Lightning Attendance-2 は、長いシーケンスのトレーニングと推論のコストを 1K シーケンス長のコストと一致させる、新しい線形アテンション メカニズムです。
大規模な言語モデルのシーケンス長の制限により、マルチターン対話などの人工知能の分野での応用が大幅に制限されてきました。長文理解、マルチモーダルデータの処理と生成などこの制限の根本的な理由は、現在の大規模言語モデルで使用されている Transformer アーキテクチャが、シーケンスの長さに比べて 2 次の計算複雑さを持っていることです。これは、シーケンスの長さが増加すると、必要なコンピューティング リソースが指数関数的に増加することを意味します。長いシーケンスを効率的に処理する方法は、大規模な言語モデルの常に課題の 1 つでした。 以前の方法では、推論段階で大規模な言語モデルをより長いシーケンスに適応させる方法に焦点を当てていることがよくありました。たとえば、Alibi または同様の相対位置コーディング手法を使用して、モデルをさまざまな入力シーケンス長に適応させることができます。また、RoPE などの同様の相対位置コーディング手法を使用して差分を実行し、モデルに対してさらなるトレーニングを実行することもできます。シーケンス長を増幅するという目的を達成するために、短期間の微調整が実行されます。これらの方法では、大規模なモデルに特定の長いシーケンスのモデリング機能のみが許可されますが、実際のトレーニングと推論のオーバーヘッドは削減されていません。 #OpenNLPLab チームは、大規模な言語モデルの長シーケンス問題を完全に解決しようとしています。彼らは、長いシーケンスのトレーニングと推論のコストを 1K シーケンス長のコストと一致させる新しい線形アテンション メカニズムである Lightning Attendance-2 を提案し、オープンソース化しました。メモリのボトルネックが発生する前に、シーケンスの長さを無制限に増やしても、モデルのトレーニング速度に悪影響を与えることはありません。これにより、無制限の長さの事前トレーニングが可能になります。同時に、非常に長いテキストの推論コストも 1,000 トークンのコストと一致するか、それ以下になるため、現在の大規模な言語モデルの推論コストが大幅に削減されます。