



以前に書いたものおよび著者の個人的な理解
自動運転車のセンサー レベルでのドメインの変化は、非常に一般的な現象です。たとえば、さまざまなシナリオや場所にある自動運転車は、自己の中にあります。 - 異なる照明や気象条件下での車両の運転、異なるセンサー機器を装備した自動運転車両など、上記すべては自動運転領域における典型的な違いと考えることができます。このドメインの違いが自動運転に課題をもたらします。その主な理由は、古いドメインの知識に依存する自動運転モデルは、追加コストなしでこれまで見たことのない新しいドメインに直接展開することが難しいためです。したがって、この論文では、ドメイン移行のための新しい視点と方法を提供する再構築シミュレーション認識 (ReSimAD) スキームを提案します。具体的には、暗黙的再構成技術を用いて運転シーンにおける古いドメイン知識を取得し、その再構成プロセスの目的は、古いドメインのドメイン関連知識をドメイン不変表現(ドメイン不変表現)に変換する方法を研究することです。たとえば、3D シーンレベルのメッシュ表現 (3D メッシュ表現) はドメイン不変の表現であると考えられます。再構成された結果に基づいて、シミュレーターを使用して、ターゲット ドメインのより現実的なシミュレーション点群を生成します。このステップは、再構成された背景情報とターゲット ドメインのセンサー ソリューションに依存するため、データ収集とラベル付けの時間が短縮されます。その後のセンシングプロセス 新しいドメインデータのコスト。
実験検証部分では、Waymo-to-KITTI、Waymo-to-nuScenes、Waymo-to-ONCE などのさまざまなクロスドメイン設定を検討しました。すべてのクロスドメイン設定はゼロショット実験設定を採用しており、ソース ドメインのバックグラウンド メッシュとシミュレートされたセンサーのみに依存してターゲット ドメイン サンプルをシミュレートし、モデルの汎化機能を向上させます。結果は、ReSimAD がターゲット ドメイン シーンに対する知覚モデルの一般化能力を大幅に向上させ、教師なしドメイン適応手法よりも優れていることを示しています。
論文情報

- 論文タイトル: ReSimAD: ソース再構築と自動運転のためのゼロショット 3D ドメイン転送ターゲットシミュレーション
- ICLR-2024は
- 論文発行者: 上海人工知能研究所、上海交通大学、復旦大学、北杭大学
- 論文アドレス: https:/// arxiv.org/abs/2309.05527
- コード アドレス: シミュレーション データ セットと認識部分、https://github.com/PJLab-ADG/3DTrans#resimad; ソース ドメイン再構成部分、https:// github. com/pjlab-ADG/neuralsim; ターゲット ドメイン シミュレーション パート、https://github.com/PJLab-ADG/PCSim
研究動機#課題
: 3D モデルは自動運転車が周囲を認識するのに役立ちますが、既存のベースライン モデルを新しい領域 (異なるセンサー設定や目に見えない都市など) に一般化することは困難です。自動運転分野の長期的なビジョンは、モデルがより低コストでドメイン移行を実現できるようにすることです。つまり、ソース ドメインで完全にトレーニングされたモデルを、ソース ドメインとターゲット ドメインのシナリオにうまく適応させることです。ターゲット ドメインがそれぞれ存在します。明らかなデータ分布の違いがある 2 つのドメインがあります。たとえば、ソース ドメインは晴れ、ターゲット ドメインは雨、ソース ドメインは 64 ビーム センサー、ターゲット ドメインは 32 ビーム センサーです。 一般的に使用されるソリューションのアイデア
: 上記のドメインの違いに直面した場合、最も一般的な解決策は、ターゲット ドメインのシナリオのデータを取得してアノテーションを付けることです。この方法により、ドメインの違いをある程度回避できます。違いによるモデルの性能低下が問題ですが、1) データ収集コストと 2) データのラベル付けコストが膨大です。したがって、以下の図に示すように (2 つのベースライン メソッド (a) と (b) を参照)、新しいドメインのデータ収集とデータ アノテーションのコストを軽減するために、シミュレーション エンジンを使用して、いくつかのシミュレートされたデータをレンダリングできます。点群サンプル: これは、シミュレーションから現実への研究作業における一般的なソリューションのアイデアです。もう 1 つのアイデアは、教師なしドメイン適応 (UDA for 3D) です。このタイプの研究の目的は、ラベルのないターゲット ドメイン データ (実際のデータであることに注意してください) のみにさらされる条件下で、ほぼ完全に教師ありの微調整を実現する方法を研究することです。 ) これが達成できれば、ターゲット ドメインのラベル付けコストは確かに節約されますが、UDA 手法では、ターゲット ドメインのデータ分布を特徴付けるために、実際のターゲット ドメイン データを大量に収集する必要があります。図 1: さまざまなトレーニング パラダイムの比較
