
ホームページ >テクノロジー周辺機器 >AI >モデル、データ、フレームワークの詳細: 効率的な大規模言語モデルの 54 ページにわたる徹底的なレビュー
モデル、データ、フレームワークの詳細: 効率的な大規模言語モデルの 54 ページにわたる徹底的なレビュー

- PHPz転載
- 2024-01-14 19:48:061396ブラウズ
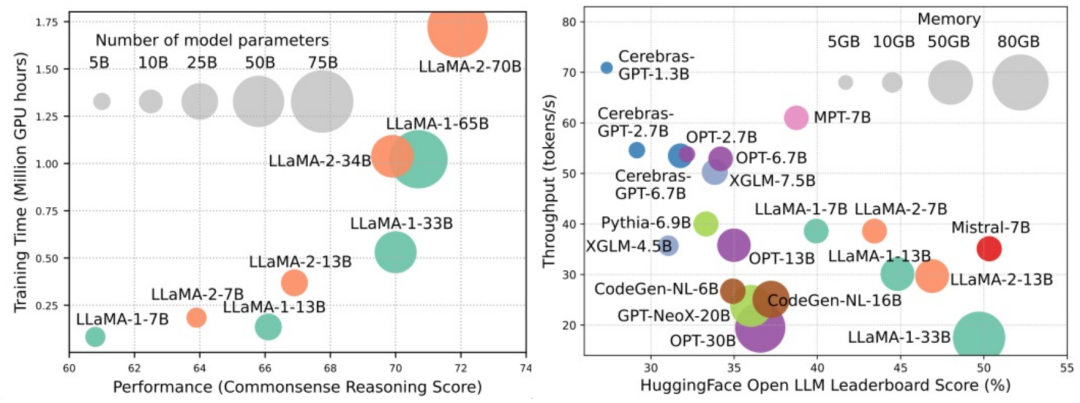
大規模言語モデル (LLM) は、自然言語理解、言語生成、複雑な推論など、多くの重要なタスクにおいて説得力のある機能を実証し、社会に大きな影響を与えてきました。ただし、これらの優れた機能には、大量のトレーニング リソース (左の図に示す) と長い推論時間 (右の図に示す) が必要です。したがって、研究者は効率の問題を解決するための効果的な技術的手段を開発する必要があります。
さらに、図の右側からわかるように、Mistral-7B などのいくつかの効率的な LLM (言語モデル) が、LLM の設計と展開にうまく使用されています。 。これらの効率的な LLM は、LLaMA1-33B と同様の精度を維持しながら、推論メモリの使用量を大幅に削減し、推論の待ち時間を短縮できます。これは、LLM の設計と使用にうまく適用されている、実行可能で効率的な方法がすでにいくつかあることを示しています。
