
ホームページ >システムチュートリアル >Linux >リアルタイムの抽出とログベースのデータ同期の一貫性
リアルタイムの抽出とログベースのデータ同期の一貫性

- 王林転載
- 2024-01-16 14:36:05754ブラウズ
著者: 王東
宜新技術研究開発センターのアーキテクト
- 現在、CreditEase Technology R&D Center でアーキテクトとして勤務し、ストリーム コンピューティングとビッグ データ ビジネス製品ソリューションを担当しています。
- 以前は、Naver China (韓国最大の検索エンジン会社) の中国 R&D センターで上級エンジニアとして勤務し、CUBRID 分散データベース クラスター開発と CUBRID データベース エンジン開発に長年従事してきました http:// www.cubrid.org/blog/news/cubrid-cluster-introduction/
テーマの紹介:
- DWS の背景紹介
- dbus ワームホールの全体的なアーキテクチャと技術実装計画
- DWSの実践事例
この共有のテーマは「ログベースの DWS プラットフォームの実装と応用」で、主に CreditEase で現在行っていることのいくつかを共有します。このトピックには、2 つのチームの多くの兄弟姉妹の努力の結果が含まれています (私たちのチームと汕尾チームの結果)。今回は私が代わりに書いて、頑張ってご紹介させていただきます。
実際、実装全体は原理的には比較的単純ですが、当然ながら多くのテクノロジが必要です。この問題の原理と重要性を皆さんに理解してもらえるよう、できるだけ簡単な方法で表現しようとします。プロセス中にご質問がございましたら、いつでもご質問ください。できる限りお答えいたします。
DWS は略称で、後ほど説明しますが 3 つのサブプロジェクトで構成されます。
1.背景
事は少し前の会社のニーズから始まります。CreditEase がインターネット金融会社であることは誰もが知っています。私たちのデータの多くは標準的なインターネット会社とは異なります。一般的に言えば、それらは次のとおりです:
 データを扱う人は誰でも、データが非常に貴重であることを知っており、これらのデータはさまざまなシステムのデータベースに保存されています。データを必要とするユーザーは、どのようにして一貫性のあるリアルタイムのデータを入手できるのでしょうか?
データを扱う人は誰でも、データが非常に貴重であることを知っており、これらのデータはさまざまなシステムのデータベースに保存されています。データを必要とするユーザーは、どのようにして一貫性のあるリアルタイムのデータを入手できるのでしょうか?
- 同社の統合ビッグ データ プラットフォームは Sqoop を使用して、閑散期にさまざまなシステムからデータを均一に抽出し、Hive テーブルに保存して、他のデータ ユーザーにデータ サービスを提供します。このアプローチは一貫性の問題を解決しますが、適時性は低く、基本的には T 1 の適時性です。
- トリガーに基づいて増分変更を取得する際の主な問題は、ビジネス側の介入が非常に大きく、トリガーによってパフォーマンスの損失も発生することです。
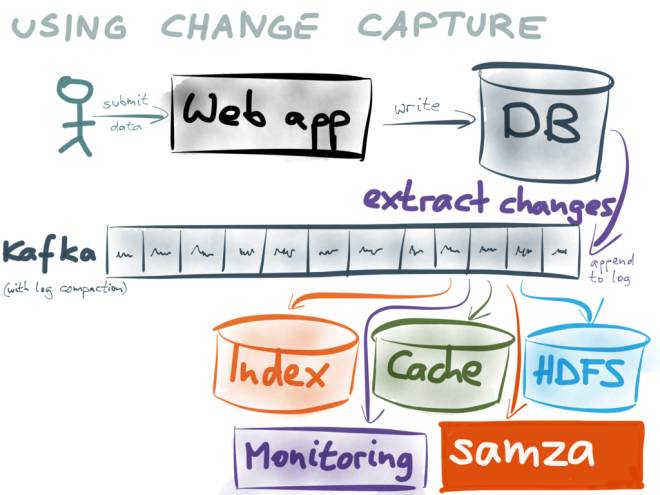 (この画像の出典: https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructor-or-why-dual-writes-are-a-bad - アイデア/)###
(この画像の出典: https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructor-or-why-dual-writes-are-a-bad - アイデア/)###
###例えば:###
