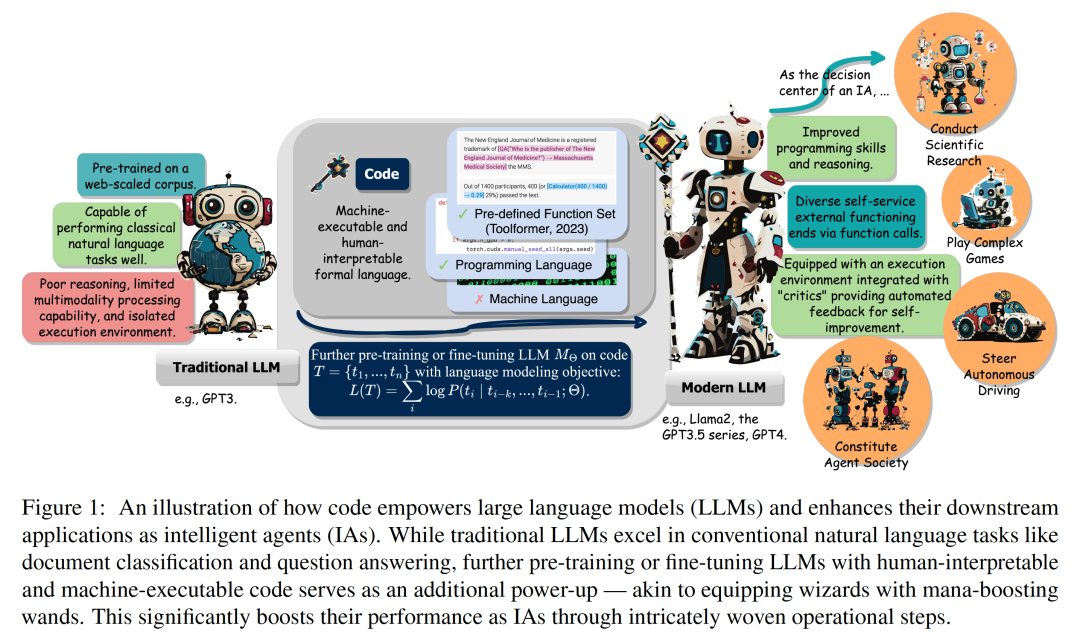
かつてリスフォードの杖がダンブルドアのような並外れた魔術師の伝説を生み出したように、大きな可能性を秘めた従来の大規模言語モデルは、コードコーパスの事前トレーニング/微調整を経て、元の実行能力を超えたものを習得しました。 具体的には、大規模モデルの高度なバージョンは、コードの記述、より強力な推論、実行インターフェイスへの独立した参照、独立した改善などの点で改善されています。 AI エージェントとして、下流のタスクを実行する際にあらゆる面でメリットをもたらします。 最近、イリノイ大学アーバナシャンペーン校 (UIUC) の研究チームが重要なレビューを発表しました。 
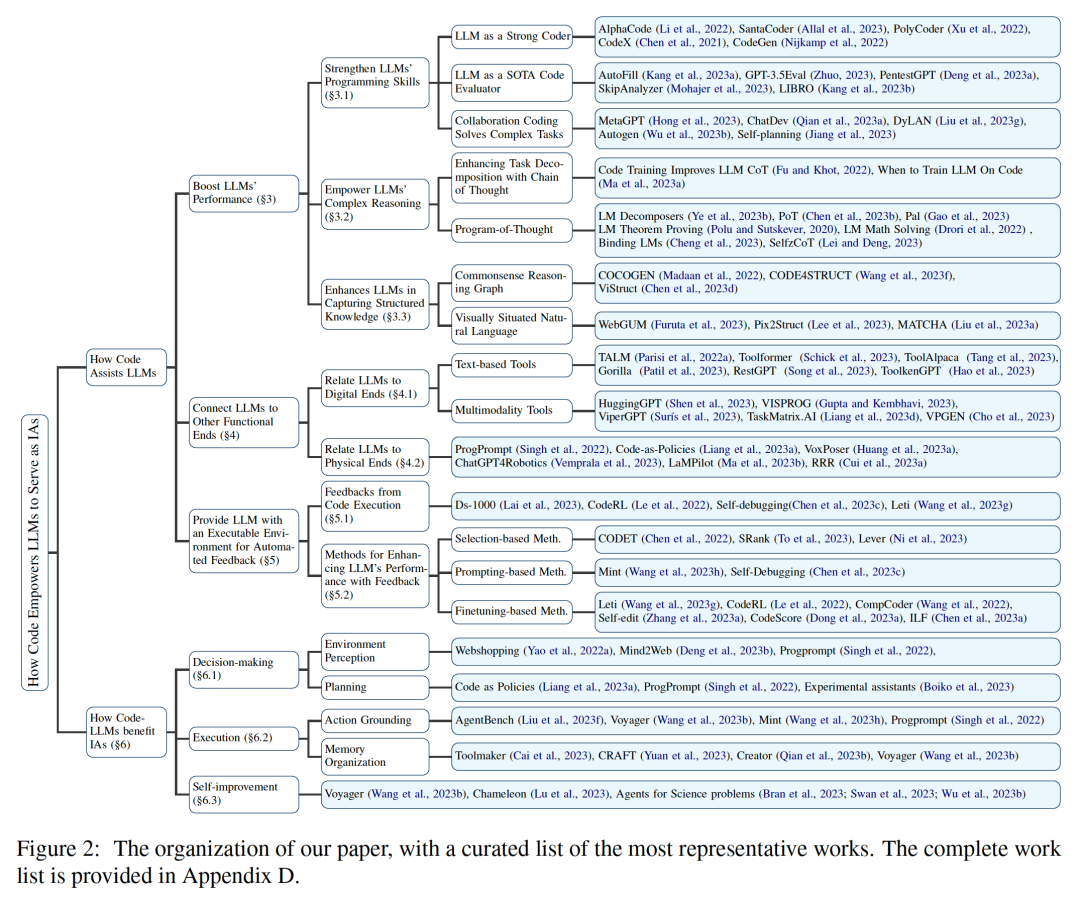
論文リンク: https://arxiv.org/abs/2401.00812このレビューではコード (コード) 大規模言語モデル (LLM) と、それらに基づく強力な機能に基づくインテリジェント エージェント (インテリジェント エージェント) を提供する方法。 その中で、コードとは、プログラミング言語、事前定義された関数セットなど、機械で実行可能で人間が判読できる形式言語を特に指します。従来の自然言語を理解/生成するように LLM を指導する方法と同様に、LLM をコードに習熟させるには、同じ言語モデリングのトレーニング目標をコード データに適用するだけで済みます。 従来の言語モデルとは異なり、Llama2 や GPT4 など、現在一般的に使用されている LLM は、サイズが大幅に向上しただけでなく、典型的な自然言語モデルとは独立して開発されています。言語コーパス、コードコーパスのトレーニング。