
ホームページ >テクノロジー周辺機器 >AI >RoboFusion による SAM を使用した信頼性の高いマルチモーダル 3D 検出
RoboFusion による SAM を使用した信頼性の高いマルチモーダル 3D 検出

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-16 14:03:211255ブラウズ
論文リンク: https://arxiv.org/pdf/2401.03907.pdf
マルチモーダル 3D 検出器は、安全で信頼性の高い自動運転認識システムを研究するために設計されています。クリーンなベンチマーク データセットでは最先端のパフォーマンスを実現しますが、現実世界の環境の複雑さと過酷な条件は無視されることがよくあります。同時に、ビジュアルベーシックモデル (VFM) の出現により、マルチモーダル 3D 検出の堅牢性と汎用化機能の向上は、自動運転における機会と課題に直面しています。したがって、著者らは、SAM のような VFM を活用して配布外 (OOD) ノイズ シナリオに対処する RoboFusion フレームワークを提案します。
まず、元の SAM を SAM-AD という名前の自動運転シナリオに適用します。 SAM または SAMAD をマルチモーダル手法と連携させるために、SAM によって抽出された画像特徴をアップサンプリングする AD-FPN を導入します。ノイズと天候による干渉をさらに低減するために、ウェーブレット分解を使用して深度ガイド画像のノイズを除去します。最後に、セルフ アテンション メカニズムを使用して、融合された特徴を適応的に再重み付けし、過剰なノイズを抑制しながら有益な特徴を強化します。 RoboFusion は、VFM の汎用性と堅牢性を活用してノイズを徐々に低減することで、マルチモーダル 3D オブジェクト検出の回復力を強化します。その結果、KITTIC および nuScenes-C ベンチマークの結果によると、RoboFusion はノイズの多いシーンでも最先端のパフォーマンスを実現します。
