これは、著者のセバスチャン・ラシュカが何百もの実験を経て得た経験であり、一読の価値があります。
データとモデル パラメーターの量を増やすことが、ニューラル ネットワークのパフォーマンスを向上させる最も直接的な方法であると認識されています。現在、主流の大規模モデルのパラメータ数は数千億にまで拡大しており、「大規模モデル」の大型化傾向はますます激しくなるでしょう。 この傾向は、多くのコンピューティング能力の課題を引き起こしています。数千億のパラメータを持つ大規模な言語モデルを微調整したい場合、トレーニングに時間がかかるだけでなく、大量の高性能メモリ リソースも必要になります。 大規模モデルの微調整コストを「下げる」ために、Microsoft の研究者は低ランク適応 (LoRA) テクノロジを開発しました。 LoRA の繊細さは、元の大型モデルに取り外し可能なプラグインを追加することに相当し、モデル本体は変更されないことです。 LoRA はプラグアンドプレイで軽量で便利です。 LoRA は最も広く使用されている方法の 1 つであり、大規模な言語モデルのカスタマイズされたバージョンを効率的に微調整するための最も効果的な方法の 1 つです。 オープンソース LLM に興味がある場合、LoRA は学ぶ価値のある基本テクノロジーであり、見逃せないものです。 ウィスコンシン大学マディソン校のデータ サイエンス教授である Sebastian Raschka 氏も、LoRA をあらゆる側面から研究しました。長年機械学習の分野を研究してきた彼は、複雑な技術概念を解明することに非常に熱心に取り組んでいます。何百もの実験を行った後、Sebastian Raschka は、LoRA を使用して大規模モデルを微調整した経験をまとめ、雑誌「Ahead of AI」に発表しました。 
著者の当初の意図を維持することに基づいて、このサイトはこの記事をまとめました: 先月、私は主に以下に基づいて LoRA 実験に関する記事を共有しました。私と同僚が Lightning AI で管理しているオープンソースの Lit-GPT ライブラリについて、私の実験から学んだ主な経験と教訓について話し合います。さらに、LoRA テクノロジーに関連するよくある質問にもお答えします。カスタムの大規模言語モデルの微調整に興味がある場合、これらの洞察がすぐに始めるのに役立つことを願っています。 つまり、この記事で説明する主なポイントは次のとおりです。
- ただしLLM トレーニング (または GPU でトレーニングされたすべてのモデル) にはランダム性が避けられませんが、複数 LUN トレーニングの結果は依然として非常に一貫しています。
- QLoRA は、GPU メモリの制限がある場合に、コスト効率の高い妥協点を提供します。実行時間は 39% 増加しますが、メモリは 33% 節約されます。
- LLM を微調整する場合、オプティマイザーの選択は結果に影響を与える主な要素ではありません。 AdamW、SGD とスケジューラ、または AdamW とスケジューラのいずれであっても、結果への影響は最小限です。
- Adam はモデル パラメーターごとに 2 つの新しいパラメーターを導入するため、メモリを大量に消費するオプティマイザーであると考えられていますが、これは LLM ニーズのピーク メモリに大きな影響を与えません。これは、メモリの大部分が追加のパラメータを保持するのではなく、大きな行列の乗算に割り当てられるためです。