私たちのアイデア: 上記の 2 つのカテゴリの研究アイデアとは異なり、下図 ((c) ベースライン プロセスを参照) に示すように、私たちはデータ シミュレーションと知覚の統合ルートに取り組んでいます。 virtual と real を組み合わせます。ここで、virtual と real の組み合わせにおけるリアリティとは、大規模なラベル付けされたソース ドメイン データに基づいてドメイン不変表現を構築することを指します。この仮定は、多くのシナリオにとって実際的に重要です。長期にわたる履歴データの蓄積後、次のことができるからです。この種のラベル付きソース ドメイン データが存在すると常に考えますが、一方で、仮想と現実の組み合わせでのシミュレーションは、ソース ドメイン データに基づいてドメイン不変表現を構築する場合、この表現を既存のドメイン データにインポートすることができます。ターゲット ドメイン データのシミュレーションを実行するレンダリング パイプライン。現在のシミュレーションとリアルの研究作業と比較して、私たちの方法は、道路構造、上り坂と下り坂の斜面などの実際の情報を含む実際のシーンレベルのデータによってサポートされています。この情報は、シミュレーションエンジンのみに依存するだけでは取得することが困難です。自体。ターゲット ドメインでデータを取得した後、そのデータを PV-RCNN などの現在の最適な知覚モデルに統合してトレーニングし、ターゲット ドメインでのモデルの精度を検証します。全体的な詳細なワークフローについては、以下の図を参照してください。
 図 2 ReSimAD のフローチャート
図 2 ReSimAD のフローチャート
ReSimAD のフローチャートを図 2 に示します。これには主に a)ポイントツーメッシュ暗黙的再構成プロセス, b) メッシュツーポイント シミュレーション エンジン レンダリング プロセス, c) ゼロサンプルセンシングプロセス。
ReSimAD: シミュレーション再構成を意識したパラダイム
a) ポイントツーメッシュ暗黙的再構成プロセス: の影響を受けます。 StreetSurf に触発され、実際の多様なストリート シーンの背景と動的な交通流情報を再構築するために LIDAR 再構築のみを使用します。私たちは最初に純粋な点群 SDF 再構成モジュール (LiDAR のみの暗黙的ニューラル再構成、LINR) を設計しました。その利点は、照明の変化、気象条件の変化、カメラのセンシングによって引き起こされるドメインの違いの影響を受けないことです。等。純粋な点群 SDF 再構成モジュールは、LiDAR レイを入力として受け取り、深度情報を予測し、最後にシーンの 3D メッシュ表現を構築します。
具体的には、原点  から方向
から方向  で放射された光線
で放射された光線  に対して、ボリューム レンダリングを LIDAR に適用して、符号付き距離フィールド (SDF) ネットワークとレンダリング深度 D をトレーニングします。
に対して、ボリューム レンダリングを LIDAR に適用して、符号付き距離フィールド (SDF) ネットワークとレンダリング深度 D をトレーニングします。
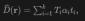
ここで、 はサンプル ポイント  のサンプリング深さ、 は累積透過率 (累積透過率) であり、近似関数を使用して取得されます。 NeuSのレンジモデル。
のサンプリング深さ、 は累積透過率 (累積透過率) であり、近似関数を使用して取得されます。 NeuSのレンジモデル。
StreetSurf からインスピレーションを得て、この記事で提案する再構成プロセスのモデル入力は LIDAR レイから取得され、出力は予測深度です。サンプリングされた LIDAR ビーム  ごとに、対数 L1 損失を
ごとに、対数 L1 損失を  に適用します。これは、近距離モデルと遠距離モデルのレンダリング深度を組み合わせたものです。
に適用します。これは、近距離モデルと遠距離モデルのレンダリング深度を組み合わせたものです。
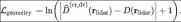
ただし、 LINR 手法にはまだいくつかの課題があります。 LIDAR によって取得されるデータは本質的に希薄であるため、単一の LIDAR 点群フレームでは、標準の RGB 画像に含まれる情報の一部しかキャプチャできません。この違いは、効果的なトレーニングに必要な幾何学的詳細を提供する際の深度レンダリングの潜在的な欠点を浮き彫りにします。したがって、結果として再構築されたメッシュ内に多数のアーティファクトが発生する可能性があります。この課題に対処するために、Waymo シーケンス内のすべてのフレームを結合して点群の密度を高めることを提案します。