下図に示すように、モデルサイズ 400M、1B、3B では、系列長が増加するにつれて、FlashAttendant2 がサポートする LLaMA の学習速度は急激に低下し始めますが、Lightning Attendant-2 がサポートする TansNormerLLM の速度は低下しています。ほとんど変化なし。 ###############図1############
- 論文: ライトニング アテンション-2: 大規模な言語モデルで無制限のシーケンス長を処理するための無料ランチ
- 論文のアドレス: https://arxiv.org / pdf/2401.04658.pdf
- オープンソースのアドレス: https://github.com/OpenNLPLab/lightning-attention
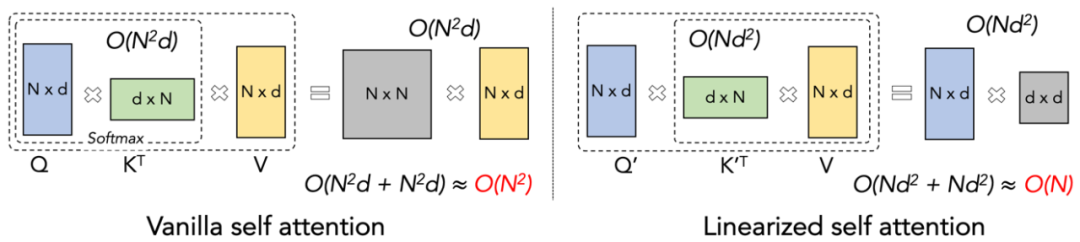
大規模モデルの事前トレーニング速度を、異なるシーケンス長にわたって一貫して維持すること、これが重要です。不可能なミッションのように聞こえます。実際、これは、アテンション メカニズムの計算の複雑さがシーケンスの長さに対して線形のままであれば達成できます。 2020 年に線形アテンション [https://arxiv.org/abs/2006.16236] が登場して以来、研究者たちは線形アテンションの実際の効率を理論上の線形計算の複雑さと一致させるために懸命に取り組んできました。 2023 年以前は、リニア アテンションに関するほとんどの研究は、精度をトランスフォーマーと一致させることに焦点を当てていました。最終的に 2023 年半ばには、改良されたリニア アテンション メカニズム [https://arxiv.org/abs/2307.14995] を最先端の Transformer アーキテクチャと正確に一致させることができます。ただし、最も重要な「左乗算から右乗算」の計算トリック (下図を参照) は、計算量を線形アテンションで線形に変更します (下図を参照) が、実際には直接左乗算アルゴリズムよりもはるかに遅くなります。実装。その理由は、右乗算の実装には多数のループ演算を含む累積加算 (cumsum) を使用する必要があり、大量の IO 演算により右乗算の効率が左乗算よりも大幅に低下するためです。
