
ホームページ >テクノロジー周辺機器 >AI >グラフ分野初のユニバーサルフレームワークが登場! ICLR\'24 Spotlight に選ばれ、あらゆるデータセットと分類の問題を解決できます
グラフ分野初のユニバーサルフレームワークが登場! ICLR\'24 Spotlight に選ばれ、あらゆるデータセットと分類の問題を解決できます

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-04 10:45:221110ブラウズ
一般的なグラフ モデルはありますか——分子構造に基づいて毒性を予測できるだけでなく、社会的影響に関する情報も提供できます。ネットワーク 友人に勧められましたか?
それとも、さまざまな著者による論文の引用を予測できるだけでなく、遺伝子ネットワークにおける人間の老化メカニズムを発見することもできるのでしょうか?
言わないでください、
ICLR 2024によってスポットライトとして受け入れられた「One for All(OFA)」フレームワークはこの「本質」を実現しています」。 この研究は、セントルイスのワシントン大学のChen Yixin教授のチーム、北京大学のZhang Muhan氏、京東研究所のTao Dacheng氏などの研究者によって共同提案されました。
グラフ フィールドの
最初の一般的なフレームワークとして、OFA を使用すると、単一の GNN モデルをトレーニングして、グラフ フィールド内の任意のデータ セット、任意のタスク タイプ、および任意のシーンの分類タスクを解決できます。 。
 実装方法、以下は著者の寄稿です。
実装方法、以下は著者の寄稿です。
グラフ分野における汎用モデルの設計は 3 つの大きな困難に直面しています
さまざまなタスクを解決するための汎用基本モデルを設計することは、人工知能の分野における長期的な目標です。近年、基本的な大規模言語モデル (LLM) は、自然言語タスクの処理において優れたパフォーマンスを発揮しています。
ただし、グラフの分野では、グラフ ニューラル ネットワーク (GNN) はさまざまなグラフ データで優れたパフォーマンスを発揮しますが、同時に複数のグラフを処理できるネットワークを設計およびトレーニングする方法は次のとおりです。タスクの基本的なグラフ モデルにはまだ長い道のりがあります。
自然言語分野と比較して、グラフ分野における一般モデルの設計は多くの特有の困難に直面しています。 まず、自然言語とは異なり、グラフデータが異なれば属性や分布もまったく異なります。
たとえば、分子図は、複数の原子がさまざまな力の関係を通じてさまざまな化学物質をどのように形成するかを説明します。引用関係図は、記事間の相互引用のネットワークを表します。
これらの異なるグラフ データをトレーニング フレームワークの下で統合することは困難です。
