
ホームページ >テクノロジー周辺機器 >AI >小紅樹捜索チームが明らかにする:大規模モデル蒸留におけるネガティブサンプルの検証の重要性
小紅樹捜索チームが明らかにする:大規模モデル蒸留におけるネガティブサンプルの検証の重要性

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-17 11:51:051450ブラウズ

#大規模言語モデル (LLM) は推論タスクではうまく機能しますが、そのブラックボックス プロパティと多数のパラメーターにより、実際の適用は制限されます。特に複雑な数学的問題を扱う場合、LLM は誤った推論チェーンを開発することがあります。従来の研究方法では、陽性サンプルからの知識のみが伝達され、合成データ内の間違った答えを含む重要な情報は無視されます。したがって、LLM のパフォーマンスと信頼性を向上させるには、LLM が複雑な問題についてよりよく理解し、推論できるように、陽性サンプルに限定されるのではなく、合成データをより包括的に検討して利用する必要があります。これは、実際の LLM の課題を解決し、その広範な適用を促進するのに役立ちます。
AAAI 2024 で、Xiaohongshu 検索アルゴリズム チーム は革新的なフレームワークを提案しました。大規模なモデルの推論能力を抽出する過程でのマイナスのサンプル知識。ネガティブサンプル、つまり推論プロセス中に正しい答えが得られなかったデータは役に立たないとみなされがちですが、実際には貴重な情報が含まれています。
この論文では、大規模モデルの蒸留プロセスにおけるネガティブ サンプルの価値を提案および検証します、モデルの特化フレームワークを構築します。ポジティブ サンプルの使用に加えて、ネガティブサンプルも最大限に活用し、LLM の知識を磨きます。このフレームワークは、 ネガティブ支援トレーニング (NAT) 、 ネガティブ キャリブレーション強化 (NCE) 、および 動的自己一貫性 (ASC) を含む 3 つのシリアル化ステップで構成されており、以下をカバーします。トレーニングから推論までのプロセス全体。広範な一連の実験を通じて、LLM 知識の蒸留におけるネガティブ データの重要な役割を実証しました。
1. 背景
現在の状況では、思考連鎖 (CoT) に導かれて、大規模言語モデル (LLM) が強力な推論機能を実証しています。ただし、この新たな機能は、数千億のパラメータを持つモデルによってのみ実現できることを私たちは示しました。これらのモデルは膨大なコンピューティング リソースと高い推論コストを必要とするため、リソースの制約の下で適用するのは困難です。したがって、私たちの研究目標は、現実世界のアプリケーションに大規模に展開できる複雑な算術推論が可能な小型モデルを開発することです。
