
ホームページ >テクノロジー周辺機器 >AI >ツールキットを使用して大規模モデルの推論パフォーマンスを 40 倍向上
ツールキットを使用して大規模モデルの推論パフォーマンスを 40 倍向上

- 王林転載
- 2023-11-30 20:26:05965ブラウズ
Intel® Transformer の拡張機能とは何ですか?
Intel® Extension for Transformers[1] は、インテルによって発売された革新的なツールキットであり、Intel® アーキテクチャ プラットフォーム、特に 4 番目のプラットフォームに基づくことができます。世代 Intel® Xeon® スケーラブル プロセッサ (開発コード名 Sapphire Rapids[2]、SPR) は、Transformer ベースの大規模言語モデル (LLM) を大幅に高速化します。その主な機能は次のとおりです。
- Hugging Face トランスフォーマー API[3] を拡張し、Intel® Neural Compressor[4] を活用することで、シームレスなモデル圧縮エクスペリエンスをユーザーに提供します。
- 低ビット量子化カーネル (NeurIPS 2023: CPU での効率的な LLM 推論 [5]) を使用した LLM 推論ランタイムを提供し、Falcon、LLaMA、MPT、Llama2、BLOOM、OPT、ChatGLM2、GPT-J などの一般的な LLM をサポートします。 6B、Baichuan-13B-Base、Baichuan2-13B-Base、Qwen-7B、Qwen-14B、および Dolly-v2-3B[6];
- 高度な圧縮センシング ランタイム[7] (NeurIPS 2022: 高速) CPU および QuaLA-MiniLM での蒸留: 量子化長適応型 MiniLM、NeurIPS 2021: 一度プルーニングすれば忘れる: 事前トレーニング済み言語モデルのスパース/プルーニング)。
この記事では、LLM 推論ランタイム (「LLM ランタイム」と呼ばれる) と、Transformer ベースの API を使用してインテル® Xeon® 上で実行する方法に焦点を当てます。 スケーラブルなプロセッサ上でより効率的な LLM 推論を実現し、チャット シナリオで LLM のアプリケーション問題に対処する方法を説明します。
LLM ランタイムIntel® Extension for Transformers によって提供される LLM ランタイム[8] は、GGML[9] からインスピレーションを得た、軽量かつ効率的な LLM 推論ランタイムです。 llama.cpp[10] と互換性があり、次の特徴があります:
- カーネルは
- Intel® Xeon® CPU 向けに組み込まれています 複数の AI アクセラレーション テクノロジ ( AMX、VNNI など)、AVX512F および AVX2 命令セットが最適化されています。 は、さまざまな粒度 (チャネルごとまたはグループごと)、さまざまなグループ サイズ (32/ など) など、より多くの量子化オプションを提供できます。 128);
- には、より優れた KV キャッシュ アクセスとメモリ割り当て戦略があります;
- には、マルチチャネル システム推論での分散に役立つテンソル並列化機能があります。
from transformers import AutoTokenizer, TextStreamerfrom intel_extension_for_transformers.transformers import AutoModelForCausalLMmodel_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl,"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer(prompt, return_tensors="pt").input_idsstreamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True)outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)デフォルト設定は、重みを 4 ビットとして保存し、計算を 8 ビットとして実行します。