
ホームページ >テクノロジー周辺機器 >AI >写真からビデオが生成され、口を開ける、うなずく、感情、怒り、悲しみ、喜びはすべて入力によって制御できます。
写真からビデオが生成され、口を開ける、うなずく、感情、怒り、悲しみ、喜びはすべて入力によって制御できます。

- 王林転載
- 2023-12-03 11:17:21937ブラウズ
最近、マイクロソフトが実施した調査で、ビデオ処理ソフトウェア PS がいかに柔軟であることが明らかになりました。
この調査では、AI に写真を撮る機能を与えるだけで済みます。 、写真に写っている人物のビデオを生成したり、キャラクターの表情や動きをテキストで制御したりできます。たとえば、「口を開けて」というコマンドを与えると、ビデオ内のキャラクターが実際に口を開きます。

#コマンドが「悲しい」の場合、彼女は悲しい表情と頭の動きをします。
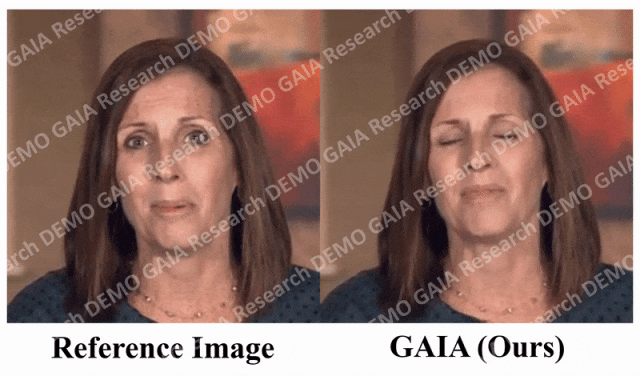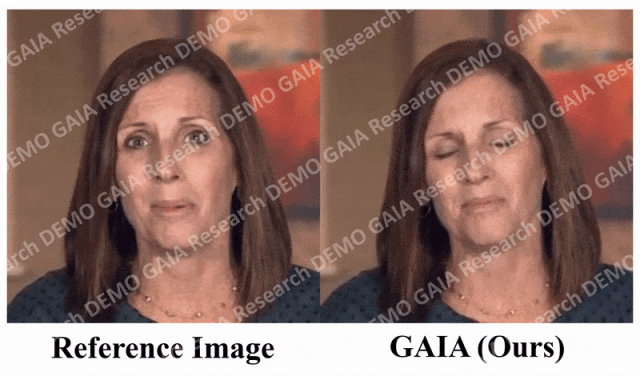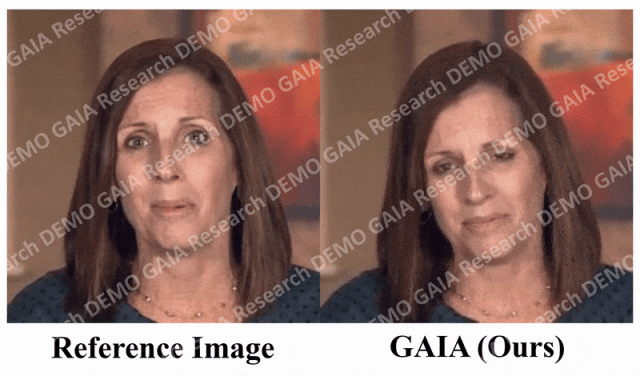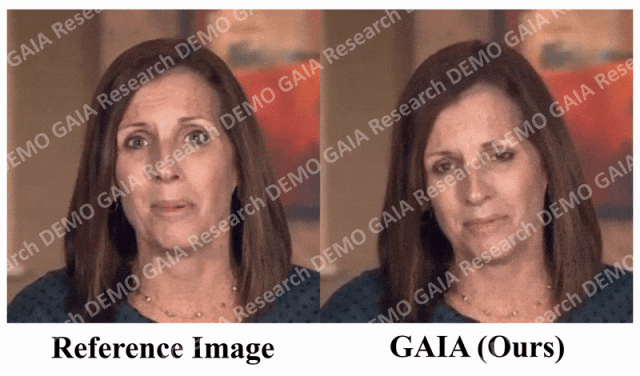
「驚く」コマンドが与えられると、アバターの額の線がぎゅっと絞られます。

さらに、音声を提供して、仮想キャラクターの口の形や動きを音声と同期させることもできます。あるいは、アバターが模倣するライブ ビデオを提供することもできます。
アバターの動きにうなずいたり、振り向いたり、頭を傾けたりするなど、さらにカスタム編集が必要な場合は、この技術もサポートされています

この研究は GAIA (Generative AI for Avatar、アバターのための生成 AI) と呼ばれ、そのデモが広まり始めています。ソーシャルメディア。多くの人がその効果を賞賛し、それを死者の「復活」に利用したいと考えています。
#しかし、これらのテクノロジーの継続的な進化により、オンライン動画の真実と虚偽の区別が難しくなり、利用されにくくなるのではないかと心配する人もいます。犯罪者による詐欺です。今後も不正防止対策は強化されていくようだ。
GAIA にはどのようなイノベーションがありますか?