- キャッシュ サービスを提供するユーザーは、Redis または alluxio でログをキャッシュできます;
- データ同期のユーザーは、データを自分のデータベースに保存できます;
- kafka のログは繰り返し使用して一定期間キャッシュできるため、各ユーザーは kafka のログを使用することでデータベースとの一貫性を維持し、リアルタイムのパフォーマンスを確保できます。
- 抽出に Sqoop を使用する代わりに、ログと Kafka をベースとして使用するのはなぜですか?なぜなら:###
そこで私たちは、ログベースの企業レベルのプラットフォームを構築するというアイデアを思いつきました。
DWS プラットフォームについて説明しましょう。DWS プラットフォームは 3 つのサブプロジェクトで構成されています:
- Dbus (データ バス): ソースからリアルタイムでデータを抽出し、独自のスキーマを使用して合意された JSON 形式のデータ (UMS データ) に変換し、それを Kafka に入れる役割を担います。
- ワームホール (データ交換プラットフォーム): kafka からのデータの読み取りとターゲットへのデータの書き込みを担当します。
- Swifts (リアルタイム コンピューティング プラットフォーム): は、kafka からデータを読み取り、リアルタイムで計算し、kafka にデータを書き戻す役割を果たします。
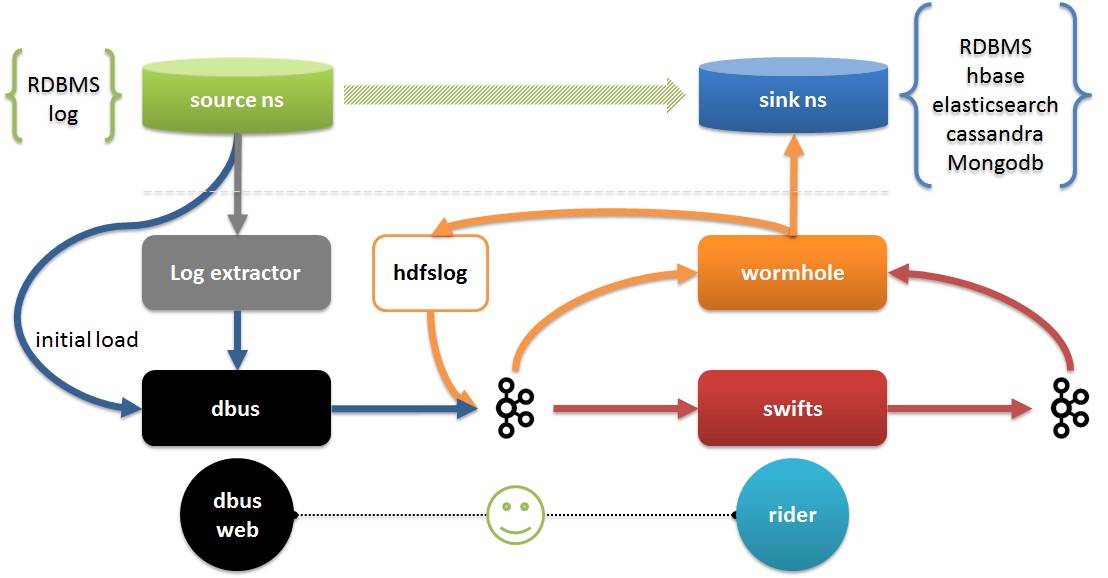 ###写真の中の:###
###写真の中の:###
- ワームホールはすべてのログ データを HDFS に保存できます。また、HBash、Elasticsearch、Cassandra など、jdbc をサポートするすべてのデータベースにデータを実装することもできます。
- Swifts は、ストリーミング結合、ルックアップ、フィルター、ウィンドウ集約、その他の機能のサポートを含む、構成と SQL を通じてストリーミング計算をサポートします。 Dbus Web は、dbus の構成管理エンドです。構成管理に加えて、Rider には、ワームホールと Swift のランタイム管理、データ品質検証などが含まれます。
- 時間の都合上、今日はDWSのDbusとWormholeを中心に紹介し、必要に応じてSwiftについても紹介します。
写真の出典: https://github.com/alibaba/canal
ビンログには 3 つのモードがあります: 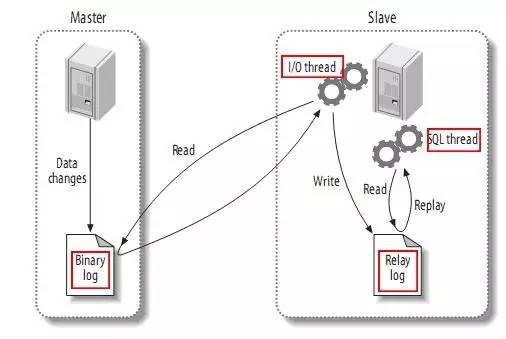
- 混合モード: MySQL は、実行された特定の SQL ステートメントごとに記録されるログ形式を区別します。つまり、Statement と Row のいずれかを選択します。
- それぞれの長所と短所は次のとおりです:
ここから引用: http://www.jquerycn.cn/a_13625
ステートメント モードには欠点があるため、DBA とのやり取りの中で、実際の運用プロセスではレプリケーションに行モードが使用されることが分かりました。これにより、ログ全体を読み取ることが可能になります。 
ソース側への影響を最小限に抑えるために、明らかに、スレーブ ライブラリから binlog ログを読み取る必要があります。
binlog を読み取るためのソリューションは多数あり、github にも多数あります。https://github.com/search?utf8=✓&q=binlog を参照してください。最終的に、ログ抽出方法としてアリババの運河を選択しました。
Canal は、アリババの中国とアメリカのコンピューター ルームを同期するために初めて使用されました。Canal の原理は比較的単純です:
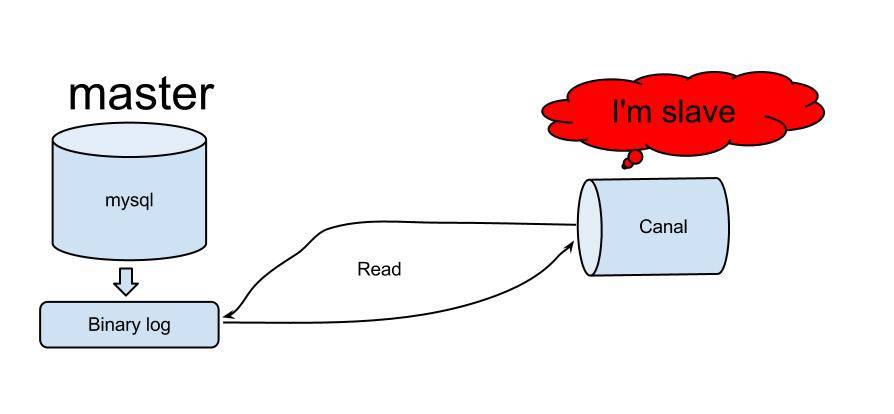
######解決######
