
ホームページ >テクノロジー周辺機器 >AI >X-Dreamer は次元の壁を突破し、2D 生成と 3D 生成の分野を統合し、高品質のテキストを 3D 生成にもたらします。
X-Dreamer は次元の壁を突破し、2D 生成と 3D 生成の分野を統合し、高品質のテキストを 3D 生成にもたらします。

- PHPz転載
- 2023-12-15 13:54:33688ブラウズ
近年、事前トレーニングされた拡散モデルの開発により、テキストの 3D コンテンツへの自動変換において重要な進歩が見られました [1、2、3]。その中で、DreamFusion[4] は、事前トレーニングされた 2D 拡散モデル [5] を利用して、専用の 3D アセット データセットを必要とせずにテキストから 3D アセットを自動的に生成する効果的な方法を導入しています
## DreamFusion に導入された主要な革新の 1 つは、分別蒸留サンプリング (SDS) アルゴリズムです。このアルゴリズムは、NeRF [6] などの事前トレーニング済み 2D 拡散モデルを使用して単一の 3D 表現を評価し、任意のカメラ視点からのレンダリング画像が指定されたテキストと高い一貫性を維持するように最適化します。独創的な SDS アルゴリズムに触発され、事前トレーニングされた 2D 拡散モデルを適用することでテキストから 3D への生成タスクを進歩させるいくつかの作品 [7、8、9、10、11] が登場しました。
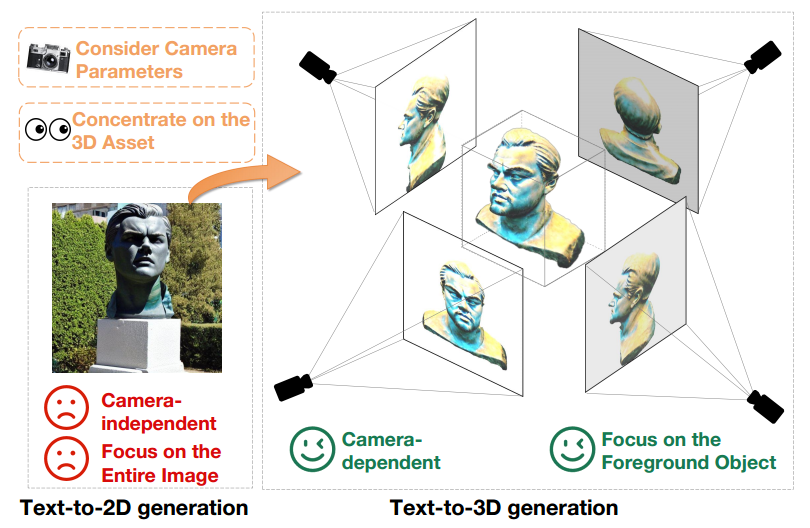
テキストから 3D への生成は、事前トレーニングされたテキストから 2D への拡散モデルを活用することで大幅に進歩しましたが、2D 画像と 3D アセットの間には依然として大きなギャップがあります。フィールドギャップ。この違いは図 1 に明確に示されています。
まず、テキストから 2D モデルは、他の角度を無視して特定の角度から高品質の画像を生成することに重点を置いた、カメラに依存しない生成結果を生成します。対照的に、3D コンテンツの作成は、位置、撮影角度、視野などのカメラ パラメーターと複雑に結びついています。したがって、テキストから 3D モデルは、考えられるすべてのカメラ パラメーターにわたって高品質の結果を生成する必要があります。
さらに、テキストから 2D への生成モデルは、画像全体の一貫性を維持するために、前景要素と背景要素を同時に生成する必要があります。対照的に、テキストから 3D への生成モデルでは、前景オブジェクトの作成のみに重点を置く必要があります。この違いにより、テキストから 3D モデルは、前景オブジェクトを正確に表現および生成するために、より多くのリソースと注意を割り当てることができます。したがって、事前トレーニングされた 2D 拡散モデルを 3D アセット作成に直接使用する場合、テキストから 2D への生成とテキストから 3D への生成の間の領域の違いが、重大なパフォーマンスの障壁になります。 ##図 1 同じテキスト プロンプト、つまり「レオナルド ディカプリオの頭の像」の下でのテキストから 2D への生成モデル (左) とテキストから 3D への生成モデル (右) の出力。
X-Dreamer の重要なコンポーネントは、カメラ誘導低ランク適応 (CG-LoRA) とアテンション マスク アライメント (AMA) ロスの 2 つの革新的な設計です。
まず第一に、既存の方法 [7、8、9、10] は通常、テキストから 3D への生成に 2D 事前トレーニング済み拡散モデル [5、12] を使用します。カメラを操作する機能、パラメータ間の固有の関係。この制限に対処し、X-Dreamer がカメラ パラメーターの影響を直接受けた結果を確実に生成できるようにするために、この論文では、事前トレーニングされた 2D 拡散モデルを調整する CG-LoRA を紹介しています。特に、CG-LoRA のパラメータは各反復中にカメラ情報に基づいて動的に生成されるため、テキストから 3D モデルとカメラ パラメータの間に堅牢な関係が確立されます。