知識の蒸留は、LLM の特定の機能をより小さなモデルに移すための効率的な方法を提供します。このプロセスはモデルの特殊化とも呼ばれ、小規模なモデルに特定の機能に重点を置くことを強制します。これまでの研究では、LLM の文脈学習 (ICL) を利用して数学的問題の推論パスを生成し、それをトレーニング データとして使用することで、小さなモデルが複雑な推論能力を獲得するのに役立ちました。ただし、これらの研究では、正しい答えを持つ生成された推論パス (つまり、肯定的なサンプル) をトレーニング サンプルとしてのみ使用し、間違った答えを持つ推論ステップ (つまり、否定的なサンプル) の貴重な知識を無視しました。したがって、研究者は、小規模モデルのパフォーマンスを向上させるために、ネガティブ サンプルの推論ステップを利用する方法を検討し始めました。 1 つのアプローチは、敵対的トレーニングを使用することです。この場合、ジェネレーター モデルを導入して間違った答えの推論パスを生成し、これらのパスを肯定的な例とともに使用して小さなモデルをトレーニングします。このようにして、小規模モデルはエラー推論ステップで貴重な知識を学習し、推論能力を向上させることができます。もう 1 つのアプローチは、自己教師あり学習を使用することです。正解と不正解を比較し、小さなモデルにそれらを区別してそこから有用な情報を抽出することを学習させます。これらの方法は、小規模モデルに対してより包括的なトレーニングを提供し、より強力な推論機能を与えることができます。 つまり、負のサンプルで推論ステップを使用すると、小規模モデルがより包括的なトレーニングを取得し、推論能力を向上させるのに役立ちます。この
 #picture
#picture
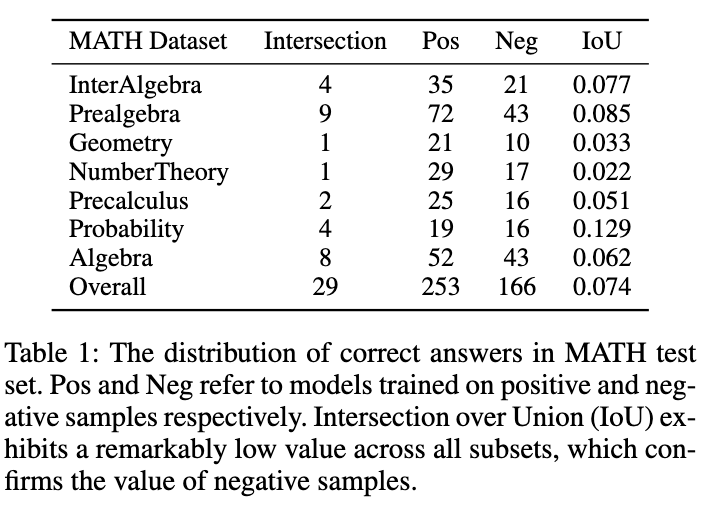
を図に示します。表 1 は、陽性サンプルと陰性サンプルそれぞれにおける興味深い現象を示しています。データに基づいてトレーニングされたモデルでは、MATH テスト セット上の正確な回答の重複は非常にわずかです。陰性サンプルを使用してトレーニングされたモデルは精度が低くなりますが、陽性サンプル モデルでは正しく回答できないいくつかの質問を解決でき、陰性サンプルに貴重な知識が含まれていることを確認できます。さらに、負のサンプル内の誤ったリンクは、モデルが同様の間違いを避けるのに役立ちます。ネガティブサンプルを活用すべきもう 1 つの理由は、OpenAI のトークンベースの価格戦略です。 MATH データセットに対する GPT-4 の精度でさえ 50% 未満です。これは、肯定的なサンプル知識のみが利用される場合、大量のトークンが無駄になることを意味します。したがって、ネガティブサンプルを直接破棄するのではなく、そこから貴重な知識を抽出して利用し、小規模モデルの特殊性を高める方が良い方法であると提案します。
モデルの特殊化プロセスは、一般的に 3 つのステップに要約できます。
1) 思考連鎖の蒸留、小規模モデルは次を使用してトレーニングされます。 LLM によって生成される推論チェーン。
2) モデルをさらに最適化するための自己強化、自己蒸留、またはデータの自己拡張。