このレビューでは、オハイオ州立大学、インペリアル カレッジ、ミシガン州立大学、ミシガン大学、Amazon、Google、Boson AI、研究者の専門家が協力しています。 Microsoft Asia Research では、効率的な LLM に関する体系的かつ包括的な研究調査を提供しています。彼らは、LLM の効率を最適化するための既存のテクノロジーを モデル中心、データ中心、フレームワーク中心 の 3 つのカテゴリに分類し、最も最先端の関連テクノロジーを要約して議論しました。

- #論文: https://arxiv.org/abs/2312.03863
- GitHub: https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey
レビューに関係する論文を便利に整理し、最新の状態に保つために、研究者は GitHub リポジトリを作成し、積極的に維持しています。彼らは、このリポジトリが研究者や実践者が効率的な LLM の研究開発を体系的に理解し、この重要で刺激的な分野に貢献するよう促すのに役立つことを望んでいます。
ウェアハウスの URL は https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey です。このリポジトリでは、効率的で低消費電力の機械学習システムの調査に関連するコンテンツを見つけることができます。このリポジトリは、人々が効率的で低消費電力の機械学習システムをより深く理解し、検討するのに役立つ研究論文、コード、ドキュメントを提供します。この分野に興味がある場合は、このリポジトリにアクセスして詳細情報を入手できます。
モデル中心
