
ホームページ >テクノロジー周辺機器 >AI >大規模機械学習における幻覚軽減技術の包括的な研究
大規模機械学習における幻覚軽減技術の包括的な研究

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-05 16:54:111465ブラウズ
大規模言語モデル (LLM) は、大量のパラメーターとデータを含むディープ ニューラル ネットワークであり、テキストの理解や生成など、自然言語処理 (NLP) の分野でさまざまなタスクを実行できます。近年、計算能力とデータ規模の向上に伴い、GPT-4、BART、T5などLLMは目覚ましい発展を遂げ、強力な汎化能力と創造性を発揮しています。
LLM にも深刻な問題があり、テキストを生成するときに、実際の事実やユーザー入力と矛盾するコンテンツ (幻覚) が生成されやすくなります。この現象は、システムのパフォーマンスを低下させるだけでなく、ユーザーの期待や信頼に影響を与え、さらにはセキュリティや倫理上のリスクを引き起こす可能性があります。したがって、LLM の幻覚をどのように検出して軽減するかが、現在の NLP 分野において重要かつ緊急のテーマとなっています。
1月1日、SM Towhidul Islam、バングラデシュのイスラム科学技術大学、米国のサウスカロライナ大学人工知能研究所、スタンフォード大学の科学者数名米国のアマゾン人工知能局、トンモイ氏、SM メヘディ・ザマン氏、ヴィニヤ・ジェイン氏、アンク・ラニ氏、ヴィプラ・ロウテ氏、アマン・チャダ氏、アミタヴァ・ダス氏は「大規模言語による幻覚軽減技術の包括的調査」というタイトルの論文を発表した。モデル」は、大規模言語モデル (LLM) の導入と分類を目的としています。) 幻覚軽減技術。

彼らはまず、幻覚の定義、原因と影響、およびその評価方法を紹介しました。次に彼らは、幻覚軽減技術をデータセットベース、タスクベース、フィードバックベース、検索ベースの 4 つの主要なカテゴリに分類する詳細な分類システムを提案しています。各カテゴリ内で、さまざまなサブカテゴリがさらに細分化され、いくつかの代表的な方法が示されています。
著者らは、これらのテクノロジーの長所と短所、課題と限界、および将来の研究の方向性も分析しています。彼らは、現在の技術には汎用性、解釈可能性、拡張性、堅牢性の欠如など、依然としていくつかの問題があると指摘しました。彼らは、将来の研究は次の側面に焦点を当てる必要があると示唆しました:より効果的な幻覚検出および定量化方法の開発、マルチモーダル情報と常識知識の活用、より柔軟でカスタマイズ可能な幻覚軽減フレームワークの設計、人間の参加とフィードバックの考慮。
1. LLM における幻覚の分類システム
LLM における幻覚の問題をよりよく理解し、説明するために、彼らは幻覚を提案しました。ベース ソース、タイプ、範囲、影響の分類システムを図 1 に示します。彼らは、このシステムが LLM の幻覚のあらゆる側面をカバーし、幻覚の原因と特徴を分析し、幻覚の重症度と害を評価するのに役立つと考えています。
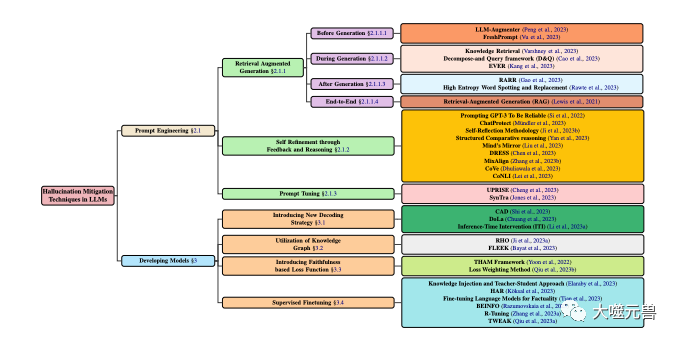 図 1
図 1
LLM における幻覚軽減手法の分類。モデル開発とプロンプト手法を伴う一般的な手法に焦点を当てています。モデル開発は、新しいデコード戦略、ナレッジ グラフ ベースの最適化、新しい損失関数コンポーネントの追加、教師あり微調整などのさまざまな方法に分かれています。一方、キュー エンジニアリングには、検索強化ベースの方法、フィードバック ベースの戦略、またはキュー調整が含まれる場合があります。
幻覚の原因
幻覚の原因は、LLM における幻覚の根本原因であり、次の 3 つのカテゴリに要約できます。
パラメトリック知識: 文法、意味論、常識など、トレーニング前の段階で大規模なラベルのないテキストから LLM によって学習される暗黙的な知識。この知識は通常、LLM のパラメータに保存され、アクティベーション関数やアテンション メカニズムを通じて呼び出すことができます。パラメトリック知識は LLM の基礎ですが、不正確、古い、または偏った情報が含まれていたり、ユーザーが入力した情報と矛盾したりする可能性があるため、幻想の原因となる可能性もあります。
