
ホームページ >テクノロジー周辺機器 >AI >Google DeepMind の調査では、敵対的攻撃が人間と AI の視覚認識に影響を与え、花瓶を猫と間違える可能性があることが判明しました。
Google DeepMind の調査では、敵対的攻撃が人間と AI の視覚認識に影響を与え、花瓶を猫と間違える可能性があることが判明しました。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-09 14:50:54556ブラウズ
人間のニューラル ネットワーク (脳) と人工ニューラル ネットワーク (ANN) の関係は何ですか?
ある先生は、これをこう例えました。ネズミとミッキーマウスの関係に似ています。
現実のニューラル ネットワークは強力ですが、人間が知覚、学習、理解する方法とはまったく異なります。
たとえば、ANN は人間の知覚では通常見られない脆弱性を示し、敵対的な摂動の影響を受けやすくなります。
画像では、数ピクセルの値を変更するか、ノイズ データを追加するだけで済みます。
から人間の視点、観察に違いはなく、画像分類ネットワークにとっては全く無関係なカテゴリとして認識されます。
しかし、Google DeepMind の最新の調査では、これまでの見解が間違っている可能性があることが示されています。
デジタル画像のわずかな変化でも、人間の知覚に影響を与える可能性があります。
言い換えれば、人間の判断は、そのような敵対的な摂動によって影響を受ける可能性もあります。

#論文アドレス: https://www.nature.com/articles/s41467-023-40499-0
Google DeepMind によるこの記事は、Nature Communications に掲載されました。
この論文では、制御された試験条件下で人間も同じ摂動に対して敏感性を示す可能性があるかどうかを調査しています。
研究者たちは一連の実験を通じてこれを証明しました。
同時に、これは人間の視覚と機械の視覚の類似点も示しています。
敵対的画像
敵対的画像とは、AI モデルが画像コンテンツを誤って分類する原因となる画像への微妙な変更です。 - このタイプ意図的な欺瞞を敵対的攻撃と呼びます。
たとえば、AI モデルに花瓶を猫、または花瓶以外のものとして分類させる攻撃がターゲットになる可能性があります。

上の図は、敵対的攻撃のプロセスを示しています (人間の観察の便宜上、中央のランダムな摂動は誇張されています)。
デジタル画像では、RGB 画像の各ピクセルは 0 ~ 255 (深さ 8 ビット) の値を持ち、その値は単一ピクセルの強度を表します。
敵対的攻撃の場合、狭い範囲でピクセル値を変更することで攻撃効果が得られる場合があります。
現実の世界では、一時停止標識を速度制限標識と誤認識させるなど、物理的オブジェクトに対する敵対的攻撃も成功する可能性があります。
そのため、セキュリティ上の理由から、研究者たちはすでに敵対的な攻撃を防御し、リスクを軽減する方法に取り組んでいます。
人間の知覚に対する敵対的な影響
これまでの研究では、人は明確な形状の手がかりを提供する大きな振幅の画像の摂動に敏感である可能性があることが示されています。
しかし、より微妙な敵対的攻撃は人間にどのような影響を与えるのでしょうか?人は画像内の摂動を無害なランダムな画像ノイズとして認識しますか?また、それは人間の知覚に影響を与えますか?
これを解明するために、研究者たちは制御された行動実験を実施しました。
まず、一連の生の画像が取得され、各画像に対して 2 つの敵対的攻撃が実行され、複数のペアの摂動画像が生成されます。
以下のアニメーションの例では、元の画像はモデルによって「花瓶」として分類されています。
敵対的攻撃により、モデルは 2 つの乱れた画像を高い確信度で「猫」と「トラック」として誤分類しました。

次に、人間の参加者に 2 つの画像を見せて、的を絞った質問をしました: どちらの画像がより猫に似ていますか? ?
どちらの写真も猫には見えませんでしたが、選択を迫られました。
多くの場合、被験者は自分がランダムな選択をしたと信じていますが、本当にそうなのでしょうか?
