
ホームページ >テクノロジー周辺機器 >AI >トークンに分割せずにバイトから直接学習することで効率よく学習することができます。
トークンに分割せずにバイトから直接学習することで効率よく学習することができます。

- 王林転載
- 2024-02-04 14:54:29760ブラウズ
言語モデルを定義する場合、文を単語、サブワード、または文字に分割するために、基本的な単語分割手法がよく使用されます。サブワード セグメンテーションは、トレーニング効率と語彙外の単語を処理する能力とのバランスをとるため、長い間最も一般的な選択肢です。ただし、一部の研究では、タイプミス、スペルと大文字の変更、形態学的変化の処理に対する堅牢性の欠如など、サブワードのセグメンテーションに関する問題が指摘されています。したがって、モデルの精度と堅牢性を向上させるために、言語モデルの設計においてこれらの問題を慎重に考慮する必要があります。
したがって、一部の研究者は、バイト シーケンスを使用するアプローチ、つまり、単語の分割を行わずに生データを予測結果にエンドツーエンドでマッピングするアプローチを選択しました。サブワード モデルと比較して、バイト レベルの言語モデルは、さまざまな記述形式や形態変化に一般化するのが簡単です。ただし、テキストをバイトとしてモデル化すると、生成されるシーケンスは対応するサブワードよりも長くなります。効率を向上させるには、アーキテクチャを改善することで達成する必要があります。
自己回帰トランスフォーマーは言語モデリングにおいて支配的な地位を占めていますが、その効率の問題は特に顕著です。シーケンスの長さが増加するにつれて計算コストが二次関数的に増加するため、長いシーケンスのスケーラビリティが低下します。この問題を解決するために、研究者らは長いシーケンスを処理できるように Transformer の内部表現を圧縮しました。そのようなアプローチの 1 つは、中間層内でトークンのグループをマージし、それによって計算コストを削減する、長さを意識したモデリング アプローチの開発です。最近、Yu らは MegaByte Transformer と呼ばれる方法を提案しました。固定サイズのバイト フラグメントを使用して圧縮形式をサブワードとしてシミュレートするため、計算コストが削減されます。ただし、これは現時点では最善の解決策ではない可能性があり、さらなる研究と改善が必要です。