コードは、標準化された構文、論理的一貫性、抽象化、モジュール性を備えており、高レベルの目標を実行可能なステップに変換できるため、人間とコンピューターを接続する理想的な媒体となります。 図 2 に示すように、このレビューでは、研究者は関連する研究をまとめ、コードを LLM トレーニング データに組み込むことのさまざまな利点を詳細に分析しました。 #研究者らは、特に、コードの固有のプロパティが次の要因に寄与していることを観察しました。
1 . LLM のコード記述能力、推論能力、構造化情報処理能力を強化して、より複雑な自然言語タスクに適用できるようにする;
2. LLM が構造化された正確な中間ステップ (以下のステップ) を生成できるようにガイドする関数呼び出しを通じて外部の実行エンドに接続できます;
3. コードのコンパイルおよび実行環境を使用して、モデルを独自に改善するための多様なフィードバックを提供します。
さらに、研究者らは、コードによって与えられるこれらの LLM の最適化項目、インテリジェント エージェントの意思決定センターとしての LLM をどのように強化するかについても深く調査しました。指示、目標の分解、計画、およびアクションを実行してフィードバックから改善するための一連の能力。
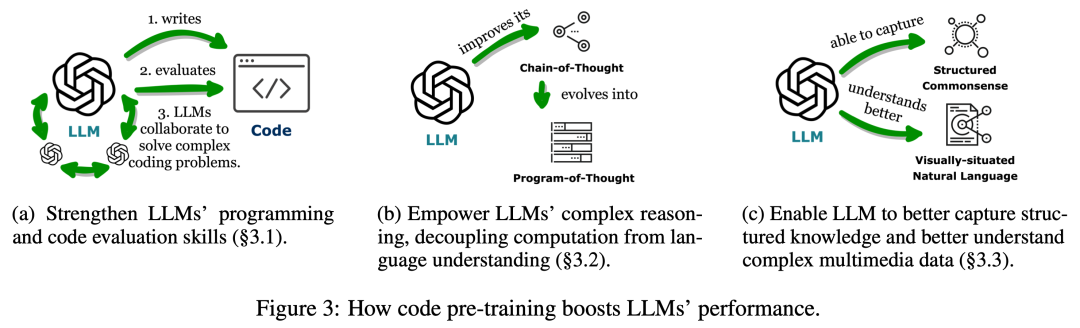
図 3 に示すように、最初の部分では、コード上で LLM を事前トレーニングすることで、LLM のタスク範囲が自然言語に拡張されたことが研究者らによってわかりました。 。これらのモデルは、数学理論のコード生成、一般的なプログラミング タスク、データ検索など、さまざまなアプリケーションをサポートできます。コードは、論理的に一貫した順序付けられた一連のステップを生成する必要があり、これは効果的な実行に不可欠です。さらに、コード内の各ステップが実行可能であるため、ロジックを段階的に検証できます。