Waymo データセットの Top LiDAR の垂直視野の制限により、-17.6° ~ 2.4° の範囲の点群を取得するだけでは、周囲の高層ビルの再構成に明らかな制限があります。この課題に対処するために、Side LiDAR の点群を再構築用のサンプリング シーケンスに組み込むソリューションを導入します。自動運転車の前後左右に 4 つのブラインドフィリング レーダーが設置されており、垂直視野は [-90°、30°] に達し、視野範囲が狭いという欠点を効果的に補います。上部のライダー。側面 LIDAR と上部 LIDAR の間の点群密度の違いにより、高層ビル シーンの再構成品質を向上させるために、側面 LIDAR に高いサンプリング ウェイトを割り当てることを選択します。
再構築の品質評価: 動的オブジェクトによって引き起こされるオクルージョンと LIDAR ノイズの影響により、再構築の暗黙的表現にはある程度のノイズが存在する可能性があります。そこで、再構成精度を評価した。旧ドメインから大量の注釈付き点群データを取得できるため、旧ドメインで再レンダリングすることで旧ドメインのシミュレートされた点群データを取得し、再構成されたメッシュの精度を評価できます。二乗平均平方根誤差 (RMSE) と面取り距離 (CD) を使用して、シミュレートされた点群と元の実際の点群を測定します。
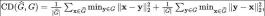
それぞれの説明については、配列再構築スコアといくつかの詳細なプロセスについては、元の付録を参照してください。
b) メッシュからポイントへのシミュレーション エンジン レンダリング プロセス : 上記の LINR メソッドを通じて静的背景メッシュを取得した後、Blender Python API を使用して変換します。データは .ply 形式から .fbx 形式の 3D モデル ファイルに変換され、最終的に背景メッシュがアセット ライブラリとしてオープン ソース シミュレーター CARLA にロードされます。
まず、Waymo のアノテーション ファイルを取得して、各トラフィック参加者のバウンディング ボックス カテゴリと 3 次元オブジェクト サイズを取得し、この情報に基づいて、CARLA のデジタル アセット ライブラリで同じカテゴリのトラフィック参加者を検索します。サイズが最も近いデジタル資産がインポートされ、トラフィック参加者モデルとして使用されます。 CARLA シミュレーターで利用可能なシーンの信頼性情報に基づいて、交通シーン内の検出可能なオブジェクトごとに検出ボックス抽出ツールを開発しました。詳細については、PCSim 開発ツールを参照してください。
 図 3 さまざまなデータセットにおける交通参加者のオブジェクト サイズ (長さ、幅、高さ) の分布。図 3 からわかるように、この方法を使用してシミュレートされたオブジェクト サイズの分布の多様性は非常に幅広く、KITTI、nuScenes、Waymo、ONCE などの現在公開されているデータ セットを超えています。
図 3 さまざまなデータセットにおける交通参加者のオブジェクト サイズ (長さ、幅、高さ) の分布。図 3 からわかるように、この方法を使用してシミュレートされたオブジェクト サイズの分布の多様性は非常に幅広く、KITTI、nuScenes、Waymo、ONCE などの現在公開されているデータ セットを超えています。
Waymo をソース ドメイン データとして使用し、Waymo 上で再構築してより現実的な 3D メッシュを取得します。同時に、KITTI、nuScenes、ONCE をターゲット ドメイン シナリオとして使用し、これらのターゲット ドメイン シナリオで私たちの方法によって達成されるゼロショット パフォーマンスを検証します。
上記の章の導入に従って、Waymo データセットに基づいて 3D シーンレベルのメッシュ データを生成し、上記の評価基準を使用してどの 3D メッシュが Waymo ドメインで高品質であるかを判断します。スコアに基づいて最高の 146 メッシュを選択し、その後のターゲット ドメイン シミュレーション プロセスを実行します。
評価結果
 ResimAD データセットのいくつかの視覚化例を以下に示します。
ResimAD データセットのいくつかの視覚化例を以下に示します。
評価結果 ResimAD データセットのいくつかの視覚化例を以下に示します。
ResimAD データセットのいくつかの視覚化例を以下に示します。 
実験設定
ベースラインの選択: 提案された ReSimAD を 3 つの典型的なクロスドメイン ベースラインと比較します。 a) データ シミュレーションのベースラインb) シミュレーション エンジンのセンサー パラメーター設定を変更することによるデータ シミュレーションのベースライン; c) ドメイン アダプテーション (UDA) ベースライン.