- 静的データセットの場合、複数ラウンドのトレーニングなどの複数回の反復はうまく機能しない可能性があります。これは多くの場合、過剰学習につながり、トレーニング結果の悪化につながります。
- LoRA を組み込む場合は、モデルのパフォーマンスを最大化するために、キー マトリックスと値マトリックスだけでなく、すべてのレイヤーに LoRA が適用されていることを確認してください。
- LoRA ランクを調整し、適切な α 値を選択することが重要です。ヒントとして、α 値をランク値の 2 倍に設定してみてください。
- 14 GB の RAM を搭載した単一の GPU を使用すると、最大 70 億のパラメータを使用して大規模なモデルを数時間で効率的に微調整できます。静的データ セットの場合、LLM を「オールラウンド プレイヤー」に強化し、すべてのベースライン タスクで良好なパフォーマンスを発揮することは不可能です。この問題を解決するには、データソースを多様化するか、LoRA 以外のテクノロジーを使用する必要があります。
#また、LoRA に関するよくある質問 10 個にお答えします。
読者の皆様にご興味があれば、LoRA を最初から実装するための詳細なコードを含む、LoRA のより包括的な紹介をもう一度書きます。今日の記事では主に LoRA の使用における重要な問題について説明します。正式に始める前に、いくつかの基本的な知識を追加しましょう。
GPU メモリの制限により、モデルはトレーニングプロセス ウェイトにはコストがかかります。
たとえば、重み行列 W で表される 7B パラメーター言語モデルがあるとします。バックプロパゲーション中、モデルは損失関数値を最小限に抑えるために元の重みを更新することを目的として、ΔW 行列を学習する必要があります。
重みは次のように更新されます: W_updated = W ΔW。
重み行列 W に 7B パラメータが含まれる場合、重み更新行列 ΔW にも 7B パラメータが含まれます。行列 ΔW の計算は非常に多くの計算とメモリを消費します。
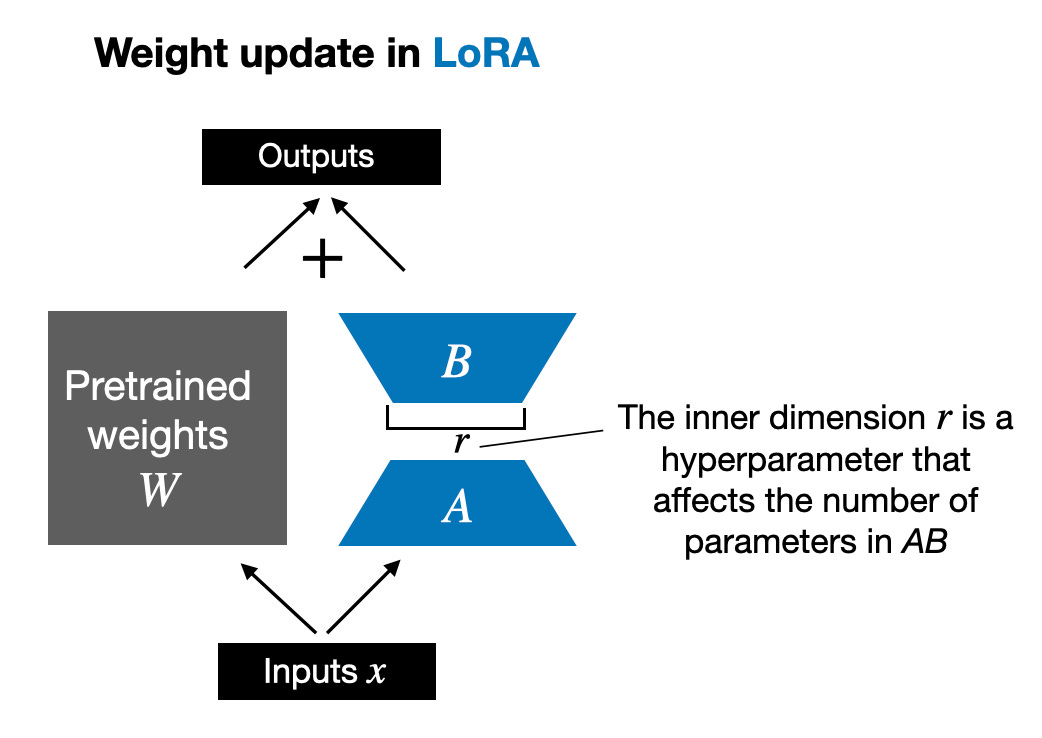
Edward Huらによって提案されたLoRAは、重み変動ΔWの部分を低ランク表現に分解します。具体的には、ΔW を明示的に計算する必要はありません。代わりに、LoRA は、下図に示すように、トレーニング中に ΔW の分解表現を学習します。これが LoRA の計算リソースを節約する秘密です。
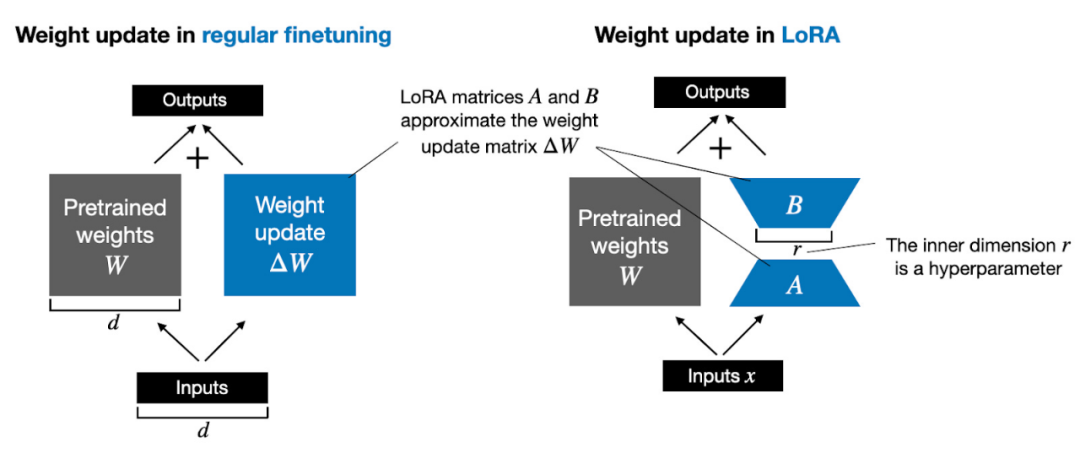 上に示したように、ΔW の分解は、より大きな行列 ΔW を表すために 2 つの小さな LoRA 行列 A および B を使用する必要があることを意味します。 A の行数が ΔW と同じで、B の列数が ΔW と同じである場合、上記の分解は ΔW = AB と書くことができます。 (AB は、行列 A と B の間の行列乗算の結果です。) このアプローチでは、どれくらいのメモリが節約されますか?また、ハイパーパラメータであるランク r にも依存します。たとえば、ΔW に 10,000 行、20,000 列がある場合、200,000,000 個のパラメーターを保存する必要があります。 r=8 で A と B を選択した場合、A には 10,000 行と 8 列があり、B には 8 行と 20,000 列があり、これは 10,000×8 8×20,000 = 240,000 パラメーターであり、200,000,000 パラメーターの約 830 分の 1 です。 