第 2 に、事前トレーニングされたテキストから 2D への拡散モデルでは前景と背景の生成に注意が割り当てられますが、3D アセットの作成では前景オブジェクトの正確な生成により多くの注意が必要です。この問題に対処するために、この論文では、3D オブジェクトのバイナリ マスクを使用して、事前トレーニングされた拡散モデルのアテンション マップをガイドし、前景オブジェクトの作成を優先する AMA 損失を提案しています。このモジュールを組み込むことにより、X-Dreamer は前景オブジェクトの生成を優先し、生成される 3D コンテンツの全体的な品質を大幅に向上させます。
プロジェクトのホームページ:

Github ホームページ: https://github.com/xmu-xiaoma666/X-Dreamer
ディスカッション
#アドレス: https://arxiv.org/abs/2312.00085
XX-Dreamer は、text-to の分野に次の貢献を行っています。 -3D 生成の貢献: XX-Dreamer は、幾何学学習と外観という 2 つの主要な段階で構成されます。勉強。幾何学学習のために、この研究では 3D 表現として DMTET を使用し、それを初期化するために 3D 楕円体を利用します。損失関数は初期化されると、平均二乗誤差 (MSE) 損失を使用します。次に、DMTET と CG-LoRA は、この研究で提案されている分別蒸留サンプリング (SDS) 損失と AMA 損失を使用して最適化され、3D 表現と入力テキスト プロンプトの整合性を確保します #For外観学習では、この論文では双方向反射分布関数 (BRDF) モデリングを使用しています。具体的には、この論文では、トレーニング可能なパラメータを備えた MLP を利用して、表面の材質を予測します。ジオメトリ学習段階と同様に、この論文では SDS 損失と AMA 損失を使用して MLP と CG-LoRA のトレーニング可能なパラメータを最適化し、3D 表現とテキスト キューの間の位置合わせを実現します。図2にX-Dreamerの詳細な構成を示します。 図 2 幾何学学習と外観学習を含む X-Dreamer の概要。 幾何学学習 (幾何学学習) このモジュールでは、X-Dreamer DMTET は、MLP ネットワーク ジオメトリを初期化した後、DMTET のジオメトリを入力テキスト プロンプトに合わせます。これは、差分レンダリング技術を使用して、ランダムにサンプリングされたカメラ ポーズ c を与えられた初期化された DMTET から法線マップ n とオブジェクトのマスク m を生成することによって行われます。続いて、法線マップ n が、トレーニング可能な CG-LoRA 埋め込みを備えたフリーズ安定拡散モデル (SD) に入力され、 ##このうち、 は SD のパラメータを表し、
は、 i 番目の注目層の注目マップ。関数 3D オブジェクトのジオメトリを取得した後、この記事の目的は、物理ベース レンダリング (PBR) マテリアル モデルを使用して 3D オブジェクトの外観を計算することです。材料モデルには、拡散項 について、 このうち、 は、 # # テキストを 2D と 3D に生成する際のドメイン ギャップによって引き起こされる最適ではない 3D 結果の生成の問題を解決するために、X-Dreamer はカメラ ガイダンスに基づく低ランク適応方法を提案しました。
図 3 カメラ誘導 CG-LoRA の図。 具体的には、テキスト プロンプト ここで、 ##このうち、 は、テンソルの形状を から ここで、 は事前学習済み SD の凍結パラメータを表します。モデル、 再表現する必要があるのは、アテンション マスク アラインメント損失 (AMA 損失) SD は前です。 - 前景要素と背景要素の両方を考慮して 2D 画像を生成するようにトレーニングされています。ただし、テキストから 3D への生成では、前景オブジェクトの生成にさらに注意を払う必要があります。この要件を考慮して、X-Dreamer は、SD のアテンション マップを 3D オブジェクトのレンダリングされたマスク イメージと位置合わせするためのアテンション マスク アライメント ロス (AMA ロス) を提案します。