MySQL バージョンの Dbus の主なソリューションは次のとおりです:増分ログについては、Canal Server をサブスクライブすることで、MySQL の増分ログを取得します:
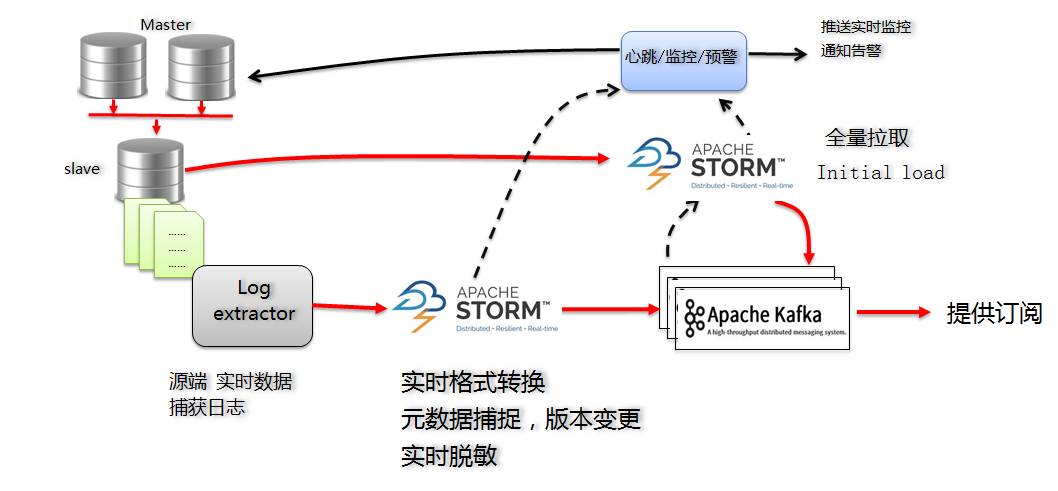
- 増分ストーム構成情報は、高可用性要件を満たすために Zookeeper に保存されます。
- Kafka は、出力結果としてだけでなく、処理中のバッファおよびメッセージ分解領域としても機能します。
- Storm をソリューションとして使用することを検討する場合、私たちは主に Storm には次の利点があると考えています。
- Storm の同時実行性を構成することで、パフォーマンスを拡張する機能を有効にすることができます;
- 全額抽出
- フロー テーブルの場合、増分部分で十分ですが、多くのテーブルでは初期 (既存) 情報を知る必要があります。このとき初期ロード(firstload)が必要です。
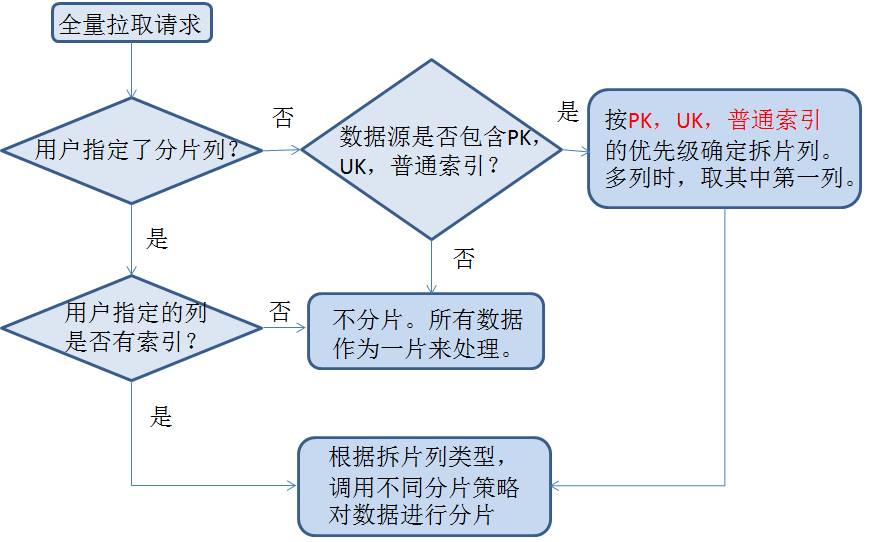
- データシャーディングではシャーディングカラムを考慮し、設定に応じた範囲でデータを分割してカラムを自動選択し、シャーディング情報をkafkaに保存する必要があります。
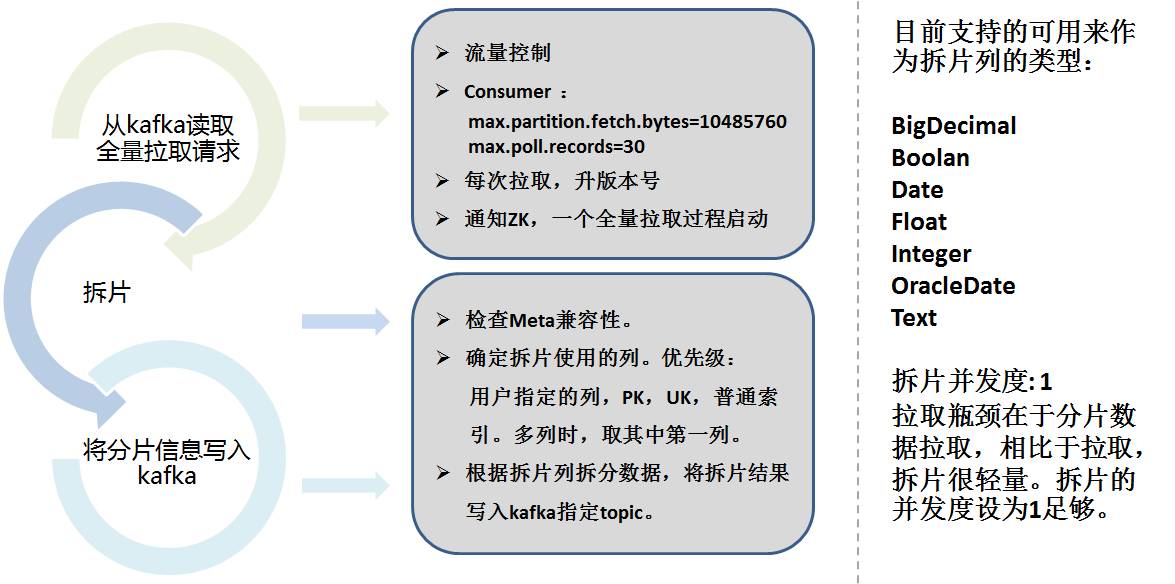 完全抽出用の Storm プログラムは、Kafka のシャーディング情報を読み取り、複数の同時実行レベルを使用して、プルのために並行してスタンバイ データベースに接続します。抽出時間が非常に長くなる可能性があるためです。抽出プロセス中に、ハートビート プログラムの監視を容易にするために、リアルタイム ステータスが Zookeeper に書き込まれます。
完全抽出用の Storm プログラムは、Kafka のシャーディング情報を読み取り、複数の同時実行レベルを使用して、プルのために並行してスタンバイ データベースに接続します。抽出時間が非常に長くなる可能性があるためです。抽出プロセス中に、ハートビート プログラムの監視を容易にするために、リアルタイム ステータスが Zookeeper に書き込まれます。
インクリメンタルであってもフルであっても、kafka に出力される最終メッセージは、UMS (統一メッセージ スキーマ) 形式と呼ばれる、私たちが合意した統一メッセージ形式です。 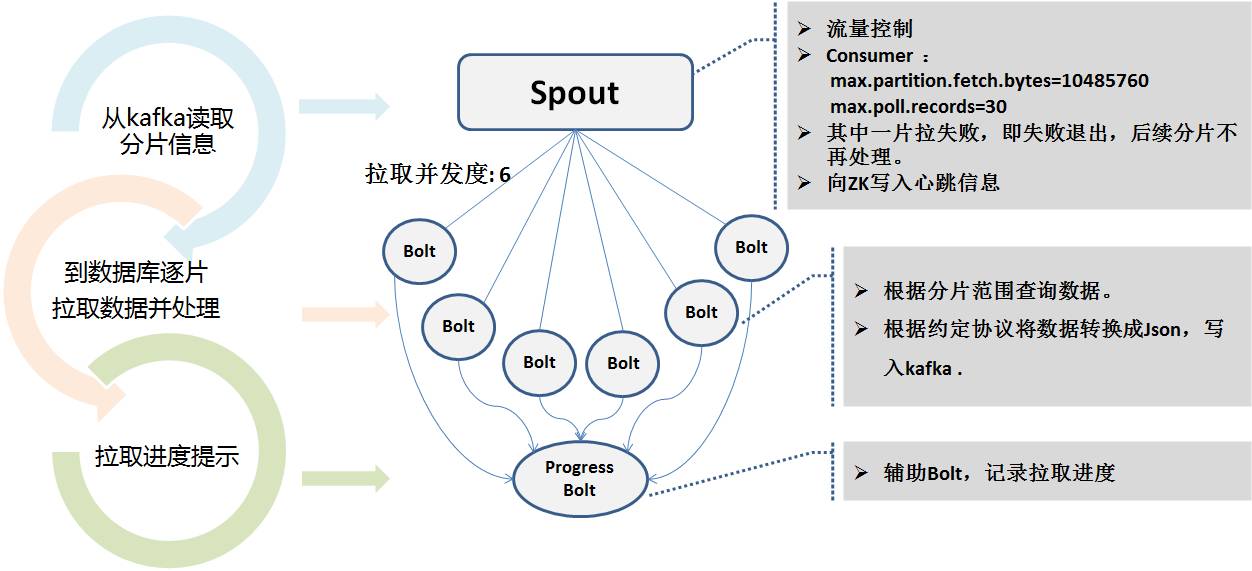
メッセージのスキーマ部分は、名前空間がタイプ、データ ソース名、スキーマ名、テーブル名、バージョン番号、サブライブラリ番号、サブテーブル番号で構成されていることを定義しており、会社全体のすべてのテーブルを説明できます。名前空間を通じて一意に見つけることができます。
- _ums_op_ データ型が I (挿入)、U (更新)、D (削除) であることを示します。 _ums_ts_ 追加、削除、変更が発生したイベントのタイムスタンプ。明らかに、新しいデータのタイムスタンプが更新されます。
- _ums_id_ メッセージの一意の ID で、メッセージが一意であることを保証しますが、ここではメッセージの順序 (後で説明します) を保証します。
UMS でサポートされるデータ型は Hive 型を指し、基本的にすべてのデータ型を含むように簡略化されています。
完全な一貫性と増分的な一貫性 データ転送全体において、ログメッセージの順序を可能な限り保証するために、kafka は 1 つのパーティションを使用します。一般に、基本的には順次的であり、一意です。しかし、Kafka の書き込みは失敗し、書き直される可能性があることはわかっています。Storm はやり直しメカニズムも使用します。したがって、厳密に 1 回と完全なシーケンスを保証するわけではありませんが、少なくとも 1 回は保証されます。