もちろん、A と B は ΔW によってカバーされるすべての情報を取得できるわけではありませんが、これは LoRA の設計によって決まります。 LoRA を使用する場合、モデル W は、事前トレーニング データセット内のすべての知識を収集するためのフルランクを持つ大きな行列であると想定します。 LLM を微調整するとき、すべての重みを更新する必要はありませんが、コア情報を取得するために ΔW よりも少ない重みを更新するだけで済みます。これが、AB 行列を通じて低ランク更新が実装される方法です。 LLM または GPU でトレーニングされているものの、ランダム性モデルは避けられませんが、LoRA を使用して複数の実験を実施したところ、LLM の最終ベンチマーク結果は、さまざまなテスト セットで驚くべき一貫性を示しました。これは、他の比較研究を行うための良い基礎となります。
上に示したように、ΔW の分解は、より大きな行列 ΔW を表すために 2 つの小さな LoRA 行列 A および B を使用する必要があることを意味します。 A の行数が ΔW と同じで、B の列数が ΔW と同じである場合、上記の分解は ΔW = AB と書くことができます。 (AB は、行列 A と B の間の行列乗算の結果です。) このアプローチでは、どれくらいのメモリが節約されますか?また、ハイパーパラメータであるランク r にも依存します。たとえば、ΔW に 10,000 行、20,000 列がある場合、200,000,000 個のパラメーターを保存する必要があります。 r=8 で A と B を選択した場合、A には 10,000 行と 8 列があり、B には 8 行と 20,000 列があり、これは 10,000×8 8×20,000 = 240,000 パラメーターであり、200,000,000 パラメーターの約 830 分の 1 です。 もちろん、A と B は ΔW によってカバーされるすべての情報を取得できるわけではありませんが、これは LoRA の設計によって決まります。 LoRA を使用する場合、モデル W は、事前トレーニング データセット内のすべての知識を収集するためのフルランクを持つ大きな行列であると想定します。 LLM を微調整するとき、すべての重みを更新する必要はありませんが、コア情報を取得するために ΔW よりも少ない重みを更新するだけで済みます。これが、AB 行列を通じて低ランク更新が実装される方法です。 LLM または GPU でトレーニングされているものの、ランダム性モデルは避けられませんが、LoRA を使用して複数の実験を実施したところ、LLM の最終ベンチマーク結果は、さまざまなテスト セットで驚くべき一貫性を示しました。これは、他の比較研究を行うための良い基礎となります。
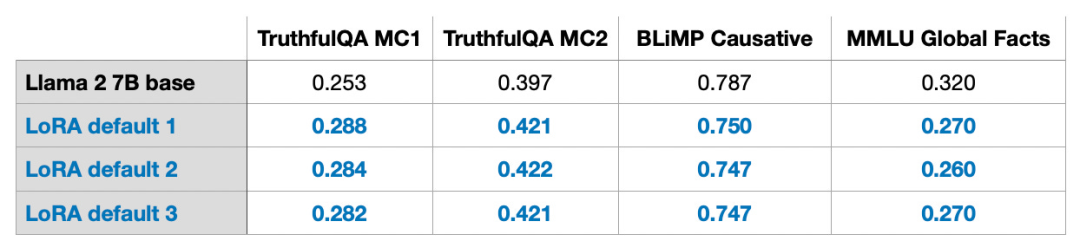
これらの結果は、r=8 という小さな値を使用したデフォルト設定で得られたものであることに注意してください。実験の詳細については、私の他の記事をご覧ください。 # 記事リンク: https://lightning.ai/pages/community/lora-insights/
##QLoRA 計算 - メモリ トレードオフ
QLoRA は、Tim Dettmers らによって提案された Quantitative LoRA の略称です。 QLoRA は、微調整中にメモリ フットプリントをさらに削減するための手法です。バックプロパゲーション中に、QLoRA は事前トレーニングされた重みを 4 ビットに量子化し、ページング オプティマイザーを使用してメモリ ピークを処理します。
