
ホームページ >テクノロジー周辺機器 >AI >大型模型にも泥棒がいる?パラメータを保護するには、大きなモデルを送信して「人間が判読できる指紋」を作成してください。
大型模型にも泥棒がいる?パラメータを保護するには、大きなモデルを送信して「人間が判読できる指紋」を作成してください。

- PHPz転載
- 2024-02-02 21:33:301427ブラウズ
異なる基本モデルは、異なる品種の犬としてシンボル表示され、同じ「犬の形をした指紋」は、それらが同じ基本モデルから派生したことを示します。
大規模モデルの事前トレーニングには大量のコンピューティング リソースとデータが必要となるため、事前トレーニングされたモデルのパラメータは主要な機関が保護に重点を置く中核的な競争力と資産となっています。 。ただし、従来のソフトウェアの知的財産保護とは異なり、事前トレーニングされたモデルのパラメーターの不正使用を判断するには、2 つの新たな問題があります:
1) 事前トレーニングされたモデルのパラメーター、特に数千億のモデルのパラメーター。通常はオープンソースではありません。
事前トレーニングされたモデルの出力とパラメーターは、後続の処理ステップ (SFT、RLHF、事前トレーニングの継続など) の影響を受けるため、モデルが微調整されているかどうかを判断することが困難になります。別の既存のモデルに基づいています。モデルの出力に基づいて判断する場合でも、モデルのパラメーターに基づいて判断する場合でも、特定の課題があります。
したがって、大規模なモデル パラメーターの保護は、効果的な解決策が存在しない新たな問題となります。
上海交通大学の Lin Zhouhan 教授の Lumia 研究チームは、大規模モデル間の祖先関係を特定できる革新的なテクノロジーを開発しました。このアプローチでは、モデル パラメーターを公開せずに、人間が判読できる大規模モデルのフィンガープリントを使用します。この技術の研究開発は、大型モデルの開発と応用にとって非常に重要な意味を持ちます。
この方法では 2 つの識別方法が提供されます。1 つは定量的な識別方法で、テストされた大規模モデルと一連のベース モデルの類似性を比較することで、事前トレーニングされたベース モデルが盗まれたかどうかを判断します。もう 1 つは定量的な識別方法です。は、人間が判読できる「犬の絵」を生成することで、モデル間の継承関係を迅速に発見する定性的判断手法です。

6 つの異なる基本モデル (最初の行) とそれらの対応する子孫モデル (下の 2 行) のフィンガープリント。

#人間が判読できる大規模モデルのフィンガープリントが 24 個の異なる大規模モデルに対して生成されました。
動機と全体的なアプローチ
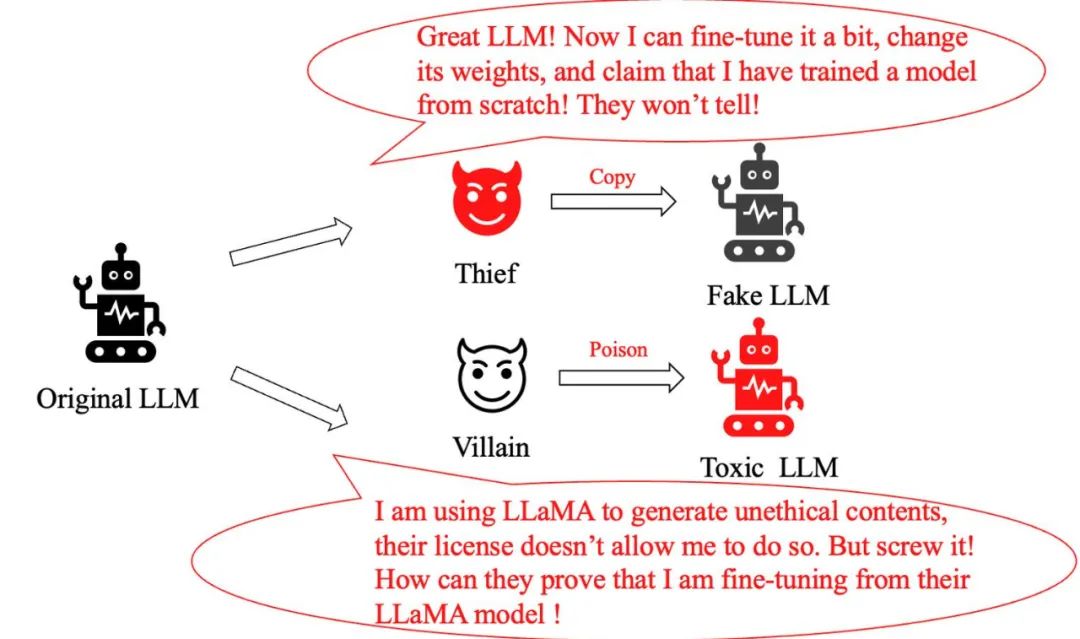
大規模モデルの急速な開発により、幅広い応用の可能性がもたらされましたが、同時にそれが引き金となりました。新たな挑戦の連続。未解決の問題としては、次の 2 つが挙げられます。モデル盗難問題 : 元の大型モデルにわずかな調整を加えただけの賢い「泥棒」が、次のように主張しました。まったく新しいモデルを作成し、自分の貢献を誇張しました。海賊版モデルかどうかをどのように特定すればよいでしょうか?
モデル悪用問題: 犯罪者が LLaMA モデルを悪意を持って変更し、それを使用して有害な情報を生成した場合、たとえメタのポリシーでこの行為が明確に禁止されていたとしても、どうすればよいでしょうか。 LLaMA モデルを使用していることを証明しますか?