したがって、_ums_id_ が特に重要になります。
完全抽出の場合、_ums_id_ は一意です。zk の同時実行度ごとに異なる ID スライスが取得され、一意性とパフォーマンスが保証されます。負の数値を入力しても増分データと競合せず、増分メッセージの初期値になることも保証されます。 。
増分抽出の場合、MySQL ログ ファイル番号とログ オフセットを一意の ID として使用します。 ID は 64 ビット長の整数として使用され、上位 7 ビットはログ ファイル番号に使用され、下位 12 ビットはログ オフセットとして使用されます。
例: 000103000012345678。 103 はログ ファイル番号、12345678 はログ オフセットです。
これにより、ログレベルから物理的な一意性が確保され(やり直してもID番号が変わらない)、順序も保証される(ログの位置も特定できる)。 _ums_id_ の消費ログを比較することで、_ums_id_ を比較することでどのメッセージが更新されたかを知ることができます。
実際、_ums_ts_ と _ums_id_ は同様の意図を持っていますが、_ums_ts_ が繰り返される場合がある点、つまり 1 ミリ秒間に複数の操作が発生する点が異なるため、_ums_id_ を比較する必要があります。
ハートビートの監視と早期警告 システム全体には、データベースのメイン同期とバックアップ同期、Canal Server、複数の同時実行 Storm プロセスなど、さまざまな側面が含まれます。したがって、プロセスの監視と早期警告が特に重要です。
たとえば、ハートビート モジュールを通じて、抽出された各テーブルに心理データを 1 分ごとに挿入し (構成可能)、送信時間を節約します。このハートビート テーブルも抽出され、プロセス全体をたどると、実際には同じです同じロジックに従って (複数の同時ストームが異なるブランチを持つ可能性があるため)、ハートビート パケットを受信すると、データの追加、削除、または変更がなくても、リンク全体が開いていることが証明できます。
Storm プログラムとハートビート プログラムはデータを公開統計トピックに送信し、統計プログラムはそれを influxdb に保存します。grafana を使用して表示すると、次の効果がわかります:
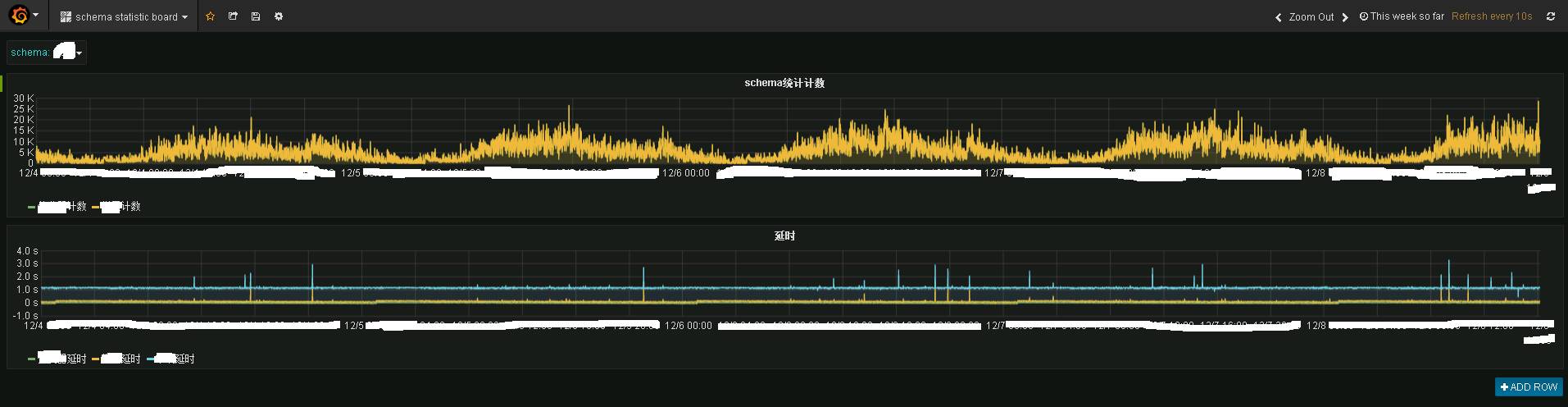 写真は、ある業務システムのリアルタイム監視情報を示しています。上がリアルタイムの渋滞状況、下がリアルタイムの遅延状況です。リアルタイム性が依然として非常に優れていることがわかり、基本的には 1 ~ 2 秒でデータが端末 Kafka に転送されています。
写真は、ある業務システムのリアルタイム監視情報を示しています。上がリアルタイムの渋滞状況、下がリアルタイムの遅延状況です。リアルタイム性が依然として非常に優れていることがわかり、基本的には 1 ~ 2 秒でデータが端末 Kafka に転送されています。
Granfana はリアルタイム監視機能を提供します。
遅延がある場合は、dbus のハートビート モジュールを通じて電子メール アラームまたは SMS アラームが送信されます。
リアルタイムの減感作 データ セキュリティを考慮して、Dbus のフル ストームおよび増分ストーム プログラムは、感度解除が必要なシナリオ向けのリアルタイムの感度解除機能も備えています。減感作には 3 つの方法があります:
 要約すると: 簡単に言うと、Dbus はさまざまなソースからデータをリアルタイムでエクスポートし、UMS の形式でサブスクリプションを提供し、リアルタイムの感度解除、実際の監視、および警報をサポートします。
要約すると: 簡単に言うと、Dbus はさまざまなソースからデータをリアルタイムでエクスポートし、UMS の形式でサブスクリプションを提供し、リアルタイムの感度解除、実際の監視、および警報をサポートします。