ノンパラメトリック知識: 事実、証拠、参照など、LLM が微調整または生成フェーズ中に外部の注釈付きデータから取得する明示的な知識。この知識は通常、構造化または非構造化形式で存在し、検索または記憶メカニズムを通じてアクセスできます。ノンパラメトリック知識は LLM を補完しますが、ノイズ、誤ったデータまたは不完全なデータが含まれていたり、LLM のパラメトリック知識と矛盾したりする可能性があるため、錯覚の原因になる可能性もあります。
生成戦略: デコード アルゴリズム、制御コード、プロンプトなど、テキストを生成するときに LLM によって使用されるいくつかのテクノロジまたはメソッドを指します。これらの戦略は LLM のツールですが、LLM が特定の知識に過度に依存したり無視したり、生成プロセスにバイアスやノイズを導入したりする可能性があるため、幻想の原因にもなりえます。
幻覚の種類
幻覚の種類とは、LLM によって生成される幻覚の特定の症状を指し、次の 4 つのカテゴリに分類できます:
文法的幻覚: LLM によって生成された、スペルミス、句読点の誤り、語順の誤り、時制の誤り、主語と動詞の不一致などの文法上の誤りまたは不規則性を含むテキストを指します。この錯覚は通常、LLM の言語ルールの不完全な把握、またはノイズの多いデータへの過剰適合によって引き起こされます。
意味的幻覚 (意味的幻覚): 単語の意味の誤り、参照の誤り、論理的誤り、あいまいさ、矛盾など、LLM によって生成されたテキストの意味上の誤りまたは不合理性を指します。 。この錯覚は、LLM の言語の意味の理解が不十分であること、または複雑なデータの処理が不十分であることが原因で発生することがよくあります。
知識幻覚 (知識幻覚): 事実上の誤り、証拠の誤り、引用の誤り、入力または文脈との不一致など、知識の誤りまたは不一致を含む LLM によって生成されたテキストを指します。 、など。この錯覚は通常、LLM の誤った取得または知識の不適切な使用によって引き起こされます。
創造的幻覚 (創造的幻覚): スタイル エラー、感情的エラー、間違った視点、タスクや目標との非互換性など、創造的エラーまたは不適切な点がある LLM によって生成されたテキストを指します。等。この錯覚は、LLM による作成に対する不当な制御や不適切な評価によって引き起こされることがよくあります。
幻覚の程度
幻覚の程度とは、LLM によって生成される幻覚の量と質を指し、次のように分類できます。 3 つのカテゴリ:
軽度の幻覚: 幻覚は軽減され軽くなり、テキスト全体の読みやすさや理解しやすさに影響を与えたり、テキストの主なメッセージや目的を損なったりすることはありません。たとえば、LLM は、軽微な文法上の誤り、意味上の曖昧さ、詳細な知識の誤り、または創造的な微妙な違いを生成します。
中等度の幻覚: 多くの重度の幻覚があり、テキストの読みやすさと理解の一部に影響を与え、テキストの二次情報と目的も損ないます。通常、LLM は大きな文法上の誤りや意味上の不合理を生成します。
重度の幻覚 (重度の幻覚): 幻覚は非常に多く、非常に重く、テキスト全体の読みやすさと理解しやすさに影響を与え、テキストの主なメッセージと目的も破壊します。
幻覚の影響
幻覚の影響とは、LLM がユーザーとシステムに幻覚を生成する潜在的な影響を指します。これは次のように分類できます。
無害な幻覚: ユーザーやシステムにマイナスの影響を与えることはなく、楽しさ、創造性、多様性の増加など、プラスの影響を与える可能性もあります。 、など。たとえば、LLM は、タスクや目標に関連しないコンテンツ、ユーザーの好みや期待と一致するコンテンツ、ユーザーの気分や態度と一致するコンテンツ、またはユーザーの目的に役立つコンテンツを生成します。ユーザーのコミュニケーションまたはインタラクションのコンテンツ。
