
ホームページ >テクノロジー周辺機器 >AI >RAGか微調整か? Microsoft は、特定の分野における大規模モデル アプリケーションの構築プロセスに関するガイドをリリースしました
RAGか微調整か? Microsoft は、特定の分野における大規模モデル アプリケーションの構築プロセスに関するガイドをリリースしました

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-16 18:48:261396ブラウズ
検索拡張生成 (RAG) と微調整 (ファインチューニング) は、大規模な言語モデルのパフォーマンスを向上させる 2 つの一般的な方法ですが、どちらの方法が優れているのでしょうか?特定のドメインでアプリケーションを構築する場合、どちらがより効率的ですか? Microsoft のこのペーパーは、選択する際の参考になります。
大規模な言語モデル アプリケーションを構築する場合、独自のドメイン固有データを組み込むために、検索強化の生成と微調整という 2 つのアプローチがよく使用されます。検索強化生成では、外部データを導入することでモデルの生成機能が強化され、微調整によって追加の知識がモデル自体に組み込まれます。しかし、これら 2 つのアプローチの長所と短所については十分に理解されていません。
この記事では、マイクロソフトの研究者によって提案された新しい焦点を紹介します。それは、農業業界向けに特定のコンテキストと適応応答機能を備えた AI アシスタントを作成することです。包括的な大規模言語モデル プロセスを導入することにより、高品質で業界固有の質問と回答を生成できます。このプロセスは、広範囲の農業トピックをカバーする関連文書の特定と収集から始まる体系的な一連のステップで構成されています。これらの文書はその後、基本的な GPT モデルを使用して意味のある質問と回答のペアを生成するために整理および構造化されます。最後に、生成された質問と回答のペアが評価され、その品質に基づいてフィルタリングされます。このアプローチは、農業従事者や関連実務者がさまざまな問題や課題に適切に対処できるようにするための、正確かつ実践的な情報を提供できる強力なツールを農業業界に提供します。
この記事は、農業をケーススタディとして使用し、農業業界にとって貴重な知識リソースを作成することを目的としています。その最終目標は、農業分野におけるLLMの発展に貢献することです。

論文のアドレス: https://arxiv.org/pdf/2401.08406.pdf