実験から観察された不変項 #交通大学のチームは、大規模なモデルを微調整したり、さらに事前学習したりすると、これらのモデルのパラメーター ベクトルの方向がわずかに変化することを発見しました。対照的に、最初からトレーニングされた大規模なモデルの場合、そのパラメーターの方向は他の基本モデルとは完全に異なります。
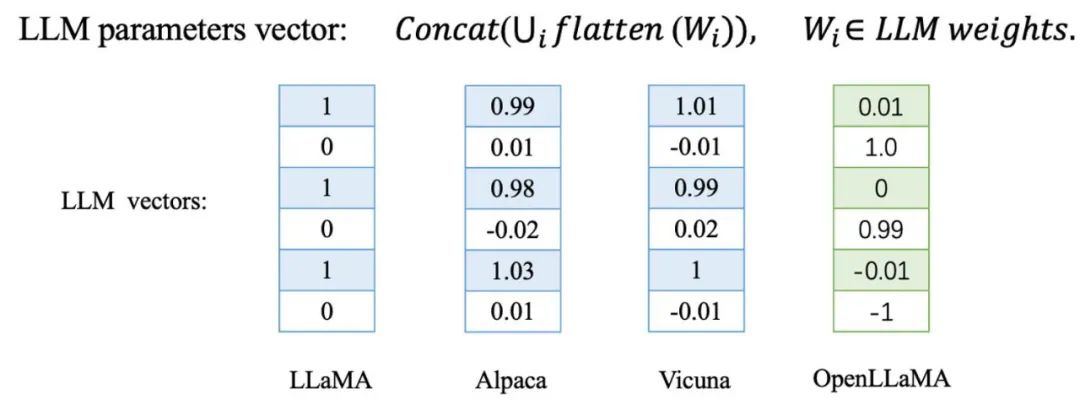 これらは、LLaMA の微調整によって取得された Alpaca と Vicuna、さらに事前トレーニングによって取得された Chinese LLaMA および Chinese LLaMA を含む、LLaMA の一連の派生モデルで検証されました。 LLaMAチャイニーズアルパカ。さらに、Baichuan や Shusheng など、独自にトレーニングされた基本モデルもテストしました。
これらは、LLaMA の微調整によって取得された Alpaca と Vicuna、さらに事前トレーニングによって取得された Chinese LLaMA および Chinese LLaMA を含む、LLaMA の一連の派生モデルで検証されました。 LLaMAチャイニーズアルパカ。さらに、Baichuan や Shusheng など、独自にトレーニングされた基本モデルもテストしました。  表内で青色でマークされた LLaMA 微分モデルと LLaMA-7B ベース モデルは、パラメーター ベクトルにおいて非常に高いコサイン類似性を示します。これは、これらの微分モデルがであることを意味します。パラメータ ベクトル方向ではベース モデルに非常に近くなります。対照的に、赤色でマークされた独立してトレーニングされたベース モデルは、パラメーター ベクトルの方向がまったく関係なく、まったく異なる状況を示しています。
表内で青色でマークされた LLaMA 微分モデルと LLaMA-7B ベース モデルは、パラメーター ベクトルにおいて非常に高いコサイン類似性を示します。これは、これらの微分モデルがであることを意味します。パラメータ ベクトル方向ではベース モデルに非常に近くなります。対照的に、赤色でマークされた独立してトレーニングされたベース モデルは、パラメーター ベクトルの方向がまったく関係なく、まったく異なる状況を示しています。 これらの観察に基づいて、彼らはこの経験的規則性に基づいてモデルのフィンガープリントを作成できるかどうかを検討しました。ただし、重要な疑問が残ります。このアプローチは悪意のある攻撃に対して十分に堅牢ですか?
これを検証するために、研究チームはLLaMAを微調整する際のペナルティ損失としてモデル間のパラメータの類似性を追加し、モデルのパラメータの方向がベースモデルから可能な限り逸脱するようにしました。パフォーマンスを維持しながら元のパラメータの方向から逸脱するかどうかをテスト モデルで微調整できます。
 元のモデルとペナルティ損失を追加して得られたモデルをテストしました。 -BoolQ や MMLU などの 8 つのベンチマークでチューニング。以下のグラフからわかるように、コサイン類似度が低下すると、モデルのパフォーマンスが急速に低下します。これは、ベース モデルの機能を損なうことなく、元のパラメータの方向から逸脱することが非常に難しいことを示しています。
元のモデルとペナルティ損失を追加して得られたモデルをテストしました。 -BoolQ や MMLU などの 8 つのベンチマークでチューニング。以下のグラフからわかるように、コサイン類似度が低下すると、モデルのパフォーマンスが急速に低下します。これは、ベース モデルの機能を損なうことなく、元のパラメータの方向から逸脱することが非常に難しいことを示しています。 