有害な幻覚: 効率、精度、信頼性、満足度などの低下など、ユーザーとシステムに悪影響を及ぼします。たとえば、LLM は、タスクや目標と一致しないコンテンツ、ユーザーの好みや期待と一致しないコンテンツ、ユーザーの気分や態度と一致しないコンテンツ、またはユーザーのコミュニケーションを妨げるコンテンツを生成します。またはインタラクション、コンテンツ。
危険な幻覚: 誤解、対立、論争、傷害などを引き起こすなど、ユーザーとシステムに重大な悪影響を及ぼします。たとえば、LLM は、事実や証拠に反するコンテンツ、道徳や法律に反するコンテンツ、人権や尊厳に反するコンテンツ、あるいは安全や健康を脅かすコンテンツを生成します。
2. LLM における幻覚の原因の分析
LLM における幻覚の問題をよりよく解決するには、次のことを行う必要があります。幻覚の原因の詳細な分析。前述の幻覚の情報源に基づいて、著者は幻覚の原因を次の 3 つのカテゴリに分類します。 パラメータ知識の不足または過剰: トレーニング前の段階で、LLM は通常、大量のラベルなしテキストを使用して言語ルールと知識を学習し、それによってパラメータ知識を形成します。ただし、この種の知識には、不完全、不正確、更新されていない、一貫性がない、無関係など、いくつかの問題が発生する可能性があり、その結果、LLM がテキストを生成するときに入力情報を完全に理解して利用できなかったり、テキストを正しく生成できなかったりすることがあります。出力される情報を区別して選択することで幻覚を引き起こす。一方で、パラメータの知識が豊富または強力すぎる場合もあり、LLM がテキストを生成するときに自分の知識に過度に依存したり優先したりする一方で、入力情報を無視したり矛盾したりして、幻覚を引き起こすことがあります。 ノンパラメトリック知識の欠如またはエラー: 微調整または生成フェーズでは、LLM は通常、言語知識を取得または補足するために外部の注釈付きデータを使用し、それによってノンパラメトリック知識を形成します。 。この種の知識には、不足、ノイズ、エラー、不完全さ、矛盾、無関係などのいくつかの問題が発生する可能性があり、その結果、LLM がテキストを生成するときに入力情報を効果的に取得して融合したり、入力情報を正確に検証して修正したりすることができなくなります。情報を出力し、それによって幻覚を引き起こします。また、ノンパラメトリックな知識は複雑または多様すぎるため、LLM がテキストを生成するときにさまざまな情報ソースのバランスを取り調整したり、さまざまなタスク要件を適応して満たしたりすることが困難になり、その結果、錯覚が生じます。 不適切または不十分な生成戦略: LLM がテキストを生成する場合、通常、生成プロセスと結果を制御または最適化するために何らかのテクノロジーまたは方法を使用し、それによって生成戦略を形成します。これらの戦略には、不適切、不十分、不安定、説明不能、信頼できないなどの問題が発生する可能性があり、その結果、LLM がテキスト生成時に生成の方向性と品質を効果的に規制および指導できなくなったり、テキストを検出して修正できなくなったりします。エラーが発生し、幻覚が引き起こされました。また、生成戦略が複雑すぎるか変更可能であるため、LLM がテキストを生成する際に生成の一貫性と信頼性を維持および確保することが困難になったり、生成の効果を評価してフィードバックを与えることが困難になり、幻覚が引き起こされることもあります。 LLM における幻覚の問題をよりよく解決するには、次のことが必要です。 LLM によって生成される幻覚を効果的に検出し、評価します。上記の幻覚の種類に応じて、著者は幻覚の検出方法を次の 4 つのカテゴリに分類します。 文法的幻覚の検出方法: いくつかの文法チェック ツールまたはルールを使用して、幻覚を識別します。 LLM によって生成されたテキストの文法上の誤りまたは不規則性を修正します。たとえば、スペル チェック、句読点チェック、語順チェック、時制チェック、主語と動詞の一致チェックなどの一部のツールやルールを使用して、LLM によって生成されたテキスト内の文法上の錯誤を検出して修正できます。 意味錯覚の検出方法: いくつかの意味分析ツールまたはモデルを使用して、LLM によって生成されたテキストの意味エラーまたは不合理性を理解し、評価します。