論文タイトル: RAG と微調整: パイプライン、トレードオフ、および農業に関するケーススタディ
この記事のプロセスの目標は、特定の業界のニーズを満たすドメイン固有の質問を生成することです。専門家と関係者、そして答え。この業界では、AI アシスタントに期待される回答は、関連する業界固有の要素に基づいている必要があります。
この記事は農業研究を扱い、その目的はこの特定の分野で答えを生み出すことです。したがって、研究の開始点は農業データセットであり、このデータセットは、質問生成、検索強化生成、および微調整プロセスという 3 つの主要コンポーネントに供給されます。質問と回答の生成では、農業データセット内の情報に基づいて質問と回答のペアが作成され、検索拡張生成ではそれが知識源として使用されます。生成されたデータは洗練され、複数のモデルを微調整するために使用され、その品質は提案された一連の指標を通じて評価されます。この包括的なアプローチを通じて、大規模な言語モデルの力を活用して、農業業界やその他の利害関係者に利益をもたらします。
この記事は、農業分野における大規模言語モデルの理解に特別な貢献をしました。これらの貢献は次のように要約できます:
1, LLM の包括的な評価: この記事 LlaMa2-13B、GPT-4、Vicuna などの大規模な言語モデルは、農業関連の質問に答えるために広範囲に評価されています。評価には主要な農業生産国のベンチマーク データセットが使用されました。この分析では、GPT-4 は他のモデルよりも常に優れていますが、微調整と推論に関連するコストを考慮する必要があります。
2. 検索テクノロジーと微調整がパフォーマンスに及ぼす影響: この記事では、LLM のパフォーマンスに対する検索テクノロジーと微調整の影響について調査します。研究により、検索強化の生成と微調整の両方が LLM のパフォーマンスを向上させる効果的な手法であることが判明しました。
3. さまざまな業界における LLM の潜在的なアプリケーションの影響: LLM に RAG および微調整テクノロジーを適用するプロセスを確立したい人にとって、この記事は先駆的なものです。ステップと複数の業界にわたるイノベーションとコラボレーションを促進します。
方法
この記事のパート 2 では、データ取得プロセス、情報抽出プロセス、質問と回答の生成、およびデータの微調整など、採用された方法論について詳しく説明します。モデル。この方法論は、以下の図 1 に示すように、ドメイン固有のアシスタントを構築するための質問と回答のペアを生成および評価するように設計されたプロセスを中心に展開します。