3) 自己一貫性は、推論タスクにおけるモデルのパフォーマンスを向上させる効果的なデコード戦略として広く使用されています。
この研究では、ネガティブ サンプルを完全に活用し、LLM からの複雑な推論機能の抽出を容易にする新しいモデル特化フレームワークを提案します。
- 私たちはまず、 ネガティブ支援トレーニング (NAT) メソッドを設計しました。このメソッドでは、デュアル LoRA 構造が前方からトレーニングするように設計されています。否定的な方向の両方の知識を得る。補助モジュールとして、ネガティブ LoRA の知識は、修正注意メカニズムを通じてポジティブ LoRA のトレーニング プロセスに動的に統合できます。
- 自己強化のために、負の出力をベースラインとしてキーを強化する Negative Calibration Enhancement (NCE) を設計しました。前方推論リンクの抽出。
- #トレーニング段階に加えて、推論プロセス中にもネガティブな情報を利用します。従来の自己無矛盾性手法では、すべての候補出力に等しい重みまたは確率ベースの重みを割り当てるため、一部の信頼性の低い回答に投票することになります。この問題を軽減するために、投票前にソートする動的自己一貫性 (ASC) メソッドが提案されています。このメソッドでは、ソート モデルが正サンプルと負サンプルでトレーニングされます。 2. 方法
- #ステップ 1: ネガティブな LoRA をトレーニングし、ユニットのマージを通じてポジティブなサンプルの推論知識の学習を支援します。
-
#ステップ 2: 自己強化プロセスを調整するためのベースラインとしてネガティブな LoRA を使用します; -
##ステップ 3: ポジティブ サンプルとネガティブ サンプルでランキング モデルをトレーニングし、推論プロセス中のスコアに基づいて候補推論リンクを適応的に実行します。 - #写真
2.1 ネガティブ アシスタンス トレーニング (NAT)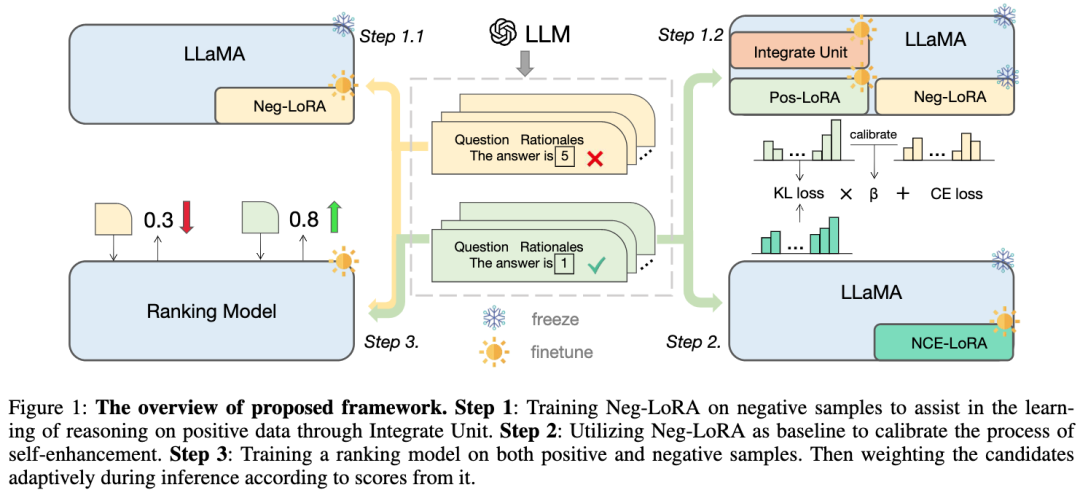
ネガティブ知識の吸収 と 動的統合ユニット
の 2 つの部分に分かれています。2.1.1 ネガティブな知識の吸収
ネガティブなデータを最大化することで、次のことが期待されます。陰性サンプルの知識は LoRA θ
によって吸収されること。このプロセス中、LLaMA のパラメータは凍結されたままになります。#図
2.1.2 動的統合ユニット
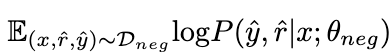 θ
θ
がどの数学問題が得意であるかを事前に判断することは不可能であるため、学習の過程で積極的に学習できるように、下図に示すような動的積分ユニットを設計しました。サンプル知識、動的統合は θ から得られます 知識:
写真
#社内知識の忘れ去られないようθ
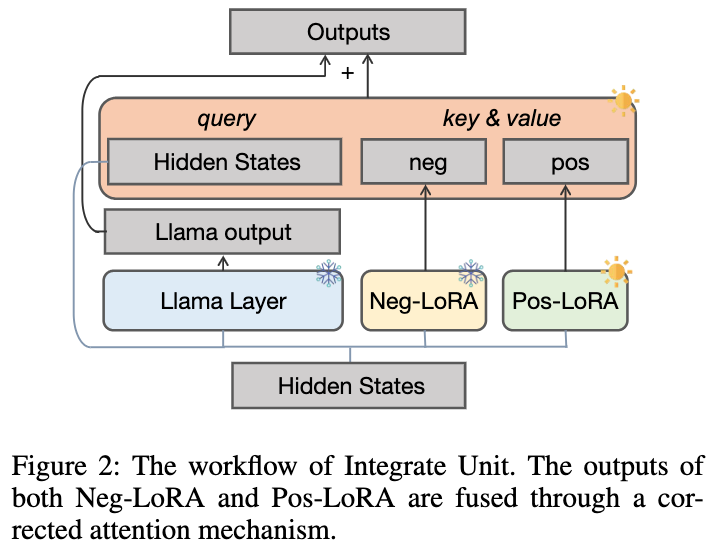