大きな理由の 1 つはデカップリングです。Kafka には自然なデカップリング機能があり、プログラムは kafka を介して非同期メッセージ パッシングを直接実行できます。 Dbus と Wornhole も、メッセージの受け渡しと分離のために内部で kafka を使用します。
もう 1 つの理由は、UMS が自己記述型であるためです。kafka をサブスクライブすることで、有能なユーザーは誰でも UMS を直接消費して使用できます。
UMS の結果は直接サブスクライブできますが、開発作業は依然として必要です。 Wormhole が解決するのは、Kafka のデータをさまざまなシステムに実装するためのワンクリック構成を提供し、開発能力のないデータ ユーザーがワームホールを通じてデータを使用できるようにすることです。
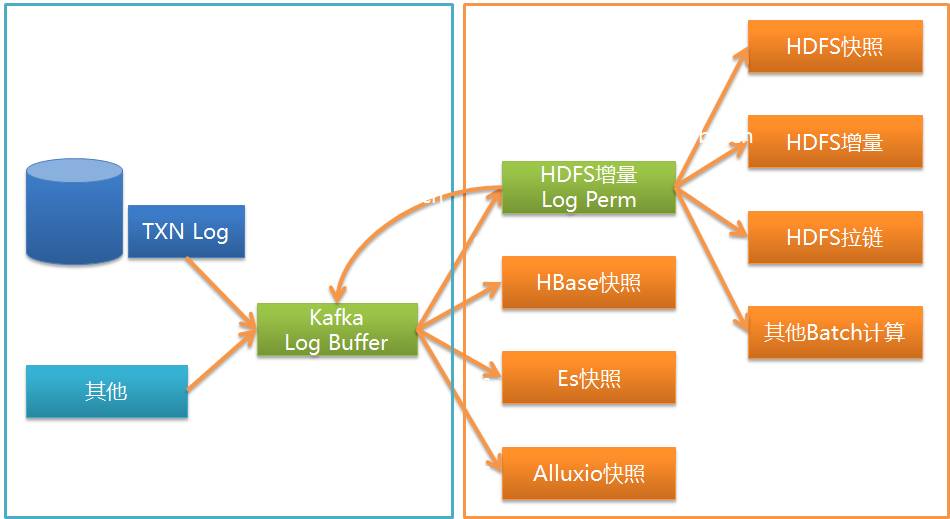
図に示すように、ワームホールはさまざまなシステムに kafka の UMS を実装できますが、現在最もよく使用されているのは HDFS、JDBC データベース、および HBase です。
テクノロジー スタックでは、ワームホールはスパーク ストリーミングの使用を選択します。
ワームホールでは、フローはソースからターゲットまでの namaspace を参照します。 1 つの Spark ストリーミングは複数のフローを処理します。
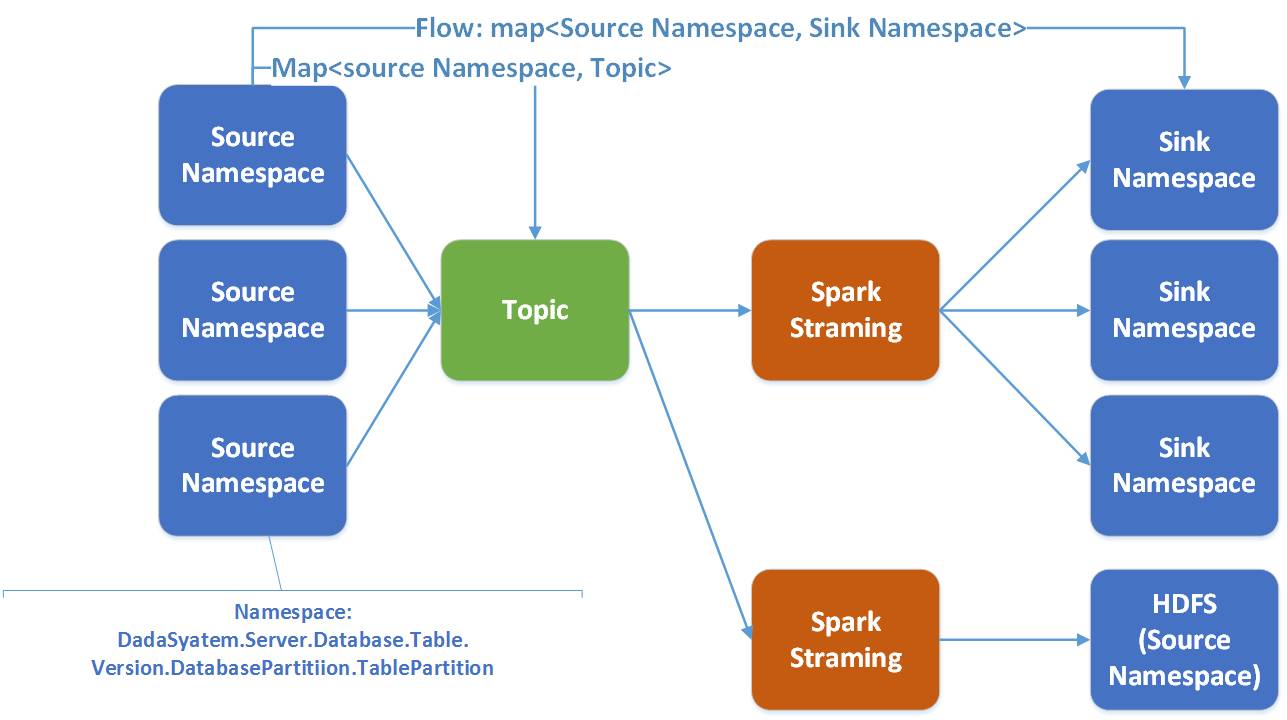
Spark を選択する十分な理由があります:
- Spark はさまざまな異種ストレージ システムを自然にサポートします;
- Spark Stream の遅延は Storm よりもわずかに劣りますが、Spark の方がスループットとコンピューティング パフォーマンスが優れています;
- Spark は、並列コンピューティングのサポートにおいてより優れた柔軟性を備えています;
- Spark は、後の開発を容易にするために、テクノロジー スタック内で Sparking Job、Spark Streaming、および Spark SQL を解決するための統合機能を提供します。
- Swifts の本質は、kafka で UMS データを読み取り、リアルタイム計算を実行し、その結果を kafka の別のトピックに書き込むことです。
- リアルタイム計算は、フィルター、投影 (投影)、ルックアップ、ストリーミング結合ウィンドウ集計など、さまざまな方法で実行でき、ビジネス価値のあるさまざまなストリーミング リアルタイム計算を完了できます。
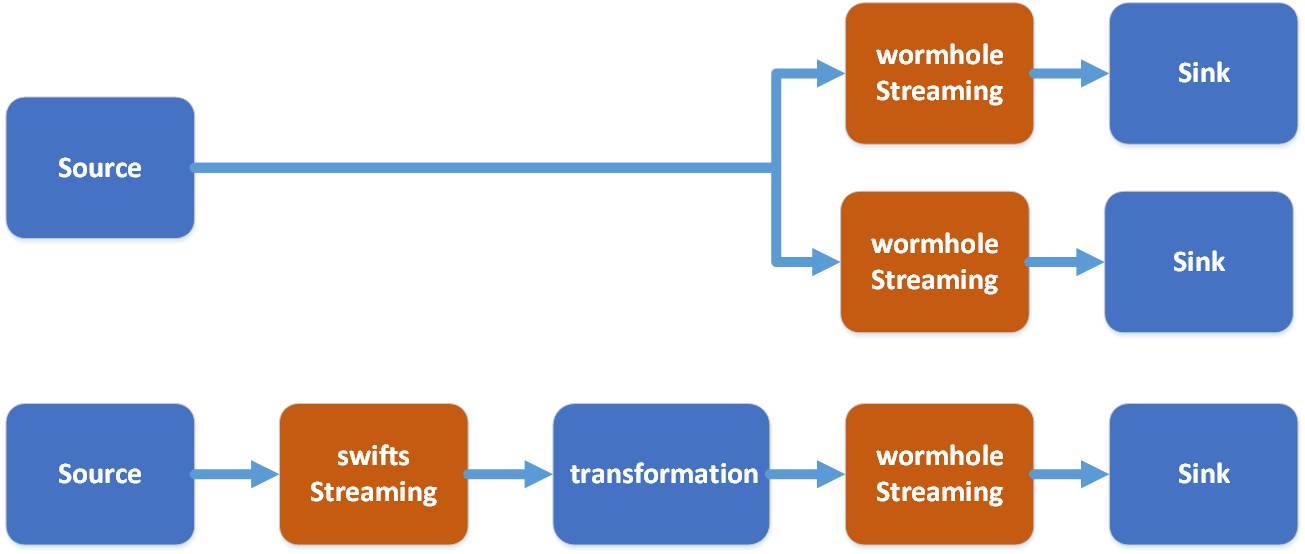
Kafka は通常、数日分の情報のみを保存し、すべての情報を保存するわけではありませんが、HDFS はすべての履歴の追加、削除、および変更を保存できます。これにより、多くのことが可能になります:
- HDFS でログを再生することで、いつでも履歴スナップショットを復元できます。
- 分析を容易にするために、各レコードの履歴情報を復元するためのジッパー テーブルを作成できます。
- プログラムでエラーが発生した場合、バックフィルを使用してメッセージを再利用し、新しいスナップショットを再形成できます。
Spark はネイティブで Parquet を非常に適切にサポートしているため、Spark SQL は Parquet に優れたクエリを提供できます。 UMS が HDFS に実装されると、UMS は Parquet ファイルに保存されます。 Parquet の内容は、すべてのログの追加、削除、変更情報と、_ums_id_、_ums_ts_ が保存されるというものです。
ワームホール スパーク ストリーミングは、名前空間に従って異なるディレクトリにデータを分散して保存します。つまり、異なるテーブルとバージョンが異なるディレクトリに配置されます。