ただし、さまざまな計算データ型 (dtype) と重みデータ型の組み合わせもサポートされており、ユーザーは必要に応じて設定を変更できます。この機能の使用方法のサンプル コードを以下に示します。
from transformers import AutoTokenizer, TextStreamerfrom intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfigmodel_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl,"woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4")tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer(prompt, return_tensors="pt").input_idsstreamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name,quantization_cnotallow=woq_config)outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)パフォーマンス テスト継続的な努力の結果、上記の最適化スキームの INT4 パフォーマンスは大幅に向上しました。この記事では、
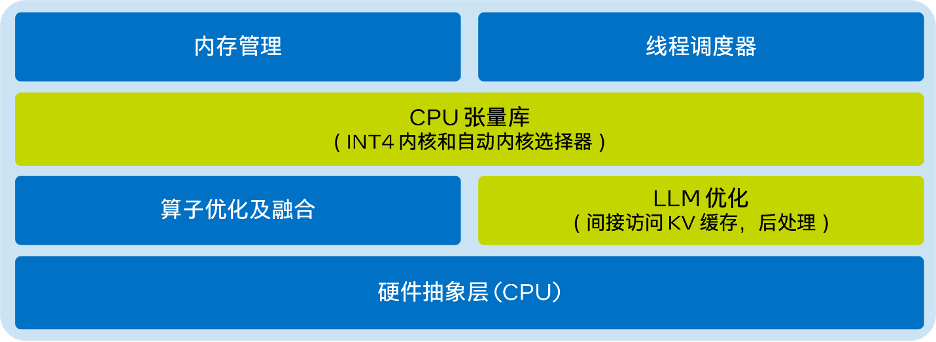
Intel® 256 GB 合計メモリ (16 x 16 GB DDR5 4800 MT/s [4800 MT/s])、BIOS 3A14.TEL2P1、マイクロコード 0x2b0001b0、 CentOSストリーム8。 推論パフォーマンス テストの結果を以下の表に示します。入力サイズは 32、出力サイズは 32、ビームは 1
##△ 表 1. LLM ランタイムと llama.cpp の推論パフォーマンスの比較 (入力サイズ = 32、出力サイズ = 32、ビーム = 1) 
入力サイズが異なる場合の推論パフォーマンスは 1024、出力サイズは 32、ビームは 1 です。テスト結果の詳細を次の表に示します。
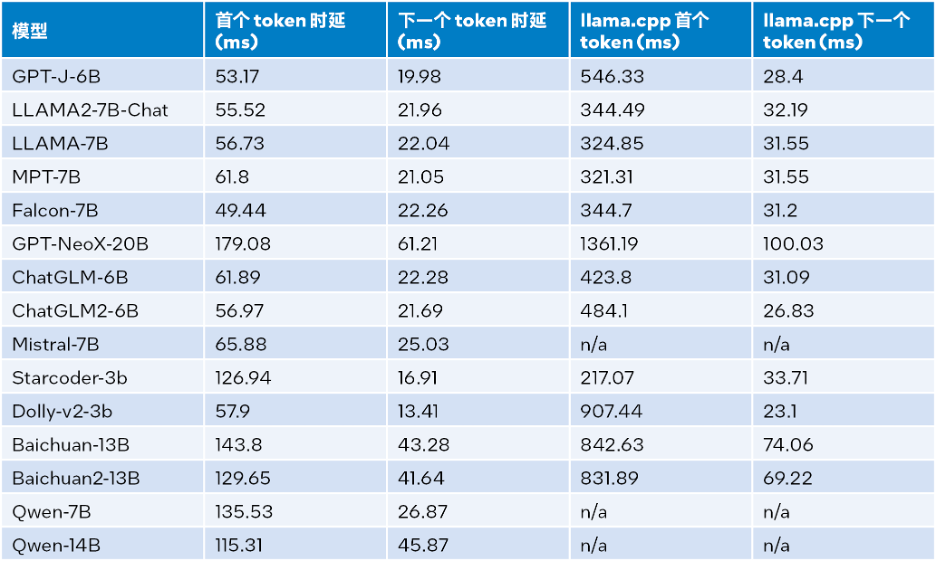
△表 2. LLMランタイムと llama.cpp の推論パフォーマンスの比較 (入力サイズ = 1024、出力サイズ = 32、ビーム = 1)
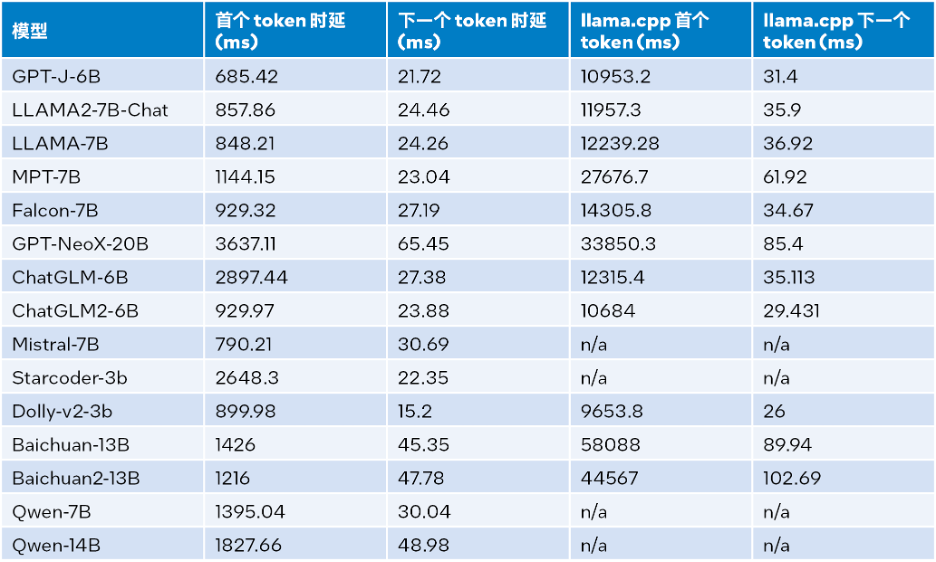
上記の表 2 によると、同じく第 4 世代 Intel® Xeon® スケーラブル プロセッサ上で動作する llama.cpp と比較すると、最初のトークンであっても次のトークンであっても、LLM ランタイムはレイテンシを大幅に短縮できます。 、最初のトークンと次のトークンの推論速度は最大 40 倍 [a] (Baichuan-13B、入力は 1024) と 2.68 倍 [ b] 増加します。 (MPT-7B、入力は 1024)。 llama.cpp のテストでは、デフォルトのコードベース [10] が使用されます。
表 1 と表 2 のテスト結果を組み合わせると、次のことがわかります。同じく第 4 世代 インテル® Xeon® スケーラブル プロセッサーで実行されている llama.cpp と比較すると、LLM ランタイムは大幅に向上します。多くの一般的な LLM の全体的なパフォーマンス: 入力サイズが 1024 の場合、3.58 ~ 21.5 倍の向上が達成され、入力サイズが 32 の場合、1.76 ~ 3.43 倍の向上が達成されます[c] 。