ゼロサンプル トーキング アバター生成テクノロジーは、音声に基づいて自然なビデオを合成し、生成される口の形、表情、頭の姿勢が音声の内容と一致することを保証することを目的としています。これまでの研究では通常、高品質の結果を達成するために、仮想キャラクターごとに特定のモデルの特定のトレーニングや調整、または推論中にテンプレート ビデオの利用が必要でした。最近、研究者は、ターゲット アバターの肖像画画像を外観基準として使用するだけで、ゼロショット トーキング アバターを生成する方法の設計と改善に焦点を当てています。ただし、これらの方法では通常、ワーピングベースのモーション表現や 3D モーファブル モデル (3DMM) などのドメイン事前分布を使用して、タスクの難易度を軽減します。このようなヒューリスティックは効果的ではありますが、多様性を制限し、不自然な結果につながる可能性があります。したがって、データ配布からの直接学習が今後の研究の焦点です
この記事では、マイクロソフトの研究者が、音声やチラシから学習できる GAIA (Generative AI for Avatar) を提案しました。生成プロセスでドメイン事前要素を排除し、自然に話す仮想キャラクター ビデオに合成されます。

プロジェクト アドレス: https://microsoft.github.io/GAIA/関連プロジェクトの詳細は、このリンクでご覧いただけます
論文リンク: https://arxiv.org/pdf/2311.15230.pdf
#Gaia が 2 つの重要な洞察を明らかにします:#VAE の主な機能は、動きと外観を分解することです。 2 つのエンコーダ (モーション エンコーダとアピアランス エンコーダ) と 1 つのデコーダで構成されます。トレーニング中、モーション エンコーダーへの入力は顔のランドマークの現在のフレームですが、外観エンコーダーへの入力は現在のビデオ クリップ内のランダムにサンプリングされたフレームです。次に、エンコーダの出力が最適化されて、現在のフレームが再構築されます。