



今日は、機械学習における一般的な教師なし学習のクラスタリング手法について共有したいと思います。
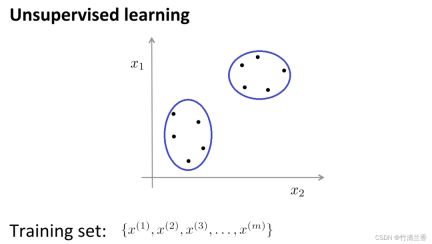
教師なし学習では、データにラベルが付けられないため、何が必要かをラベル付けする必要はありません。教師あり学習で行われるのは、この一連のラベルなしデータをアルゴリズムに入力し、アルゴリズムにデータに隠されたいくつかの構造を見つけさせることです。下図のデータを通じて、見つけられる構造の 1 つがポイントです。データセットは 2 つの別々の点のセット (クラスター) に分割でき、これらのクラスターを周回できるアルゴリズム (cluster) はクラスタリング アルゴリズムと呼ばれます。
#クラスタリング アルゴリズムの適用
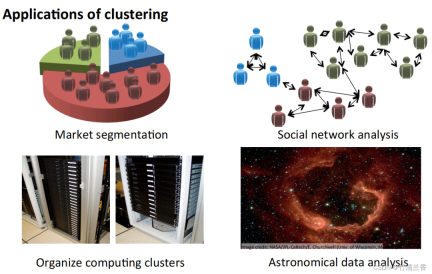
- 市場セグメンテーション: グループデータベース内の顧客情報を市場に応じて異なるグループに分類し、個別に販売したり、異なる市場に応じてサービスを向上させたりすることができます。
- ソーシャル ネットワーク分析: 電子メールで最も頻繁に連絡を取る人、および最も頻繁に連絡を取る人を通じて、密接に関連するグループを見つけます。
- コンピューター クラスターの編成: データ センターでは、コンピューター クラスターが連携して動作することが多く、リソースの再編成、ネットワークの再配置、データ センターの最適化、データ通信に使用できます。
- 天の川の構成を理解する: この情報を使用して、天文学について学びましょう。
クラスター分析の目標は、同じクラスターに割り当てられた観測値間のペアごとの差が、同じクラスターに割り当てられた観測値間のペアごとの差異よりも小さくなる傾向があるように、観測値をグループ (「クラスター」) に分割することです。異なる クラスター内の観測間の差異。クラスタリング アルゴリズムは、組み合わせアルゴリズム、ハイブリッド モデリング、パターン検索の 3 つの異なるタイプに分類されます。
# 一般的なクラスタリング アルゴリズムは次のとおりです。K-Means クラスタリング
- 階層型クラスタリング
- 凝集型クラスタリング
- 親和性伝播
- 平均シフト クラスタリング
- 二等分 K 平均法
- DBSCAN
- OPTICS
- BIRCH
- K 平均法
K 平均法は、1957 年にベル研究所のスチュアート ロイドによって提案されました。当初はパルス コード変調に使用されていました。このアルゴリズムが一般に発表されたのは 1982 年でした。 1965 年に Edward W. Forgy が同じアルゴリズムを公開したため、K 平均法は Lloyd-Forgy と呼ばれることもあります。
クラスタリングの問題では、通常、ラベルのないデータ セットの処理が必要であり、これらのデータを密接に関連するサブセットまたはクラスターに自動的に分割するアルゴリズムが必要です。現在、最も一般的で広く使用されているクラスタリング アルゴリズムは、K 平均法アルゴリズムです。
K 平均法アルゴリズムの直感的な理解:
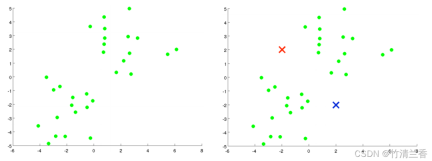
- 最初のステップは、(データを 2 つのカテゴリにクラスタリングしたいため) 2 つの点をランダムに生成することです (上の図の右側)。クラスター重心と呼ばれます。
- 2 番目のステップは、K 平均法アルゴリズムの内部ループを実行することです。 K 平均法アルゴリズムは 2 つのことを実行する反復アルゴリズムです。1 つ目はクラスターの割り当てで、2 つ目は重心の移動です。
- #内部ループの最初のステップは、クラスターの割り当てを実行すること、つまり各サンプルを走査し、クラスターの中心からの距離に従って各点を割り当てることです。この場合、異なるクラスター中心 (どのクラスター中心が互いに近いか) に移動するには、データセットを横断して、各ポイントを赤または青に色付けします。
内側のループの 2 番目のステップは、赤と青のクラスターの中心が、それらが属する点の平均位置に移動するようにクラスターの中心を移動することです。
新しいクラスターの中心からの距離に基づいて、すべてのポイントを新しいクラスターに割り当て、反復によってクラスターの中心の位置が変化しなくなり、ポイントの色も変化するまでこのプロセスを繰り返します。これ以上の変更はありません。この時点で、K-means による集計が完了したと言えます。このアルゴリズムは、データ内の 2 つのクラスターを非常にうまく見つけます。
