
ホームページ >テクノロジー周辺機器 >AI >ICLR 2024 | 初のゼロ次最適化深層学習フレームワーク、MSU と LLNL が DeepZero を提案
ICLR 2024 | 初のゼロ次最適化深層学習フレームワーク、MSU と LLNL が DeepZero を提案

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-15 18:39:09806ブラウズ
この記事は、ゼロ次最適化のスケーラビリティの向上に関する研究であり、コードはオープンソースであり、論文は ICLR 2024 に受理されました。
今日は、ミシガン州立大学とローレンス リバモア国立研究所の共同研究による「DeepZero: Scaling up Zeroth-Order Optimization for Deep Model Training」というタイトルの論文を紹介します。この論文は最近 ICLR 2024 会議で採択され、研究チームはコードをオープンソース化しました。 このペーパーの主な目的は、深層学習モデルのトレーニングにおけるゼロ次最適化手法を拡張することです。 0 次最適化は、勾配情報に依存せず、高次元のパラメーター空間や複雑なモデル構造をより適切に処理できる最適化手法です。ただし、既存のゼロ次最適化手法は、深層学習モデルを扱う際に規模と効率の課題に直面しています。 これらの課題に対処するために、研究チームは DeepZero フレームワークを提案しました。このフレームワークは、新しいサンプリング戦略と適応調整メカニズムを導入することにより、大規模な深層学習モデルのトレーニングを効率的に処理できます。 DeepZero はゼロ次最適化を利用し、分散コンピューティングと並列化技術を組み合わせて、

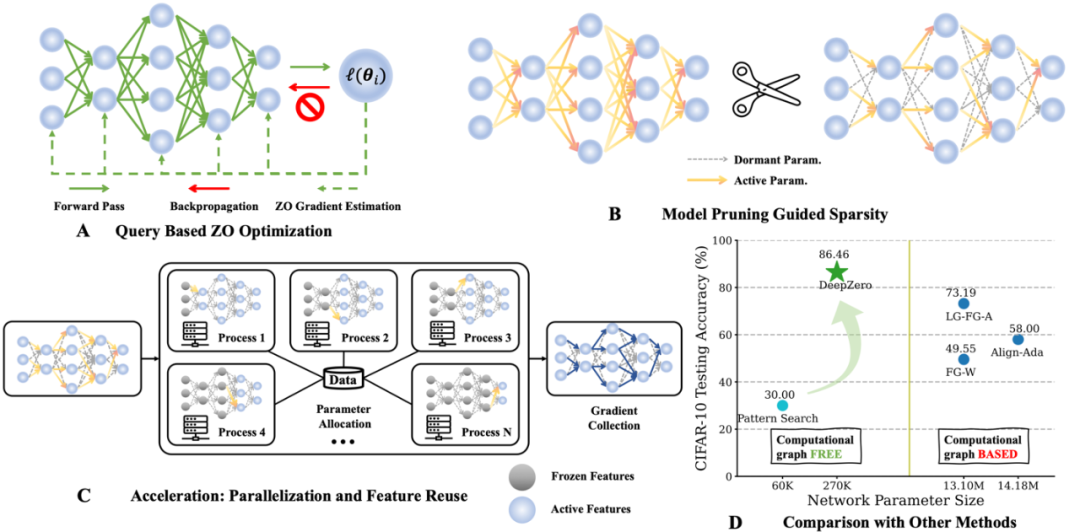
Paper でのトレーニングを高速化します。アドレス: https://arxiv.org/abs/2310.02025
プロジェクト アドレス: https://www.optml-group.com/posts/deepzero_iclr24
1. 背景
ゼロ次 (ZO) 最適化は、機械学習 (機械学習) の問題を解決するための一般的なテクノロジとなっています。 (FO) 情報の入手が困難または不可能:
物理学、化学およびその他の分野: 機械学習モデルは、複雑なシミュレーターまたは実験的相互作用に関連している可能性があります。基礎となるシステムは微分可能ではありません。
ブラック ボックス学習シナリオ : ブラック ボックス ディープに対する敵対的攻撃など、ディープ ラーニング (深層学習) モデルがサードパーティ API と統合されている場合学習モデルと防御、およびブラックボックスは言語モデル サービスの学習を促進します。
ハードウェアの制限: ハードウェア システムに深層学習モデルを実装する場合、一次勾配の計算に使用される原理的なバックプロパゲーション メカニズムがサポートされない場合があります。
ただし、現在、ゼロ次最適化のスケーラビリティは未解決の問題のままであり、その使用は主に、サンプルレベルの敵対的攻撃など、比較的小規模な機械学習問題に限定されています。 。問題の次元が増加するにつれて、従来のゼロ次法の精度と効率は低下します。これは、ゼロ次有限差分に基づく勾配推定値が一次勾配の偏った推定値であり、その偏差が高次元空間でより明らかになるためです。これらの課題は、この記事で説明する中心的な質問の動機となります: ディープ ラーニング モデルをトレーニングできるように、ゼロ次最適化を拡張するにはどうすればよいですか?
