
ホームページ >テクノロジー周辺機器 >AI >AIが生まれ変わる:オンライン文学界の覇権を取り戻す
AIが生まれ変わる:オンライン文学界の覇権を取り戻す

- 王林転載
- 2024-01-04 19:24:551431ブラウズ
Reborn、私は今世でMidRealとして生まれ変わります。他人の「ウェブ記事」執筆を手伝うAIロボット。

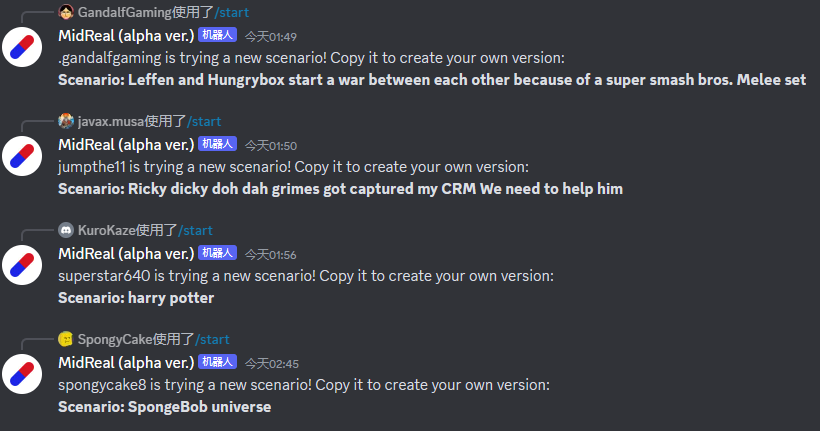
# クラシックな設定は誰にも愛されないでしょう?私はしぶしぶこれらのユーザーの想像力を実現するお手伝いをさせていただきます。
正直に言うと、私の中では前世では、見るべきものと見るべきではないものはすべて見ました。以下のトピックはすべて私のお気に入りです。


#自慢ではありませんが、私に執筆を依頼していただければ、素晴らしい作品を作成させていただきます。結末にご満足いただけない方、「途中で死んでしまった」キャラクターが好きな方、執筆途中で作者が困難に遭遇した場合でも、安心してお任せいただけますので、ご満足いただける内容を書きます。 。 ################################################ #甘い記事、罵倒的な記事、想像力豊かな記事、それぞれがあなたのスイートスポットを強く刺激します。
 MidReal の自己報告を聞いた後、考えていますか?理解していますか?
MidReal の自己報告を聞いた後、考えていますか?理解していますか?
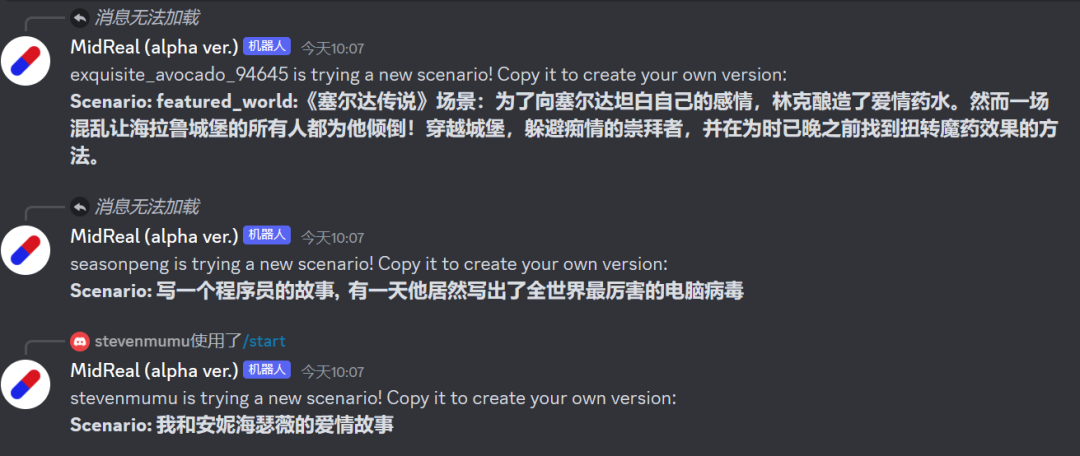
MidReal は、ユーザーが提供したシナリオの説明に基づいて、対応する新しいコンテンツを生成できる非常に強力なツールです。プロットのロジックと創造性が優れているだけでなく、生成プロセス中にイラストも生成され、想像しているものをより鮮明に描写します。さらに、MidReal にはインタラクティブ性という非常に優れた特徴もあります。展開したいストーリーラインを選択し、ストーリー全体をニーズに合わせてより適切なものにすることができます。小説を書いている場合でも、クリエイティブなプロジェクトを作成している場合でも、MidReal は非常に便利なツールです。
#ダイアログ ボックスに「/start」と入力して、ストーリーを伝え始めます。試してみてはいかがでしょうか。MidReal ポータル: https://www.midreal.ai/

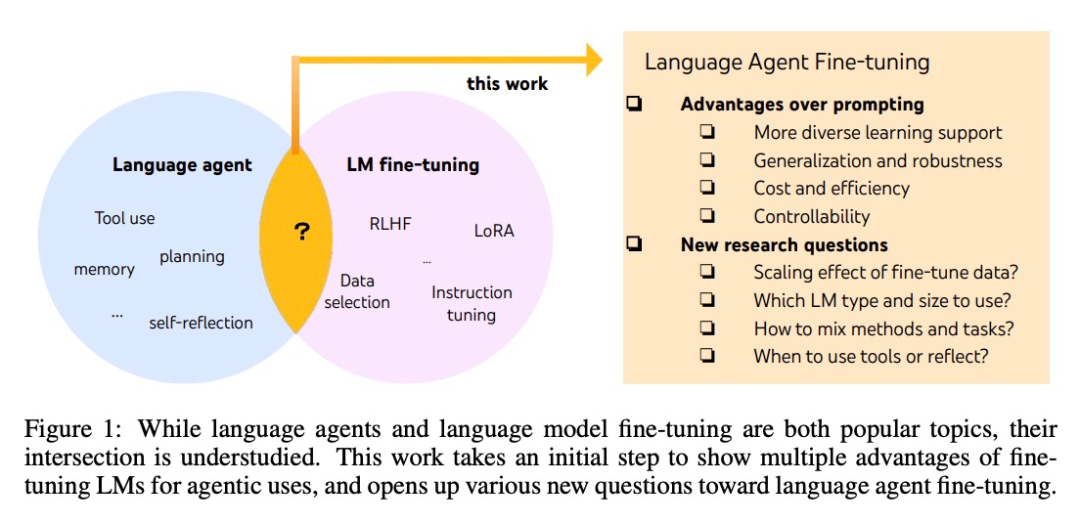