# シンプルで理解しやすく、計算速度が速く、大規模なデータセットに適しています。 階層的クラスタリングは、特定のレベルに従ってサンプル セットをクラスタリングする操作です。ここでのレベルは、実際には特定の距離の定義を指します。 クラスタリングの最終的な目的は、分類の数を減らすことであるため、その動作は、リーフ ノードからリーフ ノードに徐々に近づくことに似ています。ルート ノード 樹状図プロセス。この動作は「ボトムアップ」とも呼ばれます。 より一般的には、階層クラスタリングは初期化された複数のクラスターをツリー ノードとして扱い、各反復ステップでは 2 つのクラスターをマージします。同様のクラスターを新しい大規模クラスターに追加するなどして、最終的に 1 つのクラスター (ルート ノード) だけが残ります。 階層的クラスタリング戦略は、集約 (ボトムアップ) と分割 (トップダウン) という 2 つの基本パラダイムに分けられます。 #階層型クラスタリングの反対は、DIANA (分割分析) としても知られる分割クラスタリングであり、その動作プロセスは「トップダウン」です。 K 平均法アルゴリズムの結果は、検索に選択されたクラスターの数と開始構成の割り当てによって異なります。対照的に、階層的クラスタリング手法ではそのような指定は必要ありません。代わりに、ユーザーは、2 組の観測値間のペアごとの非類似性に基づいて、(素の) 観測値グループ間の非類似性の尺度を指定する必要があります。名前が示すように、階層的クラスタリング手法は、各レベルのクラスタが 1 つ下のレベルのクラスタをマージすることによって作成される階層表現を生成します。最下位レベルでは、各クラスターに 1 つの観測値が含まれます。最上位レベルでは、すべてのデータを含むクラスターが 1 つだけあります。 利点: Affinity Propagation は、データ内の「模範」(代表点) と「クラスター」(クラスター) を識別するために設計されたグラフ理論に基づくクラスタリング アルゴリズムです。 K-Means などの従来のクラスタリング アルゴリズムとは異なり、Affinity Propagation は事前にクラスターの数を指定する必要がなく、クラスターの中心をランダムに初期化する必要もなく、代わりにデータ ポイント間の類似性を計算することによって最終的なクラスター化結果を取得します。 利点: アルゴリズムは、まずすべてのデータ ポイントを初期クラスターとして扱い、次に K 平均法アルゴリズムをクラスターに適用し、クラスターを 2 つのサブクラスターに分割し、次の二乗誤差を計算します。各サブクラスターと (SSE)。次に、誤差の二乗和が最も大きいサブクラスタを選択し、再度 2 つのサブクラスタに分割するという処理を、所定のクラスタ数に達するまで繰り返す。 利点: 密度法は、距離に依存せず、密度に依存するという特徴があります。したがって、距離ベースのアルゴリズムでは「球状」クラスターしか見つけられないという欠点を克服できます。 DBSCAN アルゴリズムの核となる考え方は次のとおりです。指定されたデータ ポイントに対して、密度 ある閾値に達するとクラスタに属し、それ以外の場合はノイズ点とみなされます。 OPTICS (クラスタリング構造を識別するためのポイントの順序付け) は、クラスターの数を自動的に決定できる密度ベースのクラスタリング アルゴリズムです。同時に、あらゆる形状のクラスターを検出し、ノイズの多いデータを処理することもできます。 OPTICS アルゴリズムの中心的な考え方は、特定のデータ ポイントと他のポイントの間の距離を計算することです。密度に対する距離の到達可能性を決定し、密度ベースの距離グラフを構築します。次に、この距離マップをスキャンすることにより、クラスターの数が自動的に決定され、各クラスターが分割されます。 BIRCH (Balanced Iterative Reduction and Hierarchical Clustering) は、大規模なデータ セットを効率的に処理できる階層クラスタリングに基づくクラスタリング アルゴリズムです。あらゆる形状のクラスターで良好な結果を達成します BIRCH アルゴリズムの中心的な考え方は、データ セットを階層的にクラスター化することでデータのサイズを徐々に縮小し、最終的にクラスターを縮小することです。という構造が得られます。 BIRCH アルゴリズムは、CF ツリーと呼ばれる B ツリーに似た構造を使用します。この構造は、サブクラスターを迅速に挿入および削除でき、クラスターの品質と効率を確保するために自動的にバランスをとることができます
K-Means アルゴリズムの利点:
欠点:
階層的クラスタリング
利点:
欠点:
##計算の複雑さが高すぎます;
書き直された内容は次のとおりです: 凝集クラスタリングはボトムアップ クラスタリング アルゴリズムです。各データ ポイントを初期クラスタとして扱い、それらを徐々にマージします。停止条件が満たされるまで、より大きなクラスターを形成します。このアルゴリズムでは、各データ ポイントは最初に個別のクラスターとして扱われ、その後、すべてのデータ ポイントが 1 つの大きなクラスターにマージされるまで、クラスターが徐々にマージされます。
さまざまな形状やサイズのクラスターに適用でき、事前にクラスターの数を指定する必要はありません。
欠点:
特に大規模なものを扱う場合、計算の複雑さが高くなります。スケール データ セットには、大量のコンピューティング リソースとストレージ スペースが必要です。
変更されたコンテンツ: アフィニティ伝播アルゴリズム (AP) は通常、アフィニティ伝播アルゴリズムまたは近接伝播アルゴリズムと訳されます
#利点:
#最終的なクラスタリング ファミリの数を指定する必要がありません
アルゴリズムは計算の複雑さが高く、大量のストレージを必要とします。スペースとコンピューティング リソース。
シフト クラスタリングは、密度ベースのノンパラメトリック クラスタリング アルゴリズムであり、その基本的な考え方は、データ ポイントの最大密度を見つけることです。データ内のクラスターを識別するための位置 (「極大値」または「ピーク」と呼ばれます)。このアルゴリズムの核心は、各データ ポイントの局所密度を推定し、その密度推定結果を使用してデータ ポイントの移動方向と距離を計算することです。
クラスターの数を指定する必要はなく、複雑な形状のクラスターに対しても良好な結果が得られます。
特に大規模なものを扱う場合、計算の複雑さが高くなります。スケール データ セットは、多くのコンピューティング リソースとストレージ スペースを消費する必要があります。
Bisecting K-Means は、K-Means アルゴリズムに基づく階層的クラスタリング アルゴリズムです。その基本的な考え方は、すべてのデータを結合することです。点を 1 つのクラスターに分割し、さらにそのクラスターを 2 つのサブクラスターに分割し、それぞれのサブクラスターに K-Means アルゴリズムを適用するという処理を、所定のクラスター数に達するまで繰り返します。
## は高い精度と安定性を備えており、大規模なデータセットを効果的に処理できます。クラスターの初期数を指定する必要があります。
特に大規模なものを扱う場合、計算の複雑さが高くなります。スケール データ セットには、大量のコンピューティング リソースとストレージ スペースが必要です。
密度ベースの空間クラスタリング アルゴリズム DBSCAN (Density-Based Spatial Clustering of Applications with Noise) は、ノイズを含む代表的なクラスタリング アルゴリズムです。
利点:
欠点:
OPTICS
#利点:
欠点:
BIRCH
# # 利点:
欠点:
以上が教師なし機械学習を探索するための 9 つのクラスタリング アルゴリズムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 LM Studioを使用してLLMをローカルに実行する方法は? - 分析VidhyaApr 19, 2025 am 11:38 AM
LM Studioを使用してLLMをローカルに実行する方法は? - 分析VidhyaApr 19, 2025 am 11:38 AM自宅で大規模な言語モデルを簡単に実行する:LM Studioユーザーガイド 近年、ソフトウェアとハードウェアの進歩により、パーソナルコンピューターで大きな言語モデル(LLM)を実行することが可能になりました。 LM Studioは、このプロセスを簡単かつ便利にするための優れたツールです。この記事では、LM Studioを使用してLLMをローカルに実行する方法に飛び込み、重要なステップ、潜在的な課題、LLMをローカルに配置することの利点をカバーします。あなたが技術愛好家であろうと、最新のAIテクノロジーに興味があるかどうかにかかわらず、このガイドは貴重な洞察と実用的なヒントを提供します。始めましょう! 概要 LLMをローカルに実行するための基本的な要件を理解してください。 コンピューターにLM Studiをセットアップします