事前トレーニングでこれらのコード属性を活用して埋め込むと、多くの従来の自然言語の下流タスクにおける LLM の思考連鎖 (CoT) パフォーマンスが向上し、複雑な推論スキルの向上が実証されます。同時に、コードの構造化形式を暗黙的に学習することにより、codeLLM は、マークアップ言語、HTML、図の理解に関連するタスクなど、常識的な構造化推論タスクのパフォーマンスを向上させます。
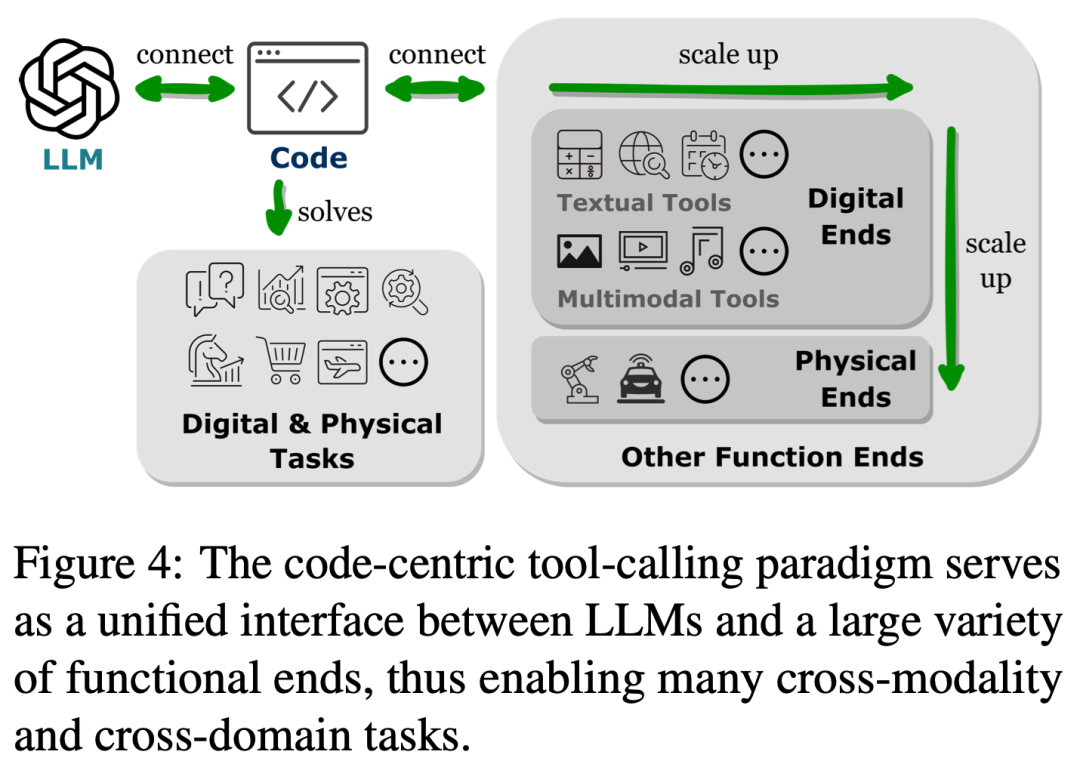
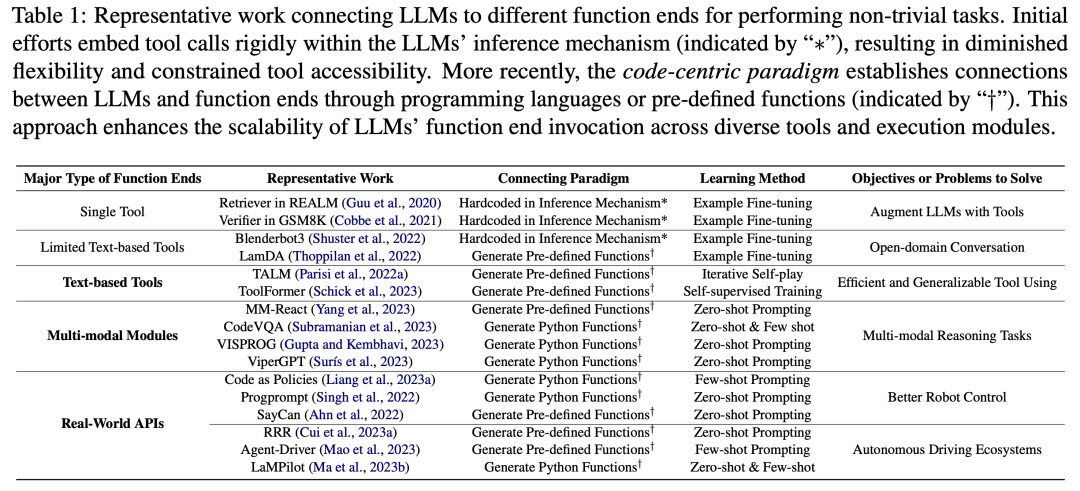
図 4 に示すように、LLM を他の機能端と接続する (つまり、外部ツールや実行モジュールを通じて LLM の機能を拡張する) と、LLM がより正確かつ確実にタスクを実行できるようになります。 。
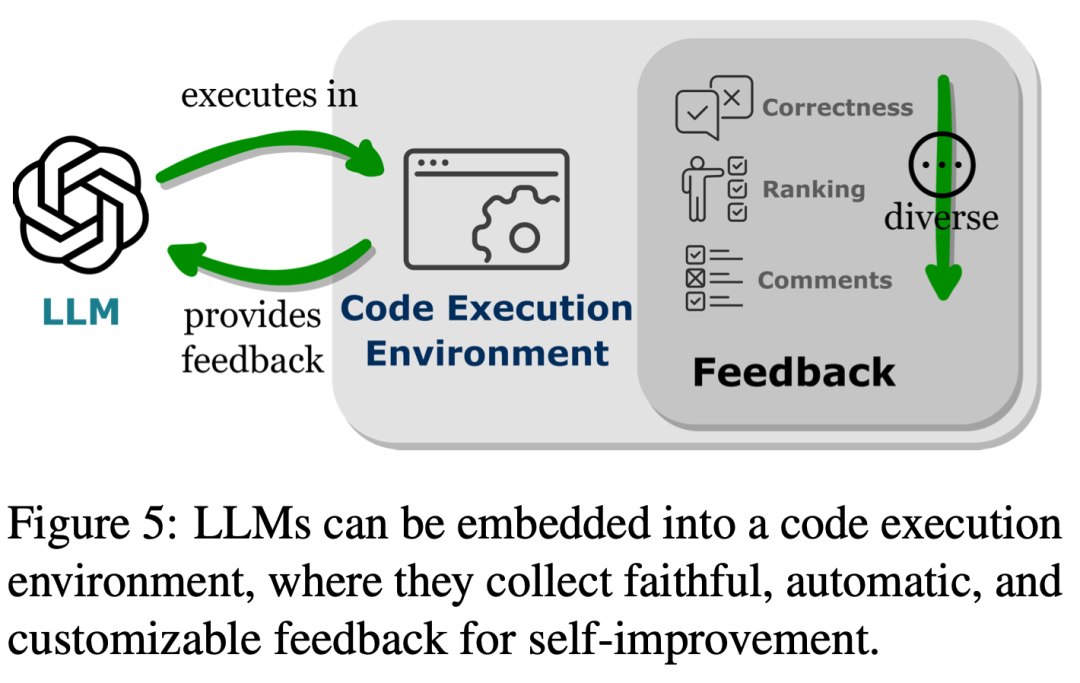
2 番目の部分では、表 1 に示すように、研究者は一般的な傾向を観察しました。LLM は、プログラミング言語を生成するか、事前定義された関数を利用することによって、他の機能エンドポイントとの接続を確立します。この「コード中心のパラダイム」は、LLM の推論メカニズムにおけるツール呼び出しを厳密にハードコーディングする厳格なアプローチとは異なります。これにより、LLM は、調整可能なパラメーターを使用して、実行モジュールを呼び出すトークンを動的に生成できます。 このパラダイムは、LLM が他の機能目的と対話するためのシンプルかつ明確な方法を提供し、アプリケーションの柔軟性と拡張性を強化します。さらに重要なことは、LLM が複数のモダリティやドメインをカバーする多数の機能エンドポイントと対話できるようになることです。 LLM がアクセスできる機能端末の数と種類を拡張することで、LLM はより複雑なタスクを処理できるようになります。 