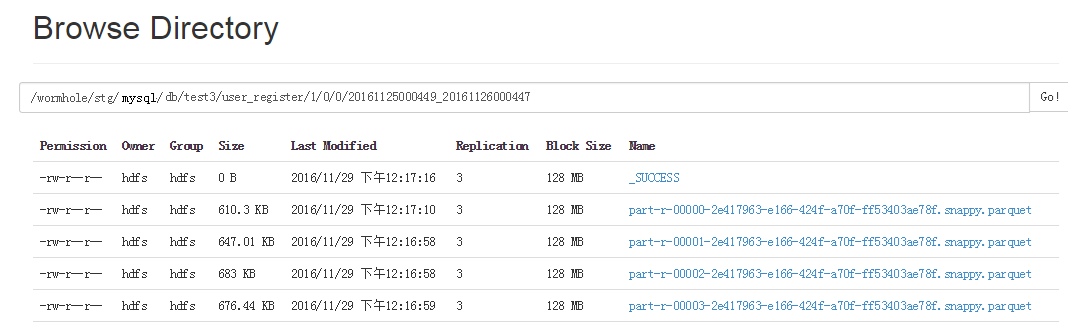 毎回書き込まれる Parquet ファイルは小さいファイルであるため、HDFS が小さいファイルに対して適切にパフォーマンスを発揮しないことは誰もが知っているため、これらの Parquet ファイルを毎日定期的に大きいファイルにマージする別のジョブがあります。
毎回書き込まれる Parquet ファイルは小さいファイルであるため、HDFS が小さいファイルに対して適切にパフォーマンスを発揮しないことは誰もが知っているため、これらの Parquet ファイルを毎日定期的に大きいファイルにマージする別のジョブがあります。
各 Parquet ファイル ディレクトリには、ファイル データの開始時刻と終了時刻があります。このようにして、データを補充するときに、すべてのデータを読み取ることなく、選択した時間範囲に基づいてどの Parquet ファイルを読み取る必要があるかを決定できます。
データの挿入または更新が不可能である データを処理してデータベースまたは HBase に入れる必要が生じることがよくあります。ここで問題となるのは、どのような種類のデータを更新できるのかということです。ここで最も重要な原則は、データの冪等性です。
データの追加、削除、変更が発生したかどうかに関係なく、直面する問題は次のとおりです。
- どの行を更新する必要があるか;
- 更新された戦略とは何ですか。
最初の質問では、実際にデータを見つけるための一意のキーを見つける必要があります。一般的なものは次のとおりです:
- ビジネス ライブラリの主キーを使用します;
- ビジネス パーティは、複数の列を結合一意インデックスとして指定します;
2 番目の質問では、_ums_id_ が関係します。_ums_id_ の大きな値が更新されることが保証されているため、対応するデータ行を見つけた後、この原則に従ってそれを置き換えて更新します。
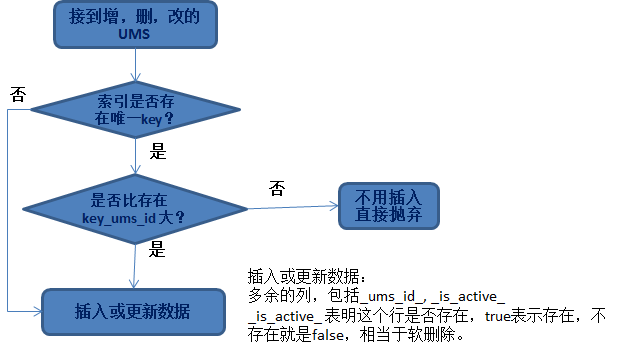
論理的に削除して _is_active_ 列を追加する必要がある理由は、次のような状況のためです:
挿入された _ums_id_ が比較的大きい場合は、削除されたデータ (データが削除されたことを示します) ですが、ソフト削除でない場合は、この時点で小さな _ums_id_ データ (古いデータ) を挿入すると、実際に挿入されます。
これにより、古いデータが挿入されます。べき等ではなくなりました。したがって、削除されたデータが引き続き保持されること (ソフト削除) は貴重であり、データの冪等性を保証するために使用できます。
HBase の保存Hbase へのデータの挿入は非常に簡単です。違いは、HBase が複数のバージョンのデータを保持できることです (もちろん、1 つのバージョンのみを保持することもできます)。デフォルトでは 3 つのバージョンが保持されます。
したがって、HBase にデータを挿入するときに解決する必要がある問題は次のとおりです:
- 適切な行キーを選択します: 行キーの設計はオプションです。ユーザーはソース テーブルの主キーを選択するか、複数の列を結合主キーとして選択できます。
- 適切なバージョンを選択します。行バージョンとして _ums_id_ より大きなオフセット (100 億など) を使用します。
パフォーマンス向上の観点から、Spark Streaming Dataset コレクション全体を比較せずに HBase に直接挿入できます。 HBase がバージョンに基づいて、どのデータを保持できるか、どのデータを保持する必要がないかを自動的に判断します。
Jdbc挿入データ:
データをデータベースに挿入します。冪等性を確保する原理は単純ですが、パフォーマンスを向上させたい場合、実装はさらに複雑になります。1 つずつ比較してから挿入または更新することはできません。