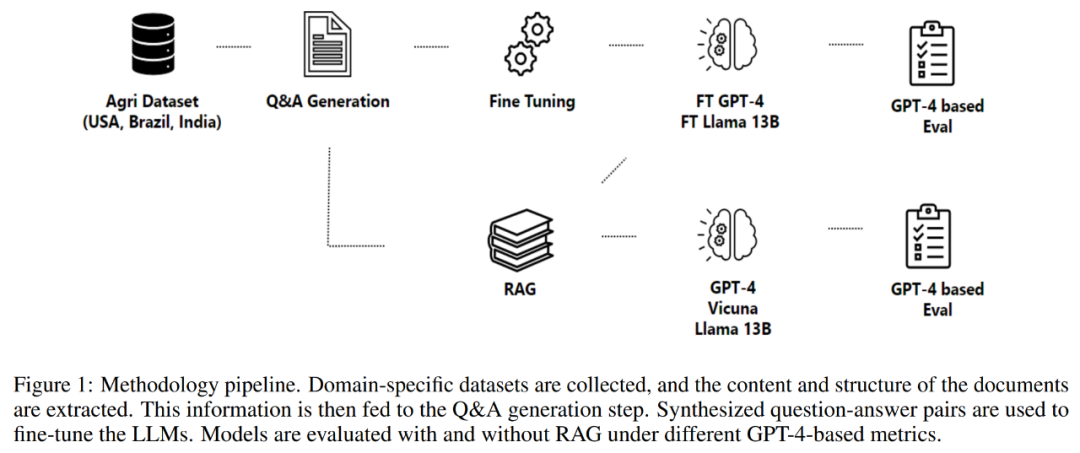
プロセスはデータ取得から始まります。これには、政府機関、科学知識データベースなどのさまざまな高品質リポジトリからのデータの取得や、必要に応じて独自のデータの使用が含まれます。 。
データ取得の完了後、プロセスは収集されたドキュメントから情報を抽出し続けます。このステップは、複雑で構造化されていない PDF ファイルを解析してコンテンツと構造を復元する必要があるため、非常に重要です。以下の図 2 は、データセットからの PDF ファイルの例を示しています。

プロセスの次のコンポーネントは、質問と回答の生成です。ここでの目標は、抽出されたテキストの内容を正確に反映する、コンテキストベースの高品質な質問を生成することです。この方法では、入力と出力の構造的構成を制御するフレームワークを採用し、それによって言語モデルによって生成される応答の全体的な効果を高めます。
その後、このプロセスにより、定式化された質問に対する回答が生成されます。ここで採用されたアプローチは、検索強化生成を活用し、検索メカニズムと生成メカニズムの機能を組み合わせて高品質の回答を作成します。
最後に、このプロセスでは Q&A を通じてモデルを微調整します。最適化プロセスでは、低ランク調整 (LoRA) などの方法を使用して科学文献の内容とコンテキストを包括的に理解し、科学文献をさまざまな分野や業界で貴重なリソースにしています。
データセット
この研究では、三大作物生産から得られたコンテキスト関連の質問と回答のデータセットを使用して、生成された言語モデルを微調整および検索強化によって評価します。国:米国、ブラジル、インド。この記事の場合、産業背景として農業が使用されています。利用可能なデータは、規制文書から科学レポート、農学検査、知識データベースに至るまで、その形式と内容が多岐にわたります。
この記事は、米国農務省、州農業および消費者サービス機関などからの公開されているオンライン文書、マニュアル、レポートから情報を収集したものです。
利用可能な文書には、作物と家畜の管理、病気とベストプラクティス、品質保証と輸出規制、支援プログラムの詳細、保険と価格設定に関する連邦規制と政策情報が含まれます。収集されたデータは、米国 44 州をカバーする合計 23,000 を超える PDF ファイルに含まれ、5,000 万以上のトークンが含まれています。研究者らはこれらのファイルをダウンロードして前処理し、質問と回答の生成プロセスへの入力として使用できるテキスト情報を抽出しました。