脳が微妙な敵対的攻撃に鈍感であれば、被験者は 50% の確率でそれぞれの写真を選択するでしょう。
ただし、実験によると、選択率 (つまり、人間の知覚バイアス) は実際には偶然 (50%) よりも高く、実際には画像ピクセルの調整は非常に小さいことがわかりました。 。
参加者の観点からは、2 つのほぼ同一の画像を区別するように求められているように感じます。しかし、これまでの研究では、自信や認識を伝えるには信号が弱すぎるにもかかわらず、人は選択をするときに弱い知覚信号を使用することが示されています。
この例では、花瓶が見えるかもしれませんが、脳内の何らかの活動により、そこには猫の影があることがわかります。
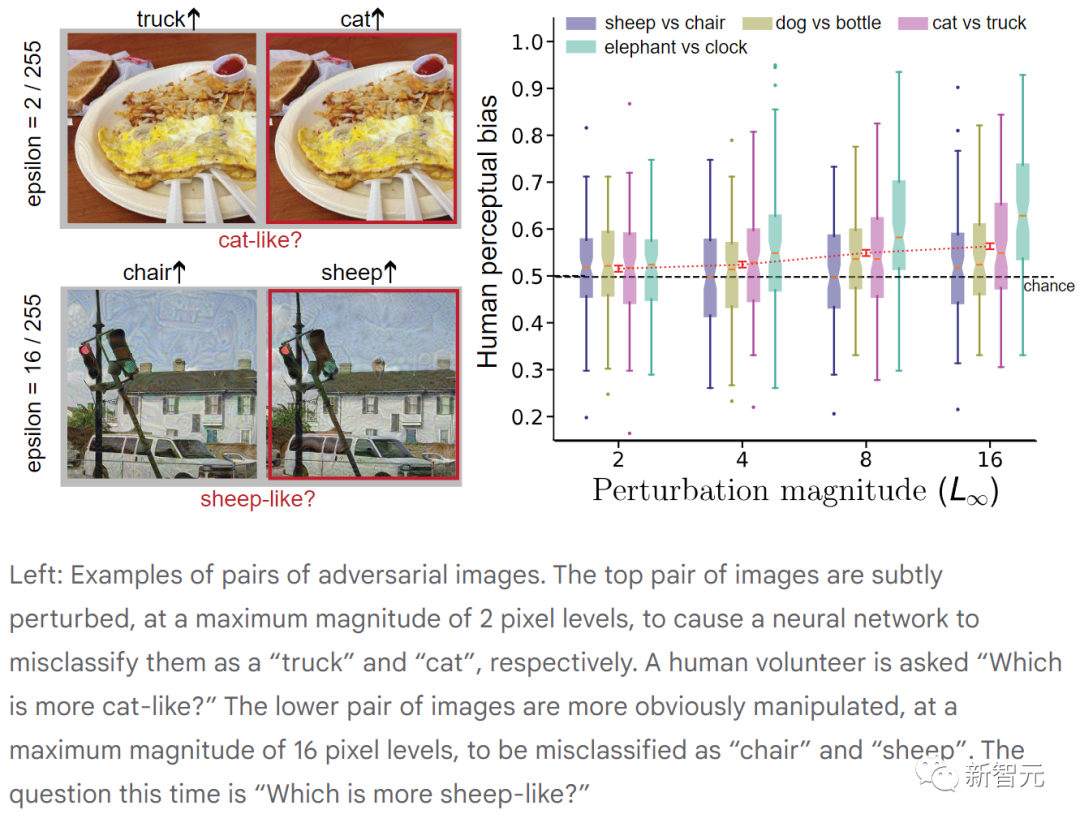
#上の図は、敵対的な画像のペアを示しています。上の画像のペアは最大振幅 2 ピクセルで微妙に摂動されており、ニューラル ネットワークがそれらをそれぞれ「トラック」と「猫」として誤分類します。 (ボランティアには「どちらがより猫に似ていますか?」と尋ねられました。)
下の画像ペアの乱れはより明白で、最大振幅は 16 ピクセルですが、これは誤っていました。ニューラルネットワークにより「椅子」と「羊」に分類されます。 (今回の質問は「どちらが羊に似ていますか?」)
各実験において、参加者は半分以上の確率で対象の質問に対する答えを確実に選択しました。 。人間の視覚は機械の視覚ほど敵対的な摂動の影響を受けにくいものの、これらの摂動は依然として人間に機械による決定を支持するバイアスを与える可能性があります。
人間の知覚が敵対的な画像によって影響を受ける可能性がある場合、これは新たな、しかし重大なセキュリティ問題となります。
これには、人工知能の視覚システムの動作と人間の知覚の類似点と相違点を調査し、より安全な人工知能システムを構築するための徹底的な研究が必要です。
論文の詳細
敵対的摂動を生成するための標準手順は、RGB 画像を確率分布にマッピングする事前トレーニング済み ANN 分類器から始まります。固定されたクラスのセット。
画像に変更を加えると (特定のピクセルの赤色の強度を高めるなど)、出力確率分布にわずかな変化が生じます。
敵対的な画像が検索され (勾配降下法)、ANN が正しいクラスに割り当てられる確率を下げる原因となる元の画像の摂動が取得されます (非標的型攻撃)。高い確率を割り当てる 特定の指定された代替カテゴリ (標的型攻撃) を与えます。
摂動が元の画像から大きく逸脱しないようにするために、敵対的機械学習の文献では L (∞) ノルム制約がよく適用され、ピクセルが逸脱できないことを指定します。元の値から ±ε を超えて大きくなる場合、ε は通常、[0 ~ 255] ピクセルの強度範囲よりもはるかに小さくなります。