を凍結し、プラスのLoRAモジュールθを追加導入します。理想的には、正の LoRA モジュールと負の LoRA モジュール (各 LLaMA レイヤーの出力は と で表されます) を前方統合して、正のサンプルには欠けているが に対応する有益な知識を補う必要があります。 θ
 に有害な知識が含まれている場合、陽性サンプルで起こり得る悪い動作を減らすために、陽性と陰性の LoRA モジュールの陰性統合を実行する必要があります。
に有害な知識が含まれている場合、陽性サンプルで起こり得る悪い動作を減らすために、陽性と陰性の LoRA モジュールの陰性統合を実行する必要があります。
#この目標を達成するために、次のような修正注意メカニズムを提案します。
#写真
## #######写真######
をクエリとして使用し、 と の注意の重みを計算します。補正項[0.5; -0.5]を加えることで、注目重みを[-0.5, 0.5]の範囲に制限し、正負両方向の知識を適応的に統合する効果が得られる。最後に、
と LLaMA 層の出力の合計が動的統合ユニットの出力を形成します。
2.2 Negative Calibration Enhancement (NCE)
モデルの推論能力をさらに強化するために、Negative Calibration Enhancement (NCE) を提案しました。 )、自己強化のプロセスを助けるために否定的な知識を使用します。まず、NAT を使用して各質問の拡張サンプルとしてペアを生成し、トレーニング データセットに追加します。自己蒸留部分については、一部のサンプルには、モデルの推論機能を向上させるために重要な、より重要な推論ステップが含まれている可能性があることに注意してください。私たちの主な目標は、これらの重要な推論ステップを特定し、自己蒸留中の学習を強化することです。
# NAT には θ
に関する有用な知識がすでに含まれていることを考慮すると、NAT は θ
よりも優れています。 # 推論能力がより強い要因は、2 つの間の一貫性のない推論のリンクに暗黙的に含まれています。したがって、KL 発散を使用してこの矛盾を測定し、この式の期待値を最大化します。
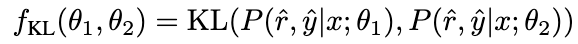 Picture
Picture
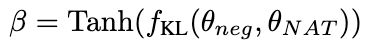 Picture
Picture
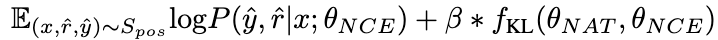 写真
写真
β の値が大きいほど、2 つの値の差が大きくなり、サンプルに含まれる量が多くなるということになります。重要な知識。 β を導入してさまざまなサンプルの損失重みを調整することで、NCE は NAT に埋め込まれた知識を選択的に学習して強化できるようになります。
2.3 動的自己一貫性 (ASC)