 Guy Periは、データ変換を通じてMcCormickの未来のフレーバーを支援しますApr 19, 2025 am 11:35 AM
Guy Periは、データ変換を通じてMcCormickの未来のフレーバーを支援しますApr 19, 2025 am 11:35 AMGuy Periは、McCormickの最高情報およびデジタルオフィサーです。彼の役割からわずか7か月後ですが、ペリは同社のデジタル能力の包括的な変革を急速に進めています。データと分析に焦点を当てている彼のキャリアに焦点が当てられています
 迅速なエンジニアリングの感情の連鎖は何ですか? - 分析VidhyaApr 19, 2025 am 11:33 AM
迅速なエンジニアリングの感情の連鎖は何ですか? - 分析VidhyaApr 19, 2025 am 11:33 AM導入 人工知能(AI)は、言葉だけでなく感情も理解し、人間のタッチで反応するように進化しています。 この洗練された相互作用は、AIおよび自然言語処理の急速に進む分野で重要です。 th
 データサイエンスワークフローのための12のベストAIツール-AnalyticsVidhyaApr 19, 2025 am 11:31 AM
データサイエンスワークフローのための12のベストAIツール-AnalyticsVidhyaApr 19, 2025 am 11:31 AM導入 今日のデータ中心の世界では、競争力と効率の向上を求める企業にとって、高度なAIテクノロジーを活用することが重要です。 さまざまな強力なツールにより、データサイエンティスト、アナリスト、開発者が構築、Deplを作成することができます。
 AV BYTE:OpenAIのGPT-4O MINIおよびその他のAIイノベーションApr 19, 2025 am 11:30 AM
AV BYTE:OpenAIのGPT-4O MINIおよびその他のAIイノベーションApr 19, 2025 am 11:30 AM今週のAIの風景は、Openai、Mistral AI、Nvidia、Deepseek、Hugging Faceなどの業界の巨人からの画期的なリリースで爆発しました。 これらの新しいモデルは、TRの進歩によって促進された電力、手頃な価格、アクセシビリティの向上を約束します
 PerplexityのAndroidアプリにはセキュリティの欠陥が感染しているとレポートApr 19, 2025 am 11:24 AM
PerplexityのAndroidアプリにはセキュリティの欠陥が感染しているとレポートApr 19, 2025 am 11:24 AMしかし、検索機能を提供するだけでなくAIアシスタントとしても機能する同社のAndroidアプリは、ユーザーをデータの盗難、アカウントの買収、および悪意のある攻撃にさらす可能性のある多くのセキュリティ問題に悩まされています。
 誰もがAIの使用が上手になっています:バイブコーディングに関する考えApr 19, 2025 am 11:17 AM
誰もがAIの使用が上手になっています:バイブコーディングに関する考えApr 19, 2025 am 11:17 AM会議や展示会で何が起こっているのかを見ることができます。エンジニアに何をしているのか尋ねたり、CEOに相談したりできます。 あなたが見ているところはどこでも、物事は猛烈な速度で変化しています。 エンジニア、および非エンジニア 違いは何ですか
 Rocketpyを使用したロケットの起動シミュレーションと分析-AnalyticsVidhyaApr 19, 2025 am 11:12 AM
Rocketpyを使用したロケットの起動シミュレーションと分析-AnalyticsVidhyaApr 19, 2025 am 11:12 AMRocketpy:A包括的なガイドでロケット発売をシミュレートします この記事では、強力なPythonライブラリであるRocketpyを使用して、高出力ロケット発売をシミュレートすることをガイドします。 ロケットコンポーネントの定義からシミュラの分析まで、すべてをカバーします


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

Dreamweaver Mac版
ビジュアル Web 開発ツール

WebStorm Mac版
便利なJavaScript開発ツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