トレーニングされた VAE が取得されると、すべてのトレーニング データに対して潜在的なアクション (つまり、モーション エンコーダーの出力) が取得されます。 推論プロセスでは、ターゲット アバターの参照ポートレート画像が与えられると、拡散モデルは画像を次のように変換します。入力された音声シーケンスは、音声の内容に適合する運動電位シーケンスを生成するための条件として使用されます。生成されたモーション潜在シーケンスと参照ポートレート画像は、VAE デコーダーを通過して、発話ビデオ出力を合成します。 調査はデータの観点から構成されており、高精細話顔データセット (HDTF) やカジュアル会話データセット v1&v2 (CC v1&v2) など、さまざまなソースからデータセットを収集しました。これら 3 つのデータセットに加えて、この研究では、7,000 時間のビデオと 8,000 のスピーカー ID を含む大規模な内部発話アバター データセットも収集しました。データセットの統計概要を表 1に示します。
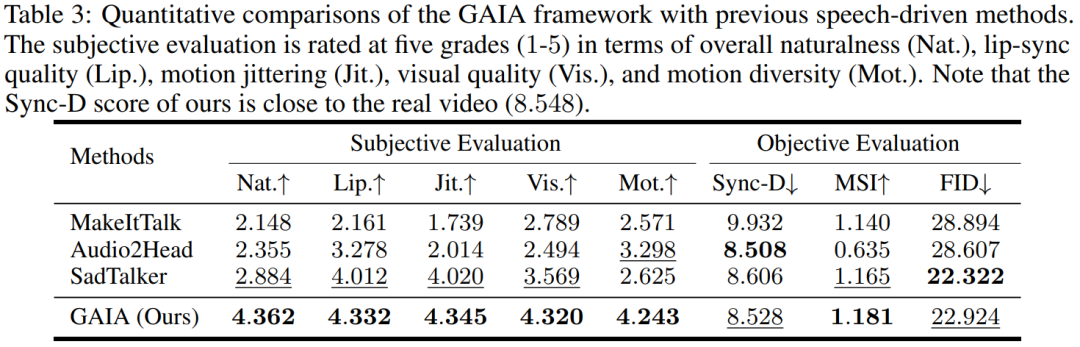
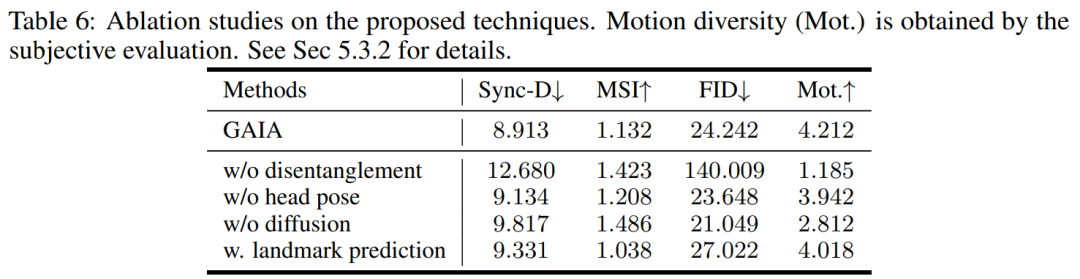
必要な情報を知るために、この記事では、次のような自動フィルタリング戦略をいくつか提案しています。トレーニング データの品質: 唇の動きを見えるようにするには、アバターの正面方向がカメラに向かう必要があります; 唇の動きが音声と一致しない極端なケースを除外するために、アバターが含まれるフレームマスクを着用しているか黙っている場合は削除する必要があります。 GAIA は、制御可能な発話アバターの生成やテキスト コマンドの仮想化キャラクター生成など、さまざまなアプリケーションを可能にする汎用的で柔軟なフレームワークです。 音声主導の結果。音声駆動型の話すアバターの生成は、音声から動きを予測することによって実現されます。表 3 と図 2 は、GAIA と MakeItTalk、Audio2Head、および SadTalker メソッドとの定量的および定性的な比較を示しています。 データから、主観的評価の点で GAIA がすべてのベースライン手法をはるかに上回っていることは明らかです。