###導入###
| DBA によって最適化されたデータベース環境では、パフォーマンスの問題の大部分は、実際には不適切な SQL 記述によって引き起こされます。 SQL の世界は不思議に満ちていますが、今日は血を吐きたくなるようなキラー SQL を紹介します。
|
保険クライアントの場合、ETL に数時間かかりました。SQL レポートを作成したところ、主に SQL の 1 つに負荷がかかっていることがわかりました。
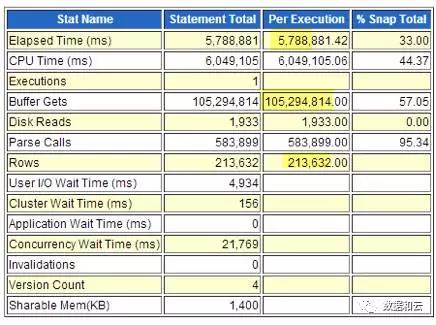
1 回の実行時間: 5788 (秒)
単一論理読み取り: 10億 (ブロック)
一度に返される行数: 210,000 (行)
まず SQL ステートメントを見てみましょう。比較的長いため、一部のみを抜粋します

実行計画を表示:
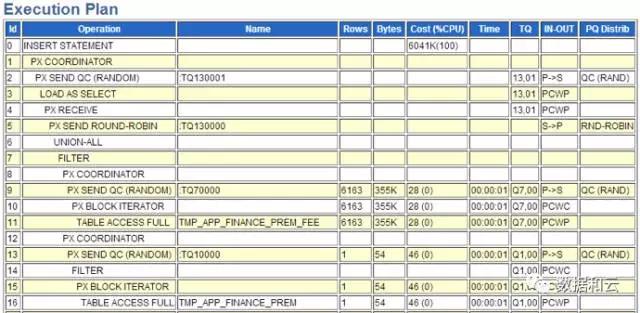
主に行 7 ~ 16 に注目します。テーブル全体のスキャンが 2 回あることがわかりました。真ん中にフィルターを施しました。
長年の経験から、2 つのテーブル全体のスキャンで構成されるフィルターには、データを 1 つずつ処理する必要があるため、重大な問題があることがわかりました。この実行プランでは、駆動テーブル全体が引き続きスキャンされます。
Not In/In 操作ではフィルター操作が生成されることがあります。11g より前のバージョンでは、not in ステートメントはアンチ結合に変換する必要があります。not in 条件の列には Not null 属性が必要です。そうでない場合は、not が含まれます。ステートメント内で。null 制限を使用しない場合は、Filter を使用して 1 つずつフィルタリングすることしかできません。
例を挙げてみましょう:
SQL1:CREATE TABLE T_OBJ AS SELECT OBJECT_ID,OWNER,OBJECT_NAME,OBJECT_TYPE FROM DBA_OBJECTS WHERE OWNER != 'SEROL';SQL2:CREATE TABLET_TABLE AS SELECT OWNER,TABLE_NAME FROM DBA_TABLES WHERE OWNER!='SEROL';
T_OBJ の属性を表示します:

3 つの列には null でないという制限がないことがわかりました。
現時点では、10G オプティマイザーであるふりをしています。
SQL> セッションの変更 set optimizer_features_enable=”10.2.0.5″;
次の SQL を実行します:
SQL>set autotracetrace exp
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME NOT IN(SELECT OBJECT_NAME FROM T_OBJ);
この時点での実行計画を確認すると、フィルターが使用されていることがわかりました:
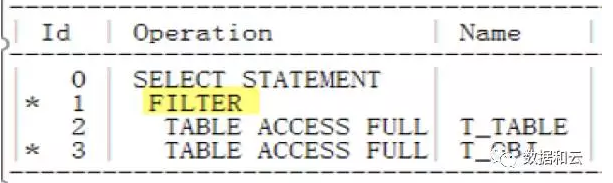
しかし、11g バージョンでは、オプティマイザは、高価なフィルターから Not in Operation を Null-Aware-Anti-Join に自動的に変換できます。
Not null 条件を追加するか、フィールド属性を not null に設定する場合
SQL> テーブル T_OBJ の変更変更(OBJECT_NAME NOT NULL);
同じステートメントを再度実行します:
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME
入っていません(T_OBJからオブジェクト名を選択してください
WHEREOBJECT_NAME が NULL ではありません);
実行計画をもう一度表示します:

