
 テクノロジー周辺機器AIMeituan、浙江大学などが協力して、リアルタイムで実行でき、Snapdragon 888 プロセッサを使用するフルプロセスのモバイル マルチモーダル大型モデル MobileVLM を開発しました。
テクノロジー周辺機器AIMeituan、浙江大学などが協力して、リアルタイムで実行でき、Snapdragon 888 プロセッサを使用するフルプロセスのモバイル マルチモーダル大型モデル MobileVLM を開発しました。Meituan、浙江大学などが協力して、リアルタイムで実行でき、Snapdragon 888 プロセッサを使用するフルプロセスのモバイル マルチモーダル大型モデル MobileVLM を開発しました。

モバイル端末に大型モデルがやってくる波はますます強くなり、ついに誰かがマルチモーダルな大型モデルをモバイル端末に移しました。最近、美団、浙江大学などが、LLMベーストレーニング、SFT、VLMのプロセス全体を含む、モバイル端末上に展開できるマルチモーダル大規模モデルを発表しました。おそらく近い将来、誰もが自分の大型モデルを便利に、早く、低コストで所有できるようになるでしょう。

- ##論文アドレス: https://arxiv.org/pdf/2312.16886.pdf #コード アドレス: https://github.com/Meituan- AutoML /MobileVLM
大規模マルチモダリティ モデル(LMM)、特に視覚言語モデル (VLM) ファミリーは、知覚と推論の能力が大幅に強化されているため、ユニバーサル アシスタントを構築するための有望な研究方向となっています。ただし、事前トレーニングされた大規模言語モデル (LLM) とビジュアル モデルの表現をどのように接続し、クロスモーダル特徴を抽出し、視覚的な質問応答、画像字幕、視覚的な知識推論、対話などのタスクを完了する方法は常に問題でした。 。
このタスクにおける GPT-4V と Gemini の優れたパフォーマンスは、何度も証明されています。ただし、これらの独自モデルの技術的な実装の詳細はまだ十分に理解されていません。同時に、研究コミュニティは一連の言語調整方法も提案しています。たとえば、Flamingo はビジュアル トークンを活用して、ゲートされたクロス アテンション レイヤーを通じて凍結された言語モデルを条件付けします。 BLIP-2 は、この対話は不十分であると考え、フリーズされたビジュアル エンコーダから最も有用な機能を抽出し、フリーズされた LLM に直接フィードする軽量のクエリ トランスフォーマ (Q-Former と呼ばれる) を導入します。 MiniGPT-4 は、BLIP-2 のフリーズされたビジュアル エンコーダーと、プロジェクション レイヤーを介してフリーズされた言語モデル Vicuna を組み合わせます。さらに、LLaVA は、単純なトレーニング可能なマッピング ネットワークを適用して、視覚的特徴を、言語モデルによって処理される単語埋め込みと同じ次元の埋め込みトークンに変換します。
大規模なマルチモーダル データの多様性に適応するために、トレーニング戦略が徐々に変化していることは注目に値します。 LLaVA は、LLM の命令調整パラダイムをマルチモーダル シナリオに再現する最初の試みとなる可能性があります。マルチモーダル命令トレースデータを生成するために、LLaVA は画像の説明文や画像のバウンディングボックス座標などのテキスト情報を純粋言語モデル GPT-4 に入力します。 MiniGPT-4 は、まず画像説明文の包括的なデータセットでトレーニングされ、次に [画像とテキスト] のペアのキャリブレーション データセットで微調整されます。 InstructBLIP は、事前トレーニングされた BLIP-2 モデルに基づいてビジュアル言語コマンド チューニングを実行し、Q-Former はコマンド チューニング形式で編成されたさまざまなデータセットでトレーニングされます。 mPLUG-Owl は 2 段階のトレーニング戦略を導入しています。まず視覚部分を事前トレーニングし、次に LoRA を使用して、さまざまなソースからの命令データに基づいて大規模言語モデル LLaMA を微調整します。
#VLM における上記の進歩にもかかわらず、コンピューティング リソースが限られている場合には、依然としてクロスモーダル機能を使用する必要があります。 Gemini は、さまざまなマルチモーダル ベンチマークで sota を上回り、低メモリ デバイス向けに 1.8B および 3.25B パラメータを備えたモバイル グレードの VLM を導入しています。また、Gemini は蒸留や量子化などの一般的な圧縮技術も使用します。このペーパーの目標は、公開データセットと視覚認識と推論のための利用可能なテクノロジーを使用してトレーニングされ、リソースに制約のあるプラットフォーム向けに調整された、初のオープンなモバイル グレード VLM を構築することです。この記事の貢献は次のとおりです。