たとえば、単語の意味分析、参照解決、論理的推論、曖昧さの除去、矛盾検出などの一部のツールやモデルを使用して、LLM によって生成されたテキスト内の意味論的な錯覚を検出および修正できます。 知識錯覚の検出方法: いくつかの知識検索または検証ツールまたはモデルを使用して、LLM によって生成されたテキスト内の知識エラーまたは不一致を取得および比較します。たとえば、ナレッジ グラフ、検索エンジン、ファクト チェック、証拠チェック、引用チェックなどの一部のツールまたはモデルを使用して、LLM によって生成されたテキスト内の知識の錯覚を検出および修正できます。 創作錯視の検出方法: 創作評価またはフィードバック ツールやモデルを使用して、LLM によって生成されたテキスト内の創作エラーや不適切さを検出および評価します。たとえば、スタイル分析、センチメント分析、創作評価、意見分析、目標分析などの一部のツールまたはモデルを使用して、LLM によって生成されたテキスト内の創作幻想を検出および修正できます。 上記の幻覚の程度と影響に応じて、幻覚の評価基準は次の 4 つのカテゴリに分類できます。文法の正しさ (Grammational Correctness): LLM によって生成されたテキストが、スペル、句読点、語順、時制、主語と動詞の一致など、文法的に言語の規則や習慣に準拠しているかどうかを指します。この標準は、BLEU、ROUGE、BERTScore などの自動または手動の文法チェック ツールや方法を通じて評価できます。 意味論的な妥当性: LLM によって生成されたテキストが、単語の意味、参照、論理、曖昧さ、矛盾など、言語の意味および論理に意味論的に準拠しているかどうかを指します。この標準は、METEOR、MoverScore、BERTScore などの自動または手動のセマンティック分析ツールまたは方法を通じて評価できます。 知識の一貫性: LLM によって生成されたテキストが実際の事実や証拠と知的に一貫しているかどうか、または事実、証拠、参考文献、一致などの入力情報やコンテキスト情報と一貫しているかどうかを指します。この基準は、FEVER、FactCC、BARTScore などの自動または手動のナレッジ検索または検証ツールまたは方法を通じて評価できます。 クリエイティブな適切性: LLM によって生成されたテキストがタスクや目標の要件を創造的に満たしているか、ユーザーの好みや期待と一致しているか、ユーザーの好みと一致しているかどうかを指します。気分や態度が調和しているか、スタイル、感情、意見、目標など、ユーザーとのコミュニケーションや対話が役立つかどうか。この標準は、BLEURT、BARTScore、SARI などの自動または手動の作成評価またはフィードバック ツールや方法を通じて評価できます。 LLM の幻覚の問題をより良く解決するには、効果的に緩和し、 LLM を減らす 幻覚が発生しました。著者は、さまざまなレベルと角度に応じて、幻覚緩和方法を次のカテゴリに分類します。 世代後の洗練LLM がテキストを生成した後、テキストのチェックと修正を実行して、錯覚を排除または軽減します。このタイプの方法の利点は、LLM の再トレーニングや調整が必要なく、任意の LLM に直接適用できることです。このタイプのアプローチの欠点は、錯覚が完全に除去されない可能性があること、または新しい錯覚が導入される可能性があること、または元のテキストの情報や創造性の一部が失われる可能性があることです。このタイプの方法の代表的なものは次のとおりです。 RARR (Refinement with Attribution and Retrieved References): (Chrysostomou and Aletras、2021) は、帰属と検索に基づいた洗練方法を提案しました。 LLM によって生成されたテキストの忠実度。属性モデルは、LLM によって生成されたテキスト内の各単語が、入力情報、LLM のパラメーター知識、または LLM の生成戦略に由来するかどうかを識別するために使用されます。検索モデルを使用して、入力情報に関連する参考テキストを外部の知識ソースから取得します。