

アリババの新しい mPLUG-Owl アップグレードは両方の長所を備えており、モーダル コラボレーションにより MLLM の新しい SOTA が可能になります

OpenAI GPT-4V と Google Gemini は、非常に強力なマルチモーダル理解機能を実証し、マルチモーダル大規模モデル (MLLM) の迅速な開発を促進し、MLLM は現在業界で最も注目されている研究の方向性。
MLLM は、さまざまな視覚言語オープンタスクにおいて優れた指示追従能力を実現します。マルチモーダル学習に関するこれまでの研究では、異なるモダリティが連携して相互に促進できることが示されていますが、既存の MLLM 研究は主に、マルチモーダル タスクの能力の向上と、モーダル コラボレーションの利点とモーダル干渉の影響のバランスをとる方法に焦点を当てています。それは対処する必要があります。

論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/pdf/2311.04257.pdf
-
次のコード アドレスを確認してください: https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl2
ModelScope エクスペリエンスアドレス: https://modelscope.cn/studios/damo/mPLUG-Owl2/summary
-
HuggingFace 体験アドレス リンク: https://huggingface.co/spaces/MAGAer13/mPLUG- Owl2
この問題に対応して、Alibaba のマルチモーダル大型モデル mPLUG-Owl がメジャー アップグレードされました。モーダルコラボレーションにより、プレーンテキストとマルチモーダリティのパフォーマンスを同時に向上させ、LLaVA1.5、MiniGPT4、Qwen-VLなどのモデルを上回り、さまざまなタスクで最高のパフォーマンスを実現します。具体的には、mPLUG-Owl2は、共有機能モジュールを利用して異なるモダリティ間の連携を促進し、各モダリティの特性を維持するためにモーダル適応モジュールを導入します。シンプルで効果的な設計により、mPLUG-Owl2 はプレーン テキストやマルチモーダル タスクなどの複数の分野で最高のパフォーマンスを実現します。モーダル コラボレーション現象の研究は、マルチモーダル大規模モデルの将来の開発にもインスピレーションを与えます
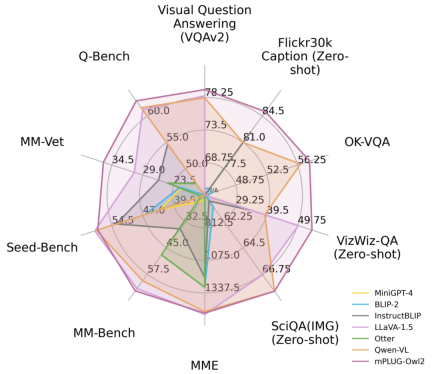
図 1 既存の MLLM モデルとのパフォーマンスの比較
メソッドの紹介 元の意味を変えないという目的を達成するには、内容を中国語に書き直す必要があります。
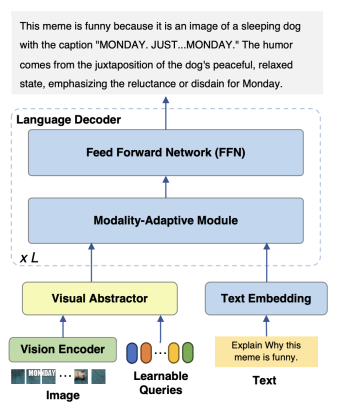
mPLUG-Owl2 モデルは主に 3 つの部分で構成されます。 ##Visual Encoder: ビジュアル エンコーダーとして、ViT-L/14 は、H x W の解像度を持つ入力画像を H/14 x W/14 のビジュアル トークンのシーケンスに変換し、Visual Abstractor に入力します。
- #Visual Extractor: 入力言語モデルのビジュアル シーケンスの長さを削減しながら、利用可能なクエリのセットを学習することで高レベルの意味論的特徴を抽出します
- 言語モデル: LLaMA-2-7B をテキスト デコーダとして使用し、図 3 に示すモーダル適応モジュールを設計します。