Spark の RDD/データセットは、パフォーマンスを向上させるためにコレクション方式で操作されることがわかっていますが、同様に、コレクション操作方式で冪等性を実現する必要があります。
具体的なアイデアは次のとおりです:
- まず、セット内の主キーに従ってターゲット データベースにクエリを実行し、既存のデータ セットを取得します。
- データセット内のコレクションと比較すると、それらは 2 つのカテゴリに分類されます:
- A: 存在しないデータ、つまりデータのこの部分を挿入できます;
B: 既存のデータと _ums_id_ を比較し、最後に _ums_id_ の大きい行のみをターゲット データベースに更新し、小さい行は直接破棄します。
Spark を使用する学生は、RDD/データセットをパーティション分割でき、複数のワーカーを使用して操作して効率を向上できることを知っています。
同時実行性を考慮する場合、挿入と更新の両方が失敗する可能性があるため、失敗後に考慮すべき戦略もあります。
例: 他のワーカーがすでに挿入されており、一意制約の挿入が失敗するため、代わりにそれを更新し、_ums_id_ を比較して更新できるかどうかを確認する必要があります。
ワームホールには、挿入できない他の状況 (ターゲット システムの問題など) に対する再試行メカニズムもあります。詳細はたくさんあります。ここではあまり紹介しません。
一部はまだ開発中です。
他のストレージへの挿入については詳しく説明しませんが、一般的な原則は、各ストレージの特性に基づいて、コレクションベースの同時データ挿入の実装を設計することです。これらは、Wormhole のパフォーマンス向上のための努力であり、Wormhole を使用するユーザーはこれらを心配する必要はありません。
ここまでお話しましたが、DWS の実際の用途は何でしょうか?次に、DWSを利用したあるシステムで実現したリアルタイムマーケティングについて紹介します。
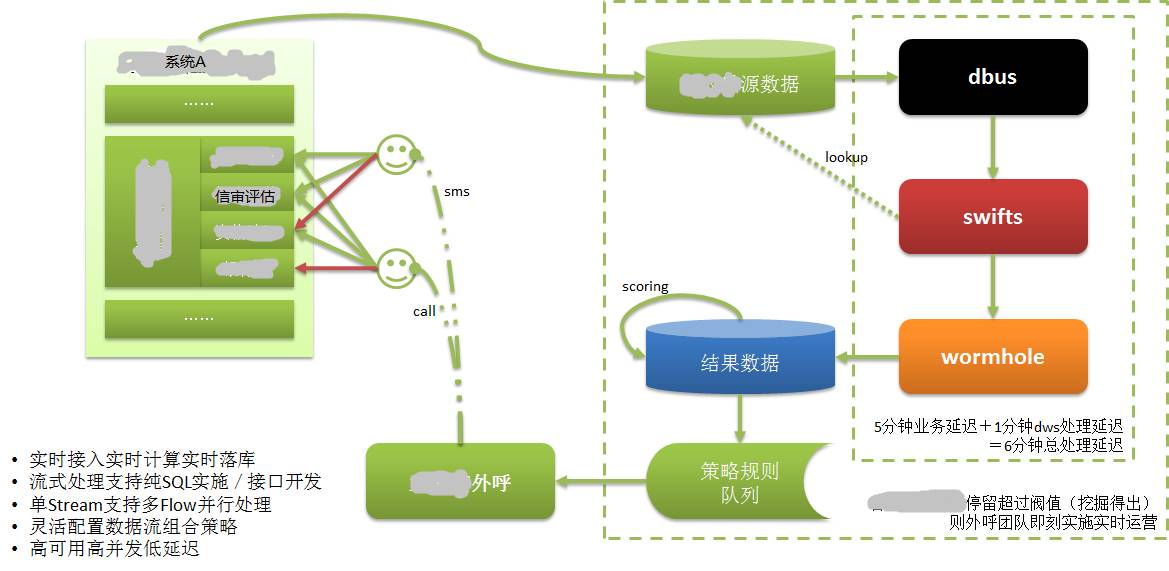
図に示すように:
システム A のデータは独自のデータベースに保存されています。CreditEase が借入を含む多くの金融サービスを提供していることはわかっていますが、借入プロセスにおいて非常に重要なのは信用調査です。
借り手は、最も強力な信用データを備えたデータである中央銀行信用報告書など、自分の信用価値を証明する情報を提供する必要があります。銀行取引やネットショッピング取引も信用属性の強いデータです。
借り手が Web またはモバイル APP を通じてシステム A に信用情報を入力すると、何らかの理由で続行できない場合があります。この借り手は優良な潜在顧客である可能性がありますが、この情報は以前は利用できなかったか、時間がかかりました。知られるようになってから長い時間が経ったため、実際、そのような顧客は失われています。
DWS 適用後、借り手が入力した情報はデータベースに記録され、DWS を通じてリアルタイムで抽出、計算され、ターゲット データベースに実装されます。顧客評価に基づいて質の高い顧客を評価します。そして、すぐに顧客情報を顧客サービスシステムに出力します。
カスタマー サービス スタッフは、非常に短時間 (数分以内) で借り手 (潜在顧客) に電話で連絡し、顧客ケアを提供し、潜在顧客を実際の顧客に変えました。借入は時間に左右され、時間がかかりすぎると価値がなくなることを私たちは知っています。
リアルタイムで抽出/計算/ドロップする機能がなければ、これらはいずれも不可能です。
リアルタイムレポートシステム別のリアルタイム レポート アプリケーションは次のとおりです。
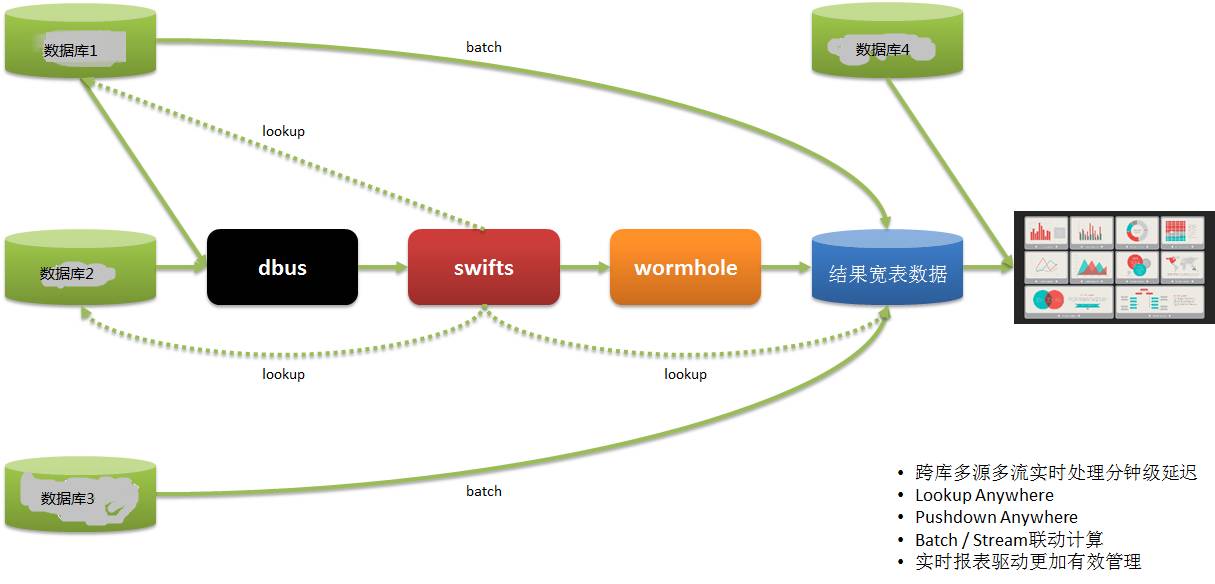