- この記事では、マルチモーダル視覚言語モデルのフルスタック変換である MobileVLM を提案します。モバイルシナリオ向けにカスタマイズされています。著者らによると、これは詳細で再現可能で強力なパフォーマンスをゼロから提供する初めてのビジュアル言語モデルだという。研究者たちは、管理されたオープンソースのデータセットを通じて、一連の高性能の基本言語モデルとマルチモーダルモデルを確立しました。
- この論文では、ビジュアル エンコーダーの設計に関して広範なアブレーション実験を実施し、さまざまなトレーニング パラダイム、入力解像度、モデル サイズに対する VLM のパフォーマンス感度を体系的に評価します。
- この論文では、視覚的特徴とテキスト特徴の間の効率的なマッピング ネットワークを設計します。これにより、推論の消費を削減しながら、マルチモーダルな特徴をより適切に調整できます。
- この記事で設計されたモデルは、Qualcomm のモバイル CPU と 65.5 インチ プロセッサで測定された速度 21.5 トークン/秒で、低電力モバイル デバイス上で効率的に実行できます。
- MobileVLM は、ベンチマークで多数のマルチモーダル大規模モデルと同等のパフォーマンスを示し、多くの実際的なタスクでのアプリケーションの可能性を証明しています。この記事はエッジ シナリオに焦点を当てていますが、MobileVLM は、クラウド内の強力な GPU でのみサポートできる多くの最先端の VLM よりも優れたパフォーマンスを発揮します。
MobileVLM
全体的なアーキテクチャ設計
 を入力として受け取ると、ビジュアル エンコーダ F_enc は画像認識のための視覚的埋め込み
を入力として受け取ると、ビジュアル エンコーダ F_enc は画像認識のための視覚的埋め込み  を抽出します。ここで、N_v = HW/P^2 は画像ブロックの数を表し、D_v は画像ブロックの隠れ層サイズを表します。視覚的な埋め込み。画像トークン処理の効率の問題を軽減するために、研究者らは、視覚特徴圧縮と視覚テキストモーダル整列のための軽量マッピングネットワーク P を設計しました。次のように、 f を単語埋め込み空間に変換し、後続の言語モデルに適切な入力次元を提供します:
を抽出します。ここで、N_v = HW/P^2 は画像ブロックの数を表し、D_v は画像ブロックの隠れ層サイズを表します。視覚的な埋め込み。画像トークン処理の効率の問題を軽減するために、研究者らは、視覚特徴圧縮と視覚テキストモーダル整列のための軽量マッピングネットワーク P を設計しました。次のように、 f を単語埋め込み空間に変換し、後続の言語モデルに適切な入力次元を提供します: 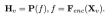
 。N_t はテキスト トークンの数を表し、D_t は単語埋め込みスペースのサイズを表します。現在の MLLM 設計パラダイムでは、LLM の計算量とメモリ消費量が最も大きくなります。これを考慮して、この記事では、速度の点でかなりの利点があり、自己回帰手法を実行できる、推論に適した一連の LLM をモバイル アプリケーション向けに調整します。マルチモーダル入力
。N_t はテキスト トークンの数を表し、D_t は単語埋め込みスペースのサイズを表します。現在の MLLM 設計パラダイムでは、LLM の計算量とメモリ消費量が最も大きくなります。これを考慮して、この記事では、速度の点でかなりの利点があり、自己回帰手法を実行できる、推論に適した一連の LLM をモバイル アプリケーション向けに調整します。マルチモーダル入力 、L は出力トークンの長さを表します。このプロセスは
、L は出力トークンの長さを表します。このプロセスは  で表すことができます。
で表すことができます。 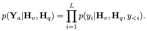
- RoPE を適用して位置情報を挿入します。
- 事前正規化を適用してトレーニングを安定させます。具体的には、この論文ではレイヤー正規化の代わりに RMSNorm を使用し、MLP 拡張率には 4 ではなく 8/3 を使用します。
- GELU の代わりに SwiGLU アクティベーション関数を使用します。

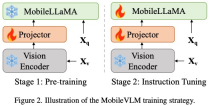
 を入力として受け取り、効率的に抽出され位置合わせされたビジュアル トークン
を入力として受け取り、効率的に抽出され位置合わせされたビジュアル トークン  を出力します。
を出力します。 