- メトリクス: We Align 3D クロスドメイン オブジェクトの現在の評価基準検出では、BEV ベースの AP と 3D ベースの AP をそれぞれ評価指標として使用します。
- パラメータ設定: 詳細については論文を参照してください。
ここでは主な実験結果のみを示します。さらに詳しい結果論文については、お問い合わせください。
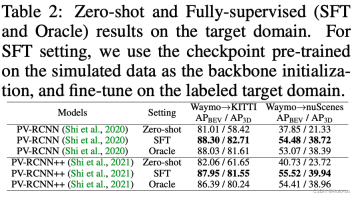
3 つのクロスドメイン設定における PV-RCNN/PV-RCNN の 2 つのモデルの適応パフォーマンス
上の表からわかること: UDA と教師なしドメイン アダプテーション (UDA) テクノロジを使用する ReSimAD の主な違いは、前者はモデル ドメイン移行にターゲット ドメイン 実際のシーン のサンプルを使用することです。 ReSimAD の実験設定では、ターゲット ドメイン内の実際の点群データに アクセスできないことが必要です。上の表からわかるように、ReSimAD によって得られたクロスドメインの結果は、UDA メソッドによって得られた結果と同等です。この結果は、商用目的で LIDAR センサーをアップグレードする必要がある場合、私たちの方法によりデータ収集のコストが大幅に削減され、ドメインの違いによるモデルの再トレーニングと再開発のサイクルがさらに短縮できることを示しています。
ReSimAD データは、ターゲット ドメインのコールド スタート データとして使用され、ターゲット ドメインで達成できる効果
##検証のために、ReSimAD が 3D 事前トレーニングに役立つより多くの点群データを生成できるかどうか、次の実験を設計しました: AD-PT (自動運転シナリオでバックボーン ネットワークを事前トレーニングするために最近提案された方法) を使用して事前トレーニングします。シミュレートされた点群 3D バックボーンをトレーニングし、ダウンストリームの実際のシーン データを使用して完全なパラメーターを微調整します。 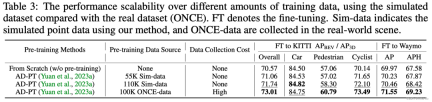
ReSimAD を活用して、点群がより広範囲に分布するデータを生成します。 AD-PT での事前トレーニング結果と公平に比較するために、ReSimAD によって生成されるシミュレートされた点群データの目標量は約
- です。上の表では、ベースライン検出器は、AD-PT メソッドを使用して実際の事前トレーニング データ (ONCE データセット) とシミュレートされた事前トレーニング データ (ReSimAD によって提供)、および KITTI および Waymo データセットで 3D 事前トレーニングされています。下流側の微調整。上の表の結果は、さまざまなサイズのシミュレーション事前トレーニング データを使用すると、ダウンストリームでのモデルのパフォーマンスを継続的に向上できることを示しています。さらに、ReSimAD によって得られる事前トレーニング データのデータ取得コストは、モデルの事前トレーニングに ONCE を使用する場合と比較して非常に低く、ReSimAD によって得られる事前トレーニングのパフォーマンスは事前トレーニングと同等であることがわかります。 ONCE データセットのパフォーマンスの比較。
- ReSimAD を使用してシミュレーションを再構築する場合と、CARLA のデフォルト シミュレーションを使用する場合の視覚的な比較
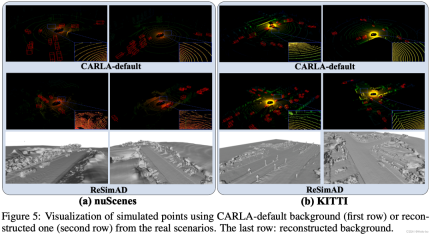 以下に基づいています。 Waymo データセット 再構築されたメッシュと VDBFusion を使用した再構築の視覚的な比較
以下に基づいています。 Waymo データセット 再構築されたメッシュと VDBFusion を使用した再構築の視覚的な比較
 概要
概要
この作業では、は、ゼロサンプルのターゲット ドメイン モデル転送タスクを実験する方法を検討することにコミットしています。このタスクでは、モデルがソース ドメインの事前トレーニング済みモデルを、ソース ドメインのサンプル データ情報にさらされることなくターゲット ドメイン シーンに正常に移行する必要があります。ターゲットドメイン。これまでの研究とは異なり、ソースドメインの暗黙的再構成とターゲットドメインの多様性シミュレーションに基づく3Dデータ生成技術を初めて検討し、この技術がデータ分布にさらされることなくより良いモデルを達成できることを検証しました。移行パフォーマンスは、一部の教師なしドメイン適応 (UDA) 方法よりもさらに優れています。
元のリンク: https://mp.weixin.qq.com/s/pmHFDvS7nXy-6AQBhvVzSw