最後に、リファインメント モデルを使用して、帰属結果と検索結果に基づいて LLM によって生成されたテキストを修正し、入力情報との一貫性と信頼性を向上させます。 High Entropy Word Spotting and Replacement (HEWSR): (Zhang et al., 2021) は、LLM によって生成されたテキストの幻覚を軽減するためのエントロピーに基づいた間引き方法を提案しました。まず、エントロピー計算モデルを使用して、LLM によって生成されたテキスト内の高エントロピーの単語、つまり生成時の不確実性がより高い単語を識別します。次に、置換モデルを使用して、入力情報または外部の知識ソースからより適切な単語を選択し、高エントロピーの単語を置き換えます。最後に、平滑化モデルを使用して、置換されたテキストにいくつかの調整を加え、文法的および意味的な一貫性を維持します。 ChatProtect (自己矛盾検出によるチャット保護): (Wang et al., 2021) は、LLM セキュリティによって生成されたチャット会話を改善するための、自己矛盾検出に基づく改良方法を提案しました。まず、矛盾検出モデルを使用して、LLM によって生成された対話内の自己矛盾、つまり、以前の対話内容と矛盾する内容を特定します。次に、置換モデルを使用して、自己矛盾した応答を、いくつかの事前定義された安全な応答の中からより適切なものに置き換えます。最後に、評価モデルを使用して、置き換えられた対話にスコアを与え、その安全性と流暢性を測定します。 フィードバックと推論による自己改善は LLM で生成されますその過程で、いくつかの評価と調整が行われます錯覚を排除または軽減するためにテキストに作成されています。このタイプの方法の利点は、幻覚をリアルタイムで監視および修正でき、LLM の自己学習および自己調整能力を向上できることです。このタイプのアプローチの欠点は、LLM の追加のトレーニングや調整が必要になる場合があること、または外部の情報やリソースが必要になる場合があることです。このタイプの方法の代表的なものは次のとおりです。 自己反省法 (SRM): (Iyer et al., 2021) は、自己フィードバックに基づいてパフォーマンスを向上させる完璧な方法を提案しました。 LLM が生成する医療上の質問と回答の信頼性。この方法では、まず生成モデルを使用して、入力された質問とコンテキストに基づいて最初の回答を生成します。次に、フィードバック モデルを使用して、入力された質問とコンテキストに基づいてフィードバックの質問を生成します。これは、最初の回答内の潜在的な幻覚を検出するために使用されます。次に、回答モデルを使用してフィードバックの質問に基づいて回答を生成し、最初の回答の正しさを検証します。最後に、修正モデルを使用して回答結果に基づいて最初の回答を修正し、信頼性と精度を向上させます。 構造化比較 (SC) 推論: (Yan et al., 2021) は、LLM によって生成されるテキストの好みの予測の一貫性を向上させるために、構造化比較に基づく推論方法を提案しました。この方法では、生成モデルを使用して、入力テキストのペアに基づいて構造化された比較を生成します。つまり、さまざまな側面でテキストのペアを比較および評価します。推論モデルを使用して、構造化された比較に基づいてテキストの好み、つまりどのテキストのペアが優先されるかを予測します。評価モデルを使用して、生成された比較を予測結果と比較して評価し、その一貫性と信頼性を向上させます。 Think While Ideally Articulated Knowledge (TWEAK): (Qiu et al., 2021a) は、LLM によって生成された知識のテキストへの忠実度を向上させる、仮説検証に基づく推論方法を提案しています。この方法では、生成モデルを使用して、入力された知識に基づいて初期テキストを生成します。次に、仮説モデルを使用して、最初のテキストに基づいていくつかの仮説を生成します。つまり、さまざまな側面からテキストの将来のテキストを予測します。