2. ゼロ次勾配推定: RGE か CGE?
ゼロ次オプティマイザは、入力を送信し、対応する関数値を受け取ることによってのみ目的関数と対話します。以下に示すように、主な勾配推定方法として、座標勾配推定 (CGE) とランダム勾配推定 (RGE) の 2 つがあります。
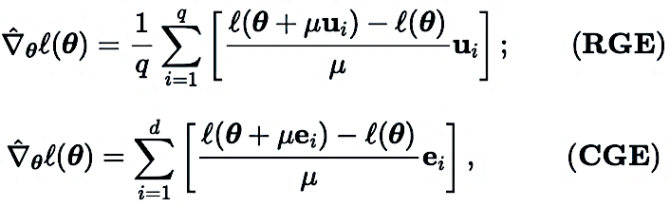
ここで、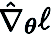 は勾配の推定値を表します。最適化変数
は勾配の推定値を表します。最適化変数 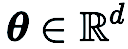 の一次勾配 (ニューラル ネットワークのモデル パラメーターなど)。
の一次勾配 (ニューラル ネットワークのモデル パラメーターなど)。
(RGE) では、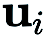 は、たとえば標準ガウス分布から引き出されたランダム摂動ベクトルを表します。
は、たとえば標準ガウス分布から引き出されたランダム摂動ベクトルを表します。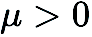 は摂動サイズ (平滑化パラメータとも呼ばれます) で、q は次の値を取得するために使用されます。有限差分 ランダムな方向の数。
は摂動サイズ (平滑化パラメータとも呼ばれます) で、q は次の値を取得するために使用されます。有限差分 ランダムな方向の数。
在(CGE)中,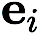 表示标准基向量,
表示标准基向量,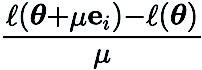 提供了
提供了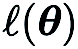 在对应坐标的偏导数的有限差分估计。
在对应坐标的偏导数的有限差分估计。
与 CGE 相比,RGE 具有可以减少函数评估次数的灵活性。尽管查询效率高,但 RGE 在从头开始训练深度模型时是否能提供令人满意的准确性仍不确定。为此,我们进行了调查,其中我们使用 RGE 和 CGE 对不同大小的小型卷积神经网络(CNN)在 CIFAR-10 上进行了训练。如下图所示,CGE 可以实现与一阶优化训练相当的测试精度,并显著优于 RGE,同时也比 RGE 具有更高的时间效率。
基于 CGE 在准确性和计算效率方面相对于 RGE 的优势,我们选择 CGE 作为首选的零阶梯度估计器。然而,CGE 的查询复杂性仍然是一个瓶颈,因为它随模型大小增加而扩大。
3. 零阶深度学习框架:DeepZero
据我们所知,之前的工作没有展示出 ZO 优化在训练深度神经网络(DNN)时不会显著降低性能的有效性。为了克服这一障碍,我们开发了 DeepZero,一种原理性零阶优化深度学习框架,可以将零阶优化扩展到从头开始的神经网络训练。