精度テスト
Intel® Transformers の拡張機能が利用可能 Intel® SignRound[11]、RTN、および GPTQ[12] が Neural Compressor で利用可能 ] および他の定量化手法を使用し、lambada_openai、piqa、winogrande、および hellaswag データセットを使用して INT4 推論精度を検証しました。以下の表は、テスト結果の平均と FP32 の精度を比較しています。
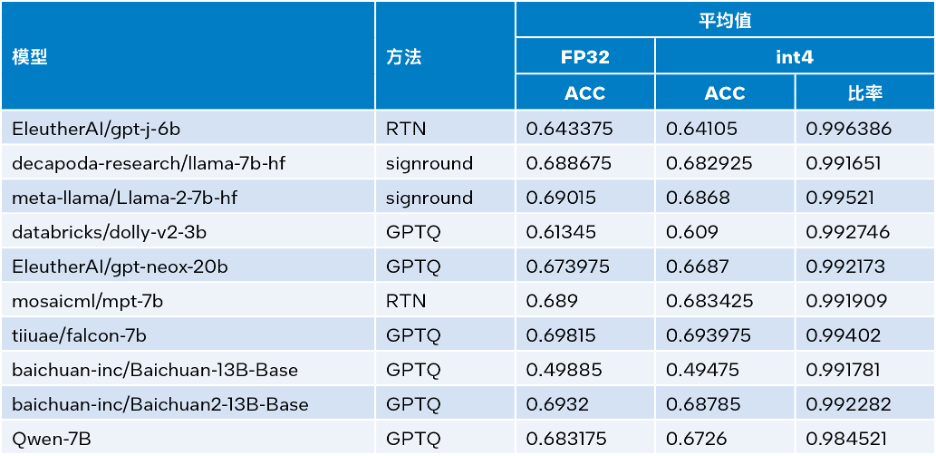
△表 3. INT4 と FP32 の精度比較
上記の表 3 からわかるように、INT4 推論は LLM に基づいた複数のモデルによって実行されます。実行時間は正確です 性的損失は非常に小さいため、ほとんど無視できます。多くのモデルを検証しましたが、スペースの都合上、ここでは一部のみを掲載します。さらに詳しい情報が必要な場合は、リンク https://medium.com/@NeuralCompressor/llm-performance-of-intel-extension-for-transformers-f7d061556176 を参照してください。
より高度な機能: より多くのシナリオで LLM のアプリケーション ニーズを満たします
同時に、LLM Runtime[8] には、デュアル チャネル CPU のテンソル並列化機能もあります。このような機能を備えた製品は初めてです。将来的には、デュアル ノードがさらにサポートされる予定です。
しかし、LLM ランタイムの利点は、その優れたパフォーマンスと精度だけではなく、チャット アプリケーション シナリオでの機能の強化や、チャット シナリオで LLM が遭遇する可能性のある問題の解決にも多大な労力を費やしてきました。次のアプリケーションの問題が発生します:
- 対話は LLM 推論に関連するだけでなく、対話履歴も非常に役立ちます。
- 制限された出力長: LLM モデルの事前トレーニングは、主に制限されたシーケンス長に基づいています。したがって、シーケンスの長さが事前トレーニング中に使用されるアテンション ウィンドウ サイズを超えると、精度が低下します。
- 非効率: デコード段階で、Transformer ベースの LLM は以前に生成されたすべてのトークンのキーと値のステータス (KV) を保存するため、過剰なメモリ使用量とデコード遅延の増加につながります。
最初の問題に関しては、LLM ランタイムの対話機能は、より多くの対話履歴データを組み込み、より多くの出力を生成することで解決されますが、llama.cpp にはまだ十分に対応する能力がありません。
2 番目と 3 番目の質問に関しては、ストリーミング LLM (Steaming LLM) を Intel® Extension for Transformers に統合しました。これにより、メモリ使用量が大幅に最適化され、推論時間の延長が削減されます。
ストリーミング LLM
従来の KV キャッシュ アルゴリズムとは異なり、私たちの方法は アテンション シンク (4 つの初期トークン) を組み合わせて、アテンション計算の安定性を向上させ、最新のトークンを保持します ローリング KV キャッシュの助けを借りて。これは言語モデリングにとって重要です。この設計は柔軟性が高く、回転位置エンコーディング RoPE と相対位置エンコーディング ALiBi を利用できる自己回帰言語モデルにシームレスに統合できます。
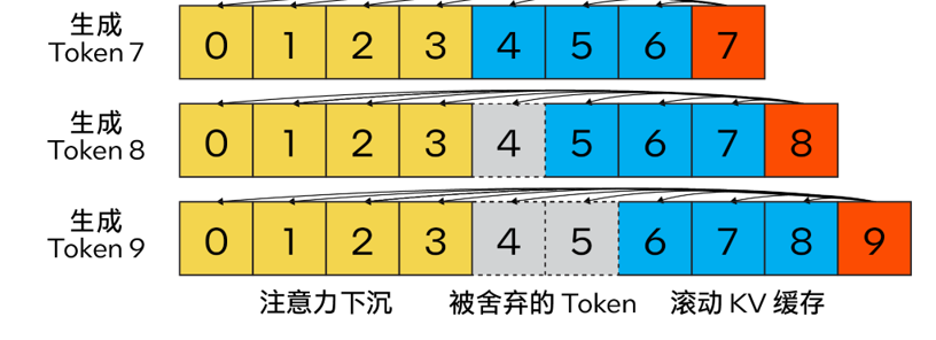
書き直す必要がある内容は次のとおりです。 △ 図 2. アテンション シンキングを使用して効率的なストリーミング言語モデルを実装する Steam LLM の KV キャッシュ (画像出典: [13])