次に、検証モデルを使用して、入力された知識に基づいて各仮説の正しさを検証します。最後に、調整モデルを使用して検証結果に基づいて初期テキストを調整し、入力された知識との一貫性と信頼性を向上させます。 新しいデコード戦略は、LLM がテキストを生成するプロセスでテキストの確率を決定することです。錯覚を排除または軽減するためのいくつかの変更または最適化。このタイプの方法の利点は、生成された結果に直接影響を与えることができ、LLM の柔軟性と効率を向上できることです。このタイプのアプローチの欠点は、LLM の追加のトレーニングや調整が必要になる場合があること、または外部の情報やリソースが必要になる場合があることです。このタイプの方法の代表的なものは次のとおりです。 Context-Aware Decoding (CAD): (Shi et al.、2021) LLM の知識によって生成されたテキストを削減するためのコントラストベースのデコード戦略を提案しました。衝突。この戦略では、対照モデルを使用して、入力情報を使用した場合と使用しない場合の LLM の出力の確率分布の差異を計算します。次に、増幅モデルを使用してこの差異を増幅し、入力情報と一致する出力の確率が高く、入力情報と矛盾する出力の確率が低くなります。最後に、生成モデルを使用して増幅された確率分布に基づいてテキストを生成し、入力情報との一貫性と信頼性を向上させます。 Decoding by Contrasting Layers (DoLa): (Chuang et al., 2021) は、LLM によって生成されたテキストにおける知識の錯覚を軽減するためのレイヤー コントラスト ベースの復号化戦略を提案しました。まず、レイヤー選択モデルを使用して、LLM 内の特定のレイヤーを知識レイヤー、つまり、より事実に基づいた知識を含むレイヤーとして選択します。次に、レイヤー コントラスト モデルを使用して、語彙空間内の知識レイヤーと他のレイヤー間の対数差が計算されます。最後に、生成モデルを使用してレイヤー比較後の確率分布に基づいてテキストを生成し、事実知識との一貫性と信頼性を向上させます。 ナレッジ グラフの利用法は、LLM がテキストを生成するプロセスでいくつかの構造を使用することです。錯覚を排除または軽減するために、入力情報に関連する知識を提供または補足するため。このタイプの方法の利点は、外部知識を効果的に取得して統合でき、LLM の知識範囲と知識の一貫性を向上できることです。このタイプのアプローチの欠点は、LLM の追加のトレーニングまたは調整が必要になる場合があること、または高品質のナレッジ グラフが必要になる場合があることです。このタイプの方法の代表的なものは次のとおりです。 RHO (ナレッジ グラフからのリンクされたエンティティと関係述語の表現): (Ji et al., 2021a) 知識に基づく表現方法を提案グラフ 、LLM によって生成された対話応答の忠実度を向上させるために使用されます。まず、ナレッジ検索モデルを使用して、ナレッジ グラフ、つまりいくつかのエンティティと関係を含むグラフから入力ダイアログに関連するいくつかのサブグラフを取得します。次に、知識エンコード モデルを使用してサブグラフ内のエンティティと関係をエンコードし、それらのベクトル表現を取得します。次に、知識融合モデルを使用して知識のベクトル表現を対話のベクトル表現に融合し、強化された対話表現を取得します。最後に、知識生成モデルを使用して、強化された対話表現に基づいて忠実な対話応答を生成します。 FLEEK (外部知識から取得した証拠による事実上の誤りの検出と修正): (Bayat et al., 2021) は、LLM によって生成されたテキストの事実性を向上させるために、ナレッジ グラフに基づく検証および修正方法を提案しました。この方法では、まず事実認識モデルを使用して、LLM によって生成されたテキスト内の潜在的に検証可能な事実、つまりナレッジ グラフで証拠が見つかる事実を識別します。次に、質問生成モデルを使用して、ナレッジ グラフをクエリするための各ファクトに対する質問が生成されます。次に、ナレッジ検索モデルを使用して、問題に関連する証拠をナレッジ グラフから取得します。