現時点では、実行計画で hash join anti.
が確認されました。
また、11g では、not null 制限なしで列内の not が許可され、アンチ結合も変換できます。
SQL> セッションの変更 set optimizer_features_enable=”11.2.0.4″;
SQL> テーブル T_OBJ 変更変更(OBJECT_NAME NULL);
SQ> SELECT * FROM T_TABLE WHERE TABLE_NAME
入っていません (T_OBJ からの SELECTOBJECT_NAME);
実行計画の表示:
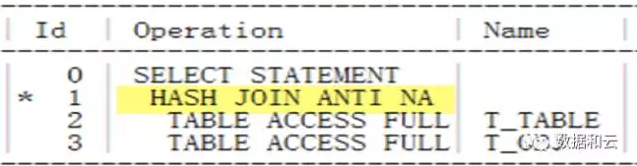
現時点では、hash join anti.
も空以外の制限なしで使用されていることがわかります。
この機能は、オプティマイザー パラメーターを通じて制御できます。
SQL>セッション セット「_optimizer_null_aware_antijoin」を変更します=FALSE;
上記のステートメントを再度実行し、実行計画を表示します:
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME
入っていません (T_OBJ からの SELECTOBJECT_NAME);
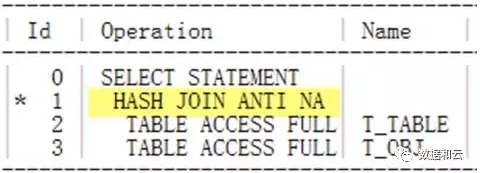
ハッシュ結合 anti.
がまだ使用されていることがわかりました。
検証の結果、このパラメータ設定で問題ありません
Not in のロジックは結果セット間の相互排他です。実際、これを書き換える方法は次のとおりです。
###-存在しない###
#—— 外部結合が null です
###-マイナス###
not in と上記の 3 つの書き方の違いは、not in では null 値が除外されることです。
書き換えてみます。
次に、奇跡が起こると思ったとき、ステートメントでエラーが報告されました。
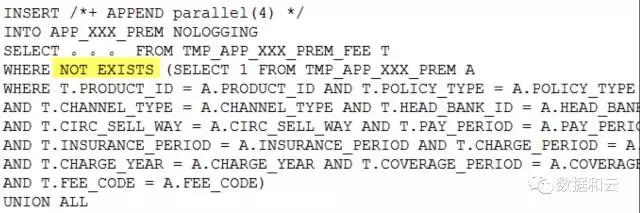
エラーが報告されるのはなぜですか?
このステートメントを not in に変換すると:

not inのロジックに従い、このときfee_codeの前に'A.'を追加することになりますが、もちろん問題ありませんが、この文をもう一度見てみると、
となります。

TMP_APP_xxx_PREM A には FEE_CODE フィールドがないため、Not in を Null Aware ANTI JOIN に自動的に変更することはできません。
それでは、答えが明らかになった今、それは間違いだったということになるのでしょうか? !始まりは推測できましたが、結末は推測できませんでした。
ただし、この場合、ステートメントが SQL ステートメントに明示的に記述されていないため、このエラーは初期の分析プロセスでは発見されませんでした。
あなたも言葉を失いましたか?実際、私がもっと聞きたいのは、キラー SQL をよく書くのですか?でも、それは問題ではありません。もし病気なら、私は薬を持っています。 (無邪気な顔、殴らないでね)
DBA によって最適化されたデータベース環境では、パフォーマンスの問題の大部分が実際には不適切な SQL 記述によって引き起こされていることは誰もが知っています。
オンラインではないシステムの場合、初期の SQL 監査と制御を通じて、SQL の問題の 80% が初期段階で排除されます。オンラインで実行されているシステムの場合は、潜在的なパフォーマンスの問題を発見して解決し、問題が発生する前に防止できます。 。
SQL 監査により、DBA はシステムの救急医からシステムの医療医に変身できます
1. DBA はアプリケーション コードの開発とテストのプロセスに参加します: 開発者に専門的なデータベース開発と最適化の提案を提供します
2. 事前最適化: アプリケーション コードをオンラインにする前に、ビジネス ニーズに応じて効率的な SQL とインデックスを設計します
3. 変更リスクの制御: アプリケーション開発中のテーブル構造の変更と SQL の変更が実行中のアプリケーションに与える影響を事前評価し、適切な変更期間と変更計画を決定します。