以上がReSimAD: 仮想データを通じて知覚モデルの汎化パフォーマンスを向上させる方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Huggingface smollmであなたの個人的なAIアシスタントを構築する方法Apr 18, 2025 am 11:52 AM
Huggingface smollmであなたの個人的なAIアシスタントを構築する方法Apr 18, 2025 am 11:52 AMオンデバイスAIの力を活用:個人的なチャットボットCLIの構築 最近では、個人的なAIアシスタントの概念はサイエンスフィクションのように見えました。 ハイテク愛好家のアレックスを想像して、賢くて地元のAI仲間を夢見ています。
 メンタルヘルスのためのAIは、スタンフォード大学でのエキサイティングな新しいイニシアチブによって注意深く分析されますApr 18, 2025 am 11:49 AM
メンタルヘルスのためのAIは、スタンフォード大学でのエキサイティングな新しいイニシアチブによって注意深く分析されますApr 18, 2025 am 11:49 AMAI4MHの最初の発売は2025年4月15日に開催され、有名な精神科医および神経科学者であるLuminary Dr. Tom Insel博士がキックオフスピーカーを務めました。 Insel博士は、メンタルヘルス研究とテクノでの彼の傑出した仕事で有名です
 2025年のWNBAドラフトクラスは、成長し、オンラインハラスメントの成長と戦いに参加しますApr 18, 2025 am 11:44 AM
2025年のWNBAドラフトクラスは、成長し、オンラインハラスメントの成長と戦いに参加しますApr 18, 2025 am 11:44 AM「私たちは、WNBAが、すべての人、プレイヤー、ファン、企業パートナーが安全であり、大切になり、力を与えられたスペースであることを保証したいと考えています」とエンゲルバートは述べ、女性のスポーツの最も有害な課題の1つになったものに取り組んでいます。 アノ
 Pythonビルトインデータ構造の包括的なガイド-AnalyticsVidhyaApr 18, 2025 am 11:43 AM
Pythonビルトインデータ構造の包括的なガイド-AnalyticsVidhyaApr 18, 2025 am 11:43 AM導入 Pythonは、特にデータサイエンスと生成AIにおいて、プログラミング言語として優れています。 大規模なデータセットを処理する場合、効率的なデータ操作(ストレージ、管理、アクセス)が重要です。 以前に数字とstをカバーしてきました
 Openaiの新しいモデルからの代替案からの第一印象Apr 18, 2025 am 11:41 AM
Openaiの新しいモデルからの代替案からの第一印象Apr 18, 2025 am 11:41 AM潜る前に、重要な注意事項:AIパフォーマンスは非決定論的であり、非常にユースケース固有です。簡単に言えば、走行距離は異なる場合があります。この(または他の)記事を最終的な単語として撮影しないでください。これらのモデルを独自のシナリオでテストしないでください
 AIポートフォリオ| AIキャリアのためにポートフォリオを構築する方法は?Apr 18, 2025 am 11:40 AM
AIポートフォリオ| AIキャリアのためにポートフォリオを構築する方法は?Apr 18, 2025 am 11:40 AM傑出したAI/MLポートフォリオの構築:初心者と専門家向けガイド 説得力のあるポートフォリオを作成することは、人工知能(AI)と機械学習(ML)で役割を確保するために重要です。 このガイドは、ポートフォリオを構築するためのアドバイスを提供します
 エージェントAIがセキュリティ運用にとって何を意味するのかApr 18, 2025 am 11:36 AM
エージェントAIがセキュリティ運用にとって何を意味するのかApr 18, 2025 am 11:36 AM結果?燃え尽き症候群、非効率性、および検出とアクションの間の隙間が拡大します。これは、サイバーセキュリティで働く人にとってはショックとしてはありません。 しかし、エージェントAIの約束は潜在的なターニングポイントとして浮上しています。この新しいクラス
 Google対Openai:学生のためのAIの戦いApr 18, 2025 am 11:31 AM
Google対Openai:学生のためのAIの戦いApr 18, 2025 am 11:31 AM即時の影響と長期パートナーシップ? 2週間前、Openaiは強力な短期オファーで前進し、2025年5月末までに米国およびカナダの大学生にChatGpt Plusに無料でアクセスできます。このツールにはGPT ‑ 4o、Aが含まれます。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