最後に、事実検証および修正モデルを使用して、証拠に基づいて LLM によって生成されたテキスト内の事実を検証および修正し、事実性と正確性を向上させます。 忠実度ベースの損失関数は、LLM でトレーニングまたは微調整されます。その過程で、測定するいくつかのメトリックが使用されます。生成されたテキストと入力情報または実際のラベルの間の一貫性は、錯覚を排除または軽減するために損失関数の一部として使用されます。このタイプの方法の利点は、LLM のパラメーターの最適化に直接影響し、LLM の忠実性と精度を向上できることです。このタイプのアプローチの欠点は、LLM の追加のトレーニングまたは調整が必要になる場合があること、または高品質の注釈付きデータが必要になる場合があることです。このタイプの方法の代表的なものは次のとおりです。 テキスト幻覚軽減 (THAM) フレームワーク: (Yoon et al.、2022) によって生成されるビデオを削減するために、情報理論に基づいた損失関数を提案しました。 LLM 会話中の幻想。まず、対話言語モデルを使用して対話の確率分布を計算します。次に、幻覚言語モデルを使用して幻覚の確率分布、つまり入力映像からは得られない情報の確率分布を計算します。次に、相互情報量モデルを使用して、対話と錯視の間の相互情報量、つまり対話に含まれる錯覚の度合いに関する相互情報量を計算します。最後に、クロスエントロピー モデルを使用して、対話と実際のラベルのクロス エントロピー、つまり対話の精度を計算します。この損失関数の目標は、相互情報量と相互エントロピーの合計を最小限に抑え、それによって対話における錯覚や誤りを減らすことです。 外部知識から取得した証拠による事実上の誤り訂正 (FECK): (Ji et al., 2021b) は、LLM によって生成されたテキストの精度を向上させるために、知識証拠に基づく損失関数を提案しました。事実。まず、ナレッジ検索モデルを使用して、ナレッジ グラフ、つまりいくつかのエンティティと関係を含むグラフから入力テキストに関連するいくつかのサブグラフを取得します。次に、知識エンコード モデルを使用してサブグラフ内のエンティティと関係をエンコードし、それらのベクトル表現を取得します。次に、知識整合モデルを使用して、LLM によって生成されたテキスト内のエンティティおよび関係をナレッジ グラフ内のエンティティおよび関係と整合させ、それらの一致度を取得します。最後に、損失関数は知識損失モデルを使用して、LLM によって生成されたテキスト内のエンティティおよび関係と、ナレッジ グラフ内のエンティティおよび関係の間の距離、つまり事実からの逸脱を計算します。この損失関数の目標は、知識の損失を最小限に抑え、それによって LLM によって生成されるテキストの事実性と正確性を向上させることです。 プロンプトの微調整とは、LLM がテキストを生成するプロセスで特定のテキストまたは記号を使用することです。 LLM の生成動作を制御または誘導して幻覚を除去または軽減するための入力。このタイプの方法の利点は、LLM のパラメーター知識を効果的に調整およびガイドでき、LLM の適応性と柔軟性を向上できることです。このタイプのアプローチの欠点は、LLM の追加のトレーニングまたは調整が必要になる場合があること、または高品質のプロンプトが必要になる場合があることです。このタイプの方法の代表的なものは次のとおりです。 UPRISE (Universal Prompt-based Refinement for Improving Semantic Equivalence): (Chen et al.、2021) は、ユニバーサルに基づく微調整方法を提案しました。 LLM によって生成されたテキストの意味上の等価性を向上させるために、プロンプトを使用します。まず、プロンプト生成モデルを使用して、入力テキスト、つまり、意味的に同等のテキストを生成するように LLM をガイドするために使用されるテキストまたは記号に基づいて一般的なプロンプトを生成します。