モデルのベンチマークと評価のために、このペーパーではワシントン州に関連するドキュメントを使用します。これには、200 万以上のトークンを含む 573 個のファイルが含まれます。以下のリスト 5 は、これらのファイルの内容の例を示しています。

メトリクス
このセクションの主な目的は、質問と解決策を導くことを目的とした包括的なメトリクスのセットを確立することです。回答生成プロセス 特に微調整および検索強化生成方法の品質評価。
メトリクスを作成するときは、いくつかの重要な要素を考慮する必要があります。まず、質問の質に固有の主観性が大きな課題を引き起こします。
第二に、指標では問題の関連性と実用性のコンテキストへの依存性を考慮する必要があります。
第三に、生成された質問の多様性と新規性を評価する必要があります。強力な質問生成システムは、特定のコンテンツのあらゆる側面をカバーする幅広い質問を生成できる必要があります。ただし、多様性と新規性を定量化することは、質問の独自性とコンテンツや他の生成された質問との類似性を評価する必要があるため、困難な場合があります。
最後に、良い質問には、提供されたコンテンツに基づいて回答できる必要があります。入手可能な情報を使用して質問に正確に回答できるかどうかを評価するには、内容を深く理解し、質問に回答するための関連情報を特定する能力が必要です。
これらのメトリクスは、モデルによって提供される回答が質問に対して正確、適切かつ効果的に回答されることを保証する上で重要な役割を果たします。しかし、質問の質を評価するために特別に設計された指標が大幅に不足しています。
この不足を認識して、この文書では質問の質を評価するために設計された指標の開発に焦点を当てます。有意義な会話を促進し、有用な回答を生成するという質問の重要な役割を考えると、質問の品質を確保することは、回答の品質を確保することと同じくらい重要です。
この記事で開発された指標は、この分野における以前の研究のギャップを埋め、質問と回答の生成プロセスの進行に大きな影響を与える質問の質を包括的に評価する手段を提供することを目的としています。
問題の評価
問題を評価するためにこの文書で開発された指標は次のとおりです:
-
関連性
グローバルな相関関係
カバレッジ
重複
多様性
詳細レベル
流暢さ
回答評価
大規模な言語モデルは、長く詳細で有益な会話応答を生成する傾向があるため、生成される応答を評価するのは困難です。
この記事では、AzureML モデルの評価を使用し、次のメトリックを使用して、生成された回答を実際の状況と比較します。
一貫性: コンテキストを考慮して、実際の回答と実際の回答の間の一貫性を比較します。状況と予想。