LoRA を使用すると、GPU メモリの 33% を節約できることがわかりました。ただし、QLoRA では事前トレーニングされたモデルの重みの量子化と逆量子化が追加されるため、トレーニング時間は 39% 増加します。
#デフォルトの LoRA の精度は 16 ビット浮動小数点です: トレーニング時間: 1.85 時間-
#メモリ使用量: 21.33GB
##QLoRA (4 桁の通常の浮動小数点数)
- メモリ使用量: 14.18GB
さらに、モデルのパフォーマンスにはほとんど影響がないことがわかりました。これは、一般的な GPU メモリのボトルネック問題をさらに解決するために QLoRA を LoRA トレーニングの代替として使用できることを示しています。

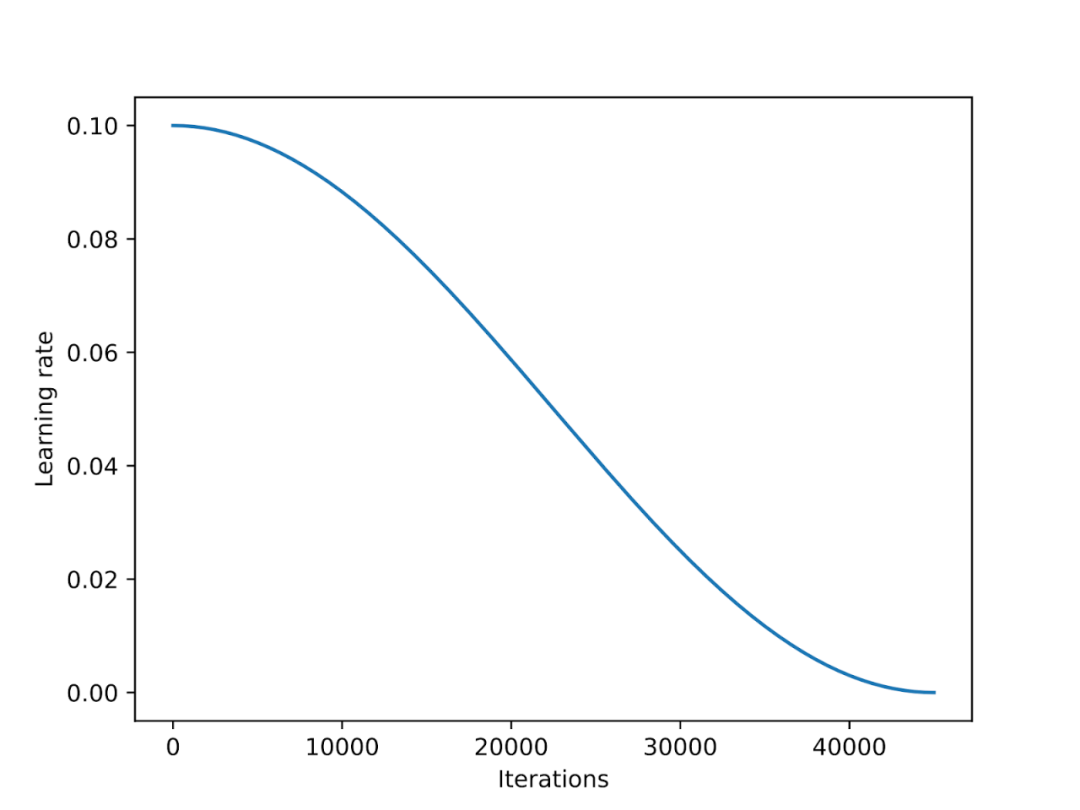
学習率スケジューラはトレーニング全体で使用されます。プロセス 学習率を下げてモデルの収束を最適化し、過剰な損失値を回避します。 コサイン アニーリングは、コサイン曲線に従って学習率を調整するスケジューラです。高い学習率から始まり、その後滑らかに減少し、コサインのようなパターンで徐々に 0 に近づきます。コサイン アニーリングの一般的なバリアントは半周期バリアントです。下の図に示すように、トレーニング中にコサイン サイクルの半分だけが完了します。
実験では、LoRA 微調整スクリプトにコサイン アニーリング スケジューラを追加しました。これにより、SGD のパフォーマンスが大幅に向上しました。ただし、Adam および AdamW オプティマイザーに対する利点は小さく、追加後の変化はほとんどありません。
 次のセクションでは、Adam に対する SGD の潜在的な利点について説明します。 Adam オプティマイザーと AdamW オプティマイザーはディープ ラーニングで人気があります。 7B パラメーター モデルをトレーニングしている場合、Adam を使用すると、トレーニング プロセス中に追加の 14B パラメーターを追跡できます。これは、他の条件が変わらない場合にモデルのパラメーター数を 2 倍にすることに相当します。 #SGD はトレーニング中に追加のパラメーターを追跡できません。では、ピーク メモリの点で SGD には Adam に比べてどのような利点があるのでしょうか? 私の実験では、AdamW と LoRA (デフォルト設定 r=8) を使用して 7B パラメーターの Llama 2 モデルをトレーニングするには、14.18 GB の GPU メモリが必要でした。 SGD を使用して同じモデルをトレーニングするには、14.15 GB の GPU メモリが必要です。 AdamW と比較すると、SGD は 0.03 GB のメモリを節約するだけであり、その効果は無視できます。 #なぜメモリをこれだけ節約できるのでしょうか?これは、LoRA を使用する際に、LoRA によってモデル内のパラメーターの数が大幅に削減されたためです。たとえば、r=8 の場合、7B の Llama 2 モデルの 6,738,415,616 個のパラメーターのうち、トレーニング可能な LoRA パラメーターは 4,194,304 個のみです。 数字だけ見ると、4,194,304 個のパラメーターはまだ多いように見えますが、実際には、これらの多くのパラメーターが占有するのは、4,194,304 × 2 × 16 ビット = 134.22 メガビット = 16.78 メガバイトだけです。 (オプティマイザー状態の保存とコピーにおける追加のオーバーヘッドにより、0.03 Gb = 30 Mb の差が観察されました。) 2 は Adam によって保存された追加パラメーターの数を表し、16 ビットはモデルの重みのデフォルトの精度を表します。
