
ホームページ >システムチュートリアル >Linux >分散システムの中核 - ログ
分散システムの中核 - ログ

- 王林転載
- 2024-02-12 16:09:16885ブラウズ
ログは、完全に順序付けされたレコード シーケンスであり、時系列で追加されます。実際には特別なファイル形式です。ファイルはバイト配列であり、ここでのログはレコード データですが、ここではファイルに対して相対的です。各レコードは次のとおりです。時間の相対的な順序で配置されます。ログは最も単純なストレージ モデルであると言えます。読み取りは通常、左から右に行われます。たとえば、メッセージ キューは通常、消費者の順序でログ ファイルに線形に書き込みます。オフセットから読み取りを開始します。
ログ自体の固有の特性により、レコードは左から右に順番に挿入されます。これは、左側のレコードが右側のレコードよりも「古い」ことを意味します。システム クロック: この機能は分散システムにとって非常に役立ち、システムにとって非常に重要です。
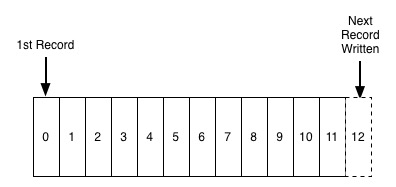
ログがいつ出現したかを知ることは不可能ですが、概念が単純すぎる可能性があります。データベース分野では、ログは、MySQL の REDO ログなど、システムがクラッシュしたときにデータとインデックスを同期するためによく使用されます。REDO ログは、システムがハングしたときにデータを保証するために使用されるディスクベースのデータ構造です。システムは、先行書き込みログとも呼ばれます。たとえば、物事の実行中、最初に REDO ログが書き込まれ、その後、実際の変更が適用されます。このようにして、クラッシュ後にシステムが回復するときに、再実行ログに基づいて再作成されます。元に戻してデータを復元します (初期化プロセス中、現時点ではクライアント接続はありません)。基本的にデータベースのすべての操作記録がログに書き込まれているため、ログはデータベースのマスターとスレーブ間の同期にも使用できます。ログをスレーブに同期し、それをスレーブで再生するだけでマスターを実現できます。 -スレーブ同期。その他多くの必要なコンポーネントもここで実装できます。REDO ログをサブスクライブすることでデータベース内のすべての変更を取得でき、それによって監査やキャッシュ同期などのパーソナライズされたビジネス ロジックを実装できます。
分散システム サービスは基本的に状態の変更に関するものであり、これはステート マシンとして理解できます。2 つの独立したプロセス (システム クロック、外部インターフェイスなどの外部環境に依存しない) は、一貫した入力が与えられると一貫した出力を生成します。そして最終的には維持されます。一貫した状態であり、ログはその固有のシーケンスによりシステム クロックに依存せず、変更順序の問題を解決するために使用できます。