自己一貫性 (SC) は、複雑なモデルのパフォーマンスをさらに向上させるのに効果的です。の推論。ただし、現在の方法では、各候補に等しい重みを割り当てるか、単に生成確率に基づいて重みを割り当てるかのいずれかです。これらの戦略では、投票段階で (r^, y^) の品質に応じて候補の重みを調整できないため、正しい候補を選択することが困難になる可能性があります。この目的を達成するために、動的自己無撞着法 (ASC) を提案します。これは、正と負のデータを利用してランキング モデルをトレーニングし、候補推論リンクを適応的に再重み付けすることができます。
2.3.1 ランキング モデルのトレーニング
理想的には、ランキング モデルは、正解 推論リンクにはより高い重みが割り当てられ、その逆も同様です。したがって、次の方法でトレーニング サンプルを構築します:
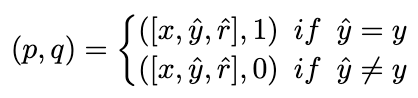 Picture
Picture
そして、MSE 損失を使用してランキング モデルをトレーニングします。
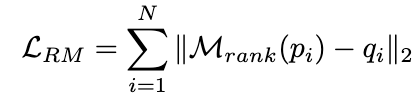 図
図
2.3.2 重み付け戦略
We will 候補の推論リンクを適応的に再重み付けするという目標を達成するために、投票戦略が次の式に変更されます:
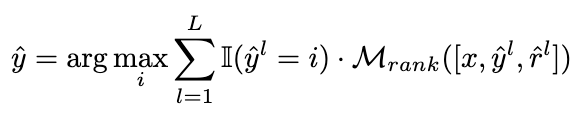 Picture
Picture
# Next 図は、ASC 戦略のプロセスを示しています。
 図
図
#知識移転の観点から、ASC は移転を実現します。 LLM からのデータを活用して、小規模モデルのパフォーマンス向上を支援するために、知識 (肯定的および否定的) をさらに活用します。
3. 実験
この研究は、7 つの異なる被験者に関する合計 12,500 の質問を含む、難解な数学的推論データセット MATH に焦点を当てています。さらに、配布外 (OOD) データに対する提案されたフレームワークの一般化能力を評価するために、GSM8K、ASDiv、MultiArith、SVAMP の 4 つのデータセットを紹介します。
教師モデルの場合、Open AI の gpt-3.5-turbo および gpt-4 API を使用して推論チェーンを生成します。スチューデントモデルにはLLaMA-7bを選択します。
私たちの研究には主に 2 つのタイプのベースラインがあります。1 つは大規模言語モデル (LLM) で、もう 1 つは LLaMA-7b に基づいています。 LLM については、GPT3 と PaLM という 2 つの人気のあるモデルと比較します。 LLaMA-7b については、まず、少数ショット、微調整 (元のトレーニング サンプル上)、CoT KD (思考連鎖蒸留) の 3 つの設定と比較するための方法を示します。ネガティブな観点からの学習に関しては、MIX (ポジティブ データとネガティブ データの混合物を使用して LLaMA を直接トレーニング)、CL (対照学習)、NT (ネガティブ トレーニング)、および UL (非尤度損失) の 4 つのベースライン手法も含まれます。 ))。