これはこの論文では、GQA、ScienceQA、TextVQA、POPE、および MME における LLaVA のマルチモーダル パフォーマンスを評価しています。また、本稿ではMMBenchを用いた総合比較も行っています。表 4 に示すように、MobileVLM は、パラメーターが削減され、トレーニング データが限られているにもかかわらず、競争力のあるパフォーマンスを達成します。場合によっては、そのメトリックは、以前の最先端のマルチモーダル視覚言語モデルよりも優れたパフォーマンスを発揮することさえあります。
##ビジュアル バックボーン ネットワーク
#VL マッピング ネットワーク
ビジュアル解像度とトークン数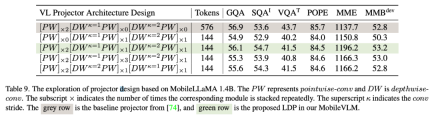

以上がMeituan、浙江大学などが協力して、リアルタイムで実行でき、Snapdragon 888 プロセッサを使用するフルプロセスのモバイル マルチモーダル大型モデル MobileVLM を開発しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 ほとんどが使用されています10 Power BIチャート - 分析VidhyaApr 16, 2025 pm 12:05 PM
ほとんどが使用されています10 Power BIチャート - 分析VidhyaApr 16, 2025 pm 12:05 PMMicrosoft PowerBIチャートでデータ視覚化の力を活用する 今日のデータ駆動型の世界では、複雑な情報を非技術的な視聴者に効果的に伝えることが重要です。 データの視覚化は、このギャップを橋渡しし、生データを変換するi
 AIのエキスパートシステムApr 16, 2025 pm 12:00 PM
AIのエキスパートシステムApr 16, 2025 pm 12:00 PMエキスパートシステム:AIの意思決定力に深く飛び込みます 医療診断から財務計画まで、あらゆることに関する専門家のアドバイスにアクセスできることを想像してください。 それが人工知能の専門家システムの力です。 これらのシステムはプロを模倣します
 3人の最高の雰囲気コーダーがこのAI革命をコードで分解するApr 16, 2025 am 11:58 AM
3人の最高の雰囲気コーダーがこのAI革命をコードで分解するApr 16, 2025 am 11:58 AMまず第一に、これがすぐに起こっていることは明らかです。さまざまな企業が、現在AIによって書かれているコードの割合について話しており、これらは迅速なクリップで増加しています。すでに多くの仕事の移動があります
 滑走路AIのGen-4:AIモンタージュはどのように不条理を超えることができますかApr 16, 2025 am 11:45 AM
滑走路AIのGen-4:AIモンタージュはどのように不条理を超えることができますかApr 16, 2025 am 11:45 AM映画業界は、デジタルマーケティングからソーシャルメディアまで、すべてのクリエイティブセクターとともに、技術的な岐路に立っています。人工知能が視覚的なストーリーテリングのあらゆる側面を再構築し始め、エンターテイメントの風景を変え始めたとき
 5日間のISRO AI無料コースを登録する方法は? - 分析VidhyaApr 16, 2025 am 11:43 AM
5日間のISRO AI無料コースを登録する方法は? - 分析VidhyaApr 16, 2025 am 11:43 AMISROの無料AI/MLオンラインコース:地理空間技術の革新へのゲートウェイ インド宇宙研究機関(ISRO)は、インドのリモートセンシング研究所(IIRS)を通じて、学生と専門家に素晴らしい機会を提供しています。
 AIのローカル検索アルゴリズムApr 16, 2025 am 11:40 AM
AIのローカル検索アルゴリズムApr 16, 2025 am 11:40 AMローカル検索アルゴリズム:包括的なガイド 大規模なイベントを計画するには、効率的なワークロード分布が必要です。 従来のアプローチが失敗すると、ローカル検索アルゴリズムは強力なソリューションを提供します。 この記事では、Hill ClimbingとSimulについて説明します
 OpenaiはGPT-4.1でフォーカスをシフトし、コーディングとコスト効率を優先しますApr 16, 2025 am 11:37 AM
OpenaiはGPT-4.1でフォーカスをシフトし、コーディングとコスト効率を優先しますApr 16, 2025 am 11:37 AMこのリリースには、GPT-4.1、GPT-4.1 MINI、およびGPT-4.1 NANOの3つの異なるモデルが含まれており、大規模な言語モデルのランドスケープ内のタスク固有の最適化への動きを示しています。これらのモデルは、ようなユーザー向けインターフェイスをすぐに置き換えません
 プロンプト:ChatGptは偽のパスポートを生成しますApr 16, 2025 am 11:35 AM
プロンプト:ChatGptは偽のパスポートを生成しますApr 16, 2025 am 11:35 AMChip Giant Nvidiaは、月曜日に、AI Supercomputersの製造を開始すると述べました。これは、大量のデータを処理して複雑なアルゴリズムを実行できるマシンを初めて初めて米国内で実行します。発表は、トランプSI大統領の後に行われます


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

WebStorm Mac版
便利なJavaScript開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