MidReal の背後にあるテクノロジーは、論文「FireAct: 言語エージェントの微調整に向けて」に由来しています。この論文の著者は、まず AI エージェントを使用して言語モデルを微調整することを試み、多くの利点を発見し、新しいエージェント アーキテクチャを提案しました。
MidReal はこの構造に基づいているため、Web 記事を非常に適切に書くことができます。
 AI エージェントの開発は通常、既製の言語モデルに基づいていますが、言語モデルはエージェントとして開発されていないため、エージェントを拡張した後のほとんどの言語モデルのパフォーマンスは堅牢性が悪い。最もスマートなエージェントは GPT-4 によってのみサポートされており、高コストと遅延、および低い制御性と高い再現性を避けることはできません。
AI エージェントの開発は通常、既製の言語モデルに基づいていますが、言語モデルはエージェントとして開発されていないため、エージェントを拡張した後のほとんどの言語モデルのパフォーマンスは堅牢性が悪い。最もスマートなエージェントは GPT-4 によってのみサポートされており、高コストと遅延、および低い制御性と高い再現性を避けることはできません。
微調整を使用すると、上記の問題を解決できます。研究者たちが言語知能のより体系的な研究に向けて第一歩を踏み出したのもこの論文でした。彼らは、複数のタスクとプロンプトメソッドによって生成されたエージェントの「アクション軌跡」を使用して言語モデルを微調整することができる FireAct を提案しました。これにより、モデルがさまざまなタスクや状況に適応し、全体的なパフォーマンスと適用性が向上します。
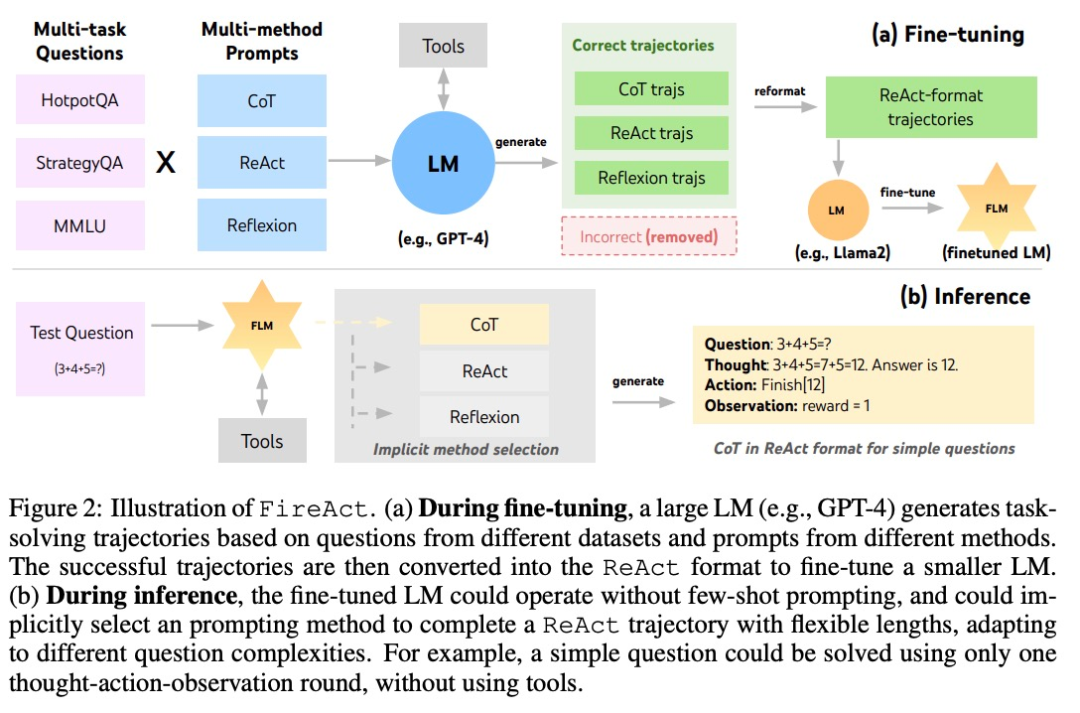
- 思考連鎖 (CoT) は、質問と回答を結びつける中間推論を生成する効果的な方法です。各 CoT 軌跡は、単一ラウンドの ReAct 軌跡に単純化できます。ここで、「思考」は中間推論を表し、「アクション」は答えを返すことを表します。 CoT は、アプリケーション ツールとの対話が必要ない場合に特に役立ちます。
- Reflexion は主に ReAct の軌跡に従いますが、追加のフィードバックと内省が追加されます。この研究では、ReAct のラウンド 6 と 10 でのみ反省が促されました。このようにして、長い ReAct 軌跡は、現在のタスクを解決するための戦略的な「支点」を提供でき、モデルが戦略を解決または調整するのに役立ちます。たとえば、「映画タイトル」で検索しても答えが見つからない場合は、検索キーワードを「監督」に変更するとよいでしょう。
- HotpotQA は、複数ステップの推論と知識の検索に対して、より困難なテストを課す QA データセットです。研究者らは、データキュレーションの微調整に 2,000 のランダムなトレーニング質問を使用し、評価には 500 のランダムな開発質問を使用しました。