最新の研究で、コーネル大学の学者たちは、MambaByte と呼ばれる効率的でシンプルなバイトレベルの言語モデルを導入しました。このモデルは、最近導入された Mamba アーキテクチャの直接の改良から派生しています。 Mamba アーキテクチャは状態空間モデル (SSM) メソッドに基づいて構築されていますが、MambaByte はより効率的な選択メカニズムを導入しており、テキストなどの離散データを処理する際のパフォーマンスが向上し、効率的な GPU 実装も提供します。研究者らは、修正されていない Mamba の使用を簡単に観察したところ、言語モデリングにおける主要な計算ボトルネックを軽減でき、それによってパッチの必要性がなくなり、利用可能な計算リソースを最大限に活用できることがわかりました。

- 論文のタイトル: MambaByte: トークンフリーの選択的状態空間モデル ##論文リンク: https://arxiv.org/pdf/2401.13660.pdf
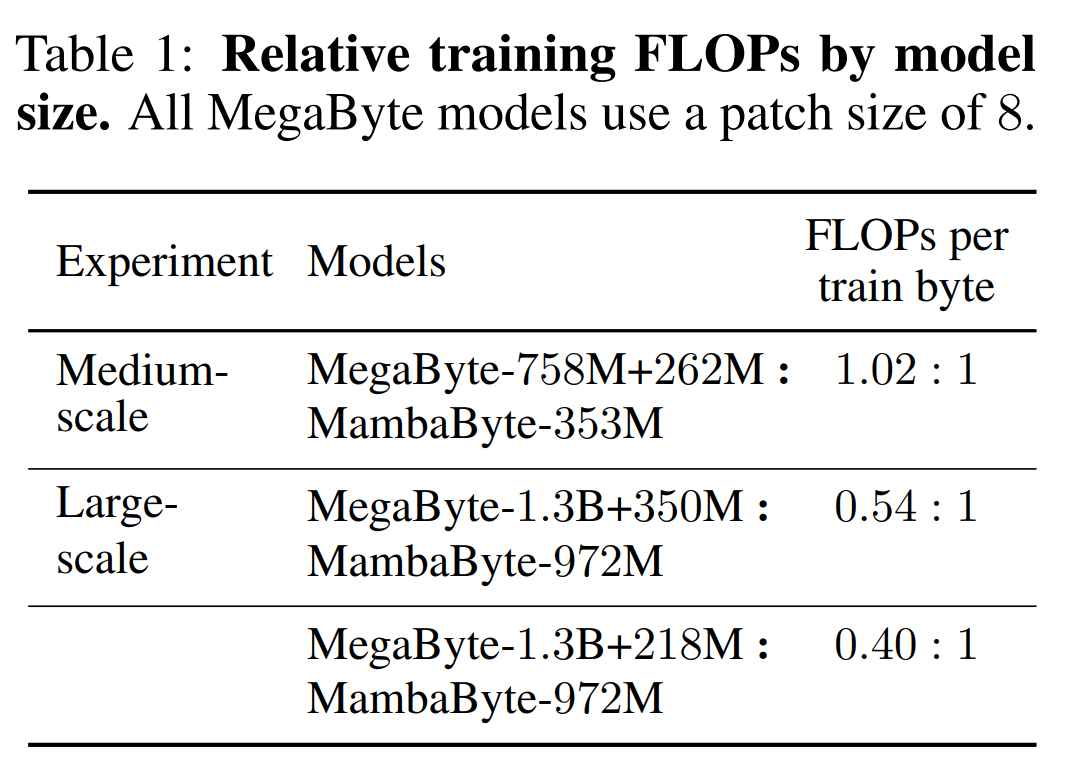
- 実験では、彼らは、MambaByte を Transformers、SSM、および MegaByte (パッチング) アーキテクチャと比較しました。これらのアーキテクチャは、固定パラメーターと計算設定に基づいて、複数の長文テキスト データセットで評価されます。図 1 は、彼らの主な発見をまとめたものです。
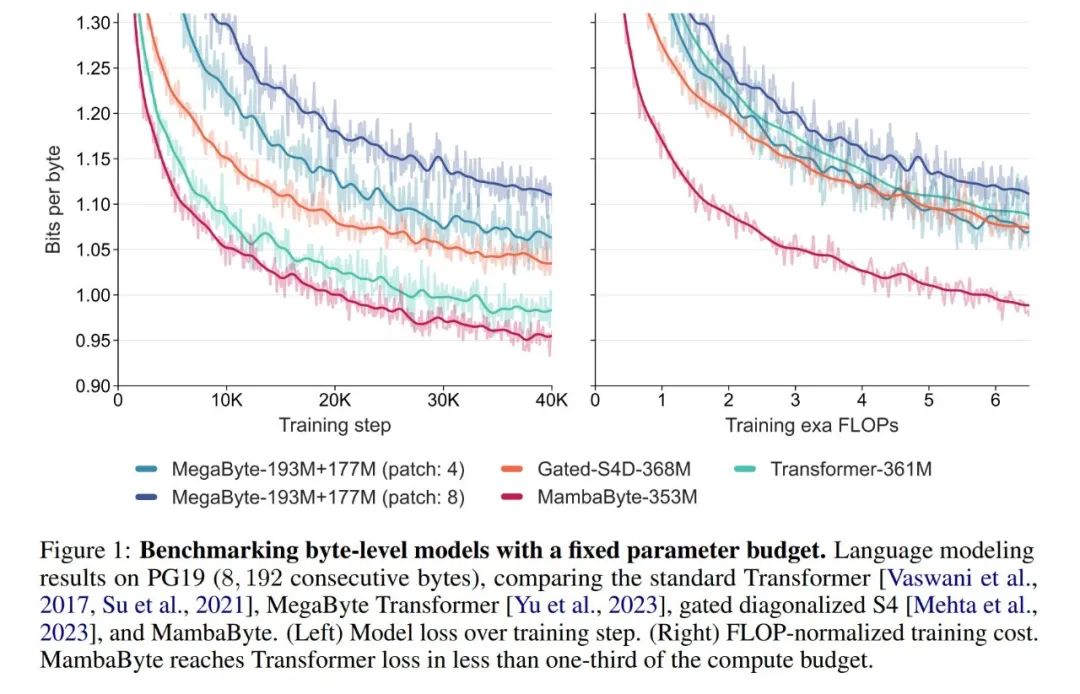 バイトレベルの Transformers と比較して、MambaByte はより高速で高性能のソリューションを提供すると同時に、コンピューティング効率も大幅に向上しています。研究者らはまた、トークンフリー言語モデルと現在の最先端のサブワード モデルを比較し、MambaByte がこの点で競争力があり、より長いシーケンスを処理できることを発見しました。この研究の結果は、MambaByte がそれに依存する既存のトークナイザーの強力な代替手段となり得ることを示しており、エンドツーエンド学習のさらなる発展を促進することが期待されています。