関連性: 回答が文脈の中で質問の主な側面にどれだけ効果的に答えているかを測定します。
信頼性: 回答がコンテキストに含まれる情報に論理的に適合するかどうかを定義し、回答の信頼性を判断するための整数スコアを提供します。
#モデルの評価
さまざまな微調整されたモデルを評価するために、この記事では評価ツールとして GPT-4 を使用します。 GPT-4 を実世界のデータセットとして使用し、農業文書から約 270 の質問と回答のペアが生成されました。微調整されたモデルと検索拡張された生成モデルごとに、これらの質問に対する答えが生成されます。
この記事では、いくつかの異なる指標で LLM を評価します:
ガイドラインによる評価 : 各 Q&A ペアについて、このペーパーは GPT-4 に次の生成を促します。正解に含まれる内容をリストした評価ガイド。次に GPT-4 は、評価ガイドの基準に基づいて各回答を 0 から 1 のスケールで採点するよう求められました。以下に例を示します。
簡潔さ : 簡潔で長い回答に含まれる内容を説明するルーブリックが作成されました。このルーブリック、実際の状況の回答、LLM の回答プロンプトに基づいて、GPT-4 を 1 から 5 のスケールで評価するように求められます。
正解度 : この記事では、完全な解答、部分的に正しい解答、または不正解の解答に何を含めるべきかを説明するルーブリックを作成します。このルーブリック、実際の状況の回答、LLM の回答プロンプトに基づいて、GPT-4 は正しい、間違っている、または部分的に正しい評価を求められます。
実験
この記事の実験はいくつかの独立した実験に分かれており、それぞれが質問と回答の生成と評価に焦点を当てています。検索の強化 生成と微調整の具体的な側面。
これらの実験では、次の領域を調査します:
Q&A の品質
コンテキスト リサーチ
-
モデルからメトリックへの計算
複合世代と個別世代の比較
アブレーション研究の取得
-
微調整
質問と回答の質
この実験では、GPT-3、GPT-3.5 という 3 つの大きな言語モデルを評価しました。 GPT-4。さまざまなコンテキスト設定の下で生成された質問と回答のペアの品質。品質評価は、関連性、対象範囲、重複、多様性などの複数の指標に基づいています。
コンテキスト調査
この実験では、モデルで生成された質問と回答のパフォーマンスに対するさまざまなコンテキスト設定の影響を調査します。生成された質問と回答のペアは、コンテキストなし、コンテキスト、外部コンテキストという 3 つのコンテキスト設定の下で評価されます。例を表 12 に示します。