具体的には、図 2 に示すように、基準画像が目を閉じていたり、頭のポーズが異常であったとしても、ベースライン手法の生成結果は通常、基準画像に大きく依存するのに対し、GAIA はさまざまな基準画像に対して良好なパフォーマンスを示します。堅牢で、より高い自然さ、高いリップシンク、より優れたビジュアル品質、およびモーションの多様性を備えた結果を生成します ##表 3 による、最高の MSI スコアは、GAIA によって生成されたビデオが優れたモーション安定性を持っていることを示します。 Sync-D スコア 8.528 は実際のビデオ スコア (8.548) に近く、生成されたビデオが優れたリップ シンクを備えていることを示しています。この研究では、ベースラインと同等の FID スコアを達成しましたが、表 6 ## で詳しく説明されているように、拡散トレーニングを行わなかったモデルの方がより良い FID スコアを達成したことが研究で判明したため、さまざまな頭のポーズの影響を受ける可能性があります。
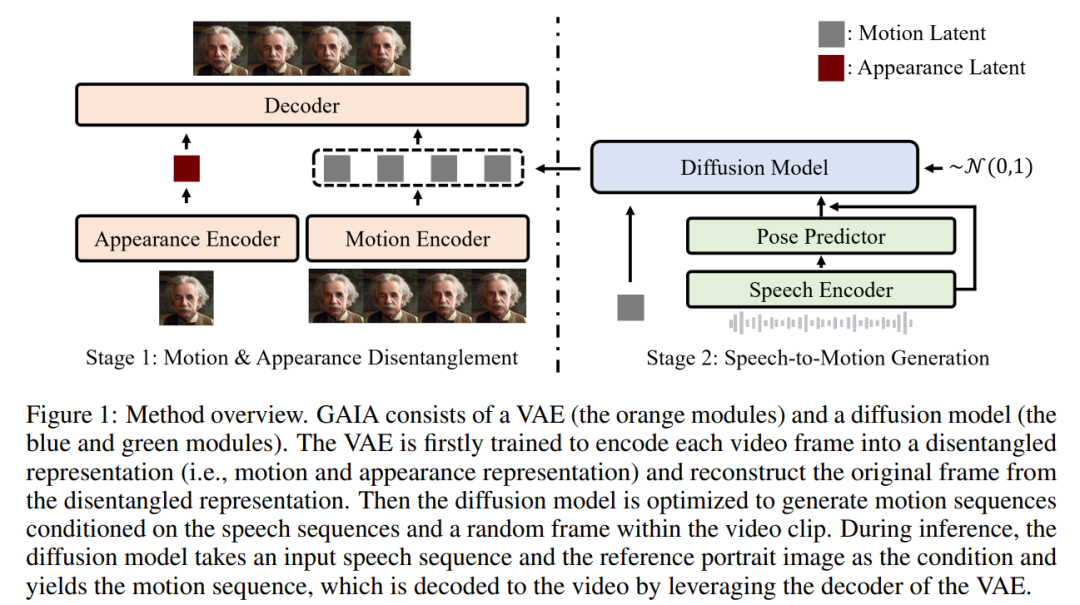 次に、この記事では、拡散モデルを使用して音声を予測するトレーニングを行います。ビデオ クリップ内のランダムにサンプリングされたフレームのモーション潜在シーケンスに基づいて、生成プロセスに外観情報を提供します。
次に、この記事では、拡散モデルを使用して音声を予測するトレーニングを行います。ビデオ クリップ内のランダムにサンプリングされたフレームのモーション潜在シーケンスに基づいて、生成プロセスに外観情報を提供します。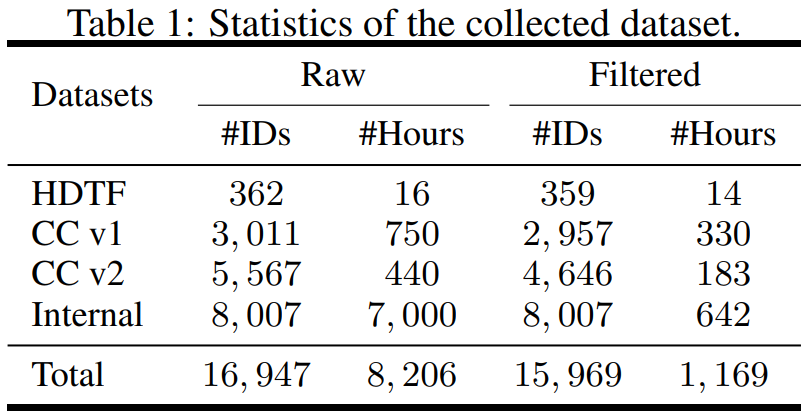
トレーニング モデルのサイズは 150M から 2B の範囲であり、その結果は、GAIA がスケーラブルであることを示しました。

 #
#
以上が写真からビデオが生成され、口を開ける、うなずく、感情、怒り、悲しみ、喜びはすべて入力によって制御できます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。