モデル中心のアプローチは、アルゴリズム レベルとシステム レベルでの効率的な手法に焦点を当てており、モデル自体が焦点となります。 。 LLM には数十億、さらには数兆のパラメータがあり、小規模モデルと比較して創発性などの独特の特性があるため、LLM の効率を最適化するには新しい技術を開発する必要があります。この記事では、 モデル圧縮、効率的な事前トレーニング、効率的な微調整、効率的な推論、効率的なモデル アーキテクチャ設計 を含む、モデル中心の手法の 5 つのカテゴリについて詳しく説明します。
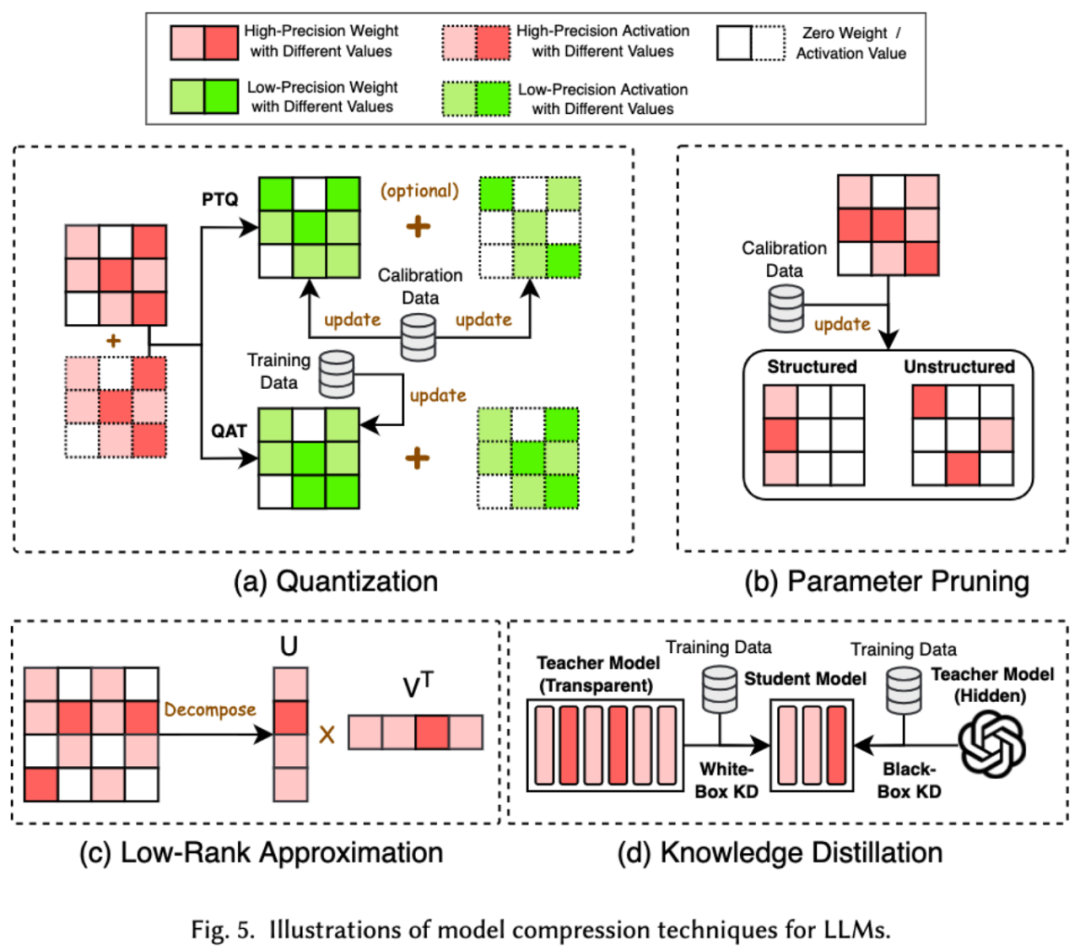
1. 圧縮モデル 機械学習の分野では、モデルのサイズが重要な考慮事項となることがよくあります。モデルが大きくなると、より多くのストレージ スペースとコンピューティング リソースが必要になることが多く、モバイル デバイスで実行すると制限が発生する可能性があります。したがって、モデル圧縮は、モデルのサイズを削減できる一般的に使用されるテクノロジです。
モデル圧縮テクノロジは、主に、量子化、パラメータ プルーニング、低圧縮の 4 つのカテゴリに分類されます。ランク推定と知識の蒸留 (以下の図を参照)。量子化によりモデルの重みまたはアクティベーション値が高精度から低精度に圧縮され、パラメータ プルーニングによりモデルの重みのより冗長な部分が検索および削除されます。低ランクの推定はモデルの重みを減らします。重み行列はいくつかの低ランクの小さな行列の積に変換され、知識の蒸留は大きなモデルを直接使用して小さなモデルをトレーニングするため、小さなモデルは次のような能力を持ちます。特定のタスクを実行するときに大きなモデルを置き換えます。