バイトレベルの Transformers と比較して、MambaByte はより高速で高性能のソリューションを提供すると同時に、コンピューティング効率も大幅に向上しています。研究者らはまた、トークンフリー言語モデルと現在の最先端のサブワード モデルを比較し、MambaByte がこの点で競争力があり、より長いシーケンスを処理できることを発見しました。この研究の結果は、MambaByte がそれに依存する既存のトークナイザーの強力な代替手段となり得ることを示しており、エンドツーエンド学習のさらなる発展を促進することが期待されています。
背景:選択的状態空間シーケンス モデル
SSM は、一次微分方程式を使用して隠れ状態の時間発展をモデル化します。線形時不変 SSM は、さまざまな深層学習タスクで良好な結果を示しています。しかし最近、Mamba の作者である Gu 氏と Dao 氏は、これらのメソッドの一定のダイナミクスには、言語モデリングなどのタスクに必要な、隠れ状態での入力依存のコンテキスト選択が欠けていると主張しました。そこで彼らは、与えられた入力 x(t) ∈ R、隠れ状態 h(t) ∈ R^n、出力 y(t) ∈ R を時変連続状態として動的に定義する Mamba 法を提案しました。時刻 t は次のとおりです:
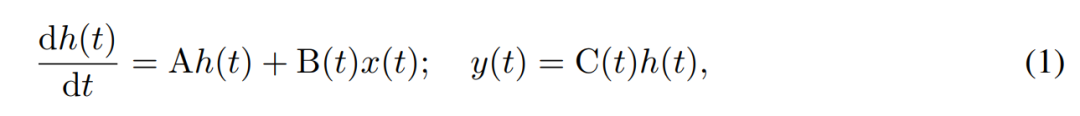 # そのパラメータは対角時不変システム行列 A∈R^(n×n )、時変入力行列と出力行列 B (t)∈R^(n×1) および C (t)∈R^(1×n)。
# そのパラメータは対角時不変システム行列 A∈R^(n×n )、時変入力行列と出力行列 B (t)∈R^(n×1) および C (t)∈R^(1×n)。
バイトなどの離散時系列をモデル化するには、(1) の連続時間ダイナミクスを離散化によって近似する必要があります。これにより、各タイム ステップで新しい行列 A、B、および C を使用した離散時間潜在反復が生成されます。つまり、
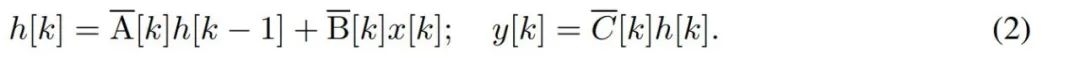