この制約は、各 RGB カラー プレーンのピクセルに適用されます。この制限によって個人が画像の変化を検出することは妨げられませんが、ε を適切に選択することで、元の画像カテゴリを示す主信号は摂動画像内でほとんどそのまま残ります。
実験
元の実験では、著者らは、短く隠された敵対的な画像に対する人間の反応を研究しました。 。
曝露時間を制限して分類誤差を増やすことにより、この実験は、そうでなければ分類の決定に影響を及ぼさないかもしれない刺激の側面に対する個人の感受性を高めるように設計されました。
敵対的摂動が実際のクラス T の画像に対して実行されます。摂動を最適化することにより、ANN は画像を A として誤分類する傾向があります。参加者は、T と A のどちらかを強制的に選択するように求められました。
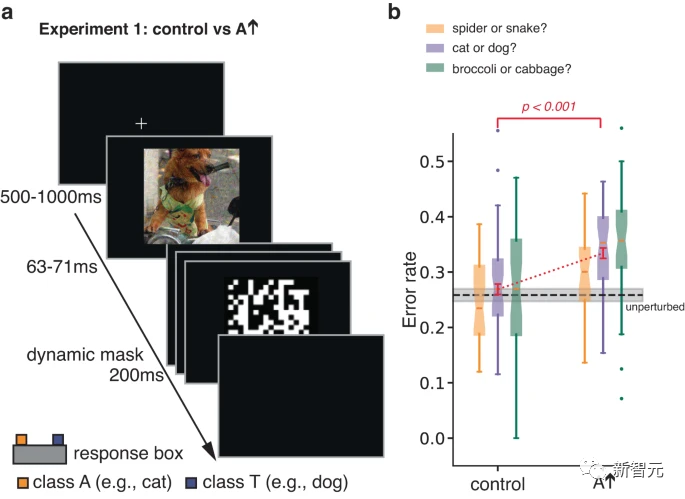
研究者らはまた、条件 A で上下を反転して取得したコントロール画像について参加者をテストしました。
この単純な変換は、敵対的摂動と画像の間のピクセル間の対応を壊し、摂動の仕様とその他の統計データを保持しながら、ANN に対する敵対的摂動の影響を大幅に排除します。
その結果、参加者は対照画像と比較して、摂動画像をカテゴリー A と判断する可能性が高いことがわかりました。
上記の実験 1 では、簡単なマスキング デモンストレーションを使用して、元の画像カテゴリ (主信号) の応答への影響を制限し、それによって敵対的な摂動 (従属信号) に対する感度を明らかにしました。
研究者らは、同じ目的を持った他の 3 つの実験も計画しましたが、大規模な摂動や限られた露出での観察の必要性は避けられました。
これらの実験では、画像内の主要な信号が応答の選択を体系的に誘導しないため、従属的な信号の影響が現れます。
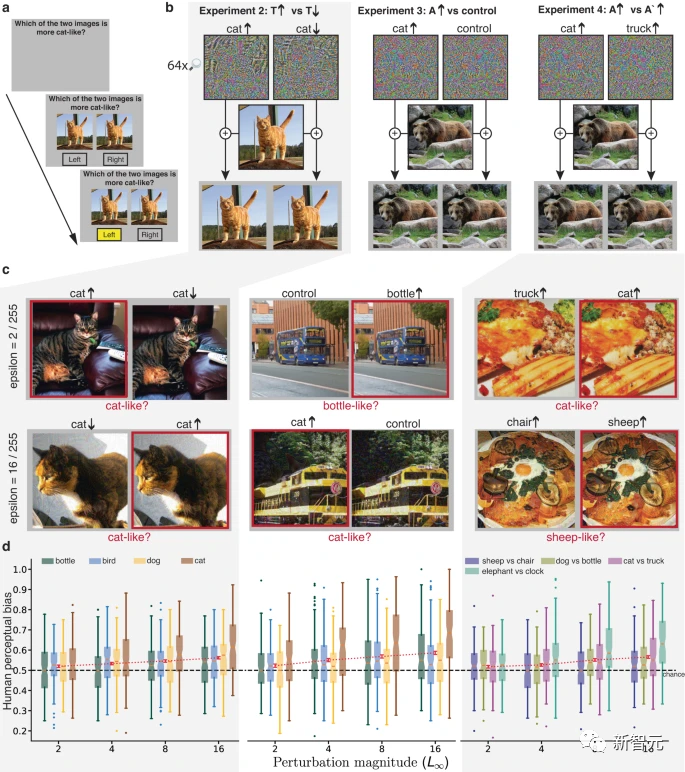
各実験では、マスクされていない刺激のほぼ同一のペアが提示され、応答が選択されるまで表示されたままになりました。刺激のペアは同じドミナント信号を持ち、どちらも同じ基礎となる画像の変調ですが、異なるスレーブ信号を持ちます。参加者は、対象カテゴリのインスタンスによりよく似た画像を選択するように求められました。
実験 2 では、両方の刺激が T カテゴリに属する画像でした。そのうちの 1 つは摂動され、ANN はそれが T カテゴリに近いと予測しました。もう 1 つは摂動され、は、T カテゴリにさえ属さないと予測されました。
実験 3 では、刺激は実際のカテゴリ T に属する画像であり、そのうちの 1 つが摂動されて ANN の分類が変更され、ターゲットの敵対的なカテゴリ A に近づきます。 、もう 1 つは同じ摂動を使用しますが、制御条件として左右を反転しました。