次のセクションでは、Adam に対する SGD の潜在的な利点について説明します。 Adam オプティマイザーと AdamW オプティマイザーはディープ ラーニングで人気があります。 7B パラメーター モデルをトレーニングしている場合、Adam を使用すると、トレーニング プロセス中に追加の 14B パラメーターを追跡できます。これは、他の条件が変わらない場合にモデルのパラメーター数を 2 倍にすることに相当します。 #SGD はトレーニング中に追加のパラメーターを追跡できません。では、ピーク メモリの点で SGD には Adam に比べてどのような利点があるのでしょうか? 私の実験では、AdamW と LoRA (デフォルト設定 r=8) を使用して 7B パラメーターの Llama 2 モデルをトレーニングするには、14.18 GB の GPU メモリが必要でした。 SGD を使用して同じモデルをトレーニングするには、14.15 GB の GPU メモリが必要です。 AdamW と比較すると、SGD は 0.03 GB のメモリを節約するだけであり、その効果は無視できます。 #なぜメモリをこれだけ節約できるのでしょうか?これは、LoRA を使用する際に、LoRA によってモデル内のパラメーターの数が大幅に削減されたためです。たとえば、r=8 の場合、7B の Llama 2 モデルの 6,738,415,616 個のパラメーターのうち、トレーニング可能な LoRA パラメーターは 4,194,304 個のみです。 数字だけ見ると、4,194,304 個のパラメーターはまだ多いように見えますが、実際には、これらの多くのパラメーターが占有するのは、4,194,304 × 2 × 16 ビット = 134.22 メガビット = 16.78 メガバイトだけです。 (オプティマイザー状態の保存とコピーにおける追加のオーバーヘッドにより、0.03 Gb = 30 Mb の差が観察されました。) 2 は Adam によって保存された追加パラメーターの数を表し、16 ビットはモデルの重みのデフォルトの精度を表します。
 #LoRA マトリックスの r を 8 から 256 に拡張すると、AdamW と比較した SGD の利点が現れます。
#LoRA マトリックスの r を 8 から 256 に拡張すると、AdamW と比較した SGD の利点が現れます。
##AdamW を使用すると 17.86 GB のメモリが占有されますSGD を使用すると 14.46 GB のメモリが占有されます
##したがって、行列のサイズが増加すると、SGD によって節約されたメモリが重要な役割を果たします。 SGD は追加のオプティマイザーパラメータを保存する必要がないため、大規模なモデルを処理するときに、Adam などの他のオプティマイザーよりも多くのメモリを節約できます。これは、メモリが限られているトレーニング タスクにとって非常に重要な利点です。
従来の深層学習では、トレーニング セットでトレーニングすることがよくあります。複数の反復が実行され、各反復はエポックと呼ばれます。たとえば、畳み込みニューラル ネットワークをトレーニングする場合、通常は数百エポックにわたって実行します。では、複数ラウンドの反復トレーニングも指導の微調整に影響を与えるのでしょうか?