具体的には、このメソッドは、事前トレーニングされた SD の各アテンション レイヤーに対して、クエリ画像特徴 このうち、 ソフトマックス関数はアテンション マップ値の正規化に使用されるため、画像特徴の解像度が高い場合、アテンション マップ内のアクティベーション値が非常に小さくなる可能性があります。ただし、レンダリングされた 3D オブジェクト マスクの各要素が 0 または 1 のバイナリ値であることを考慮すると、アテンション マップをレンダリングされた 3D オブジェクトのマスクと直接位置合わせすることは最適ではありません。この問題を解決するために、論文ではアテンション マップの値を (0, 1) の間にマッピングする正規化手法を提案しています。この正規化プロセスの式は次のとおりです。 この論文では、4 つの Nvidia RTX 3090 GPU と PyTorch ライブラリを使用して実験を実施しています。 SDS 損失を計算するために、ハギング フェイス ディフューザーによって実装された安定拡散モデルが利用されました。 DMTET エンコーダとマテリアル エンコーダの場合、それぞれ 2 層 MLP と 1 層 MLP として実装され、隠れ層の次元は 32 です。 楕円体から開始してテキストを 3D に生成する 紙のプレゼンテーション テキスト -初期幾何学的形状として楕円体を使用した X-Dreamer の to-3D 生成結果を図 4 に示します。この結果は、入力テキスト プロンプトに正確に対応する、高品質でフォトリアリスティックな 3D オブジェクトを生成する X-Dreamer の能力を示しています。 #図 4 では、楕円体を開始点として使用して text-to-3D を生成しています ##粗粒メッシュからテキストから 3D への生成を開始 多数の粗粒メッシュをインターネットからダウンロードできますが、 , これらのメッシュを直接使用して 3D コンテンツを作成すると、幾何学的な詳細が不足するため、パフォーマンスが低下することがよくあります。ただし、これらのメッシュは、3D 楕円体よりも優れた 3D 形状の事前情報を X-Dreamer に提供できます。 したがって、楕円体の代わりに粗粒ガイド グリッドを使用して DMTET を初期化することも可能です。図 5 に示すように、X-Dreamer は、提供された粗粒メッシュに詳細が欠けている場合でも、指定されたテキストに基づいて正確な幾何学的詳細を持つ 3D アセットを生成できます。 図 5 粗粒メッシュから開始される Text-to-3D 生成。 書き直す必要がある内容は次のとおりです: 定性的比較。 X の有効性を評価するため。 -Dreamer、この論文では、図 6 に示すように、DreamFusion [4]、Magic3D [8]、Fantasia3D [7]、および ProlificDreamer [11] の 4 つの先進的な手法と比較しています。 SDS ベースの方法 [4、7、8] と比較すると、X-Dreamer は高品質でリアルな 3D アセットの生成において優れています。さらに、X-Dreamer は、VSD ベースの方法 [11] と比較して、同等またはそれ以上の視覚効果を持つ 3D コンテンツを生成し、必要な最適化時間を大幅に短縮します。具体的には、ジオメトリと外観の学習プロセスにかかる時間は、ProlificDreamer では 8 時間以上であるのに対し、X-Dreamer ではわずか約 27 分です。 図 6 最先端 (SOTA) 手法との比較。 #書き直す必要がある内容は次のとおりです: アブレーション実験 CG-LoRA と AMA 損失の機能をより深く理解するために、この論文では、各モジュールを個別に追加して評価するアブレーション研究を実施しました。その影響。図 7 に示すように、アブレーションの結果は、CG-LoRA が X-Dreamer から除外されると、生成された 3D オブジェクトの形状と外観の品質が大幅に低下することを示しています。 さらに、X-Dreamer の AMA 損失も、結果として得られる 3D アセットのジオメトリと外観の忠実性に悪影響を及ぼします。これらは書き直す必要があります。