次に、ヒント微調整モデルを使用して、入力テキストとヒントに基づいて LLM のパラメーターを微調整し、入力テキストと意味的に同等のテキストを生成する傾向が高まります。最後に、このメソッドはヒント生成モデルを使用して、微調整された LLM のパラメーターに基づいて意味的に同等のテキストを生成します。 SynTra (抽象的な要約における幻覚軽減のための合成タスク): (Wang et al., 2021) は、LLM によって生成された要約における幻覚を軽減するための合成タスクベースの微調整方法を提案しました。まず、合成タスク生成モデルを使用して、入力テキストに基づいて合成タスク、つまり要約文から幻覚を検出する問題を生成します。次に、合成タスク微調整モデルを使用して、入力テキストとタスクに基づいて LLM のパラメーターを微調整し、入力テキストと一貫性のある概要を生成する傾向が高まります。最後に、合成タスク生成モデルを使用して、微調整された LLM のパラメーターに基づいて一貫した概要を生成します。 LLM における幻覚軽減技術はある程度の進歩が見られましたが、まだ改善の余地はあります。課題と限界があるため、さらなる研究と探索が必要です。主な課題と制限の一部を以下に示します。 幻覚の定義と測定: 統一された明確な定義と測定がなければ、異なる研究が判断と評価に異なる基準と指標を使用する可能性があります。 LLM によって生成されたテキスト内の錯覚。これは、矛盾した比較できない結果をもたらし、LLM における幻覚問題の理解と解決にも影響を与えます。したがって、LLM における幻覚の効果的な検出と評価を促進するために、幻覚の共通かつ信頼できる定義と測定を確立する必要があります。 幻覚に関するデータとリソース: LLM における幻覚の研究開発をサポートするための、高品質で大規模なデータとリソースが不足しています。たとえば、LLM で幻覚の検出および軽減方法をトレーニングおよびテストするための幻覚の注釈を含む一部のデータセットが不足しています。LLM によって生成されたテキスト内の知識を提供および検証するための実際の事実と証拠を含む一部の知識ソースが不足しています。 ; 幻覚を含む一部のデータセットが不足しています。LLM によって生成されたテキスト内の幻覚の影響を収集および分析するための、ユーザーのフィードバックとレビューのためのプラットフォーム。したがって、LLM における幻覚に関する効果的な研究開発を促進するには、いくつかの高品質で大規模なデータとリソースを構築する必要があります。 幻覚の原因とメカニズム: LLM が幻覚を引き起こす理由、および LLM 内で幻覚がどのように形成され伝播するかを明らかにし説明するための、原因とメカニズムについての詳細かつ包括的な分析はありません。の。たとえば、LLM におけるパラメトリック知識、ノンパラメトリック知識、生成戦略がどのように相互に影響を及ぼし、相互作用するのか、また、それらがどのようにして異なるタイプ、程度、効果の錯覚につながるのかは不明です。したがって、LLM における幻覚の効果的な予防と制御を促進するには、原因とメカニズムの詳細かつ包括的な分析が必要です。 幻覚の解決策と最適化: LLM によって生成されたテキストの幻覚を排除または軽減し、LLM によって生成されたテキストの品質を向上させるための、完璧で普遍的な解決策や最適化ソリューションはありません。効果。たとえば、LLM の汎化能力と創造性を失うことなく、LLM の忠実性と精度を向上させる方法は不明です。したがって、LLM によって生成されるテキストの品質と効果を向上させるために、いくつかの完全で普遍的なソリューションと最適化ソリューションを設計する必要があります。 3. LLM における幻覚の検出方法と評価基準
4. LLM の幻覚を緩和する方法
世代後の洗練
フィードバックと推論による自己改善
新しいデコード戦略
ナレッジ グラフの利用法
忠実度ベースの損失関数
プロンプト チューニング
5. LLM における幻覚の課題と限界
以上が大規模機械学習における幻覚軽減技術の包括的な研究の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。