Lightning をより深く理解するには、アテンション 2 のアイデアでは、まず伝統的なソフトマックス アテンションの計算式を確認してみましょう: O=softmax ((QK^T)⊙M_) V、ここで Q、K、V、M、O はクエリ、キー、マスクと出力行列、ここでの M は、一方向タスク (GPT など) では下三角の all-1 行列ですが、双方向タスク (Bert など) では無視できます。双方向タスクにはマスク行列はありません。
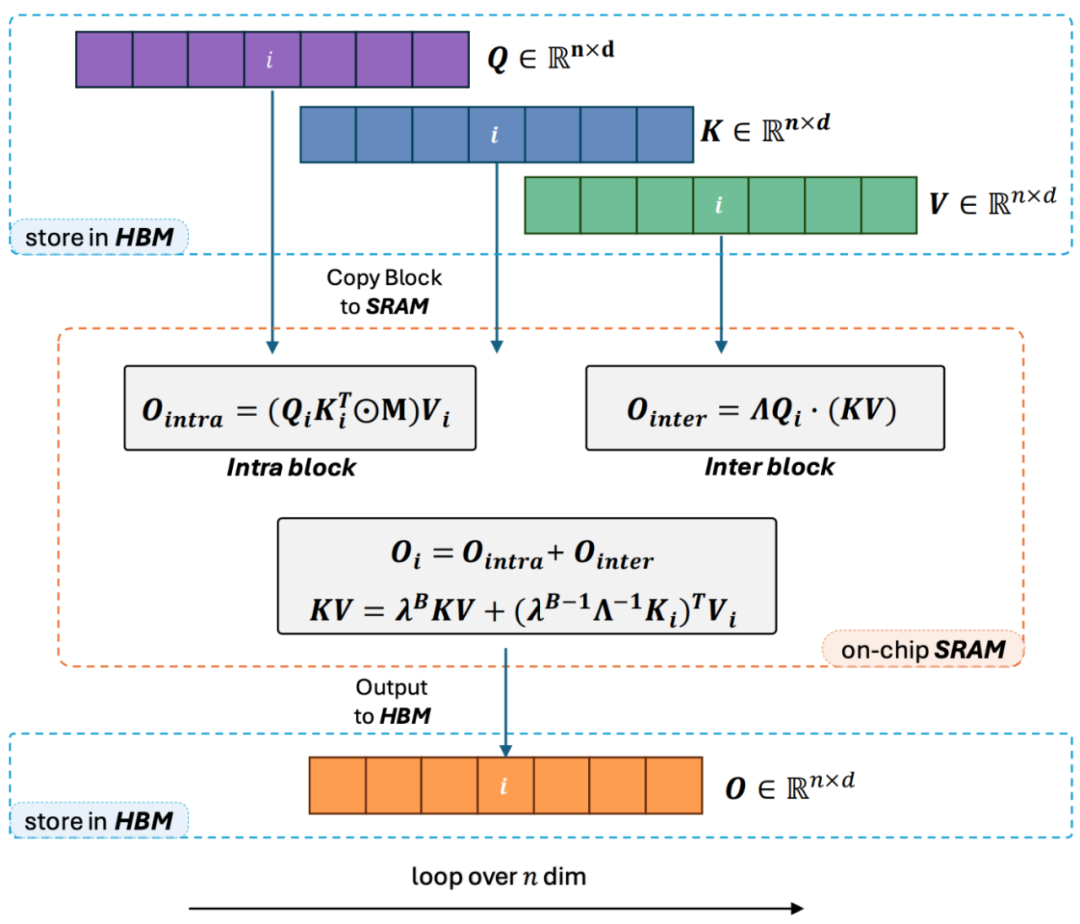
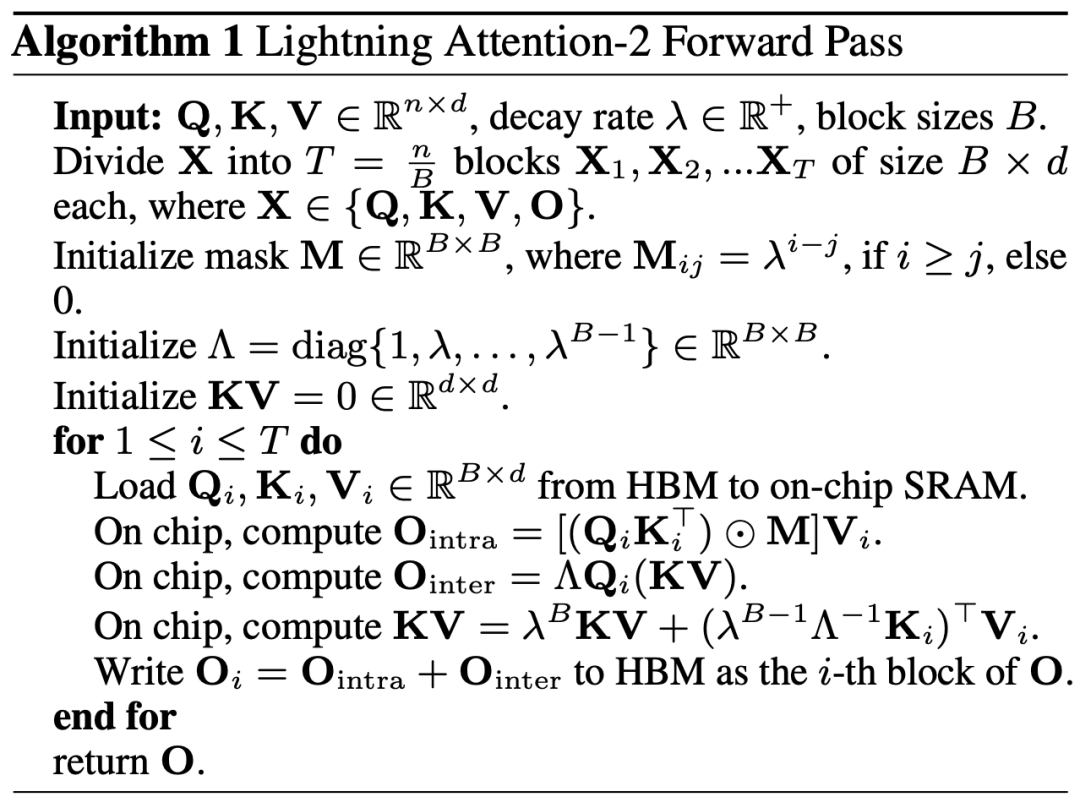
#著者は、Lightning Attendance-2 の全体的な考え方を次の 3 つのポイントにまとめて説明します。 #1. 線形 アテンションの核となるアイデアの 1 つは、計算コストのかかるソフトマックス演算子を削除して、アテンションの計算式を O=((QK^T)⊙M_) V として記述できるようにすることです。ただし、一方向タスクにはマスク行列 M が存在するため、この形式でも左乗算の計算しか実行できないため、O (N) の複雑さは得られません。しかし、双方向タスクの場合、マスク行列がないため、Linear Attendant の計算式は O=(QK^T) V にさらに簡略化できます。 Linear Attendant の微妙な点は、行列乗算の結合法則を使用するだけで、その計算式が O=Q (K^T V) にさらに変換できることです。この計算形式は右乗算と呼ばれ、対応する前者は次のようになります。左。図 2 から、リニア アテンションが双方向タスクにおいて魅力的な O (N) の複雑さを実現できることが直感的に理解できます。 2. ただし、デコーダのみの GPT モデルが徐々に LLM の事実上の標準になるにつれ、一方向を高速化するために Linear Attendant の適切な乗算機能を使用する方法が難しくなります。タスクが緊急に必要になったので、パズルを解決しました。この問題を解決するために、この記事の著者は、「分割統治」の考え方を使用して、注意行列の計算を対角行列と非対角行列の 2 つの形式に分割し、異なるものを使用することを提案しました。