注意してください ( 2)リカレント ニューラル ネットワークの線形バージョンと同様に、言語モデルの生成中にこのリカレント形式で適用できます。離散化では、各入力位置にタイム ステップ、つまり 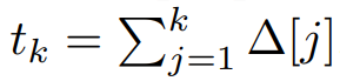 の x [k] = x (t_k) に対応する Δ[k] が必要です。離散時間行列 A、B、および C は、Δ[k] から計算できます。図 2 は、Mamba が離散シーケンスをどのようにモデル化するかを示しています。
の x [k] = x (t_k) に対応する Δ[k] が必要です。離散時間行列 A、B、および C は、Δ[k] から計算できます。図 2 は、Mamba が離散シーケンスをどのようにモデル化するかを示しています。
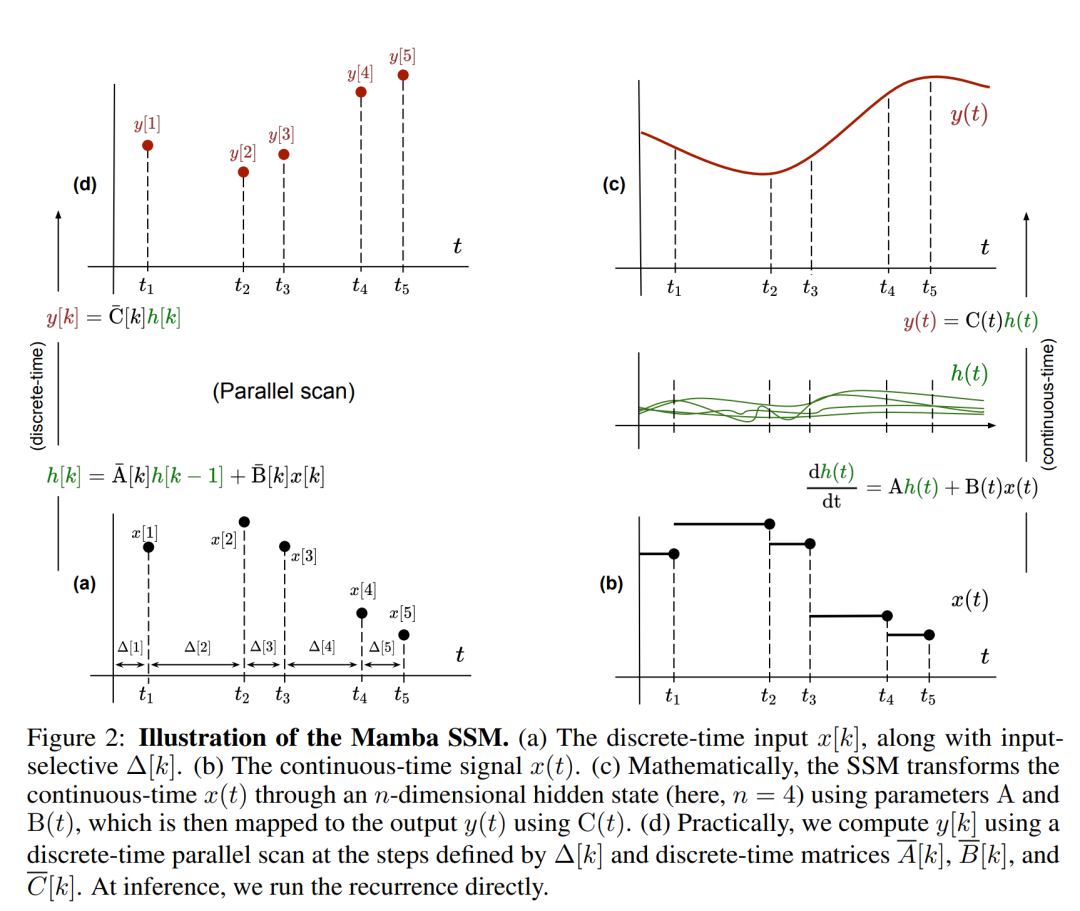
Mamba では、SSM 項は入力選択的です。つまり、B、C、Δ は入力 x [k]∈R として定義されます。 ^ d の関数:
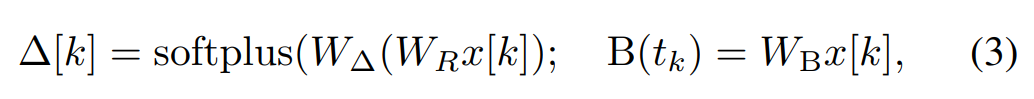
W_B ∈ R^(n×d) (C の定義も同様です) 、W_Δ ∈ R^(d×r) と W_R ∈ R^(r×d) (一部の r ≪d の場合) は学習可能な重みですが、softplus は正の値を保証します。各入力次元 d について、SSM パラメーター A、B、C は同じですが、タイム ステップ数 Δ が異なることに注意してください。これにより、各タイム ステップ k の隠れ状態サイズは n × d になります。
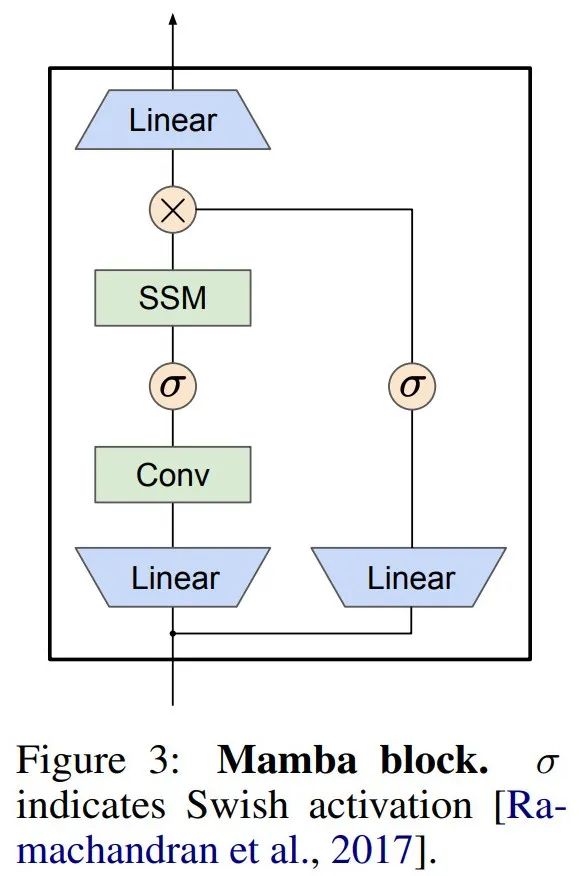
Mamba は、この SSM 層を完全なニューラル ネットワーク言語モデルに埋め込みます。具体的には、このモデルは、以前のゲート SSM からインスピレーションを得た一連のゲート層を採用しています。図 3 は、SSM レイヤーとゲート ニューラル ネットワークを組み合わせた Mamba アーキテクチャを示しています。
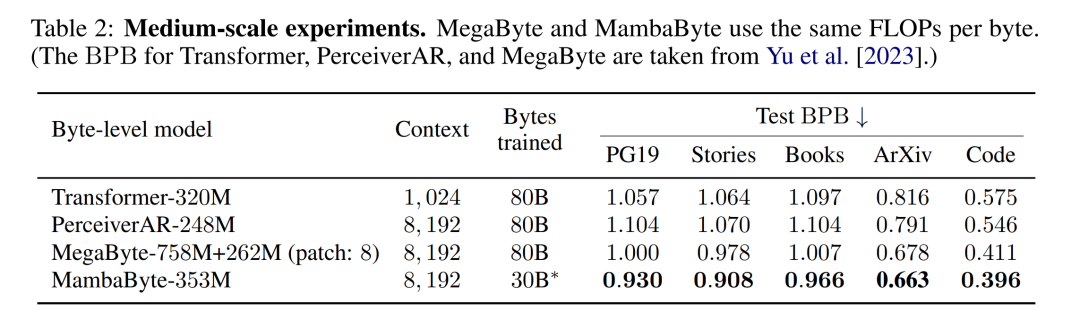
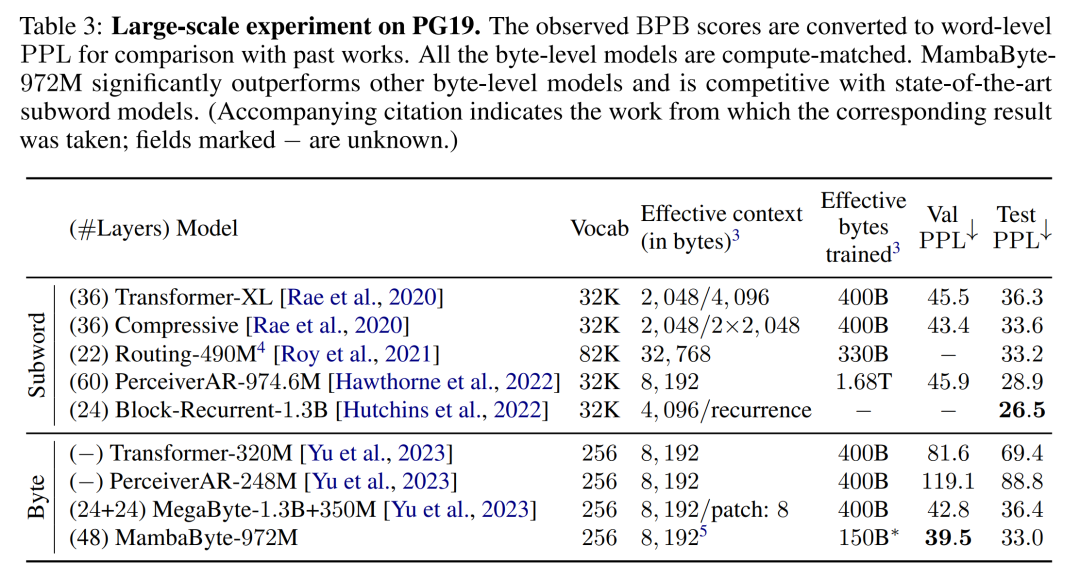