この論文では、SAM のような VFM を利用して、3D マルチモーダルオブジェクト検出器をクリーンなシーンから OOD ノイズの多いシーンまで適応させる、RoboFusion という名前の堅牢なフレームワークを提案しています。中でも鍵となるのはSAMの適応戦略だ。
1) セグメンテーション結果を推測する代わりに、SAM から抽出された特徴を使用します。
2) SAM-AD が提案されています。これは、AD シナリオ用の事前トレーニングされた SAM です。
3) 新しい AD-FPN は、VFM をマルチモーダル 3D 検出器と調整するためのフィーチャー アップサンプリングの問題を解決するために導入されました。
ノイズ干渉を軽減し、信号特性を維持するために、高周波ノイズと低周波ノイズを効果的に減衰させるディープ ガイド ウェーブレット アテンション (DGWA) モジュールが導入されています。
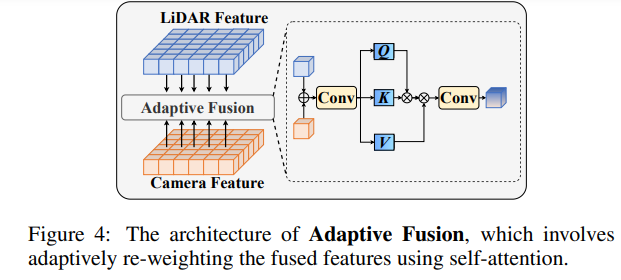
点群特徴と画像特徴を融合した後、適応融合を通じて特徴を再重み付けして、特徴の堅牢性とノイズ耐性を強化します。
RoboFusion ネットワーク構造
RoboFusion フレームワークを以下に示します。その LIDAR ブランチはベースラインに従っています [Chen et al., 2022; Bai et al., 2022]レーザー光レーダーシグネチャを生成します。カメラ ブランチでは、高度に最適化された SAM-AD アルゴリズムを最初に使用して堅牢な画像特徴を抽出し、AD-FPN と組み合わせてマルチスケール特徴を取得します。次に、元の点を使用して疎な深度マップ S が生成されます。このマップは深度エンコーダに入力されて深度特徴が取得され、マルチスケール画像特徴と融合されて深度ガイド付き画像特徴が取得されます。次に、変動する注意メカニズムを通じて突然変異ノイズが除去されます。最後に、適応型融合は、点群特徴と深度情報を備えた堅牢な画像特徴を組み合わせるセルフ アテンション メカニズムを通じて実現されます。