- Bamboogle は、HotpotQA と同様の形式の 125 個のマルチホップ質問のテスト セットですが、質問を直接グーグル検索することを避けるように慎重に設計されています。
- StrategyQA は、暗黙的な推論ステップを必要とする Yes/No QA データセットです。
- MMLU は、初等数学、歴史、コンピューター サイエンスなど、さまざまな分野の 57 の多肢選択式 QA タスクをカバーしています。
- 単一のプロンプト メソッドを使用した微調整。単一タスク ;
- 単一タスクでの微調整には複数の方法を使用します;
- 複数のタスクでの微調整には複数の方法を使用します。
研究者らは、単一のタスク (HotpotQA) と単一のプロンプト メソッド (ReAct) からのデータを使用して微調整の問題を調査しました。このシンプルで制御可能なセットアップを使用して、ヒント (パフォーマンス、効率、堅牢性、一般化) を超えた微調整のさまざまな利点を確認し、さまざまな LM、データ サイズ、および微調整方法の影響を研究します。
表 2 に示すように、微調整により、HotpotQA EM の促進効果を継続的かつ大幅に向上させることができます。弱い LM は微調整からより多くの恩恵を受けますが (例: Llama-2-7B は 77% 改善)、GPT-3.5 のような強力な LM であっても微調整によりパフォーマンスを 25% 向上させることができます。これは明らかに学習の利点を示しています。より多くのサンプルから。表 1 の強力なキューイング ベースラインと比較すると、微調整された Llama-2-13B がすべての GPT-3.5 キューイング方法よりも優れていることがわかりました。これは、より強力な商用 LM を開発するよりも、小規模なオープンソース LM を微調整する方が効果的である可能性があることを示唆しています。
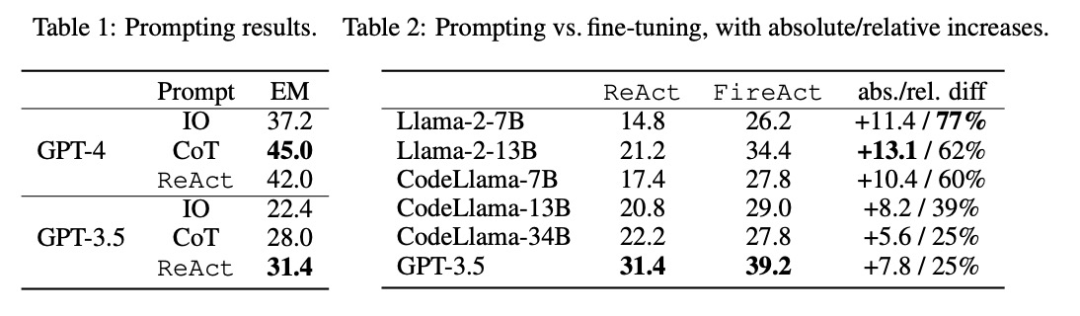
エージェントの推論プロセスでは、微調整が低コストかつ高速になります。 LM の微調整には少数のコンテキスト例が必要ないため、推論はより効率的になります。たとえば、表 3 の最初の部分では、微調整された推論のコストと shiyongtisideGPT-3.5 推論のコストを比較しており、推論時間が 70% 削減され、全体の推論コストが削減されていることがわかります。