私たちはこの機能を使用して、分散システムで発生する多くの問題を解決します。たとえば、RocketMQ のスタンバイ ノードでは、メイン ブローカーがクライアントのリクエストを受信してログを記録し、それをリアルタイムでスレーブに同期します。スレーブはそれをローカルで再生します。マスターがハングアップしても、スレーブは引き続き処理を続行できます。書き込みリクエストを拒否して続行するなど、リクエストを処理します。読み取りリクエストを処理します。ログにはデータを記録するだけでなく、SQL ステートメントなどの操作を直接記録することもできます。
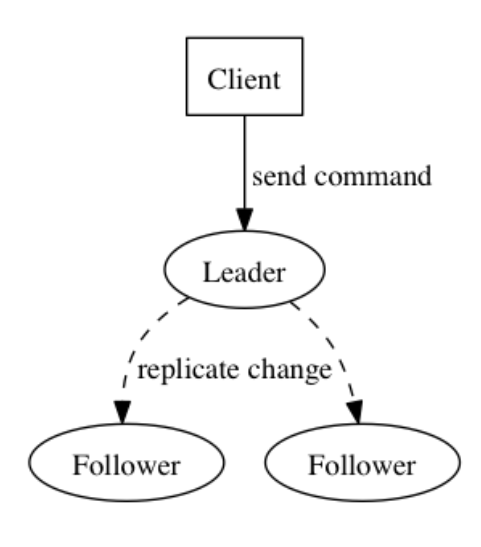
ログは一貫性の問題を解決するための重要なデータ構造です。ログは一連の操作のようなものです。各レコードは命令を表します。たとえば、広く使用されている Paxos プロトコルと Raft プロトコルはすべて、ログに基づいて構築された一貫性プロトコルです。
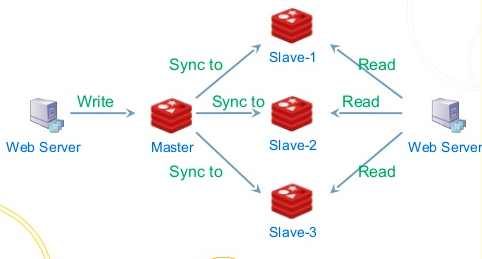
ログは、データの流入と流出の処理に簡単に使用できます。各データ ソースは独自のログを生成できます。ここでのデータ ソースは、特定のイベント ストリーム (ページ クリック、キャッシュ更新リマインダー、データベースのバイナリログの変更など)を使用すると、ログをクラスターに集中的に保存でき、サブスクライバーはオフセットに基づいてログの各レコードを読み取り、各レコードのデータと操作に基づいて独自の変更を適用できます。
ここでのログはメッセージ キューとして理解でき、メッセージ キューは非同期デカップリングと電流制限の役割を果たすことができます。なぜデカップリングと言うのでしょうか?コンシューマーとプロデューサーにとって、2 つの役割の責任は非常に明確であるため、どちらが下流であるか上流であるか、データベースの変更ログであるか特定のイベントであるかなどを気にすることなく、メッセージの作成とメッセージの消費に責任を負います。特定のパーティのことを気にする必要はまったくなく、興味のあるログとそのログ内の各レコードに注意を払うだけで済みます。
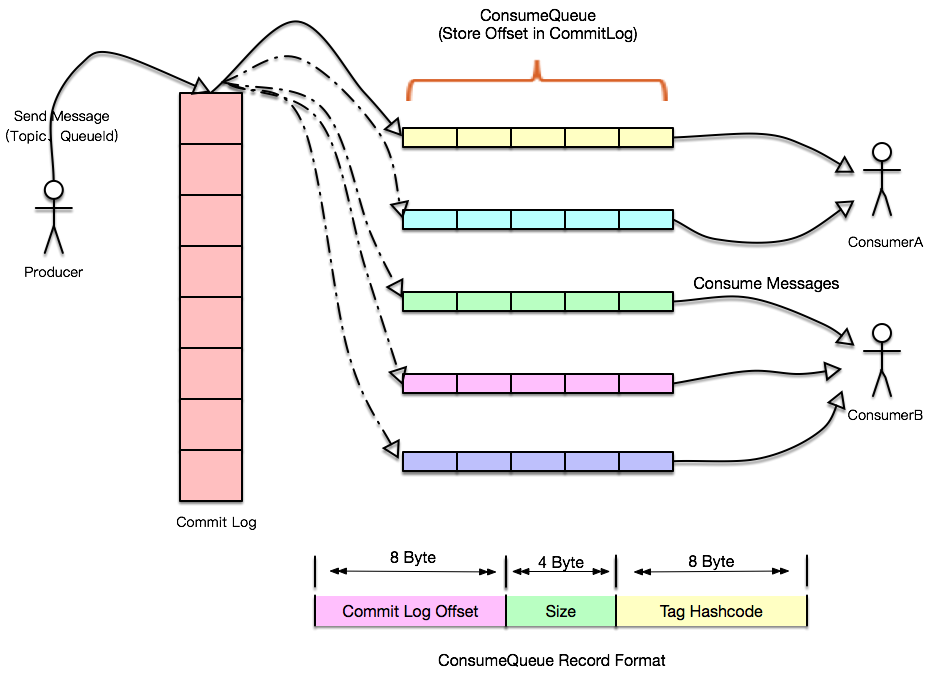
データベースの QPS は確実であり、上位層のアプリケーションは一般に水平方向に拡張できることがわかっています。この時点で、ダブル 11 のような突然のリクエストのシナリオがあり、データベースが圧倒される場合は、メッセージを導入できます。キューを作成し、各チームのデータベースを追加します 操作はログに書き込まれ、別のアプリケーションがこれらのログ レコードを消費してデータベースに適用する責任があります データベースがハングした場合でも、回復時に最後のメッセージの位置から処理を続行できます(RocketMQ と Kafka はどちらも Exactly Once セマンティクスをサポートしています)、プロデューサーの速度がコンシューマーの速度と異なっていても、影響はありません。