3.1 NAT 実験結果
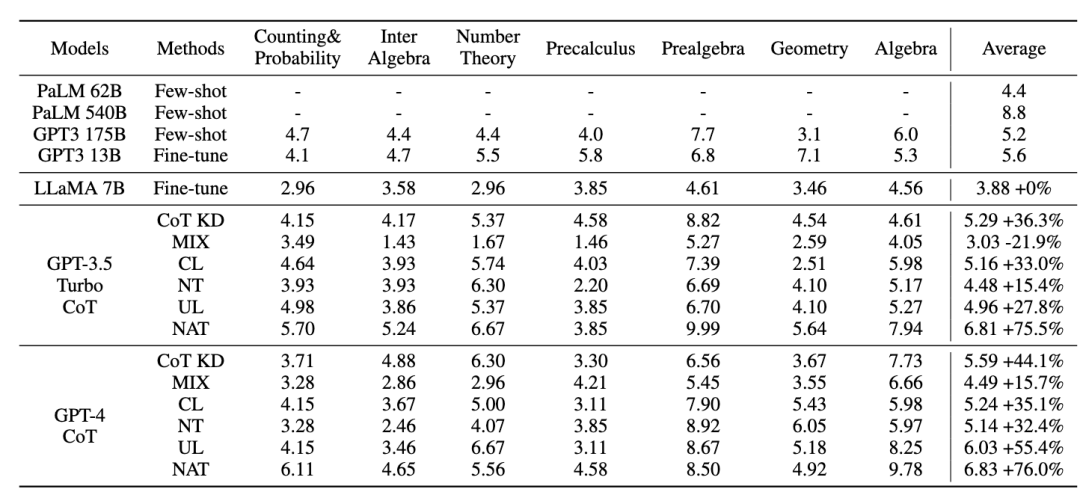
すべてのメソッドは貪欲検索 (つまり、温度 = 0) を使用します。NAT 実験結果は図に示すとおりです。結果は、提案された NAT 方法がすべてのベースラインでタスクの精度を向上させることを示しています。
GPT3 と PaLM の低い値からわかるように、MATH は非常に難しい数学的データ セットですが、NAT は非常に少ないパラメータでも良好なパフォーマンスを発揮します。生データの微調整と比較して、NAT は 2 つの異なる CoT ソースの下で約 75.75% の改善を達成します。また、NAT は、陽性サンプルの CoT KD と比較して精度を大幅に向上させ、陰性サンプルの価値を実証します。
ネガティブ情報ベースラインを利用する場合、MIX のパフォーマンスが低いということは、ネガティブ サンプルを直接トレーニングするとモデルのパフォーマンスが低下することを示しています。他の方法もほとんどが NAT より劣っており、複雑な推論タスクでは負の方向の負のサンプルのみを使用するだけでは不十分であることがわかります。
 写真
写真
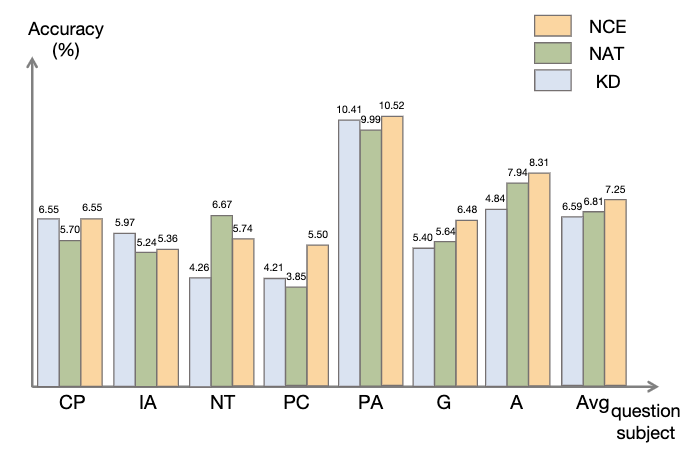
3.2 NCE実験結果
図に示すように、知識蒸留 (KD) と比較して、NCE は平均 10% (0.66) の改善を達成しています。これは、ネガティブ サンプルによって提供されるキャリブレーション情報を使用した蒸留の有効性を示しています。 NAT と比較すると、NCE は一部のパラメータを削減しますが、それでも 6.5% 向上しており、モデルを圧縮してパフォーマンスを向上させるという目的は達成されています。
 写真
写真
3.3 ASC 実験結果
ASC を評価するには、次のことを行います。サンプリング温度 T = 1 を使用して 16 個のサンプルを生成し、ベース SC および加重 (WS) SC と比較されます。図に示すように、結果は、さまざまなサンプルから回答を集約する ASC がより有望な戦略であることを示しています。
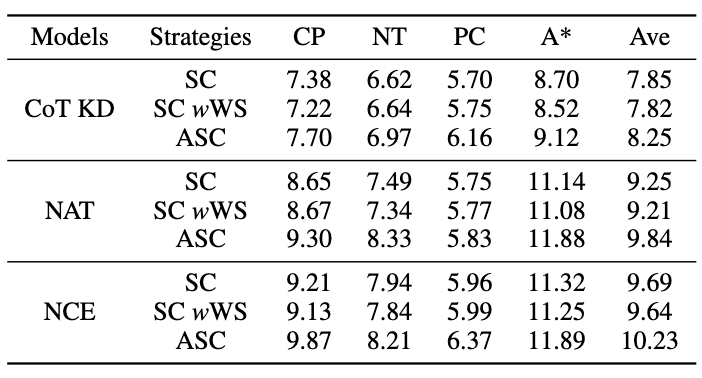 図
図
3.4 一般化実験の結果
MATH データセットを除いて、他の数学的推論タスクにおけるフレームワークの汎化能力を評価した結果は次のとおりです。
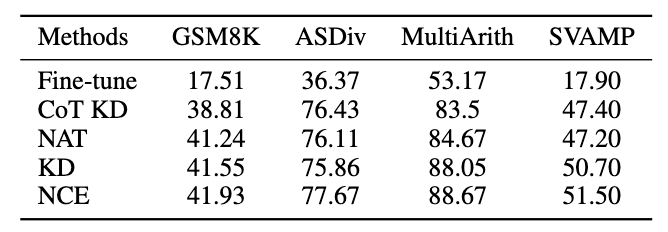 写真
写真
IV. 結論