 現在、大規模モデルのパラメータ ベクトルの方向は、その基本モデルを識別するための非常に効果的かつ堅牢な指標となっています。ただし、パラメータ ベクトルの方向を識別ツールとして直接使用する場合には、いくつかの問題があるようです。まず、このアプローチではモデルのパラメーターを明らかにする必要がありますが、これは多くの大規模モデルでは受け入れられない可能性があります。第 2 に、攻撃者はモデルのパフォーマンスを犠牲にすることなく、隠れユニットを単純に置き換えてパラメータ ベクトルの方向を攻撃できます。
現在、大規模モデルのパラメータ ベクトルの方向は、その基本モデルを識別するための非常に効果的かつ堅牢な指標となっています。ただし、パラメータ ベクトルの方向を識別ツールとして直接使用する場合には、いくつかの問題があるようです。まず、このアプローチではモデルのパラメーターを明らかにする必要がありますが、これは多くの大規模モデルでは受け入れられない可能性があります。第 2 に、攻撃者はモデルのパフォーマンスを犠牲にすることなく、隠れユニットを単純に置き換えてパラメータ ベクトルの方向を攻撃できます。 Transformer のフィードフォワード ニューラル ネットワーク (FFN) を例にとると、隠れユニットを置き換え、それに応じて重みを調整するだけで、ネットワーク出力を変更せずに重みの方向を実現できます。
 #さらに、チームは、大規模モデルの単語埋め込みに対する線形マッピング攻撃とディスプレイスメント攻撃の詳細な分析も実施しました。これらの調査結果は、「このような多様な攻撃手法に直面した場合、どのように効果的に対応し、問題を解決すればよいのか」という疑問を引き起こします。
#さらに、チームは、大規模モデルの単語埋め込みに対する線形マッピング攻撃とディスプレイスメント攻撃の詳細な分析も実施しました。これらの調査結果は、「このような多様な攻撃手法に直面した場合、どのように効果的に対応し、問題を解決すればよいのか」という疑問を引き起こします。 彼らは、パラメータ行列間の乗算によって攻撃行列を排除することにより、これらの攻撃に対して堅牢な 3 セットの不変式を導き出しました。
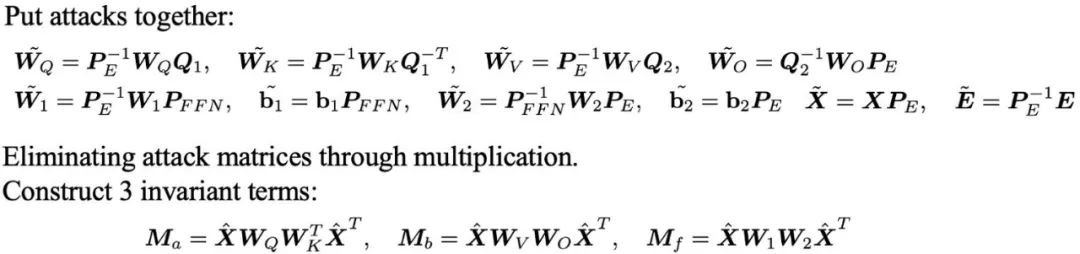
上で導出した不変式は大規模な識別マーカーとしては十分ですが、通常、これらは巨大な行列の形式で表示されますが、これは直感的ではないだけでなく、異なる大規模なモデル間の関係を決定するために追加の類似度計算が必要になります。この情報を表示する、より直感的でわかりやすい方法はありますか?
この問題を解決するために、上海交通大学チームは、モデル パラメーターから人間が判読できる指紋を生成する方法、HUREF を開発しました。
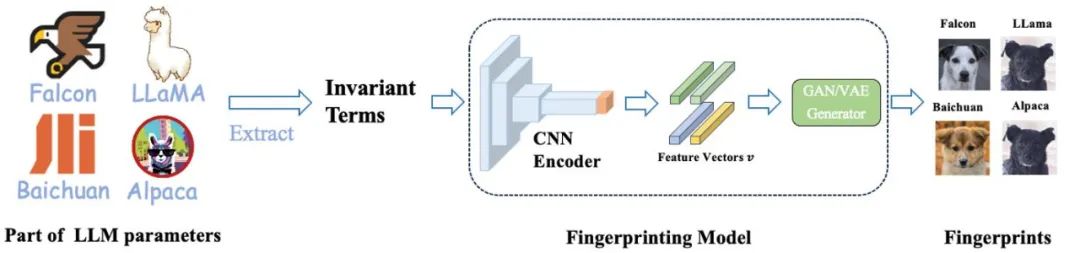
彼らは、最初に大規模モデルのいくつかのパラメーターから不変量を抽出し、次に CNN エンコーダーを使用して、局所性を維持しながら不変行列を従うメソッドにエンコードしました。ガウス分布特徴ベクトル、そして最後に使用します。これらの特徴ベクトルを視覚的な画像 (つまり、犬の写真) にデコードするための画像ジェネレーターとしてのスムーズ GAN または VAE。これらの画像は人間が判読できるだけでなく、異なるモデル間の類似性を視覚的に示し、大規模モデルの「視覚的指紋」として効果的に機能します。以下は、トレーニングと推論の詳細なプロセスです。