ログはここでバッファーの役割を果たします。すべてのレコードをログの書き込みとスレーブ ノードへの定期的な同期により、ログの書き込みはマスター ノードによって処理されるため、メッセージのバックログ容量が大幅に向上します。書き込み速度に追いつくことができます。1 つのタイプの読み取りはキャッシュに直接送信でき、もう 1 つのタイプは書き込みリクエストに遅れるコンシューマです。このタイプはスレーブ ノードから読み取ることができるため、IO 分離や一部の機能を通じてページキャッシュ、キャッシュ事前読み取りなど、オペレーティング システムに付属するファイル ポリシーを使用すると、パフォーマンスが大幅に向上する可能性があります。
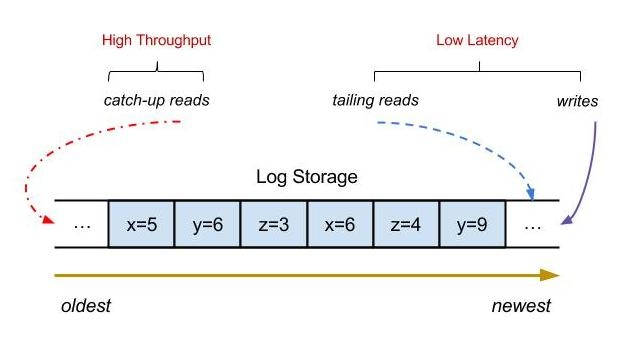
水平方向のスケーラビリティは分散システムにおいて非常に重要な機能であり、マシンを追加することで解決できる問題は問題ではありません。では、水平拡張を実現できるメッセージ キューを実装するにはどうすればよいでしょうか? スタンドアロンのメッセージ キューがある場合、トピックの数が増加するにつれて、IO、CPU、帯域幅などが徐々にボトルネックになり、パフォーマンスが徐々に低下します。ここでどのように進めればよいですか?パフォーマンスの最適化についてはどうですか?
- トピック/ログ シャーディング。本質的に、トピックによって書き込まれるメッセージはログ レコードです。書き込み数が増加するにつれて、単一のマシンが徐々にボトルネックになります。このとき、単一のトピックを複数のサブトピックに分割できます。を作成し、各トピックを異なるマシンに割り当てます。このようにして、大量のメッセージを含むトピックはマシンを追加することで解決できますが、少量のメッセージを含む一部のトピックは同じマシンに割り当てるか、パーティション分割なしで解決できます。 Kafka のプロデューサー クライアントなどのグループ コミットは、メッセージを書き込むときに、まずローカル メモリ キューに書き込み、次に各パーティションおよびノードに従ってメッセージを要約し、バッチで送信します。サーバー側またはブローカー側の場合, この方法を使用して、最初にページキャッシュに書き込み、その後ディスクを定期的にフラッシュすることもできます。フラッシュの方法はビジネスに応じて決定できます。たとえば、金融サービスでは同期フラッシュ方法が採用される場合があります。
- 無駄なデータのコピーを避ける
- IO分離
-
 ######結論######
######結論######
以上が分散システムの中核 - ログの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。