答えは「ノー」です。50,000 個の Alpaca サンプル命令微調整データセットの反復回数を 2 倍にすると、モデルのパフォーマンスが低下しました。
したがって、複数ラウンドの反復は命令の微調整に役立たない可能性があると結論付けました。 1k サンプル LIMA 命令微調整セットでも同じ動作が観察されました。モデルのパフォーマンスの低下は過剰適合によって引き起こされる可能性があり、具体的な理由についてはさらに調査する必要があります。

次の表は、LoRA がどのようにのみ使用されるかを示しています。選択した行列 (つまり、各 Transformer のキーと値の行列) が機能する実験の場合。さらに、クエリ重み行列、投影層、マルチヘッド アテンション モジュール間のその他の線形層、および出力層で LoRA を有効にすることができます。
これらの追加レイヤーの上に LoRA を追加すると、7B の Llama 2 モデルでは、トレーニング可能なパラメーターの数が 4,194,304 から 20,277,248 に 5 倍に増加します。 LoRA をより多くのレイヤーに適用すると、モデルのパフォーマンスが大幅に向上しますが、より多くのメモリ スペースも必要になります。

さらに、(1) クエリと重み行列のみを有効にした LoRA、および (2) すべてのレイヤーを有効にした LoRA の 2 つの設定のみを調査しました。 LoRA をより多くのレイヤーと組み合わせて使用することは、さらに研究する価値があります。投影層で LoRA を使用することがトレーニング結果にとって有益であるかどうかを知ることができれば、モデルをより適切に最適化し、パフォーマンスを向上させることができます。
バランスの取れた LoRA ハイパーパラメータ: R および AlphaLoRA を提案した論文で述べられているように、LoRA では追加のスケーリング係数が導入されています。この係数は、順伝播中に LoRA 重みを事前トレーニングに適用するために使用されます。この拡張には、前に説明したランク パラメーター r と、次のように適用される別のハイパーパラメーター α (アルファ) が含まれます。 
上記の式に示されているように、LoRA重み 値が大きいほど、影響が大きくなります。 前の実験では、パラメーター r=8、alpha=16 を使用しました。これにより、2 倍の拡張が行われました。 LoRA を使用して大型モデルの重量を軽減する場合、α を r の 2 倍に設定するのが一般的な経験則です。しかし、r の値が大きくなってもこのルールが依然として当てはまるかどうかは興味深いです。 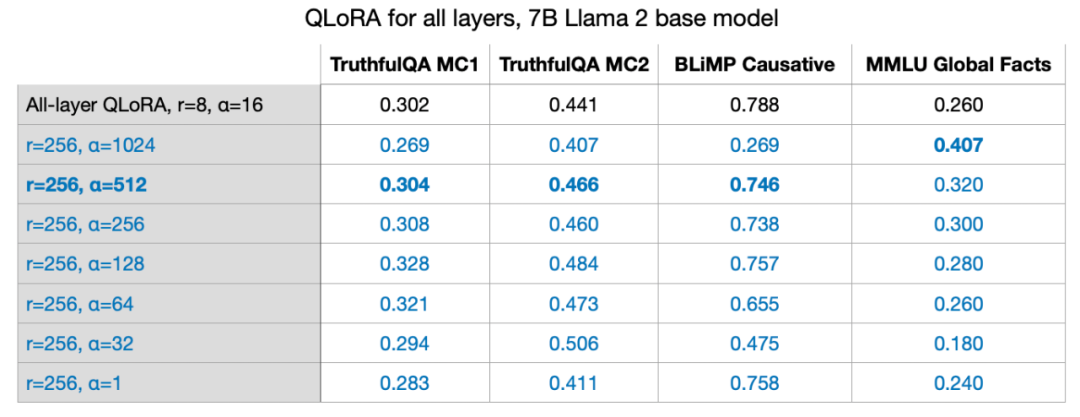
r=32、r=64、r=128、および r=512 も試しましたが、わかりやすくするためにこのプロセスを省略しましたが、 r=256 の場合、確かに最高の効果。実際、alpha=2r を選択すると最適な結果が得られます。 単一 GPU で 7B パラメータ モデルをトレーニングするLoRA を使用すると、次のことが可能になります。単一 GPU 上の 7B パラメーター モデル 7B パラメーター スケールで大規模な言語モデルを微調整します。この特定のケースでは、AdamW オプティマイザーを使用して 17.86 GB (50,000 のトレーニング サンプル) のデータを処理するのに、QLoRA の最適な設定 (r=256、alpha=512) を使用した A100 で約 3 時間かかりました (ここでは Alpaca データセット)。 