コンテキストフリー設定では、GPT-4 は 3 つのモデルの中で最も高いカバレッジとサイズのヒントを持ち、より多くのテキスト部分をカバーできることを示していますが、結果として生じる質問より長いです。ただし、3 つのモデルは、多様性、重複、関連性、流暢さに関して同様の数値を示しています。
コンテキストが含まれる場合、GPT-3.5 は GPT-3 と比較してカバレッジがわずかに増加しますが、GPT-4 は最高のカバレッジを維持します。サイズ プロンプトでは、GPT-4 の値が最も大きく、より長い質問と回答を生成できることを示しています。
多様性と重複という点では、3 つのモデルは同様に機能します。関連性と流暢性に関しては、GPT-4 は他のモデルと比較してわずかに増加しています。
外部コンテキスト設定でも、同様の状況が発生します。
さらに、各モデルを見ると、平均カバレッジ、多様性、重複、関連性、流暢さの点でコンテキストフリー設定が GPT-4 に最適なバランスを提供しているように見えますが、結果として生じる質問と回答はペアが短くなります。コンテキスト設定により、質問と回答のペアが長くなり、サイズを除く他の指標がわずかに減少しました。外部コンテキスト設定では、最も長い質問と回答のペアが生成されましたが、平均範囲は維持され、平均関連性と流暢性はわずかに向上しました。
全体として、GPT-4 の場合、コンテキストフリー設定は、平均範囲、多様性、重複、関連性、流暢さの点で最適なバランスを提供しているように見えますが、生成される回答は短くなります。コンテキスト設定により、プロンプトが長くなり、他の指標がわずかに減少しました。外部コンテキスト設定では、最も長いプロンプトが生成されましたが、平均範囲は維持され、平均関連性と流暢性はわずかに向上しました。
したがって、これら 3 つのうちの選択は、タスクの特定の要件によって異なります。プロンプトの長さを考慮しない場合は、関連性と流暢さのスコアが高いため、外部コンテキストが最良の選択となる可能性があります。
モデルからメトリックへの計算
この実験では、質問と回答のペアの品質を評価するために使用されるメトリックの計算における GPT-3.5 と GPT-4 のパフォーマンスを比較します。
全体として、GPT-4 は生成された質問と回答のペアをより流暢で文脈的に信頼できるものとして評価しますが、GPT-3.5 の評価よりも多様性や関連性が低くなります。これらの視点は、さまざまなモデルが生成されたコンテンツの品質をどのように認識し、評価するかを理解するために重要です。
結合生成と個別生成の比較