視覚的および言語モダリティの場合、既存の研究では通常、視覚的特徴をテキストの意味空間にマッピングしますが、このアプローチでは視覚情報とテキスト情報のそれぞれの特性が無視され、意味の粒度の不一致によりモデルのパフォーマンスに影響を与える可能性があります。この問題を解決するために、この論文では、視覚的特徴とテキスト的特徴を共有意味論的空間にマッピングすると同時に、視覚的言語表現を切り離して各モダリティの固有の特性を保持するモダリティ適応モジュール (MAM) を提案します。
#図 3 は、モーダル適応モジュールの概略図を示しています。
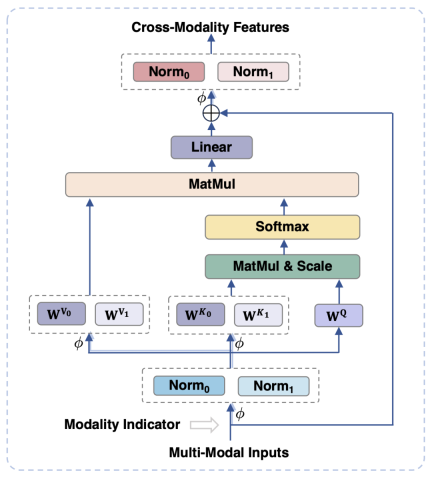
モジュールの入力ステージと出力ステージでは、LayerNorm 操作がそれぞれ視覚モダリティと言語モダリティに対して実行されます。 2 つのモードのそれぞれの特徴分布に適応します。
セルフアテンション操作では、ビジュアルモダリティと言語モダリティに別個のキー射影行列と値射影行列が使用されますが、キー射影と値射影を分離するために共有クエリ射影行列が使用されます。マトリックスは、意味論的な粒度が一致しない場合に 2 つのモダリティ間の干渉を回避できます。- 同じ FFN を共有することで、2 つのモダリティは相互のコラボレーションを促進できます
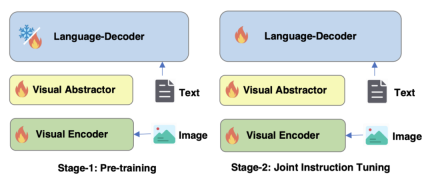
図 4 に示すように、mPLUG-Owl2 のトレーニングには、事前トレーニングと命令の微調整という 2 つの段階が含まれます。トレーニング前の段階では、主にビジュアル エンコーダーと言語モデルの調整を行います。この段階では、ビジュアル エンコーダーとビジュアル アブストラクターはトレーニング可能であり、言語モデルでは、モダリティによって追加されるビジュアル関連のモデルの重みのみが追加されます。アダプティブ モジュールが処理されます。命令の微調整ステージでは、モデルのすべてのパラメーターがテキストとマルチモーダル命令データ (図 5 に示す) に基づいて微調整され、モデルの命令追従能力が向上します。
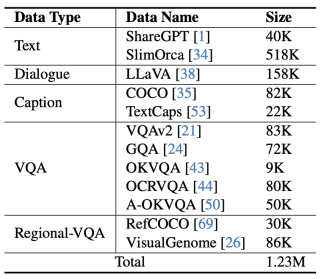
#図 5 mPLUG-Owl2 で使用される命令微調整データ
実験と結果
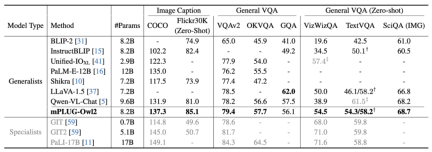
図 6 画像の説明と VQA タスクのパフォーマンス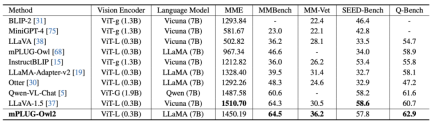
図 7 MLLM ベンチマークのパフォーマンス
図 6 と図 7 に示すように、従来の画像記述、VQA およびその他の視覚言語タスク、または MMBench、Q-ベンチなど マルチモーダル大規模モデルのベンチマーク データ セットにおいて、mPLUG-Owl2 は既存の研究よりも優れたパフォーマンスを達成しました。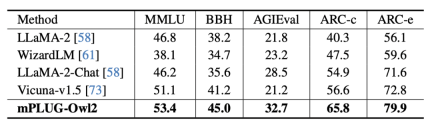
#図 8 プレーン テキストのベンチマーク パフォーマンス
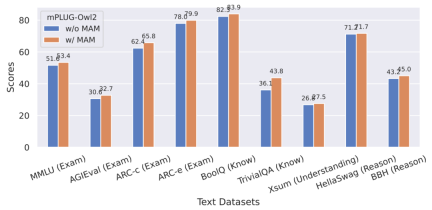
さらに、プレーン テキスト タスクに対するモーダル コラボレーションの影響を評価するために、著者は次のことも行いました。自然言語の理解と生成における mPLUG -Owl2 のパフォーマンスをテストしました。図 8 に示すように、mPLUG-Owl2 は、他の命令微調整 LLM と比較して優れたパフォーマンスを実現します。図 9 は、プレーン テキスト タスクのパフォーマンスを示しており、モーダル適応モジュールがモーダル コラボレーションを促進するため、モデルの検査能力と知識能力が大幅に向上していることがわかります。これは、マルチモーダル連携により、モデルが言語で説明するのが難しい概念を視覚情報を用いて理解できるようになり、画像内の豊富な情報によってモデルの推論能力が向上し、間接的にモデルの推論能力が強化されるためであると著者は分析している。テキスト。