第 2 に、統合コンテキスト生成タスクに変換できる LLM のすべてのタスクとは異なり、グラフ タスクには、ノード タスク、リンク タスク、フルグラフ タスクなどのさまざまなサブタスクが含まれます。
異なるサブタスクには通常、異なるタスク表現と異なるグラフ モデルが必要です。
最後に、大規模な言語モデルの成功は、プロンプト パラダイムを通じて達成されるコンテキスト学習
(コンテキスト内学習)と切り離すことができません。
大規模な言語モデルでは、プロンプト パラダイムは通常、下流のタスクの読みやすいテキストの説明です。 しかし、構造化されておらず、言葉で説明するのが難しいグラフ データの場合、コンテキスト内学習を実現する効果的なグラフ プロンプト パラダイムを設計する方法は、依然として未解決の謎です。
「テキスト ダイアグラム」の概念を使用して問題を解決する
次の図は、OFA の全体的なフレームワークを示しています。
具体的には、 , OFAのチームは、上記の3つの主要な問題を賢明な設計によって解決しました。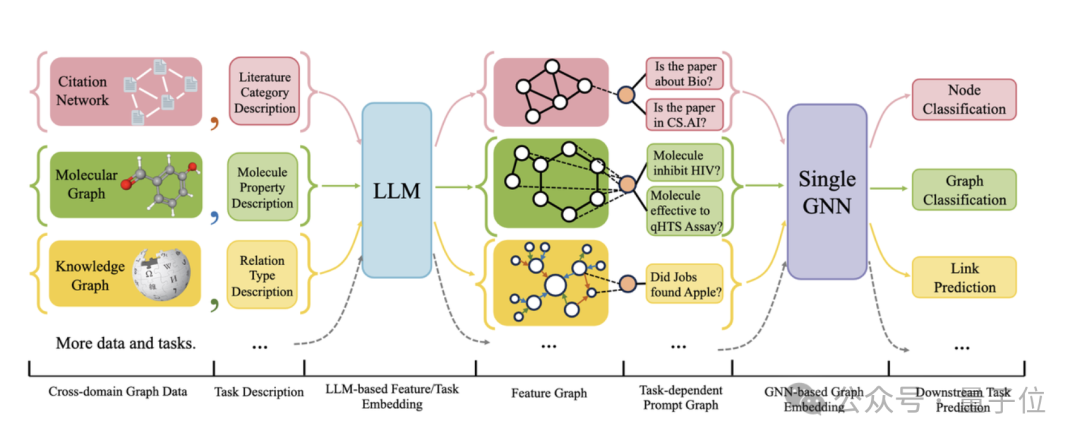 さまざまなグラフ データの属性と分布の問題を解決するために、OFA はテキスト グラフ
さまざまなグラフ データの属性と分布の問題を解決するために、OFA はテキスト グラフ
の概念を提案することで、すべてのグラフ データを統合します。 OFA は、次の図に示すように、テキスト グラフを使用して、統一された自然言語フレームワークを使用してすべてのグラフ データのノード情報とエッジ情報を記述します。次に、OFA は単一の LLM モデルを使用してすべてのデータ内のテキストの表現を学習し、その埋め込みベクトルを取得します。
これらの埋め込みベクトルは、グラフィカル モデルの入力フィーチャとして機能します。このようにして、異なるドメインのグラフ データが同じ特徴空間にマッピングされるため、統合された GNN モデルのトレーニングが可能になります。 OFA は、次の図に示すように、引用関係グラフ、Web リンク グラフ、知識グラフ、分子グラフなど、さまざまな分野からさまざまなサイズの 9 つのグラフ データ セットを収集しました。
##さらに、OFA は、グラフ内の異なるサブグラフを統合するために、対象ノード (NOI)
(NOI)
サブグラフと NOI プロンプト ノード (NOI プロンプト ノード)
(NOI プロンプト ノード)
たとえば、ノード予測タスクでは、NOI は予測する必要がある 1 つのノードを指しますが、リンク タスクでは、NOI にはリンクを予測する必要がある 2 つのノードが含まれます。 NOI サブグラフは、これらの NOI ノードの周囲に拡張された h ホップ近傍を含むサブグラフを指します。
次に、NOI プロンプト ノードは、すべての NOI に直接接続される、新しく導入されたノード タイプです。