この実験では、質問と回答を個別に生成する場合と、質問と回答を組み合わせて生成する場合の利点と欠点を調査し、次の点に焦点を当てます。トークンの利用効率の比較。
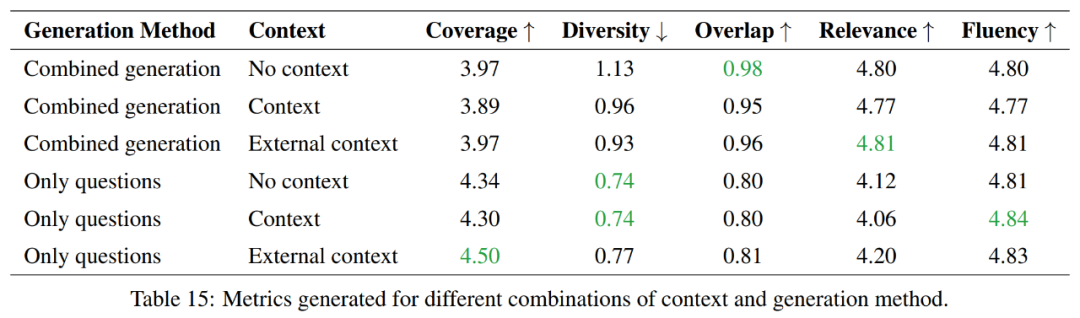
全体として、質問生成のみの方法はより良い範囲を提供し、多様性は低いですが、組み合わせた生成方法は重複と相関の点でより高いスコアをもたらします。流暢さの点では、どちらの方法も同様に機能します。したがって、これら 2 つの方法のどちらを選択するかは、タスクの特定の要件によって異なります。
より多くの情報を網羅し、より多様性を維持することが目標の場合は、質問生成のみのアプローチが推奨されます。ただし、ソースマテリアルとの高度な重複を維持する必要がある場合は、複合生成アプローチの方が良い選択になります。
検索アブレーション研究
この実験では、質問応答中に追加のコンテキストを提供することで LLM の固有の知識を強化する方法である検索強化によって生成された検索能力を評価します。 。
この論文では、取得されたフラグメントの数 (つまり、上位 k) が結果に及ぼす影響を調査し、その結果を表 16 に示します。より多くのフラグメントを考慮することにより、検索強化生成では、より一貫して元の抜粋を復元できます。
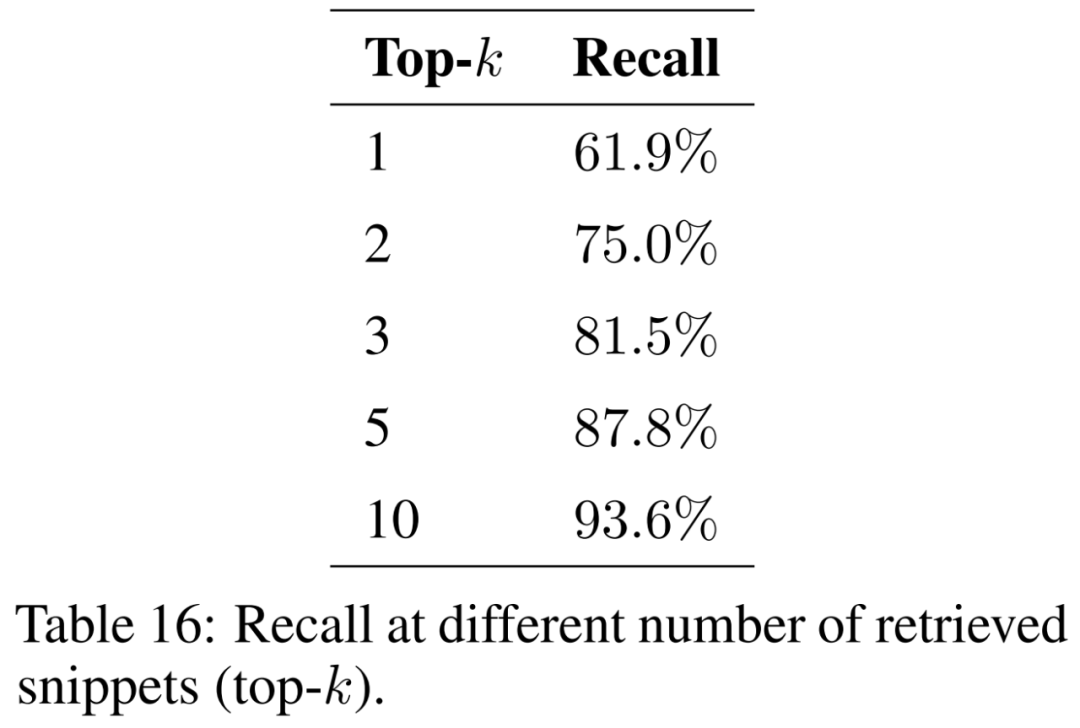
モデルがさまざまな地理的状況や現象からの質問を確実に処理できるようにするには、さまざまなトピックをカバーするようにサポート文書のコーパスを拡張する必要があります。考慮されるドキュメントが増えるにつれて、インデックスのサイズが増加することが予想されます。これにより、検索中に類似したセグメント間の衝突の数が増加し、入力された質問に関連する情報を回復する能力が妨げられ、再現率が低下する可能性があります。
微調整
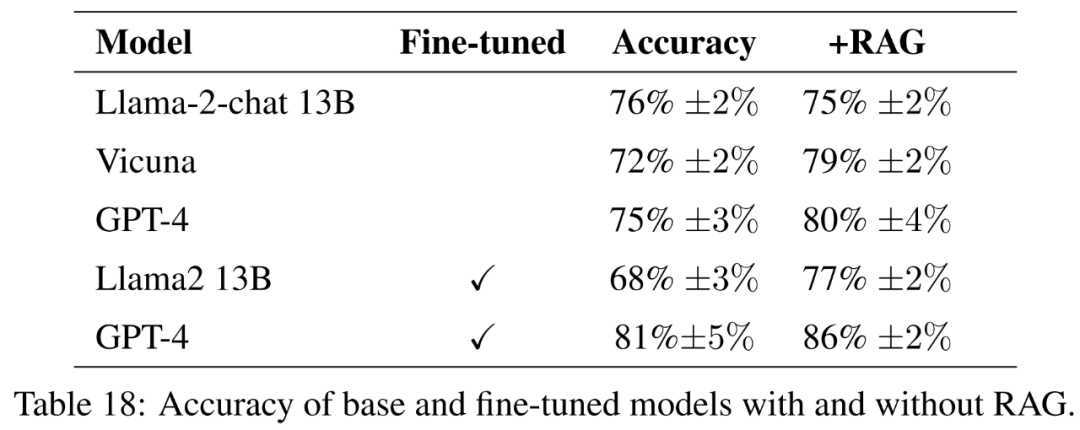
この実験では、微調整モデルと基本命令微調整モデルのパフォーマンスの違いを評価します。目標は、モデルが新しい知識を学習できるように微調整する可能性を理解することです。
基本モデルとして、この記事ではオープン ソース モデル Llama2-13B-chat および Vicuna-13B-v1.5-16k を評価します。これら 2 つのモデルは比較的小さく、計算とパフォーマンスの間の興味深いトレードオフを表しています。どちらのモデルも、異なる方法を使用して Llama2-13B を微調整したバージョンです。