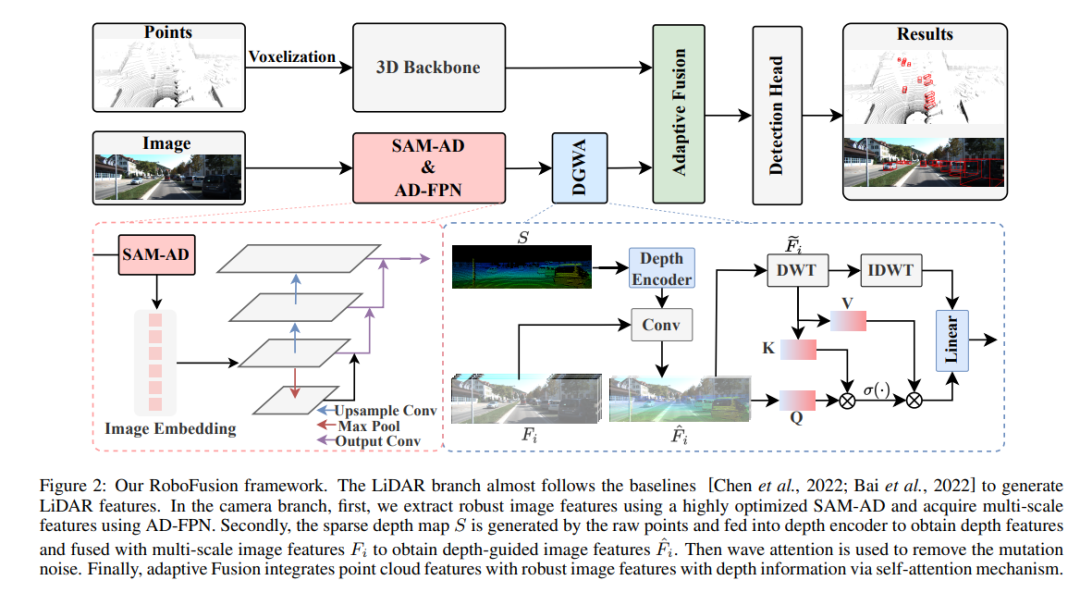
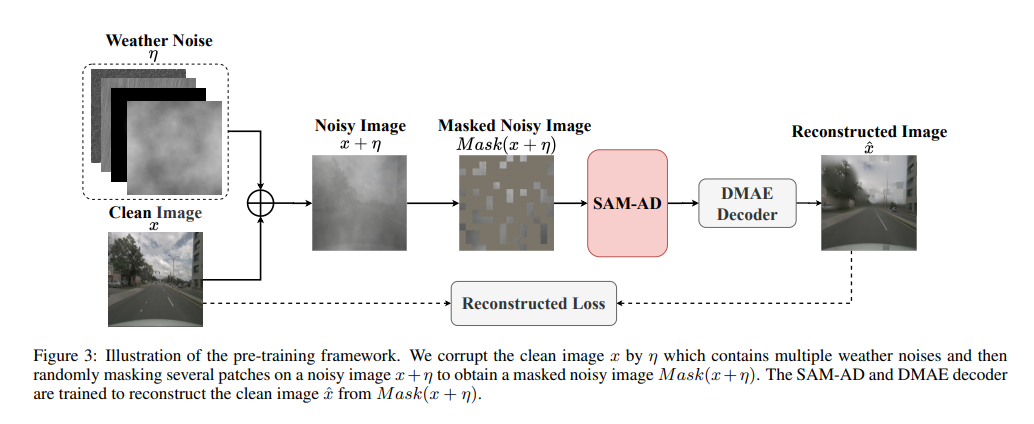
SAM-AD: SAM を AD (自動運転) シナリオにさらに適応させるために、SAM は SAM-AD を取得するように事前トレーニングされています。具体的には、成熟したデータセット (KITTI や nuScenes) から多数の画像サンプルを収集して、基本的な AD データセットを形成します。 DMAE の後、図 3 に示すように、AD シナリオで SAM-AD を取得するために SAM が事前トレーニングされます。 x を AD データセット (つまり、KITTI と nuScenes) からのクリーンな画像として示し、eta を x に基づいて生成されたノイズのある画像として示します。騒音の種類と重大度は、それぞれ 4 つの気象条件 (雨、雪、霧、晴天) と 1 ~ 5 の 5 つの重大度レベルからランダムに選択されました。 MobileSAM の画像エンコーダである SAM をエンコーダとして使用しますが、デコーダと再構成の損失は DMAE と同じです。
AD-FPN。キュー可能なセグメンテーション モデルとして、SAM はイメージ エンコーダ、キュー エンコーダ、マスク デコーダの 3 つの部分で構成されます。一般に、画像エンコーダを一般化して VFM をトレーニングしてからデコーダをトレーニングする必要があります。言い換えれば、画像エンコーダーは下流モデルに高品質で非常に堅牢な画像埋め込みを提供できますが、マスク デコーダーはセマンティック セグメンテーションのデコード サービスのみを提供するように設計されています。さらに、私たちが必要としているのは、キュー エンコーダーによるキュー情報の処理ではなく、堅牢な画像特徴です。したがって、SAM の画像エンコーダを使用して、堅牢な画像特徴を抽出します。ただし、SAMでは画像エンコーダとしてViTシリーズを採用しており、マルチスケール機能を排除し、高次元の低解像度機能のみを提供しています。 [Li et al., 2022a] に触発されて、ターゲット検出に必要なマルチスケール特徴を生成するために、ViT! に基づいたマルチスケール特徴を提供する AD-FPN が設計されています。