#2. 効率的な事前トレーニング
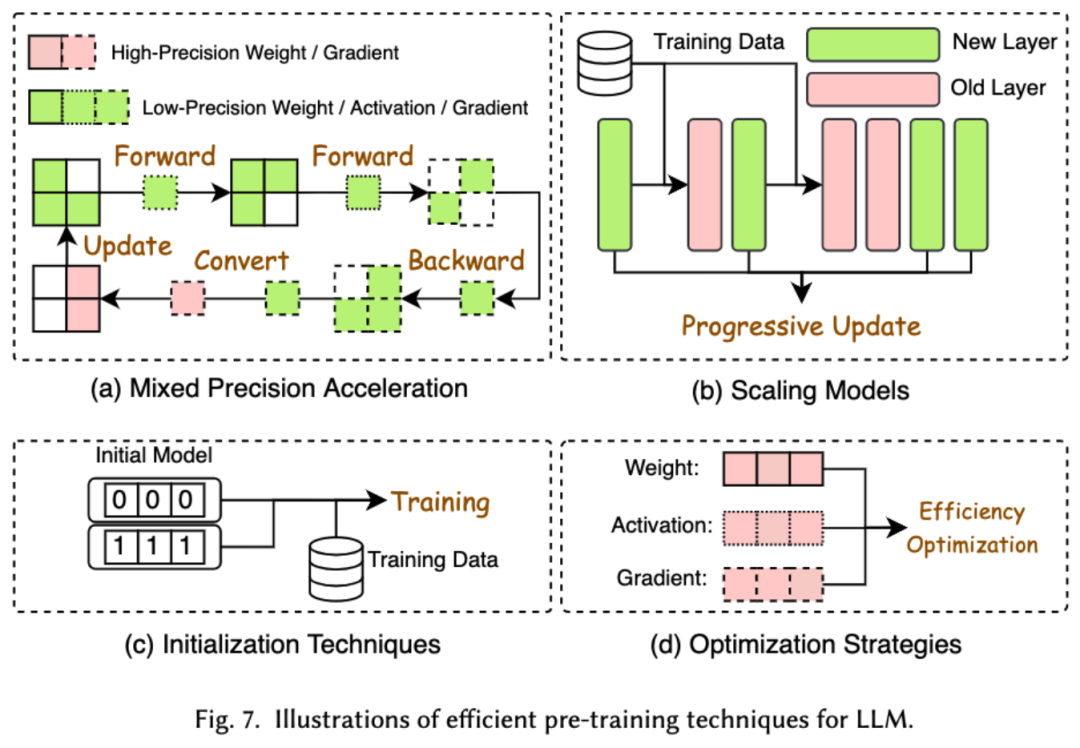
##LLM の事前トレーニングのコストは非常に高価です。効率的な事前トレーニングは、効率を向上させ、LLM の事前トレーニング プロセスのコストを削減することを目的としています。効率的な事前トレーニングは、混合精度アクセラレーション、モデル スケーリング、初期化テクノロジ、最適化戦略、およびシステム レベルのアクセラレーションに分類できます。
混合精度アクセラレーションは、低精度の重みを使用して勾配、重み、およびアクティベーションを計算し、その後高精度に変換して元の重みを更新するために適用することで、事前トレーニングの効率を向上させます。モデルのスケーリングは、小さなモデルのパラメーターを使用して大規模なモデルにスケールすることで、トレーニング前の収束を加速し、トレーニング コストを削減します。初期化テクノロジは、モデルの初期化値を設計することにより、モデルの収束を高速化します。最適化戦略は、モデルのトレーニング中のメモリ消費を削減する軽量オプティマイザーの設計に重点を置いており、システム レベルのアクセラレーションでは、分散テクノロジやその他のテクノロジを使用して、システム レベルからモデルの事前トレーニングを高速化します。
3. 効率的な微調整
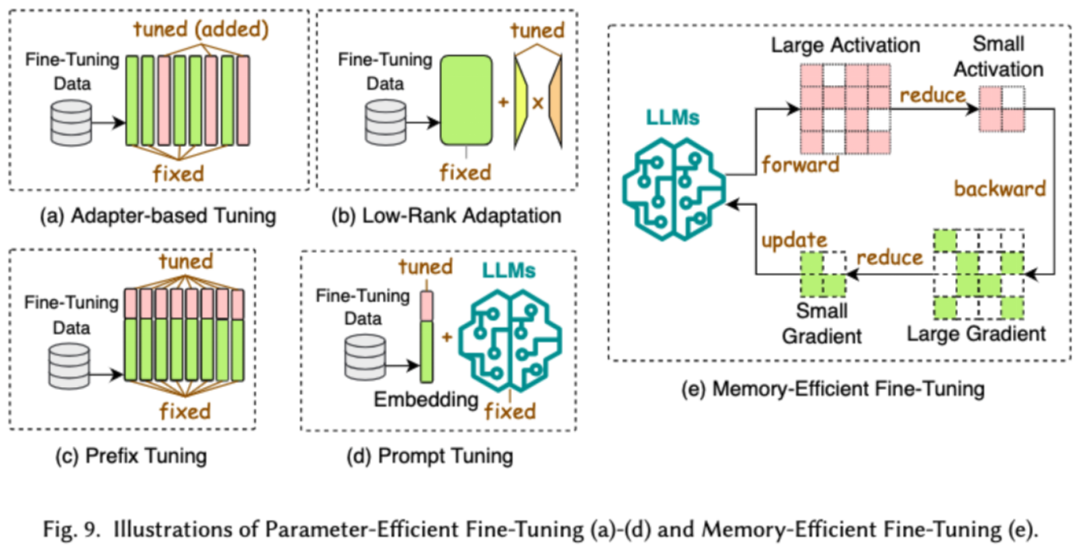