重要なのは、各 NOI プロンプト ノードには現在のタスクの説明情報が含まれていることです。この情報は自然言語の形式で存在し、テキスト グラフと同じ LLM によって表されます。
NOI 内のノードに含まれる情報は、GNN のメッセージを渡した後、NOI プロンプト ノードによって収集されるため、GNN モデルは NOI プロンプト ノードを通じて予測を行うだけで済みます。
このようにして、すべての異なるタスク タイプが統一されたタスク表現を持つようになります。具体的な例を以下の図に示します。
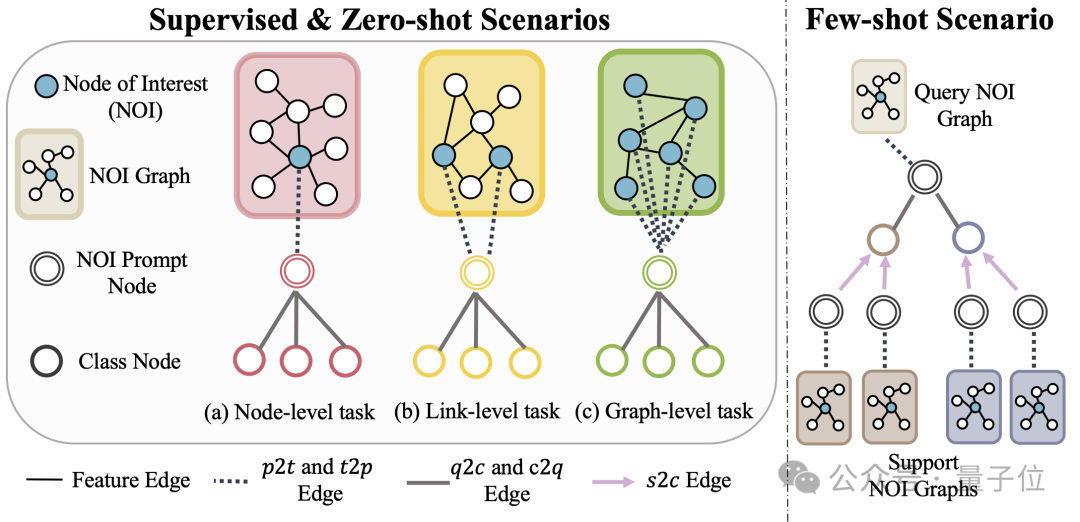
#最後に、グラフ フィールドでコンテキスト内の学習を実現するために、OFA は統一されたプロンプト サブグラフを導入します。
教師あり k ウェイ分類タスク シナリオでは、このプロンプト サブグラフには 2 種類のノードが含まれています: 1 つは前述の NOI プロンプト ノードで、もう 1 つは k 個の異なるカテゴリを表します。クラス ノード (クラス ノード) )。
各カテゴリ ノードのテキストは、このカテゴリに関連する情報を説明します。
NOI プロンプト ノードは、すべてのカテゴリ ノードに一方向に接続されます。このように構築されたグラフは、メッセージの受け渡しと学習のためにグラフ ニューラル ネットワーク モデルに入力されます。
最後に、OFA は各カテゴリ ノードに対して 2 分類タスクを実行し、最も確率の高いカテゴリ ノードを最終予測結果として選択します。
カテゴリー情報がキューサブグラフに存在するため、全く新しい分類問題に遭遇した場合でも、OFAは対応するキューサブグラフを構築することで微調整なしで直接予測することができ、ゼロショット学習を実現します。
少数ショット学習シナリオの場合、分類タスクにはクエリ入力グラフと複数のサポート入力グラフが含まれます。OFA のプロンプト グラフ パラダイムは、各サポート入力グラフの NOI プロンプト ノードを対応するカテゴリ ノードに関連付けます。クエリ入力グラフの NOI プロンプト ノードをすべてのカテゴリ ノードに接続すると同時に接続します。
後続の予測ステップは、上記の予測ステップと一致します。このようにして、各カテゴリ ノードはサポート入力グラフから追加情報を受け取り、それによって統一パラダイムの下で少数ショット学習を実現します。
OFA の主な貢献は次のように要約されます。
統合されたグラフ データ分散: テキスト グラフを提案し、LLM を使用してテキスト情報を変換することにより、OFA は分散の調整とグラフ データの統合を実現します。
統一されたグラフ タスク フォーム: NOI サブグラフと NOI プロンプト ノードを通じて、OFA はさまざまなグラフ フィールドでサブタスクの統一された表現を実現します。
統合グラフ プロンプト パラダイム: 新しいグラフ プロンプト パラダイムを提案することで、OFA はグラフ フィールドでマルチシナリオのコンテキスト内学習を実現します。