それらを計算する方法。図 3 に示すように、Linear Attendant-2 は、コンピューター分野で一般的に使用されるタイルの考え方を使用して、Q、K、および V 行列を同じ数のブロックに分割します。このうち、ブロック自体の計算 (ブロック内) はマスク行列の存在により左の乗算計算方法が残り、複雑度は O (N^2) ですが、ブロックの計算 (ブロック間) はマスク行列の存在により左の乗算計算方法が維持されます。 block) にはマスク行列がありませんが、 の存在により、適切な乗算計算方法を使用して O (N) の複雑さを楽しむことができます。 2 つを別々に計算した後、これらを直接加算して、i 番目のブロックに対応するリニア アテンション出力 Oi を取得できます。同時に、KV の状態がcumsum によって蓄積され、次のブロックの計算に使用されます。このように、ライトニング アテンション 2 全体のアルゴリズムの複雑さは、ブロック内トレードオフで O (N^2)、ブロック間トレードオフで O (N) になります。より良いトレードオフを得る方法は、タイリングのブロック サイズによって決まります。 3. 注意深い読者であれば、上記のプロセスは Lightning Attendant-2 のアルゴリズム部分にすぎないことがわかります。Lightning と名付けられたのは、作者がこの問題を十分に考慮したためです。 GPU ハードウェア実行における効率の問題のアルゴリズム プロセス。 FlashAttend の一連の作業からインスピレーションを得て、実際に GPU 上で計算を実行する際、作者は分割された Q_i、K_i、V_i テンソルを、GPU 内の容量が大きく低速な HBM から容量が小さく高速な SRAM に移動しました。これにより、大量のメモリ IO オーバーヘッドが削減されます。ブロックが Linear Attendance の計算を完了すると、その出力結果 O_i は HBM に戻されます。すべてのブロックが処理されるまで、このプロセスを繰り返します。 さらに詳細を知りたい読者は、この記事のアルゴリズム 1 とアルゴリズム 2、および論文の詳細な導出プロセスを注意深く読むことができます。アルゴリズムと導出プロセスの両方で、Lightning Attendant-2 の順方向プロセスと逆方向プロセスが区別されており、読者の理解を深めるのに役立ちます。 