#線形再発の並列スキャン。トレーニング時に、作成者はシーケンス x 全体にアクセスできるため、線形漸化式のより効率的な計算が可能になります。 Smith et al. [2023] による研究では、効率的な並列スキャンを使用して線形 SSM における逐次的再発を効率的に計算できることが実証されています。 Mamba の場合、著者は最初に繰り返しを L タプル シーケンス (e_k = 表 2 は、各データセットのバイトあたりのビット数 (BPB) を示しています。この実験では、MegaByte758M 262M モデルと MambaByte モデルは、バイトあたり同じ数の FLOP を使用しました (表 1 を参照)。著者らは、MambaByte がすべてのデータセットで一貫して MegaByte を上回っていることを発見しました。さらに、著者らは、資金の制約のため、80B バイト全体で MambaByte をトレーニングすることはできなかったが、それでも MambaByte は計算量が 63% 少なく、トレーニング データが 63% 少ないにもかかわらず MegaByte よりも優れたパフォーマンスを示したと指摘しています。さらに、MambaByte-353M はバイトスケールの Transformer や PerceiverAR よりも優れたパフォーマンスを発揮します。 わずかなトレーニングステップで、MambaByte が Does よりも優れている理由はるかに大きなモデルの方がパフォーマンスが良いでしょうか?図 1 では、同じ数のパラメーターを持つモデルを観察することで、この関係をさらに詳しく調べています。この図は、同じパラメータ サイズのメガバイト モデルの場合、入力パッチが少ないモデルの方がパフォーマンスが優れていますが、正規化を計算した後のパフォーマンスは同様であることを示しています。実際、フルレングスの Transformer は、絶対的には遅くなりますが、計算正規化後のパフォーマンスは MegaByte と同様です。対照的に、Mamba アーキテクチャに切り替えると、計算使用量とモデルのパフォーマンスが大幅に向上します。 これらの結果に基づいて、表 3 では、PG19 データセット上のこれらのモデルのより大きなバージョンを比較しています。