SAM-AD または SAM が堅牢な画像特徴を抽出できるにもかかわらず、2D ドメインと 3D ドメインの間にはギャップが依然として存在しており、損傷した環境で幾何学的な情報が不足しているカメラでは、ノイズが増幅され、マイナスの転送問題が発生することがよくあります。この問題を軽減するために、我々はディープ ガイド付きウェーブレット アテンション (DGWA) モジュールを提案します。これは次の 2 つのステップに分割できます。 1) 深度ガイダンス ネットワークは、画像特徴と点群の深度特徴を組み合わせることにより、画像特徴の前にジオメトリを追加するように設計されています。 2) Haar ウェーブレット変換を使用して、画像の特徴を 4 つのサブバンドに分解します。その後、アテンション メカニズムにより、サブバンド内の情報特徴のノイズを除去できます。
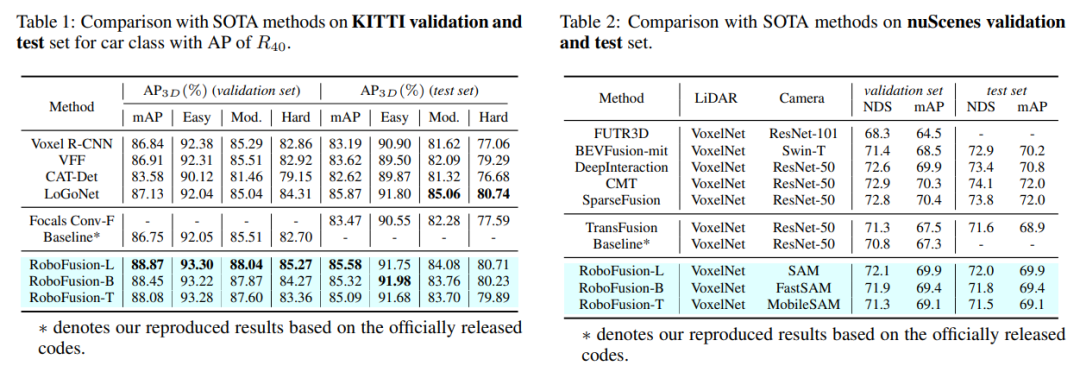
#実験による比較
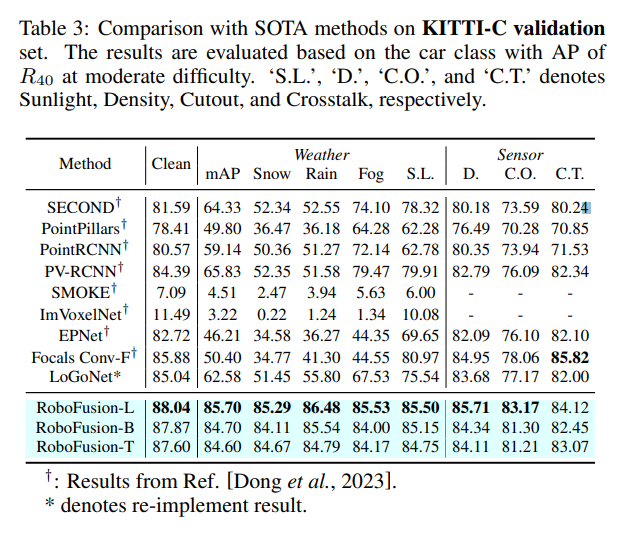
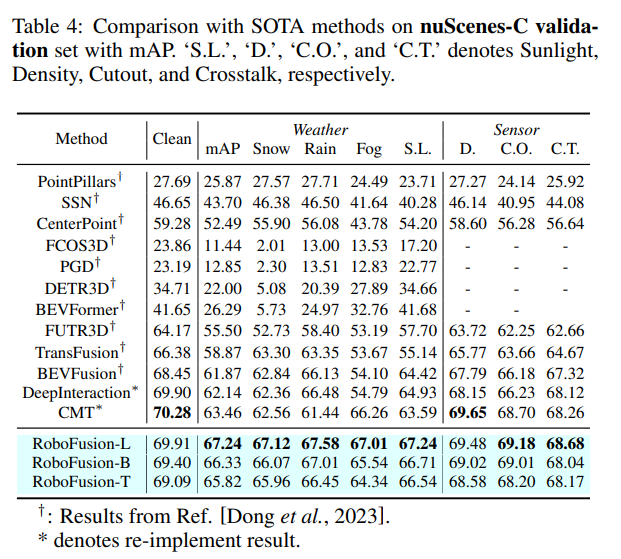
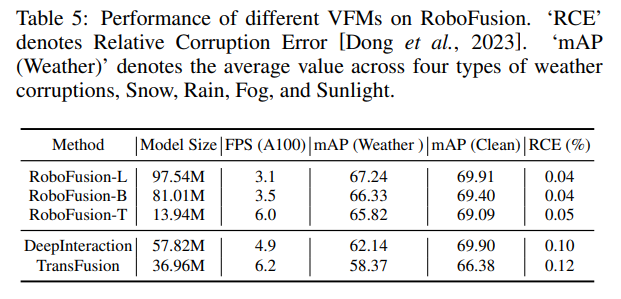

 #元のリンク: https://mp.weixin.qq.com/s/78y1KyipHeUSh5sLQZy-ng
#元のリンク: https://mp.weixin.qq.com/s/78y1KyipHeUSh5sLQZy-ng
以上がRoboFusion による SAM を使用した信頼性の高いマルチモーダル 3D 検出の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。