アブレーション実験は、生成された 3D オブジェクトの形状、外観、全体的な品質の向上における CG-LoRA および AMA 損失の個々の寄与についての貴重な調査を提供します。 図 7 X-Dreamer のアブレーション研究。 AMA 損失を導入する目的は、ノイズを減らすことです。ノイズ除去プロセスでは、前景のオブジェクトに注目が集まります。これは、SD のアテンション マップを 3D オブジェクトのレンダリング マスクと位置合わせすることによって実現されます。この目標を達成する際の AMA 損失の有効性を評価するために、この論文では、幾何学学習段階と外観学習段階それぞれで AMA 損失がある場合とない場合の SD のアテンション マップを比較します。 AMA 損失を追加すると、生成された 3D アセットのジオメトリと外観が改善されるだけでなく、SD が特に前景オブジェクト領域に注意を集中できるようになることがわかります。視覚化の結果は、SD の注意を誘導する際の AMA 損失の有効性を確認し、それによってジオメトリと外観の学習段階と前景オブジェクトの焦点合わせの品質を向上させます この研究では、次のことを紹介します。 X-Dreamer と呼ばれる画期的なフレームワークは、テキストから 2D への生成とテキストから 3D への生成の間の領域のギャップに対処することで、テキストから 3D への生成を強化することを目的としています。この目標を達成するために、この論文ではまず CG-LoRA を提案します。これは、3 次元の関連情報 (方向を認識するテキストやカメラのパラメーターを含む) を事前にトレーニングされた安定拡散 (SD) モデルに組み込むモジュールです。そうすることで、この論文は 3 次元領域に関連する情報を効果的に捉えることができます。さらに、この論文では、SD で生成されたアテンション マップを 3D オブジェクトのレンダリング マスクと位置合わせするための AMA 損失を設計します。 AMA 損失の主な目的は、前景オブジェクトの生成に向けて、テキストの焦点を 3D モデルに誘導することです。この論文では、広範な実験を通じて、提案された方法の有効性を包括的に評価し、X-Dreamer が指定されたテキスト プロンプトに基づいて高品質でリアルな 3D コンテンツを生成できることを実証します。
メソッド

 を使用して 3D 表現にパラメータ化されます。幾何モデリングの安定性を高めるために、この記事では DMTET の初期構成として 3D 楕円体を使用します。この論文では、四面体メッシュ
を使用して 3D 表現にパラメータ化されます。幾何モデリングの安定性を高めるために、この記事では DMTET の初期構成として 3D 楕円体を使用します。この論文では、四面体メッシュ  に属する各頂点
に属する各頂点 
 について、SDF 値
について、SDF 値  と変形バイアス シフト量 # という 2 つの重要な量を予測するために
と変形バイアス シフト量 # という 2 つの重要な量を予測するために  をトレーニングします。 。
をトレーニングします。 。  を楕円体に初期化するために、この記事では、楕円体内に均等に分散された N 個の点をサンプリングし、対応する SDF 値
を楕円体に初期化するために、この記事では、楕円体内に均等に分散された N 個の点をサンプリングし、対応する SDF 値  を計算します。その後、平均二乗誤差 (MSE) 損失を使用して
を計算します。その後、平均二乗誤差 (MSE) 損失を使用して  を最適化します。この最適化プロセスにより、 は DMTET を効率的に初期化し、3D 楕円体に似せることができます。 MSE 損失の計算式は次のとおりです。
を最適化します。この最適化プロセスにより、 は DMTET を効率的に初期化し、3D 楕円体に似せることができます。 MSE 損失の計算式は次のとおりです。 

 のパラメーターが、次のように定義される SDS 損失を使用して更新されます。
のパラメーターが、次のように定義される SDS 損失を使用して更新されます。 

 は与えられたノイズにおける SD の値を表します。レベル t とテキスト埋め込み y ケースの SD の予測ノイズ。さらに、