#画像 3
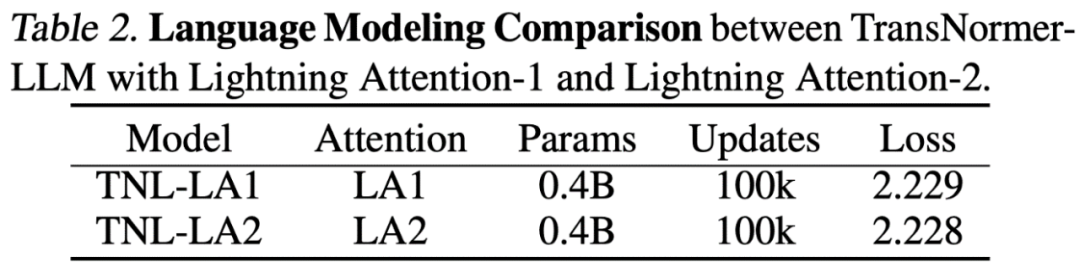
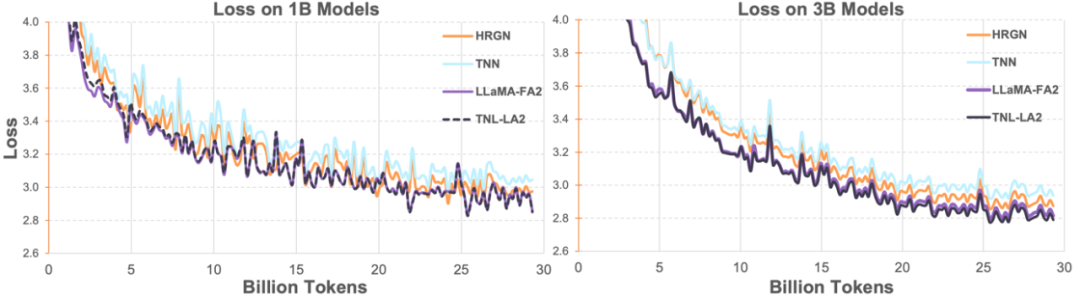
Lightning Attendant-2 の精度比較研究者らはまず、小規模 (400M) パラメータで Lightning Attendant-2 と Lightning Attendant-1 の精度の違いを比較しました。モデル 、以下の図に示すように、両者の間にほとんど違いはありません。
研究者らは次に、Lightning Attendant-2 を利用した TransNormerLLM (TNL-LA2) を、他の高度な非 Transformer アーキテクチャ ネットワークおよび FlashAttendant2 を利用した LLaMA と 1B および 3B で組み合わせました。同じコーパスの下に作成されています。以下の図に示すように、TNL-LA2 と LLaMA は同様の傾向を維持しており、損失パフォーマンスが優れています。この実験は、Lightning Attendant-2 が言語モデリングにおいて最先端の Transformer アーキテクチャに劣らない精度パフォーマンスを備えていることを示しています。
大規模言語モデル タスクでは、研究者らは、同様のサイズの大規模モデルの一般的なベンチマークで TNL-LA2 15B と Pythia の結果を比較しました。以下の表に示すように、同じトークンを食べるという条件の下では、TNL-LA2 は常識推論と多肢選択の包括的能力において Softmax 注意に基づく Pythia モデルよりわずかに高くなります。
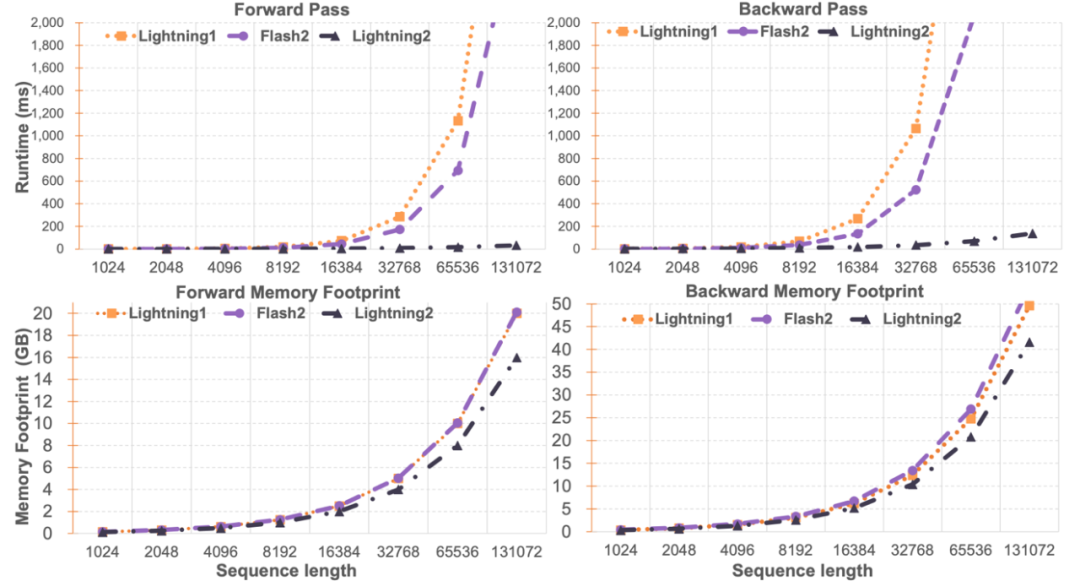
研究者によるライトニング アテンション 2 の比較と FlashAttend2 は、単一モジュールの速度とメモリ使用量を比較しました。以下の図に示すように、Lightning Attendant-1 および FlashAttendant2 と比較すると、Lightning Attendant-2 はシーケンスの長さに比べて速度が厳密に直線的に増加しています。