図 5 に示すように、LLM をコード実行環境に埋め込むと、自動フィードバックと独立したモデルの改善を実現できます。 LLM は、フィードバックに対応できるため、トレーニング パラメーターの範囲を超えてパフォーマンスを発揮します。ただし、ノイズの多いキュー入力は下流タスクでの LLM のパフォーマンスを妨げる可能性があるため、フィードバックは慎重に選択する必要があります。さらに、人材にはコストがかかるため、信頼性を維持しながらフィードバックを自動的に収集する必要があります。 3 番目の部分では、研究者らは、コード実行環境に LLM を埋め込むことで、これらの基準をすべて満たすフィードバックが得られることを発見しました。 まず、コードの実行は決定的であるため、コードの実行結果からフィードバックを取得すると、LLM によって実行されたタスクを直接かつ忠実に反映できます。さらに、コード インタープリタは、LLM に内部フィードバックを自動的にクエリする方法を提供し、LLM を利用して誤ったコードをデバッグまたは最適化する際に、高価な人間による注釈の必要性を排除します。また、コードのコンパイルおよび実行環境により、LLM はバイナリ正誤評価の単純な生成、実行結果の少し複雑な自然言語説明、フィードバック値によるさまざまなランキングなど、多様かつ包括的な外部フィードバック フォームを組み込むことができます。パフォーマンスを向上させる方法を高度にカスタマイズ可能にします。 コード トレーニング データの統合によって LLM の機能が強化されるさまざまな方法を分析することで、研究者らは、LLM を強化するコードの利点がインテリジェント エージェントの主要な開発にあることをさらに発見しました。 LLM の応用分野は特に明らかです。 図 6 は、インテリジェント アシスタントの標準的なワークフローを示しています。