このフレームワークでは、トレーニングが必要な部分は CNN エンコーダーのみです。彼らは、対比学習を使用してエンコーダーのローカル保存を保証する一方、敵対的生成学習を使用して、特徴ベクトルが GAN または VAE ジェネレーターの入力空間と一致するガウス分布に従うことを保証します。
重要なのは、トレーニング プロセス中に実際のモデル パラメーターを使用する必要がなく、すべてのデータが正規分布サンプリングを通じて取得されることです。実際のアプリケーションでは、トレーニングされた CNN エンコーダーと、AFHQ 犬データセットでトレーニングされた既製の StyleGAN2 ジェネレーターが推論に直接使用されます。
さまざまな大規模モデルのフィンガープリントの生成
この方法の有効性を検証するために、チームは広く使用されているさまざまな大規模モデルで実験を実施しました。彼らは、Falcon、MPT、LLaMA2、Qwen、Baichuan、InternLM などのいくつかのよく知られたオープンソースの大規模モデルとその派生モデルを選択し、これらのモデルの不変量を計算して、以下の図に示すようなフィンガープリント イメージを生成しました。 . .

派生モデルのフィンガープリントは元のモデルと非常によく似ており、画像からどのプロトタイプ モデルに基づいているのかを直感的に識別できます。さらに、これらの派生モデルは、不変量に関して元のモデルとの高いコサイン類似性も維持します。
その後、彼らは、SFT によって取得された Alpaca と Vicuna を含む LLaMA ファミリーのモデル、拡張された中国語語彙を備えたモデル、さらなる事前学習によって取得された中国語 LLaMA と BiLLa、RLHF Beaver とマルチモーダルを含むモデルの広範なテストを実施しました。モデル Minigpt4 など