a) 零阶模型修剪(ZO-GraSP):一个随机初始化的密集神经网络往往包含一个高质量的稀疏子网络。然而,大多数有效的修剪方法都包含模型训练作为中间步骤。因此,它们不适合通过零阶优化找到稀疏性。为了解决上述挑战,我们受到了无需训练的修剪方法的启发,称为初始化修剪。在这类方法中,梯度信号保留(GraSP)被选用,它是一种通过随机初始化网络的梯度流识别神经网络的稀疏性先验的方法。
b) 稀疏梯度:为了保留训练密集模型的准确性优势,在 CGE 中我们结合了梯度稀疏性而不是权重稀疏性。这确保了我们在权重空间中训练一个密集模型,而不是训练一个稀疏模型。具体而言,我们利用 ZO-GraSP 确定可以捕获 DNN 可压缩性的逐层修剪比率(Layer-wise Pruning Ratios, LPRs),然后零阶优化可以通过不断迭代更新部分模型参数权重来训练密集模型,其中稀疏梯度比率由 LPRs 确定。
c) 特征重用:由于 CGE 逐元素扰动每个参数,它可以重用紧接扰动层之前的特征,并执行剩余的前向传播操作,而不是从输入层开始。从经验上看,带有特征重用的 CGE 在训练时间上可以实现 2 倍以上的减少。
d) 前传并行化:CGE 支持模型训练的并行化。这种解耦特性使得通过分布式机器扩展前向传播成为可能,从而显著提高零阶训练速度。
4. 实验分析
a) 图像分类
在 CIFAR-10 数据集上,我们将 DeepZero 训练的 ResNet-20 与两种通过一阶优化训练的变体进行比较:
(1)通过一阶优化训练获得的密集 ResNet-20
(2)通过一阶优化训练通过 FO-GraSP 获得的稀疏 ResNet-20
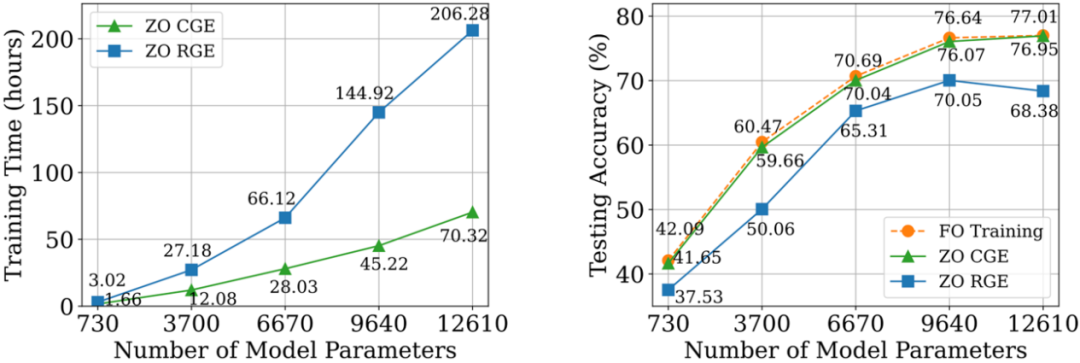
如下图所示,尽管在 80% 至 99% 的稀疏区间中,与(1)相比,使用 DeepZero 训练的模型仍存在准确度差距。这突出了 ZO 优化用于深度模型训练的挑战,其中高稀疏度的实现是被期望的。值得注意的是,在 90% 至 99% 的稀疏区间中,DeepZero 优于(2),展示了 DeepZero 中梯度稀疏性相对于权重稀疏性的优越性。
b) 黑箱防御
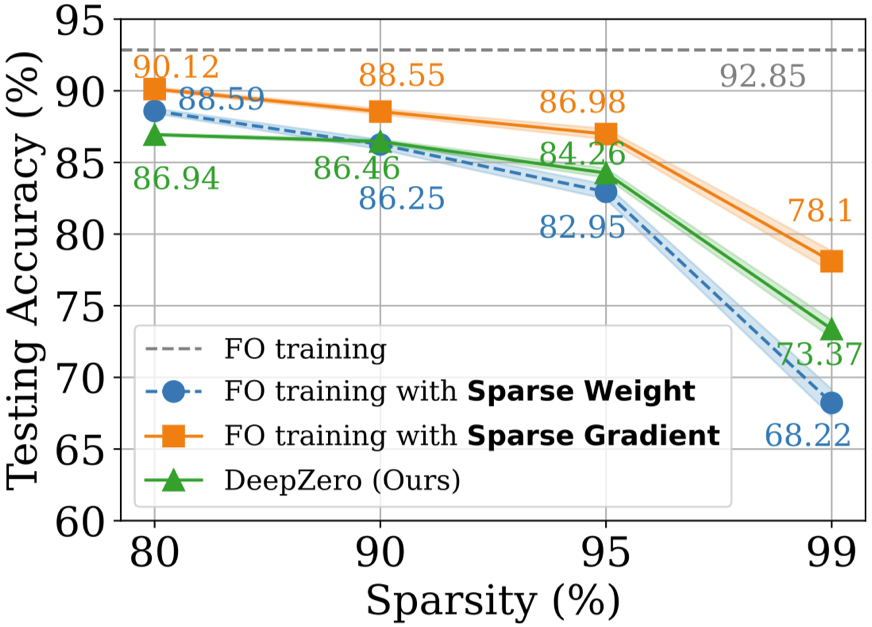
當模型的擁有者不願意與防禦者分享模型細節時,會出現黑盒子防禦問題。這對於使用一階最佳化訓練直接增強白盒模型的現有穩健性增強演算法構成了挑戰。為了克服這一挑戰,ZO-AE-DS 被提出,在白盒去噪平滑(Denoised Smoothing, DS)防禦操作和黑盒圖像分類器之間引入了自動編碼器(AutoEncoder, AE),以解決ZO訓練的維度挑戰。 ZO-AE-DS 的缺點是難以擴展到高解析度資料集(例如,ImageNet),因為使用AE 會損害輸入到黑盒影像分類器的影像的保真度,並導致較差的防禦性能。 相較之下,DeepZero 可以直接學習與黑盒分類器整合的防禦操作,無需自動編碼器。如下表所示,就認證準確率(Certified Accuracy, CA)而言 DeepZero 在所有輸入擾動半徑上始終優於 ZO-AE-DS。
