
ホームページ >テクノロジー周辺機器 >AI >なぜ国内の大手AIモデルは「ランキングのスワイプ」にハマるのか?
なぜ国内の大手AIモデルは「ランキングのスワイプ」にハマるのか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-12-02 08:53:101565ブラウズ
携帯電話サークルをフォローしている友人は、「承認しなければスコアを取得する」というフレーズに馴染みのない人はいないと思います。たとえば、AnTuTu や GeekBench などの理論性能テスト ソフトウェアは、携帯電話の性能をある程度反映できるため、プレイヤーから大きな注目を集めています。同様に、PC プロセッサーとグラフィックス カードのパフォーマンスを測定するための、対応するベンチマーク ソフトウェアがあります。
「何でも走れる」ようになってから、人気の大型AIモデルも走行スコア競争に参加するようになりました。特に「百体戦争」が始まってからは、毎日のように躍進し、各社は「」と名乗りました。ランニング「スコアファースト」
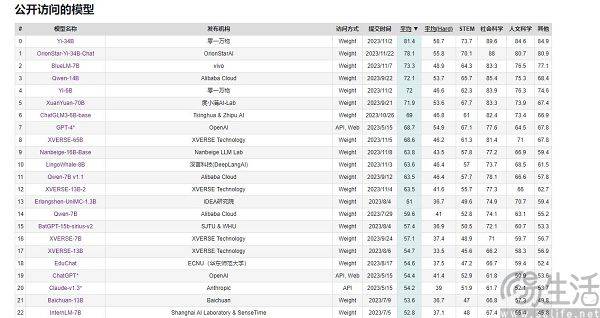
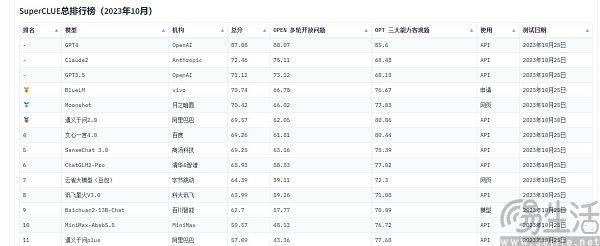
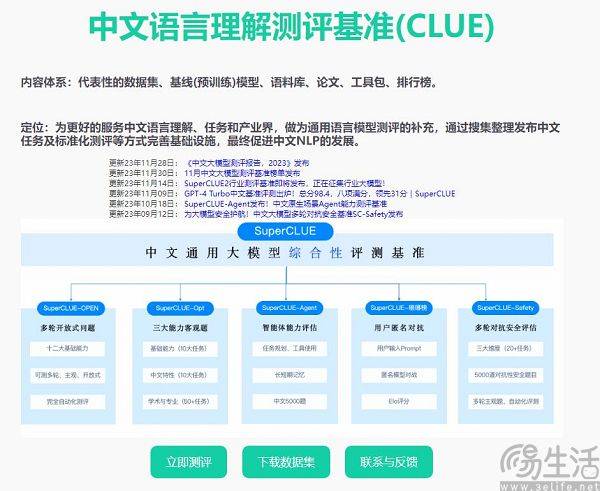
現在、中国でよく引用される大規模モデルの評価リストには、SuperCLUE、CMMLU、C-Eval などがあります。このうちCMMLUとC-Evalは、清華大学、上海交通大学、エディンバラ大学が共同で構築した総合試験評価セットです。 CMMLU は、MBZUAI、上海交通大学、マイクロソフト リサーチ アジアによって共同で立ち上げられました。 SuperCLUE については、主要大学の人工知能専門家が共同執筆しています
ご存知のとおり、スマートフォンの SoC、コンピューターの CPU、グラフィックス カードは、寿命を守るために高温になると自動的に周波数を下げ、低温になるとチップのパフォーマンスが向上します。したがって、パフォーマンス テストのために携帯電話を冷蔵庫に入れたり、コンピュータに強力な冷却システムを装備したりする人もいます。これにより、通常よりも高いスコアが得られる場合があります。また、大手携帯電話メーカーも各種ベンチマークソフトの「専用最適化」を標準運用としています
試験前に、偶然試験問題と標準解答を見て、いきなり問題を暗記すれば、試験の得点が大幅に向上することは想像できます。したがって、大規模モデルリストによって事前に設定された質問バンクがトレーニングセットに追加され、大規模モデルがベンチマークデータに適合するモデルになります。さらに、現在の LLM 自体は記憶力が優れていることで知られており、標準的な答えを暗唱するのは簡単です
Hillhouse チームの研究者は、ベンチマーク リークにより大規模なモデルの実行結果が誇張されることを発見しました。たとえば、1.3B モデルは一部のタスクではサイズの 10 倍を超える可能性がありますが、副作用として、これらが特別に設計されているという点が挙げられます。 「テスト受験」の場合「他の通常のテスト タスクで設計された大規模モデルのパフォーマンスが悪影響を受けます。結局、よく考えてみればわかるが、大型AIモデルは本来「問題作成者」であるはずだったが、あるリストで高得点を取るために「問題記憶者」となってしまったのだ。リストの特定の知識と出力スタイルを使用するため、大規模なモデルを誤解させる可能性があります。