は与えられたノイズにおける SD の値を表します。レベル t とテキスト埋め込み y ケースの SD の予測ノイズ。さらに、 (
( は正規分布からサンプリングされたノイズを表します)。
は正規分布からサンプリングされたノイズを表します)。 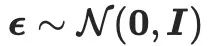 、
、 、および
、および  の実装は、DreamFusion [4] に基づいています。
の実装は、DreamFusion [4] に基づいています。  # さらに、SD を前景オブジェクトの生成に集中させるために、X-Dreamer は次のようにオブジェクト マスクを SD のアテンション マップに合わせるために追加の AMA 損失を導入します。
# さらに、SD を前景オブジェクトの生成に集中させるために、X-Dreamer は次のようにオブジェクト マスクを SD のアテンション マップに合わせるために追加の AMA 損失を導入します。  は注目層の数を表します。
は注目層の数を表します。  は、レンダリングされた 3D オブジェクト マスクのサイズを調整して、そのサイズがアテンション マップのサイズと一致するようにするために使用されます。
は、レンダリングされた 3D オブジェクト マスクのサイズを調整して、そのサイズがアテンション マップのサイズと一致するようにするために使用されます。 
 外観学習 (外観学習
外観学習 (外観学習 、粗さおよび金属項
、粗さおよび金属項  、法線変化項
、法線変化項  が含まれます。ジオメトリの表面上の任意の点
が含まれます。ジオメトリの表面上の任意の点 
 でパラメータ化された多層パーセプトロン (MLP) を使用して、次のように表現できる 3 つの物質項を取得します。 :
でパラメータ化された多層パーセプトロン (MLP) を使用して、次のように表現できる 3 つの物質項を取得します。 : 
 はハッシュ グリッド技術を使用した位置エンコードを表します。その後、レンダリングされたイメージの各ピクセルは、次の式を使用して計算できます。
はハッシュ グリッド技術を使用した位置エンコードを表します。その後、レンダリングされたイメージの各ピクセルは、次の式を使用して計算できます。 
 方向から描画された 3D オブジェクトの表面上の点
方向から描画された 3D オブジェクトの表面上の点  のピクセル値を表します。
のピクセル値を表します。  は、条件
は、条件  を満たす入射方向
を満たす入射方向  のセットによって定義される半球を表します。ここで、 は入射方向
のセットによって定義される半球を表します。ここで、 は入射方向  ## を表します。
## を表します。  # 点 におけるサーフェス法線を表します。
# 点 におけるサーフェス法線を表します。 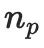
 は既製の環境マップからの入射光に対応し、
は既製の環境マップからの入射光に対応し、 # はマテリアル特性に関連する双方向反射分布関数 (つまり ##) #) (BRDF)。レンダリングされたすべてのピクセルの色を集約すると、レンダリング イメージ
# はマテリアル特性に関連する双方向反射分布関数 (つまり ##) #) (BRDF)。レンダリングされたすべてのピクセルの色を集約すると、レンダリング イメージ  が得られます。ジオメトリ学習ステージと同様に、レンダリングされたイメージ
が得られます。ジオメトリ学習ステージと同様に、レンダリングされたイメージ  が SD に供給され、SDS 損失と AMA 損失を使用して が最適化されます。
が SD に供給され、SDS 損失と AMA 損失を使用して が最適化されます。 
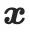

 とカメラ パラメーター
とカメラ パラメーター  が与えられた場合、まず事前にトレーニングされたテキスト CLIP エンコーダー
が与えられた場合、まず事前にトレーニングされたテキスト CLIP エンコーダー  とトレーニング可能な MLP を使用します。