c) 與模擬耦合的深度學習
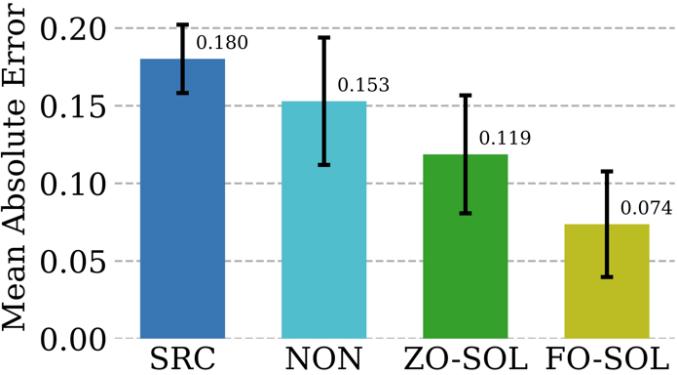
#數值方法在提供物理資訊模擬方面不可或缺,但它們本身存在挑戰:離散化不可避免地產生數值誤差。透過與迭代偏微分方程(Partial Differential Equation, PDE)求解器的循環交互訓練糾正神經網路的可行性,被稱為” 求解器環路」(Solver-in-the-Loop, SOL)。雖然現有工作專注於使用或開發可微模擬器進行模型訓練,我們透過利用 DeepZero 擴展了 SOL,使其能夠與不可微或黑盒模擬器一起使用。 下表比較了ZO-SOL(透過DeepZero 實作)與三種不同的可微方法的測試誤差修正效能:
(1) SRC(低保真模擬無誤差修正);
(2) NON(非互動式訓練,使用預先產生的低和高保真模擬資料在模擬循環外進行);
(3) FO-SOL(給定可微模擬器時,用於SOL 的一階訓練)。
每個測試模擬的誤差計算為與高保真模擬相比的修正模擬的平均絕對誤(MAE)。結果表明,透過 DeepZero 實現的 ZO-SOL 在只有基於查詢的模擬器存取權限的情況下仍然優於 SRC 和 NON,並縮小了與 FO-SOL 的效能差距。與 NON 相比,ZO-SOL 的表現突顯了在有黑盒子模擬器整合時的 ZO-SOL 前景。
5. 總結與討論
#這篇論文介紹了一個深度網路訓練中零階優化深度學習框架(DeepZero )。具體來說,DeepZero 將座標梯度估計、零階模型修剪帶來的梯度稀疏性、特徵重用以及前傳並行化整合到統一的訓練流程中。利用這些創新,DeepZero 在包括影像分類任務和各種實際黑箱深度學習場景中表現出了效率和有效性。此外,還探索了 DeepZero 在其他領域的適用性,例如涉及不可微物理實體的應用,以及在計算圖和反向傳播的計算不被支援的設備上進行訓練。
作者介紹
張益萌,密西根州⽴⼤學OPTML 實驗室, 電腦博士在讀, 研究興趣⽅向包括Generative AI, Multi-Modality, Computer Vision, Safe AI, Efficient AI。
以上がICLR 2024 | 初のゼロ次最適化深層学習フレームワーク、MSU と LLNL が DeepZero を提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。