データ利用者のデータは複数のシステムから取得されており、従来はT1経由でレポート情報を取得し、翌日の業務指導を行っていたため、非常にタイムリーでした。
DWS を通じて、複数のシステムからデータがリアルタイムに抽出され、計算および実装され、レポートが提供されるため、運用はタイムリーな展開と調整を行い、迅速に対応できます。
ここまでお話しましたが、大まかに要約してみましょう:
- DWS テクノロジーは、主流のリアルタイム ストリーミング ビッグ データ テクノロジー フレームワークに基づいており、高可用性、大スループット、強力な水平拡張、低遅延、高いフォールト トレランス、そして最終的な一貫性を備えています。
- DWS 機能は、異種マルチソースおよびマルチターゲット システム、複数のデータ形式 (構造化、半構造化、非構造化データ)、およびリアルタイム技術機能をサポートします。
- DWS は 3 つのサブプロジェクトを結合し、1 つのプラットフォームとして起動します。これにより、リアルタイム機能を備え、さまざまなリアルタイム シナリオ アプリケーションを実行できるようになります。
適切なシナリオは次のとおりです: リアルタイム同期/リアルタイム計算/リアルタイム監視/リアルタイムレポート/リアルタイム分析/リアルタイム洞察/リアルタイム管理/リアルタイムタイムオペレーション/リアルタイム意思決定
皆さん、ご清聴ありがとうございました。この共有はここで終わります。
Q1: Oracle ログ リーダー用のオープンソース ソリューションはありますか?
A1:Oracle 業界には、Oracle GoldenGate (オリジナルの Goldengate)、Oracle Xstream、IBM InfoSphere Change Data Capture (オリジナルの DataMirror)、Dell SharePlex (オリジナルの Quest など) などの商用ソリューションも多数あります。 )、国産 DSG superSync など、使いやすいオープンソース ソリューションはほとんどありません。
Q2: このプロジェクトにはどれくらいの人的資源と物的資源が投資されましたか?少し複雑な気持ちになります。
Q2: DWS は 3 つのサブプロジェクトで構成されており、各プロジェクトには平均 5 ~ 7 人が所属しています。少し複雑ですが、実際には、当社が現在直面している困難をビッグデータ技術を使用して解決する試みです。
私たちはビッグデータ関連のテクノロジーに取り組んでいるので、チームの兄弟姉妹は全員とても満足しています:)
実際、Dbus と Wormhole は比較的固定されており、再利用が簡単です。 Swifts のリアルタイム コンピューティングは各ビジネスに関連しており、カスタマイズ性が高く、比較的面倒です。
Q3: Yixin の DWS システムはオープンソースになりますか?
A3: 私たちはコミュニティへの貢献も検討しました。CreditEase の他のオープンソース プロジェクトと同様に、このプロジェクトはまだ形になったばかりで、さらに洗練する必要があります。将来的には、オープンソースであることに貢献します。
Q4: アーキテクトをどのように理解しますか?彼はシステム エンジニアですか?
A4: はシステム エンジニアではありません。CreditEase には複数のアーキテクトがいます。彼らはテクノロジーでビジネスを推進する技術マネージャーとみなされるべきです。製品設計、技術管理等を含みます。
Q5:レプリケーション スキームは OGG ですか?
A5: OGG および上記の他の商用ソリューションはオプションです。
記事の出典: DBAplus コミュニティ (dbaplus)
以上がリアルタイムの抽出とログベースのデータ同期の一貫性の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。