以上がアリババの新しい mPLUG-Owl アップグレードは両方の長所を備えており、モーダル コラボレーションにより MLLM の新しい SOTA が可能になりますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PM
AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PMスタンフォード大学ヒト指向の人工知能研究所によってリリースされた2025年の人工知能インデックスレポートは、進行中の人工知能革命の良い概要を提供します。 4つの単純な概念で解釈しましょう:認知(何が起こっているのかを理解する)、感謝(利益を見る)、受け入れ(顔の課題)、責任(責任を見つける)。 認知:人工知能はどこにでもあり、急速に発展しています 私たちは、人工知能がどれほど速く発展し、広がっているかを強く認識する必要があります。人工知能システムは絶えず改善されており、数学と複雑な思考テストで優れた結果を達成しており、わずか1年前にこれらのテストで惨めに失敗しました。 2023年以来、複雑なコーディングの問題や大学院レベルの科学的問題を解決することを想像してみてください
 Meta Llama 3.2を始めましょう - 分析VidhyaApr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析VidhyaApr 11, 2025 pm 12:04 PMメタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5などApr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5などApr 11, 2025 pm 12:01 PM今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 マシンと話すための人的費用:チャットボットは本当に気にすることができますか?Apr 11, 2025 pm 12:00 PM
マシンと話すための人的費用:チャットボットは本当に気にすることができますか?Apr 11, 2025 pm 12:00 PMつながりの慰めの幻想:私たちはAIとの関係において本当に繁栄していますか? この質問は、MIT Media Labの「AI(AHA)で人間を進める」シンポジウムの楽観的なトーンに挑戦しました。イベントではCondedgを紹介している間
 PythonのScipy Libraryの理解Apr 11, 2025 am 11:57 AM
PythonのScipy Libraryの理解Apr 11, 2025 am 11:57 AM導入 あなたが科学者またはエンジニアで複雑な問題に取り組んでいると想像してください - 微分方程式、最適化の課題、またはフーリエ分析。 Pythonの使いやすさとグラフィックスの機能は魅力的ですが、これらのタスクは強力なツールを必要とします
 ラマ3.2を実行する3つの方法-Analytics VidhyaApr 11, 2025 am 11:56 AM
ラマ3.2を実行する3つの方法-Analytics VidhyaApr 11, 2025 am 11:56 AMメタのラマ3.2:マルチモーダルAIパワーハウス Metaの最新のマルチモーダルモデルであるLlama 3.2は、AIの大幅な進歩を表しており、言語理解の向上、精度の向上、および優れたテキスト生成機能を誇っています。 その能力t
 Dagsterでデータ品質チェックを自動化しますApr 11, 2025 am 11:44 AM
Dagsterでデータ品質チェックを自動化しますApr 11, 2025 am 11:44 AMデータ品質保証:ダグスターと大きな期待でチェックを自動化する データ駆動型のビジネスにとって、高いデータ品質を維持することが重要です。 データの量とソースが増加するにつれて、手動の品質管理は非効率的でエラーが発生しやすくなります。
 メインフレームはAI時代に役割を果たしていますか?Apr 11, 2025 am 11:42 AM
メインフレームはAI時代に役割を果たしていますか?Apr 11, 2025 am 11:42 AMMainFrames:AI革命のUnsung Heroes サーバーは汎用アプリケーションで優れており、複数のクライアントの処理を行いますが、メインフレームは大量のミッションクリティカルなタスク用に構築されています。 これらの強力なシステムは、頻繁にヘビルで見られます


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