とトレーニング可能な MLP を使用します。  、これらの入力を特徴空間に投影します:
、これらの入力を特徴空間に投影します: 
 と
と 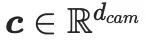 はそれぞれテキスト機能とカメラ機能です。その後、2 つの低ランク行列を使用して
はそれぞれテキスト機能とカメラ機能です。その後、2 つの低ランク行列を使用して  と
と  を CG-LoRA のトレーニング可能な次元削減行列に射影します。
を CG-LoRA のトレーニング可能な次元削減行列に射影します。 
 と
と  は CG-LoRA の 2 次元削減行列です。関数
は CG-LoRA の 2 次元削減行列です。関数 
 に変換するために使用されます。
に変換するために使用されます。 

 と
と  は 2 つの低ランク行列です。したがって、これらを 2 つの行列の積に分解して、実装でトレーニング可能なパラメータを減らすことができます (例:
は 2 つの低ランク行列です。したがって、これらを 2 つの行列の積に分解して、実装でトレーニング可能なパラメータを減らすことができます (例:  ;
;  、ここで
、ここで  #) ##,
#) ##,  ,
,  ,
, 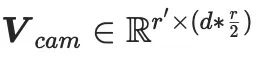 ,
, は小さな数字です (例: 4)。 LoRA の構成に従って、次元拡張行列
は小さな数字です (例: 4)。 LoRA の構成に従って、次元拡張行列  はゼロに初期化され、モデルが SD の事前トレーニングされたパラメーターを使用してトレーニングを開始するようになります。したがって、CG-LoRA のフィードフォワード プロセス式は次のとおりです。
はゼロに初期化され、モデルが SD の事前トレーニングされたパラメーターを使用してトレーニングを開始するようになります。したがって、CG-LoRA のフィードフォワード プロセス式は次のとおりです。 
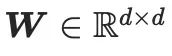
 はカスケード操作です。この方法の実装では、CG-LoRA が SD のアテンション モジュールの線形埋め込み層に統合され、方向とカメラの情報を効果的にキャプチャします。
はカスケード操作です。この方法の実装では、CG-LoRA が SD のアテンション モジュールの線形埋め込み層に統合され、方向とカメラの情報を効果的にキャプチャします。  と主要な CLS ラベル特徴
と主要な CLS ラベル特徴  を使用してアテンション マップを計算します。次のように計算されます:
を使用してアテンション マップを計算します。次のように計算されます:
 はマルチヘッド アテンション メカニズムのヘッドの数を表し、
はマルチヘッド アテンション メカニズムのヘッドの数を表し、 はアテンション マップを表し、その後、すべてのヘッド アテンション メカニズムを表します。アテンションヘッド アテンションマップ
はアテンション マップを表し、その後、すべてのヘッド アテンション メカニズムを表します。アテンションヘッド アテンションマップ  のアテンション値を平均して、全体のアテンション マップ
のアテンション値を平均して、全体のアテンション マップ  の値を計算します。
の値を計算します。 
 ここで、 は小さな定数値 (
ここで、 は小さな定数値 ( # など) を表します。 ##) 分母に 0 が表示されないようにします。最後に、AMA 損失を使用して、すべてのアテンション レイヤーのアテンション マップを 3D オブジェクトのレンダリングされたマスクに位置合わせします。
# など) を表します。 ##) 分母に 0 が表示されないようにします。最後に、AMA 損失を使用して、すべてのアテンション レイヤーのアテンション マップを 3D オブジェクトのレンダリングされたマスクに位置合わせします。 実験結果





以上がX-Dreamer は次元の壁を突破し、2D 生成と 3D 生成の分野を統合し、高品質のテキストを 3D 生成にもたらします。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。