Llama2-13B チャットは、教師あり微調整と強化学習を介して命令の微調整を実行します。 Vicuna-13B-v1.5-16k は、ShareGPT データセットでの教師あり微調整による命令の微調整バージョンです。さらに、この論文では、ベース GPT-4 を、より大きく、より高価で、より強力な代替品として評価しています。
微調整モデルについては、この文書では、農業データに基づいて Llama2-13B を直接微調整し、そのパフォーマンスを、より一般的なタスク向けに微調整された同様のモデルと比較します。この論文では、GPT-4 を微調整して、非常に大規模なモデルでも微調整が依然として役立つかどうかを評価します。ガイドラインによる評価結果を表 18 に示します。
#応答の品質を完全に測定するために、正確さに加えて、この記事では応答の簡潔さも評価します。
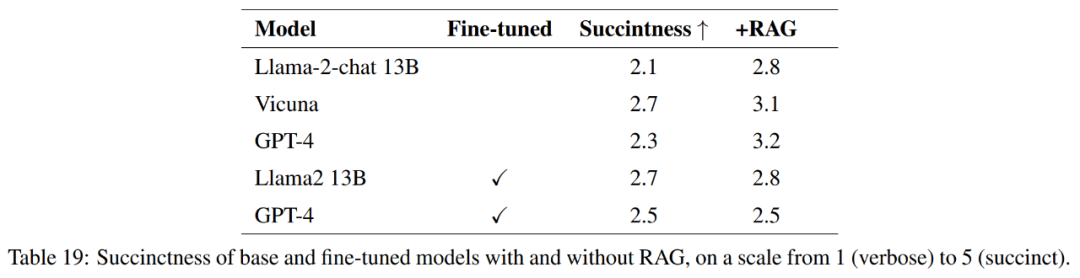
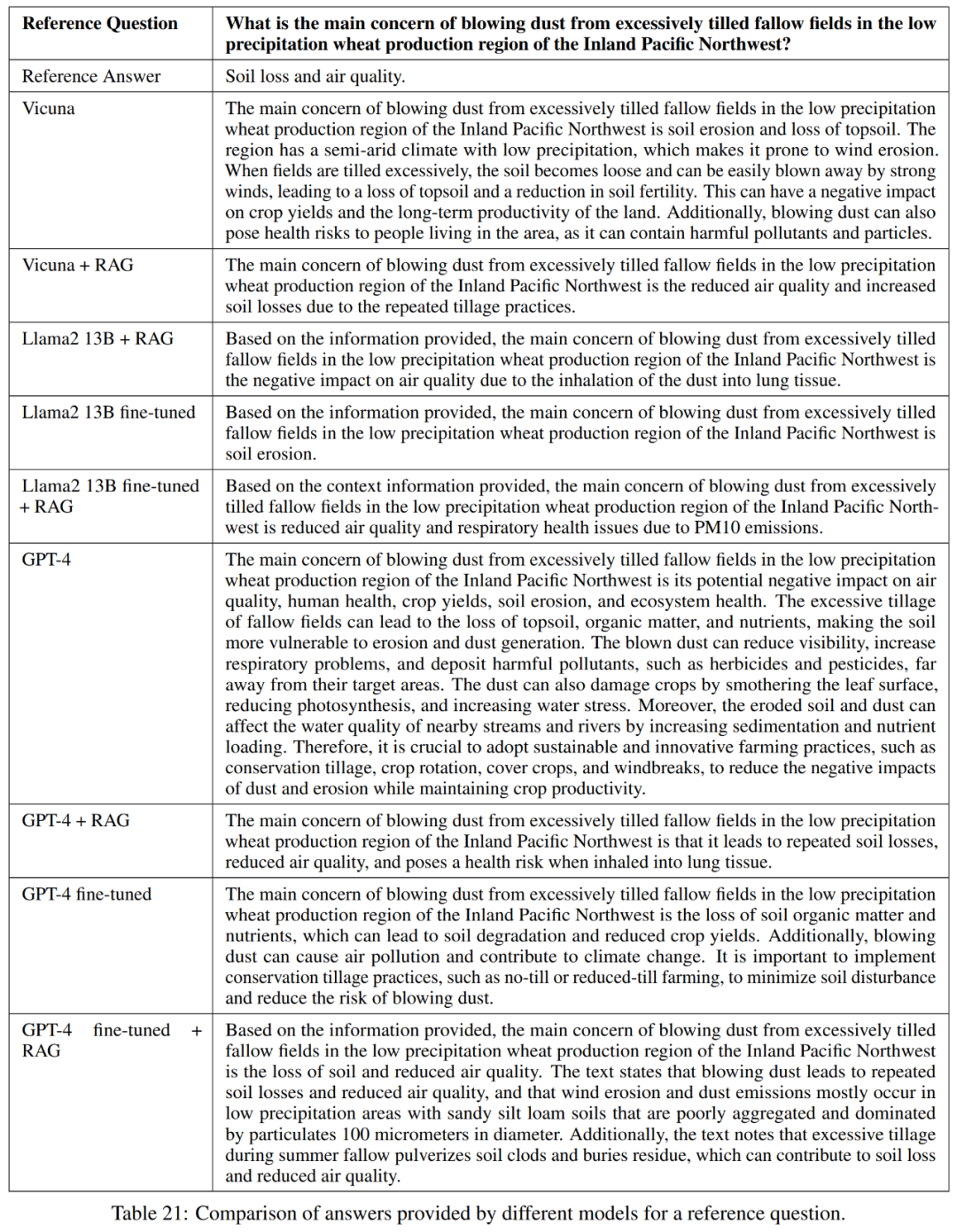
#表 21 に示すように、これらのモデルは常に質問に対する完全な答えを提供するとは限りません。たとえば、一部の回答では土壌浸食が問題であると指摘されていますが、大気の質については言及されていませんでした。
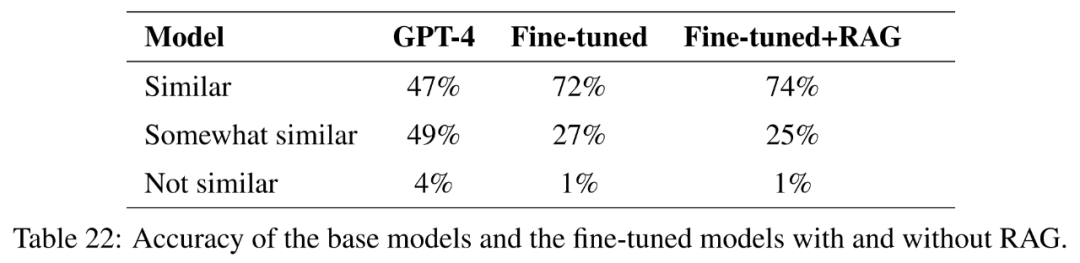
全体として、参照回答を正確かつ簡潔に回答するという点で最もパフォーマンスの高いモデルは、Vicuna 検索強化生成、GPT-4 検索強化生成、GPT-4 微調整、および GPT-4 微調整です。検索 拡張生成。これらのモデルは、正確さ、シンプルさ、情報の深さのバランスが取れたブレンドを提供します。
知識発見
この論文の研究目標は、GPT-4 の学習を支援する微調整の可能性を探ることです。応用に役立つ新しい知識 研究は非常に重要です。
これをテストするために、この記事では米国 50 州のうち少なくとも 3 つの州で類似した質問を選択しました。次に、埋め込みのコサイン類似性が計算され、1000 個のそのような質問のリストが特定されました。これらの質問はトレーニング セットから削除され、微調整と検索強化生成による微調整を使用して、GPT-4 が異なる状態間の類似性に基づいて新しい知識を学習できるかどうかを評価します。
その他の実験結果については、元の論文を参照してください。
以上がRAGか微調整か? Microsoft は、特定の分野における大規模モデル アプリケーションの構築プロセスに関するガイドをリリースしましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。