この実験では、著者らは MambaByte-972M を MegaByte-1.3B 350M およびその他のバイトレベル モデルおよびいくつかの SOTA サブワード モデルと比較しました。彼らは、MambaByte-972M がすべてのバイトレベル モデルよりも優れたパフォーマンスを示し、わずか 150B バイトでトレーニングされた場合でもサブワード モデルと競合できることを発見しました。
 ) にマップし、次に # のような関連演算子
) にマップし、次に # のような関連演算子  を定義します。
を定義します。 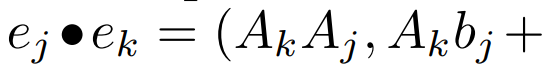 ##。最後に、並列スキャンを適用してシーケンス
##。最後に、並列スキャンを適用してシーケンス 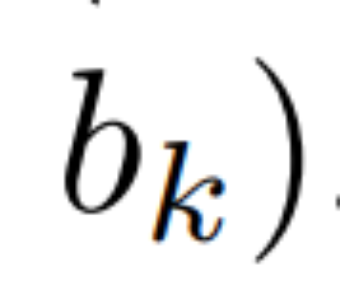 を計算しました。一般に、L/2 プロセッサを使用すると、これには
を計算しました。一般に、L/2 プロセッサを使用すると、これには 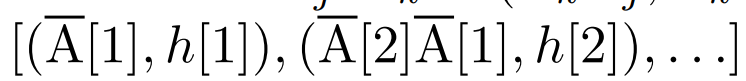 時間がかかります。ここで、
時間がかかります。ここで、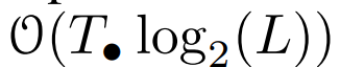 は行列乗算のコストです。 A は対角行列であり、線形漸化式は
は行列乗算のコストです。 A は対角行列であり、線形漸化式は 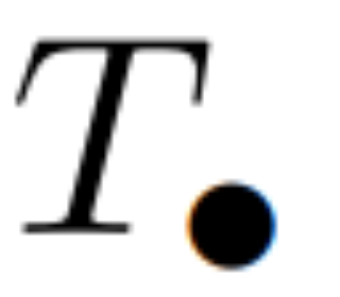 時間と O (nL) 空間で並列計算できることに注意してください。対角行列を使用した並列スキャンも非常に効率的に実行され、必要なフロップは O (nL) のみです。
時間と O (nL) 空間で並列計算できることに注意してください。対角行列を使用した並列スキャンも非常に効率的に実行され、必要なフロップは O (nL) のみです。 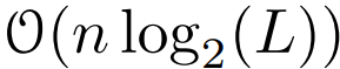
実験結果
 #
#
以上がトークンに分割せずにバイトから直接学習することで効率よく学習することができます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。