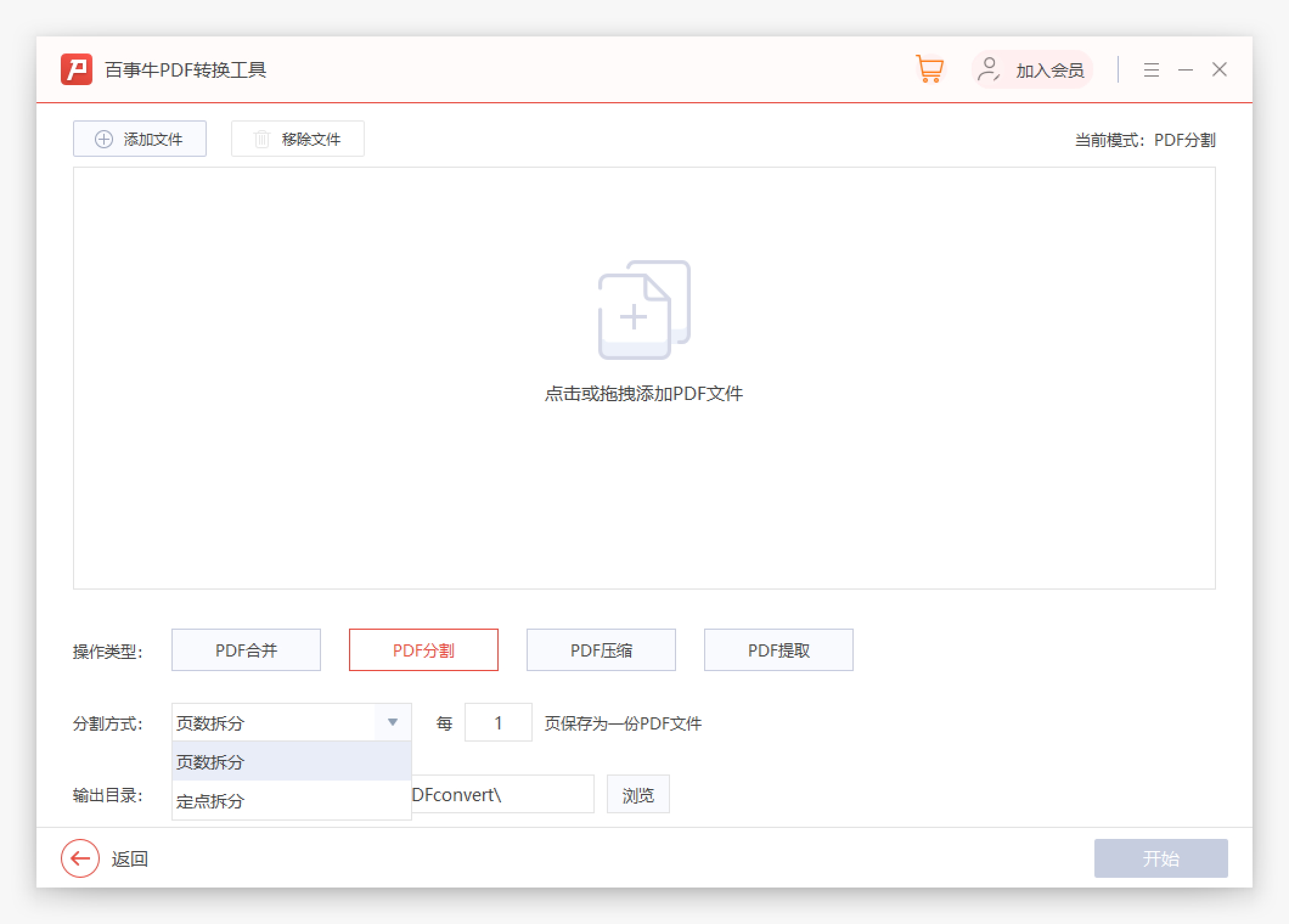
Pepsi Niu PDF 変換ツールの PDF 分割インターフェイスで、抽出する必要がある PDF ドキュメントを追加します。必要に応じて、「ページ番号」または「固定小数点分割」で分割することを選択できます。ページ分割: 分割各ページを新しい PDF ドキュメントに分割します。 固定小数点分割: 指定されたページ番号のページを新しい PDF ドキュメントに分割します。
Pepsi Niu PDF 変換ツール公式ダウンロード アドレス: https://dl.passneo.cn/down/down?path=passneo_pdf_converter_setup.exe
以上がPDF から 1 つ以上のページを抽出し、新しい PDF として保存しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。