このコントロールの効果は、摂動のノルムとその他の統計を保存することですが、画像の左側と右側が異なるため、実験 1 のコントロールよりも保守的です。画像の上部と下部よりも多くの特徴があり、より類似した統計がある可能性があります。
実験 4 の画像のペアも実際のカテゴリ T の変調であり、1 つはカテゴリ A に近くなるように摂動され、もう 1 つはカテゴリ 3 に近くなります。試験では、参加者にカテゴリー A に近い画像を選択するか、カテゴリー 3 に近い画像を選択するかを交互に依頼しました。
実験 2 ~ 4 では、各画像の人間の知覚バイアスは、ANN のバイアスと有意に正の相関がありました。摂動の振幅の範囲は 2 ~ 16 で、人間の参加者を対象に以前に研究された摂動よりも小さく、敵対的な機械学習の研究で使用される摂動と同様です。
驚くべきことに、たとえ 2 ピクセルの強度レベルの摂動でも、人間の知覚に確実に影響を与えるには十分です。
実験 2 の強みは、参加者が直感的に判断する必要があることです (例: 動揺した 2 つの猫の画像のどちらがより猫に似ているか) ;
ただし、実験 2 では、画像をシャープにしたりぼかしたりするだけで、敵対的な摂動によって画像を多かれ少なかれ猫っぽくすることができます。
実験 3 の利点は、摂動の最大振幅だけでなく、比較された摂動のすべての統計が一致することです。
ただし、摂動統計を一致させても、画像に摂動を追加したときにその摂動が同等に知覚できるとは限りません。そのため、参加者は画像の歪みに基づいて選択を行う可能性があります。
実験 4 の強みは、同じ画像ペアが質問に応じて系統的に異なる反応を生成するため、参加者が質問に敏感であることを示していることです。
しかし、実験 4 では、参加者に一見不条理な質問 (例: 2 つのオムレツの画像のどちらがより猫に似ていますか?) に答えるように依頼し、質問の解釈の仕方のばらつきを引き起こしました。
まとめると、実験 2 ~ 4 は、無制限の視聴時間による非常に小さな摂動でさえ AI ネットワークに強い影響を与える可能性があることを示す収束した証拠を提供します。下位の対立信号は人間の知覚と判断にも影響を与えます同じ方向に。
さらに、敵対的な摂動が実際の結果をもたらすには、観察時間 (自然に知覚される環境) を延長することが重要です。
以上がGoogle DeepMind の調査では、敵対的攻撃が人間と AI の視覚認識に影響を与え、花瓶を猫と間違える可能性があることが判明しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。