効率的な微調整の目的LLM のプロセス効率を微調整します。一般的な効率的な微調整テクノロジは 2 つのカテゴリに分類されます。1 つはパラメータベースの効率的な微調整で、もう 1 つはメモリ効率の高い微調整です。
パラメータベースの効率的な微調整 (PEFT) の目標は、LLM バックボーン全体をフリーズし、追加パラメータの少数のセットのみを更新することによって、LLM をダウンストリーム タスクに合わせて調整することです。この論文では、PEFT をアダプターベースの微調整、低ランク適応、プレフィックス微調整、およびプロンプトワード微調整にさらに分割しました。
効率的なメモリベースの微調整では、オプティマイザのステータスやアクティブ化値によって消費されるメモリの削減など、LLM の微調整プロセス全体でのメモリ消費の削減に重点が置かれています。
4. 効率的な推論
効率的な推論は、LLM の推論を改善することを目的としています。プロセスの効率化。研究者は、一般的な高効率推論テクノロジを 2 つのカテゴリに分類しています。1 つはアルゴリズム レベルの推論の高速化、もう 1 つはシステム レベルの推論の高速化です。
アルゴリズム レベルでの推論の高速化は、投機的デコードと KV (キャッシュの最適化) の 2 つのカテゴリに分類できます。投機的デコードでは、より小さなドラフト モデルを使用してトークンを並行して計算し、より大きなターゲット モデルの投機的プレフィックスを作成することで、サンプリング プロセスを高速化します。 KV - キャッシュの最適化とは、LLM の推論プロセス中にキーと値 (KV) ペアの繰り返し計算を最適化することを指します。