メモリ使用量に関しては、3 つすべてが同様の傾向を示していますが、Lightning Attendant-2 のメモリ使用量は小さくなっています。その理由は、FlashAttendant2 と Lightning Attendant-1 のメモリ使用量もほぼ線形であるためです。
著者は、この記事の主な焦点が線形注意ネットワークのトレーニング速度を解決し、1K シーケンスに類似した任意の長さの長いシーケンスのトレーニングを達成することにあることに気づきました。スピード。推論速度に関してはあまり紹介されていません。これは、推論中に線形アテンションをロスレスで RNN モードに変換できるため、同様の効果、つまり単一トークンの推論速度が一定になるためです。 Transformer の場合、現在のトークンの推論速度は、その前のトークンの数に関係します。
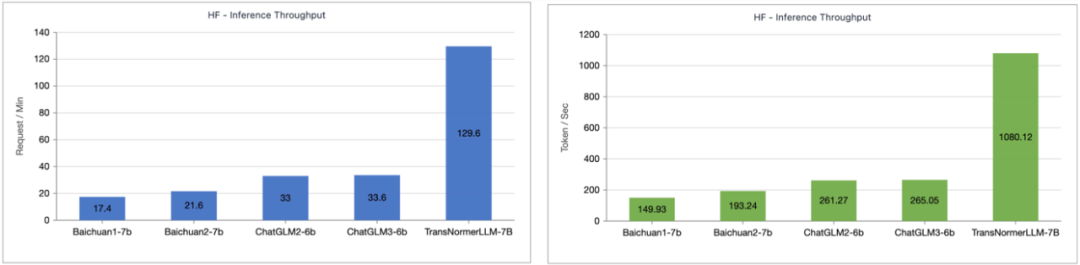
著者は、Lightning Attendant-1 でサポートされている TransNormerLLM-7B と一般的な 7B モデルの間の推論速度の比較をテストしました。以下の図に示すように、おおよそのパラメータ サイズの下で、Lightning Attendant-1 のスループット速度は Baichuan の 4 倍、ChatGLM の 3.5 倍以上であり、推論速度に優れた利点を示しています。
ライトニング アテンション 2 は、リニア アテンション メカニズムの大幅な進歩を表しており、精度と速度の両方において完璧です。 Softmax の注目は、将来的にますます大規模なモデルに持続可能なスケーラビリティを提供し、無限に長いシーケンスをより高い効率で処理する方法を提供します。 OpenNLPLab チームは、現在直面しているメモリ バリア問題を解決するために、将来的に線形アテンション メカニズムに基づく逐次並列アルゴリズムを研究する予定です。
以上がライトニング アテンション-2: 無限のシーケンス長、一定の計算能力コスト、およびより高いモデリング精度を実現する新世代のアテンション メカニズムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。