この記事の残りの部分では、その他の質問にお答えします。
#データセットは非常に重要です。 50,000 個のトレーニング サンプルを含む Alpaca データセットを使用しています。人気があるのでアルパカを選びました。この記事はすでに非常に長いため、その他のデータセットのテスト結果についてはこの記事では説明しません。
#Alpaca は合成データセットであり、今日の標準からすると少し時代遅れになる可能性があります。データの品質は非常に重要です。たとえば、6 月に私は、わずか 1,000 の例で構成される厳選されたデータセットである LIMA データセットについて説明する投稿を書きました。 #記事リンク: https://magazine.sebastianraschka.com/p/ahead-of-ai-9-llm-tuning-and-dataset
LIMA を提案した論文のタイトルにあるように、「整列のためには、少ない方が良い。LIMA のデータ量は Alpaca よりも少ないですが、65B Llama モデルはベースに微調整されています」 LIMA での結果は Alpaca よりも優れています。同じ構成 (r=256、alpha=512) を使用して、LIMA 上で 50 倍のデータを持つ Alpaca と同様のモデル パフォーマンスを取得しました。
#Q2: LoRA はドメイン適応に適していますか?
#この質問に対する明確な答えはまだありません。経験則として、知識は通常、トレーニング前のデータセットから抽出されます。通常、言語モデルは事前トレーニング データセットから知識を吸収し、命令の微調整の役割は主に、LLM が命令によりよく従うのを支援することです。 コンピューティング能力は大規模な言語モデルのトレーニングを制限する重要な要素であるため、LoRA を使用して特定のフィールドのデータセットを特化し、既存の事前トレーニングをさらに行うこともできます。トレーニングされたモデル。LLM のトレーニング。 また、私の実験には 2 つの算術ベンチマークが含まれていることにも注目してください。どちらのベンチマークでも、LoRA で微調整されたモデルのパフォーマンスは、事前トレーニングされたベース モデルよりも大幅に低下しました。これは、Alpaca データセットに対応する算術例が不足しておらず、モデルが算術知識を「忘れて」しまうためではないかと私は推測しています。モデルが算術知識を「忘れた」のか、それとも対応する命令に応答しなくなったのかを判断するには、さらなる研究が必要です。ただし、ここで 1 つの結論を導き出すことができます。「LLM を微調整するときは、関心のある各タスクの例をデータ セットに含めるのが得策です。」 #Q3: 最適な r 値を決定するにはどうすればよいですか?
# 現在、この問題に対するこれより良い解決策はありません。最適な r 値を決定するには、各 LLM および各データセットの特定の状況に基づいて、特定の問題を具体的に分析する必要があります。 r の値が大きすぎると過学習が発生し、r の値が小さすぎるとデータセット内の多様なタスクを捕捉できない可能性があると推測しています。データセットに含まれるタスクの種類が増えるほど、必要な r 値も大きくなると思います。たとえば、モデルが基本的な 2 桁の算術演算のみを実行する必要がある場合は、小さな値の r で十分な場合があります。ただし、これは私の仮説にすぎず、検証するにはさらなる研究が必要です。 #Q4: LoRA はすべてのレイヤーで有効にする必要がありますか?