システムレベルの推論高速化は、指定されたハードウェアでのメモリ アクセス数の最適化、アルゴリズムの並列処理量の増加などを行い、LLM 推論を高速化します。
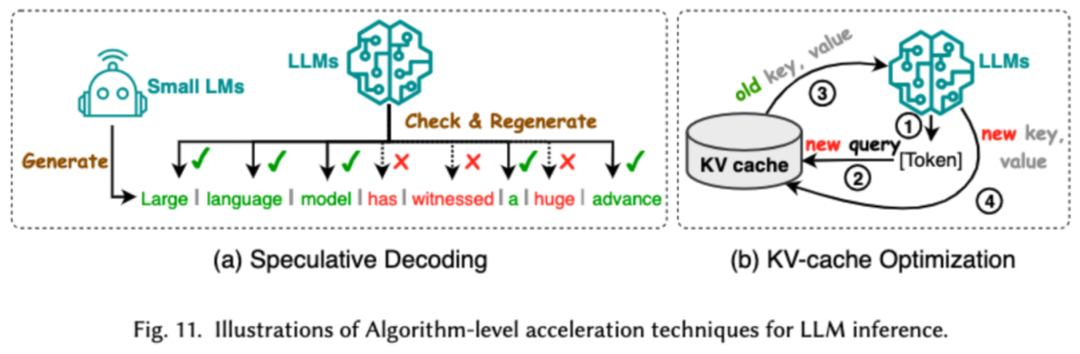
#5. 効率的なモデル アーキテクチャ設計
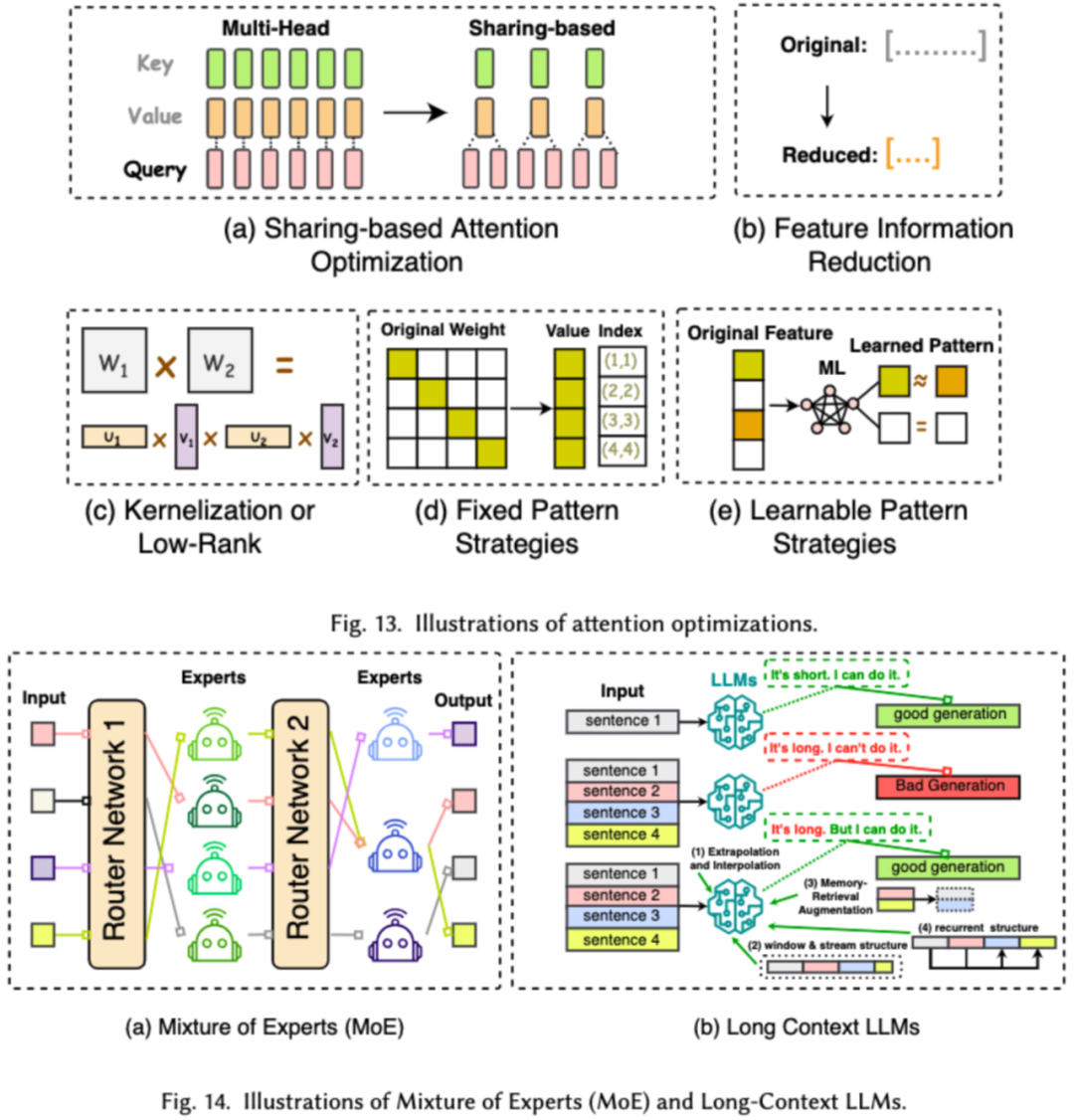
# LLM の効率的なアーキテクチャ設計とは、リソースの消費を最小限に抑えながらパフォーマンスとスケーラビリティを向上させるために、モデルの構造と計算プロセスを戦略的に最適化することを指します。私たちは、効率的なモデル アーキテクチャの設計を、モデル タイプに基づいて 4 つの主要なカテゴリ (効率的なアテンション モジュール、ハイブリッド エキスパート モデル、長いテキストのラージ モデル、およびトランスフォーマーに代わるアーキテクチャ) に分類します。
効率的なアテンション モジュールは、アテンション モジュールでの複雑な計算とメモリ使用量を最適化することを目的としていますが、混合エキスパート モデル (MoE) は、LLM の一部のモジュールで複数の推論による決定を使用します。エキスパート モデルは、全体的なスパース性を実現するための代替として使用されます。ロング テキスト ラージ モデルは、超長いテキストを効率的に処理するために特別に設計された LLM です。トランスフォーマーを置き換えることができるアーキテクチャは、モデルの複雑さを軽減し、モデル アーキテクチャを再設計することでモデルを構築し、変圧器後のアーキテクチャに対して同等の推論機能を実現します。