研究者らは、簡素化された無害なセットアップを検討しました。つまり、検索 API では、50% の確率で、 「なし」またはランダムな検索応答を返し、言語エージェントに質問に確実に答えることができるかどうかを尋ねます。表 3 の 2 番目の部分のデータによると、「なし」に設定するとより難しくなり、ReAct EM は 33.8% 減少しましたが、FireAct EM は 14.2% しか減少しませんでした。これらの予備的な結果は、堅牢性を向上させるには多様な学習サポートが重要であることを示しています。
表 3 の 3 番目の部分は、Bamboogle でヒント付き GPT-3.5 を微調整して使用した EM の結果を示しています。 HotpotQA またはヒントを使用して微調整された GPT-3.5 はどちらも Bamboogle に対して適切に一般化しますが、前者 (44.0 EM) は依然として後者 (40.8 EM) を上回っており、微調整には一般化の利点があることが示されています。
2. 単一タスクで複数の方法を使用して微調整を行う
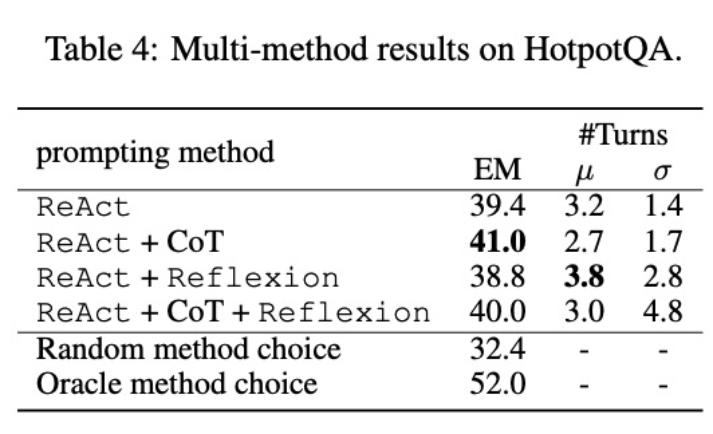
著者は CoT と Reflexion を ReAct と統合し、ReAct のパフォーマンスをテストしました。タスクに対して複数の方法を使用して微調整します (HotpotQA)。 FireAct のスコアと各データ セットの既存の手法を比較すると、次のことがわかりました。
まず、研究者らはさまざまな方法でエージェントを微調整し、柔軟性を向上させました。 5 番目の図では、定量的な結果に加えて、研究者らは複数の方法による微調整の利点を説明するために 2 つの問題例も示しています。最初の質問は比較的単純でしたが、ReAct のみを使用して微調整したエージェントが過度に複雑なクエリを検索したため、気が散って不正確な回答が返されました。対照的に、CoT と ReAct の両方を使用して微調整したエージェントは、内部知識に依存することを選択し、自信を持って 1 ラウンド以内にタスクを完了しました。 2 番目の問題はさらに難しく、ReAct のみを使用して微調整したエージェントは有用な情報を見つけることができませんでした。対照的に、Reflexion と ReAct の両方の微調整を使用したエージェントは、ジレンマに遭遇したときに反省して検索戦略を変更し、最終的に正しい答えを獲得しました。さまざまな問題に対処するために柔軟なソリューションを選択できることは、他の微調整方法と比較した FireAct の主な利点です。