今回は 2 つの設定のみを調査しました: (1) クエリと重み行列のみを有効にした LoRA、および (2) すべてのレイヤーを有効にした LoRA。 LoRA をより多くのレイヤーと組み合わせて使用する場合の効果については、さらに研究する価値があります。投影層で LoRA を使用することがトレーニング結果にとって有益であるかどうかを知ることができれば、モデルをより適切に最適化し、パフォーマンスを向上させることができます。 さまざまな設定 (lora_query、lora_key、lora_value、lora_projection、lora_mlp、lora_head) を考慮すると、検討すべき組み合わせは 64 通りあります。 #Q5: 過学習を避けるにはどうすればよいですか? 一般的に、r がトレーニング可能なパラメータの数を決定するため、r が大きいほど過学習が発生する可能性が高くなります。モデルが過学習している場合は、まず r 値を下げるか、データ セット サイズを増やすことを検討してください。さらに、AdamW または SGD オプティマイザーの重み減衰率を増やしたり、LoRA レイヤーのドロップアウト値を増やしたりしてみることもできます。
私は実験で LoRA のドロップアウト パラメータを調査していません (固定ドロップアウト率 0.05 を使用しました) LoRA のドロップアウト パラメータも研究する価値のある問題です。 #Q6: 他に選択できるオプティマイザーはありますか? 今年 5 月にリリースされた Sophia は、試してみる価値があります。Sophia は、言語モデルの事前トレーニング用のスケーラブルな確率的 2 次オプティマイザーです。次の論文「Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training」によると、Sophia は Adam と比較して 2 倍高速で、より優れたパフォーマンスを達成できます。つまり、Sophia は Adam と同様に、勾配の分散ではなく勾配の曲率を介して正規化を実装します。 論文リンク: https://arxiv.org/abs/2305.14342Q7: まだメモリ使用量に影響を与える他の要因はありますか? #精度と量子化設定、モデル サイズ、バッチ サイズ、トレーニング可能な LoRA パラメーターの数に加えて、データセットはメモリ使用量にも影響します。 Llama 2 のブロック サイズは 4048 トークンです。これは、Llama が一度に 4048 トークンを含むシーケンスを処理できることを意味します。後続のトークンにマスクが追加されると、トレーニング シーケンスが短くなり、多くのメモリを節約できます。たとえば、Alpaca データ セットは比較的小さく、最長シーケンス長は 1304 トークンです。 最長シーケンス長の 2048 トークンを持つ他のデータセットを使用しようとすると、メモリ使用量が 17.86 GB から 26.96 GB に跳ね上がります。 Q8: フル微調整や RLHF と比較して、LoRA の利点は何ですか? #RLHF は実験しませんでしたが、フル トリムを試してみました。完全な微調整には少なくとも 2 つの GPU が必要で、それぞれ 36.66 GB を消費し、完了までに 3.5 時間かかりました。ただし、ベースライン テストの結果は良好ではありません。これは、オーバーフィッティングまたは最適ではないパラメーターが原因である可能性があります。 #Q9: LoRA の重みを組み合わせることができますか?
#答えは「はい」です。トレーニング中に、LoRA の重みと事前にトレーニングされた重みを分離し、各前方パスでそれらを結合します。
現実の世界では、複数の LoRA 重みセットを持つアプリケーションがあると仮定します。重みの各セットは、アプリケーションのユーザーに対応します。その後、これらの重みが保存されますディスク容量を節約するためには別途必要です。また、事前トレーニングされた重みと LoRA 重みをトレーニング後に結合して、単一のモデルを作成することもできます。こうすることで、すべての前方パスに LoRA ウェイトを適用する必要がなくなります。 weight += (lora_B @ lora_A) * scaling
上記の方法を使用して重みを更新し、結合された重みを保存できます。
同様に、引き続き多くの LoRA 重みセットを追加できます: weight += (lora_B_set1 @ lora_A_set1) * scaling_set1weight += (lora_B_set2 @ lora_A_set2) * scaling_set2weight += (lora_B_set3 @ lora_A_set3) * scaling_set3...
Iこのアプローチを評価するための実験は行われていませんが、Lit-GPT で提供される scripts/merge_lora.py スクリプトを通じてすでに可能です。 #スクリプト リンク: https://github.com/Lightning-AI/lit-gpt/blob/main/scripts/merge_lora.py
Q10: レイヤーごとの最適なランク適応のパフォーマンスはどのくらいですか? #わかりやすくするために、ディープ ニューラル ネットワークでは通常、各層に同じ学習率を設定します。学習率は最適化する必要があるハイパーパラメータであり、さらに各層に異なる学習率を選択できます (PyTorch では、これはそれほど複雑なことではありません)。
ただし、このアプローチでは追加コストがかかり、ディープ ニューラル ネットワークでは調整できるパラメーターが他にも多数あるため、これが実際に行われることはほとんどありません。異なる層に対して異なる学習率を選択するのと同様に、異なる層に対して異なる LoRA r 値を選択することもできます。私はまだ試していませんが、この方法について詳しく説明したドキュメント「LLM Optimization: Layer-wise Optimal Rank Adaptation (LORA)」があります。理論的には、このアプローチは有望に思え、ハイパーパラメーターを最適化するための多くの余地を提供します。
#論文リンク: https://medium.com/@tom_21755/llm-optimization-layer-wise-optimal-rank-adaptation-lora-1444dfbc8e6a#元のリンク: https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms? continueFlag=0c2e38ff6893fba31f1492d815bf928b
以上が大規模なモデルではグローバルな微調整ができないわけではなく、LoRA の方がコスト効率が高く、チュートリアルが用意されているというだけです。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