データ中心
データ中心のアプローチでは、データの品質と構造に焦点を当てます。 LLM の効率を向上させる役割を果たします。この記事では、データ選択とプロンプト ワード エンジニアリングを含む 2 種類のデータ中心の手法について研究者が詳しく説明します。
1. データ選択
LLM のデータ選択は、事前に行うことを目的としています。トレーニング/トレーニング プロセスを高速化するために、冗長データや無効なデータを削除するなど、クリーニングと選択のためにデータを微調整します。
2. Prompt Word プロジェクト
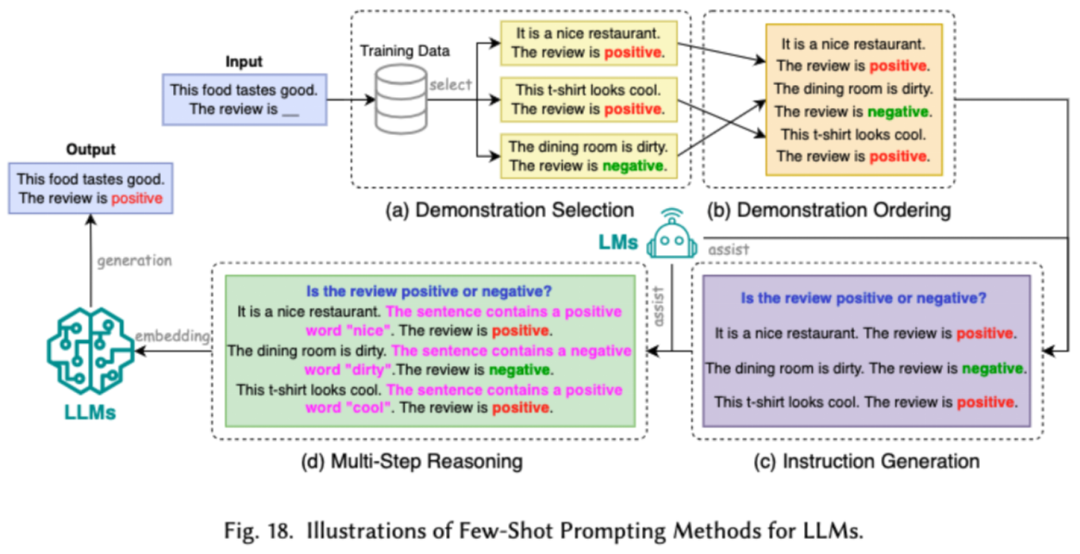
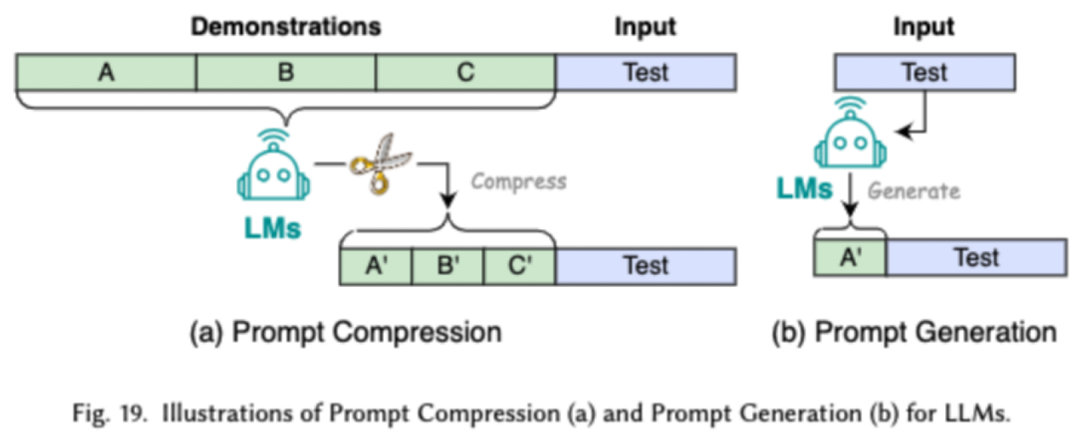
Prompt Word プロジェクトは、効果的な入力 (プロンプト ワード) を設計することで LLM をガイドします。望ましい出力を生成するには、退屈な微調整と同等のモデル パフォーマンスを達成するようにプロンプト ワードを設計できることが重要です。研究者は、一般的なプロンプト ワード エンジニアリング テクノロジを、少数サンプル プロンプト ワード エンジニアリング、プロンプト ワード圧縮、およびプロンプト ワード生成という 3 つの主要なカテゴリに分類しています。