この研究では、大規模なデータからデータを抽出するためのネガティブ サンプルの使用について検討します。言語モデル 複雑な推論機能を改良し、それを特化した小さなモデルに移行することの有効性。 Xiaohongshu 検索アルゴリズム チーム は、3 つのシリアル化ステップで構成され、モデル特化のプロセス全体を通じてネガティブな情報を最大限に活用する、まったく新しいフレームワークを提案しました。 ネガティブ アシスタンス トレーニング (NAT) は、2 つの観点からネガティブな情報を活用するためのより包括的な方法を提供します。 Negative Calibration Enhancement (NCE) は、より的を絞った方法で重要な知識を習得できるように、自己蒸留プロセスを調整できます。両方の観点でトレーニングされたランキング モデルは、回答の集計により適切な重みを割り当てて、動的自己一貫性 (ASC) を実現できます。広範な実験により、私たちのフレームワークが、生成されたネガティブサンプルを通じて推論能力を洗練する効果を向上させることができることが示されています。
紙のアドレス: https://www.php.cn/link/8fa2a95ee83cd1633cfd64f78e856bd3
5. 著者紹介
-
Li Yiwei:
現在勉強中北京理工大学で博士号取得を目指すXiaohongshuコミュニティ検索インターン、AAAI、ACL、EMNLP、NAACL、NeurIPS、KBS##などの機械学習および自然言語処理分野のトップカンファレンス/ジャーナルに参加# 彼はいくつかの論文を発表しており、主な研究方向には大規模言語モデルの蒸留と推論、オープン ドメインの対話生成などが含まれます。
-
##ユアン ペイウェン:
現在、北京理工大学で博士課程の学生として学び、小紅樹でコミュニティ検索インターンとして働いており、NeurIPS、AAAIなどで多くの第一著者論文を発表しており、DSTC11 Trackでは2位を獲得しています。 4.主な研究方向は大規模言語モデルの推論と評価です。 -
Feng Shaoxiong:
Xiaohonshu コミュニティ検索ベクトル リコールを担当します。 AAAI、EMNLP、ACL、NAACL、KBS などの機械学習および自然言語処理の分野のトップカンファレンス/ジャーナルに複数の論文を発表。
Daoxuan (Pan Boyuan):
リトル レッド ブック トランザクション検索主要。 NeurIPS、ICML、ACL などの機械学習および自然言語処理の分野のトップカンファレンスでいくつかの第一著者論文を発表し、スタンフォード機械読解コンテスト SQuAD ランキングで 2 位を獲得、スタンフォード ナチュラル コンテストで 1 位を獲得しました。言語推論ランキング。
Zeng Shu (Zeng Shushu):
Xiaohongshu コミュニティ検索責任者意味の理解と想起の向上。彼は清華大学電子工学部で修士号を取得し、インターネット分野における自然言語処理、推奨、検索およびその他の関連分野のアルゴリズムの研究に従事してきました。
#
以上が小紅樹捜索チームが明らかにする:大規模モデル蒸留におけるネガティブサンプルの検証の重要性の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。