超一般化能力
この記事では、収集した 9 つのデータセットで OFA フレームワークをテストしました。これらのテストでは、ノード予測、リンク予測、グラフ分類など、教師あり学習シナリオの 10 個の異なるタスクがカバーされました。
実験の目的は、単一の OFA モデルが複数のタスクを処理できることを検証することであり、著者は、さまざまな LLM (OFA-{LLM}) とタスク (OFA-ind-{LLM})効果ごとに個別のモデルをトレーニングします。
比較結果を次の表に示します。
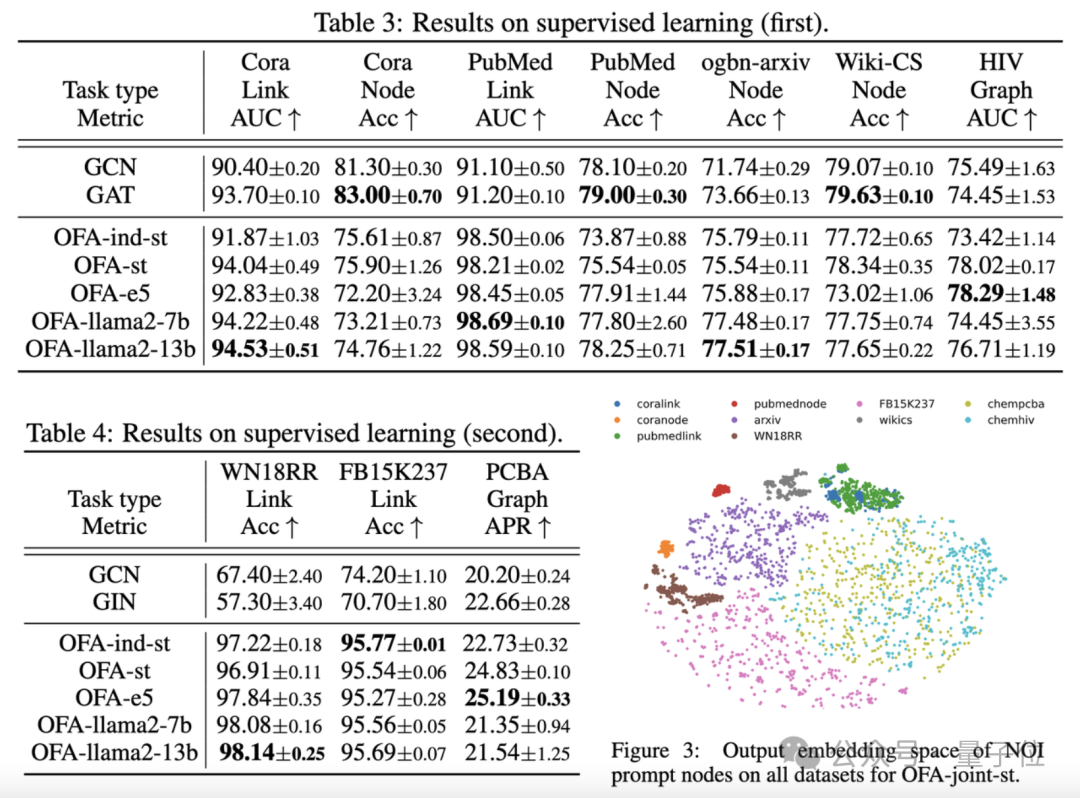
OFA の強力な一般化機能に基づいて、別のグラフ モデル (OFA -st、OFA-e5、OFA-llama2-7b、OFA-llama2-13b) つまり、すべてのタスクに対して同じ従来の個別のトレーニング モデルを使用できます (GCN、GAT、OFA-ind -st ) 同等以上のパフォーマンス。
同時に、より強力な LLM を使用すると、パフォーマンスが向上する可能性があります。この記事ではさらに、トレーニングされた OFA モデルによるさまざまなタスクの NOI プロンプト ノードの表現をプロットしています。
モデルによってさまざまなタスクがさまざまな部分空間に埋め込まれているため、OFA は相互に影響を与えることなくさまざまなタスクを個別に学習できることがわかります。
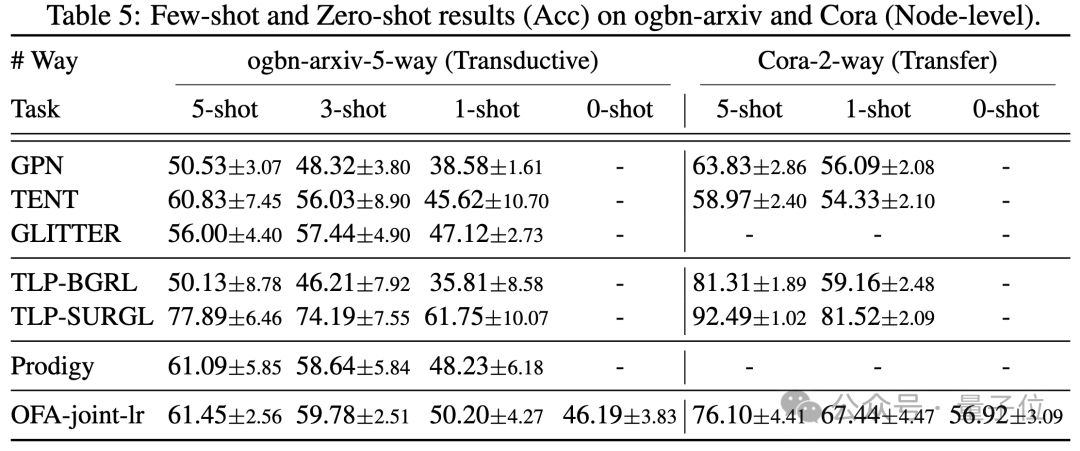
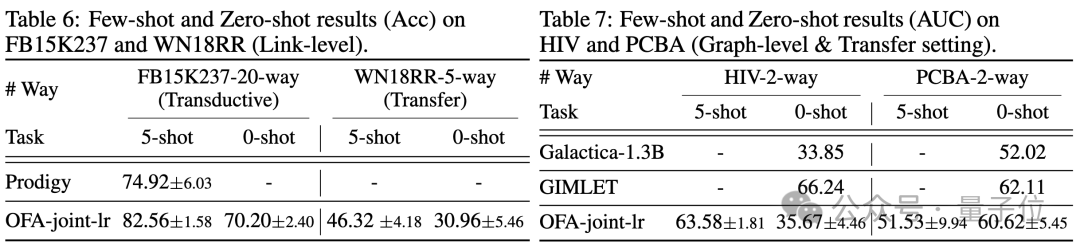
少数のサンプルとゼロのサンプルのシナリオでは、OFA は ogbn-arxiv (参照グラフ) 、FB15K237 (ナレッジ グラフ) 、および Chemble で使用されます。 (単一のモデルを使用して分子グラフで事前トレーニングします)、さまざまな下流タスクとデータセットでそのパフォーマンスをテストします。結果は次のとおりです:
 #
#
ゼロサンプルのシナリオでも、OFA は依然として良好な結果を達成できることがわかります。総合すると、実験結果は、OFA の強力な一般的なパフォーマンスと、グラフ フィールドの基本モデルとしての可能性を十分に検証しています。
研究の詳細については、元の論文を参照してください。
アドレス: https://www.php.cn/link/dd4729902a3476b2bc9675e3530a852chttps://github.com/ LechengKong/OneForAll
以上がグラフ分野初のユニバーサルフレームワークが登場! ICLR\'24 Spotlight に選ばれ、あらゆるデータセットと分類の問題を解決できますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。