少数サンプルのプロンプト ワード プロジェクトは、LLM に、実行する必要があるタスクの理解を助けるための限られたサンプル セットを提供します。プロンプト単語圧縮は、長いプロンプト入力を圧縮するか、学習してプロンプト表現を使用することにより、LLM の入力処理を高速化します。プロンプトワード生成は、手動で注釈を付けたデータを使用するのではなく、モデルが具体的で関連性のある応答を生成するようにガイドする効果的なプロンプトを自動的に作成することを目的としています。
#フレーム中心
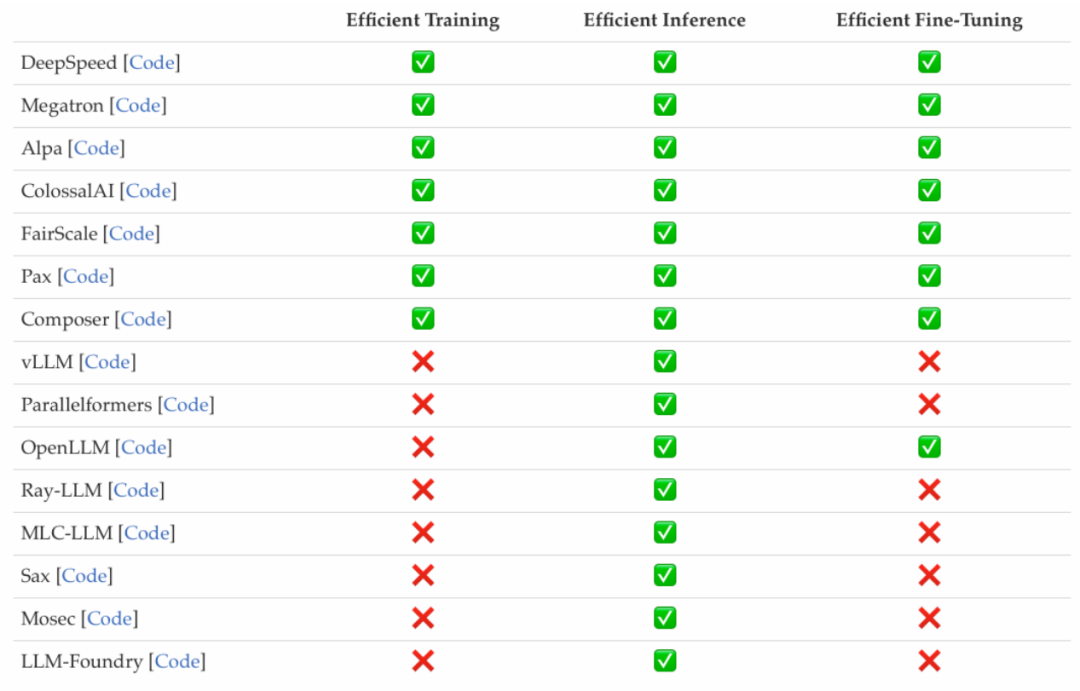
研究者は最近、一般的な効率的な LLM フレームワークには、事前トレーニング、微調整、推論など、最適化できる効率的なタスクがリストされています (下の図を参照)。
概要
この調査では、研究者はLLMの体系的なレビューを全員に提供します。 LLM をより民主化することに特化した重要な研究領域です。彼らはまず、なぜ効率的な LLM が必要なのかを説明します。この論文では、秩序あるフレームワークの下で、モデル中心、データ中心、フレームワーク中心の観点から、LLM のアルゴリズム レベルとシステム レベルでの効率的なテクノロジを調査します。
研究者らは、LLM および LLM 指向のシステムにおいて効率がますます重要な役割を果たすと考えています。彼らは、この調査が研究者や実務家がこの分野に迅速に参入するのに役立ち、効率的なLLMに関する新しい研究を刺激する触媒として機能することを望んでいます。
以上がモデル、データ、フレームワークの詳細: 効率的な大規模言語モデルの 54 ページにわたる徹底的なレビューの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。