研究者らは、LLM でのコード トレーニングによってもたらされた改善が、インテリジェント アシスタントとして実行される実際のステップにも影響を与えていることを観察しました。 これらのステップには、(1) 環境意識と計画における IA の意思決定能力の強化、(2) モジュール式アクションプリミティブでのアクションの実装、およびポリシーの実行を最適化するためのメモリの効率的な構成、および (3) コード実行環境から自動的に得られるフィードバックを通じてパフォーマンスを最適化します。 要約すると、このレビューでは、コードがどのように LLM に強力な機能を与えるのか、またコードが LLM がインテリジェント エージェントの意思決定センターとして機能するのをどのように支援するのかを研究者が分析し、明らかにしています。 研究者らは、包括的な文献レビューを通じて、コード トレーニングの後、LLM がプログラミング スキルと推論能力を向上させ、実装とクロスモーダルおよびドメインの専門知識を獲得したことを観察しました。複数の機能端末の接続機能に加えて、コード実行環境に統合された評価モジュールと対話して自動自己改善を実現する機能も強化されています。 さらに、コード トレーニングによってもたらされた LLM の機能の向上により、下流アプリケーションで LLM がインテリジェント エージェントとして機能し、意思決定、実行、実行などの特定のタスクに反映されます。自己改善のステップ。研究者らは、先行研究のレビューに加えて、潜在的な将来の方向性を導く要素として、この分野におけるいくつかの課題も提案した。 #詳細については、元の記事を参照してください。
以上が優れたプログラミング リソース、巨大なモデル、エージェントを解き放ち、より強力な力を引き起こしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。