表は、LLaMA ファミリ モデル間の不変量のコサイン類似度を示しています。同時に、図は、これら 14 のモデルに対して生成された指紋画像を示しています。まだ非常に高いです。指紋画像からそれらが同じモデルからのものであると判断できますが、これらのモデルが SFT、さらなる事前学習、RLHF、マルチモダリティなどのさまざまな異なる学習方法をカバーしていることは注目に値します。その後のさまざまなトレーニング パラダイムにおける大規模モデルの堅牢性。
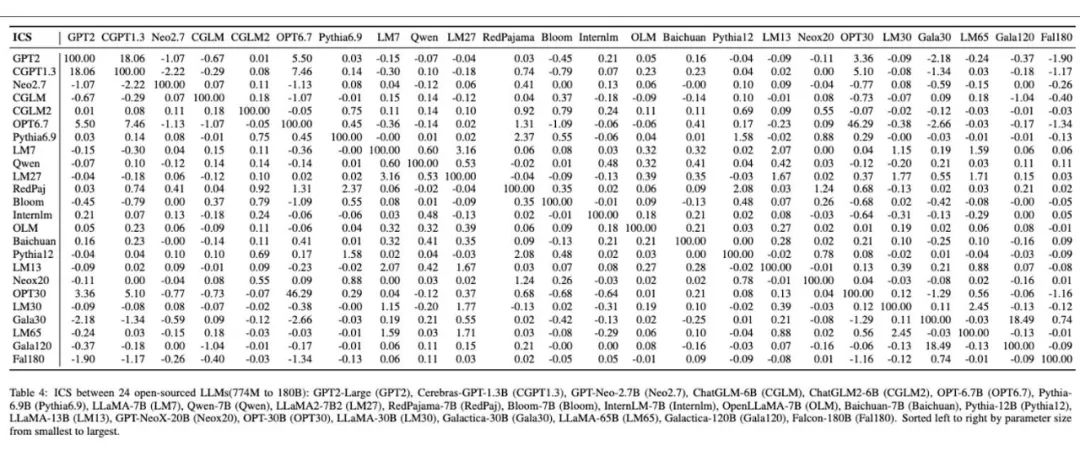
さらに、下の図は、独立してトレーニングされた 24 個のオープンソースの基本モデルに対して実施された実験結果です。彼らの方法により、それぞれの独立した基本モデルに固有の指紋画像が与えられ、異なる大型モデル間の指紋の多様性と違いが鮮明に示されます。表では、これらのモデル間の類似性の計算結果は、指紋画像に示された差異と一致しています。

最後に、チームは小規模で独立してトレーニングされた言語モデルのパラメーター方向の一意性と安定性をさらに検証しました。彼らは、Pile データセットの 10 分の 1 を使用して、4 つの GPT-NeoX-350M モデルを最初から事前トレーニングしました。
これらのモデルはセットアップにおいて同一ですが、唯一の違いは、異なる乱数シードを使用することです。以下のグラフから、乱数シードの違いだけがモデル パラメーターの方向とフィンガープリントに大きく異なることは明らかです。これは、独立してトレーニングされた言語モデル パラメーターの方向の一意性を完全に示しています。

最後に、隣接するチェックポイントの類似性を比較することで、事前トレーニング プロセス中にモデルのパラメーターが徐々に安定する傾向があることがわかりました。彼らは、この傾向はトレーニング ステップが長くなり、モデルが大規模になるほどより顕著になると考えており、これが彼らの手法の有効性を部分的に説明しています。

以上が大型模型にも泥棒がいる?パラメータを保護するには、大きなモデルを送信して「人間が判読できる指紋」を作成してください。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。