トレーニングセット、検証セット、テストセットが交差しないというのは当然のことながら理想的な状態に過ぎず、結局のところ現実は非常に希薄であり、根本的にデータ漏洩の問題はほぼ避けられません。関連技術の継続的な進歩により、現在の大型モデルの基礎である Transformer 構造のメモリと受信能力は常に向上しており、この夏、Microsoft Research の汎用 AI 戦略により、このモデルは問題を引き起こすことなく 1 億個のトークンを受信できるようになりました。物忘れは容認できません。言い換えれば、将来的には、大規模な AI モデルがインターネット全体を読み取る機能を備えている可能性があります。
技術の進歩を脇に置いても、高品質のデータは常に不足しており、生産能力も限られているため、現在の技術レベルに基づいてデータ汚染を回避することは実際には困難です。今年初めにAI研究チームエポック社が発表した論文では、AIは高品質な人間の言語データを5年以内にすべて使い果たしてしまうことが示されており、この結果により言語の成長率が高まるということです。人間の言語データ、つまり今後 5 年間にすべての人類が出版するデータ、書かれた本、書かれた論文、書かれたコードがすべて結果を予測するために考慮されます。
データセットが評価に適している場合、事前トレーニングでより良い役割を果たすことは間違いありません。たとえば、OpenAI の GPT-4 は、権威推論評価データ セット GSM8K を使用します。したがって、現在、大規模モデル評価の分野には厄介な問題が存在しており、大規模モデルからのデータに対する需要は際限なくあるため、評価機関は人工知能のメーカーよりも速く、より遠くまで行動しなければならないことにつながっています。大型モデル。しかし、今日の評価機関にはこれを行う能力が全くないようです
なぜ一部のメーカーは大型モデルの走行スコアに注目し、次々とランキングを上げようとするのでしょうか?実際、この動作の背後にあるロジックは、アプリ開発者が自分のアプリのユーザー数に水を注入するのとまったく同じです。結局のところ、アプリのユーザー規模はその価値を測る重要な要素であり、現在の大規模 AI モデルの初期段階では、評価リストの結果がほぼ唯一の比較的客観的な基準となります。一般の認識、高スコアは、優れたパフォーマンスと同等であることを意味します。
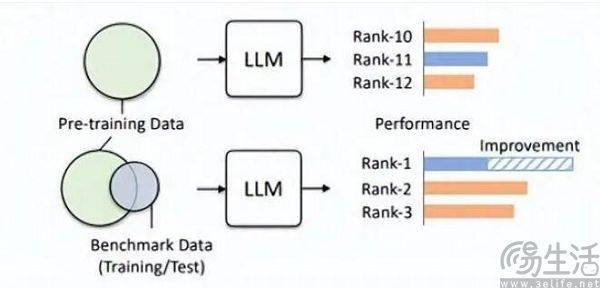
ランキングの見直しが強力な宣伝効果をもたらし、さらには資金調達の基礎を築く可能性がある場合、商業的利益の追加により、大手の AI モデル メーカーがランキングの見直しを急ぐのは避けられません。
以上がなぜ国内の大手AIモデルは「ランキングのスワイプ」にハマるのか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。