第 2 に、複数の方法を使用してさまざまな言語モデルを微調整すると、さまざまな影響が生じます。表 4 に示すように、微調整に複数のエージェントを組み合わせて使用しても必ずしも改善が得られるわけではなく、方法の最適な組み合わせは基礎となる言語モデルによって異なります。たとえば、ReAct CoT は、GPT-3.5 および Llama-2 モデルでは ReAct よりも優れていますが、CodeLlama モデルではそうではありません。 CodeLlama7/13B の場合、ReAct CoT Reflexion の結果は最悪でしたが、CodeLlama-34B は最高の結果を達成しました。これらの結果は、基礎となる言語モデルと微調整データの間の相互作用についてさらなる研究が必要であることを示唆しています。
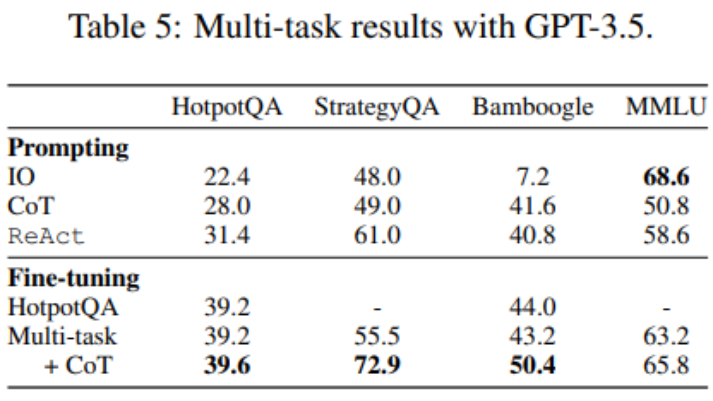
これまで、微調整には HotpotQA データのみが使用されてきましたが、LM 微調整に関する実証研究では、異なるタスクを混合することに利点があることが示されています。研究者らは、HotpotQA (500 ReAct サンプル、277 CoT サンプル)、StrategyQA (388 ReAct サンプル、380 CoT サンプル)、MMLU (456 ReAct サンプル、469 CoT サンプル) の 3 つのデータセットからの混合トレーニング データを使用して GPT-3.5 を微調整しました。 )。
表 5 に示すように、StrategyQA/MMLU データを追加した後も、HotpotQA/Bamboogle のパフォーマンスはほとんど変化しません。一方で、StrategyQA/MMLU トラックには非常に異なる質問やツールの使用戦略が含まれているため、移行が困難になります。一方、ディストリビューションの変更にもかかわらず、StrategyQA/MMLU の追加は HotpotQA/Bamboogle のパフォーマンスに影響を与えず、マルチタスク エージェントを微調整して複数のシングルタスク エージェントを置き換えることが将来の可能性のある方向であることを示しています。研究者らがマルチタスク、単一メソッドの微調整からマルチタスク、複数メソッドの微調整に切り替えたところ、すべてのタスクにわたってパフォーマンスが向上したことがわかり、マルチメソッドのエージェント微調整の価値が改めて明確になりました。
- https://twitter.com/Tisoga/status/1739813471246786823
- https://www.zhihu .com/people/eyew3g
以上がAIが生まれ変わる:オンライン文学界の覇権を取り戻すの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。