さらに、llama.cpp とは異なり、この最適化プランでは、ストリーミング LLM 戦略を強化するために、「n_keep」や「n_discard」などの新しいパラメーターも追加されています。ユーザーは、「n_keep」パラメータを使用して KV キャッシュに保持するトークンの数を指定し、「n_discard」パラメータを使用して生成されたトークンのうち破棄する数を決定できます。パフォーマンスと精度のバランスをより良くするために、システムはデフォルトで KV キャッシュ内の最新のトークン番号の半分を破棄します
同時に、パフォーマンスをさらに向上させるために、MHA フュージョンにストリーミング LLM も追加しました。モード。モデルが回転位置エンコーディング (RoPE) を使用して位置埋め込みを実装する場合、既存の K キャッシュに「シフト操作」を適用するだけで、破棄されていない以前に生成されたトークンに対する操作の実行を回避できます。この方法では、長いテキストを生成するときにコンテキスト サイズ全体を最大限に活用できるだけでなく、KV キャッシュ コンテキストが完全にいっぱいになるまで追加のオーバーヘッドが発生しません。
“shift operation”依赖于旋转的交换性和关联性,或复数乘法。例如:如果某个token的K-张量初始放置位置为m并且旋转了m×θi for i ∈ [0,d/2),那么当它需要移动到m-1这个位置时,则可以旋转回到(-1)×θi for i ∈ [0,d/2)。这正是每次舍弃n_discard个token的缓存时发生的事情,而此时剩余的每个token都需要“移动”n_discard个位置。下图以“n_keep=4、n_ctx=16、n_discard=1”为例,展示了这一过程。

△图3.Ring-Buffer KV-Cache和Shift-RoPE工作原理
需要注意的是:融合注意力层无需了解上述过程。如果对K-cache和V-cache进行相同的洗牌,注意力层会输出几乎相同的结果(可能存在因浮点误差导致的微小差异)。
您可以使用下面的代码来启动Streaming LLM:
from transformers import AutoTokenizer, TextStreamer from intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfig model_name = "Intel/neural-chat-7b-v1-1" # Hugging Face model_id or local model woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4") prompt = "Once upon a time, a little girl"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) inputs = tokenizer(prompt, return_tensors="pt").input_ids streamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name, quantization_cnotallow=woq_config, trust_remote_code=True) # Recommend n_keep=4 to do attention sinks (four initial tokens) and n_discard=-1 to drop half rencetly tokens when meet length threshold outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300, ctx_size=100, n_keep=4, n_discard=-1)
结论与展望
本文基于上述实践经验,提供了一个在英特尔® 至强® 可扩展处理器上实现高效的低位(INT4)LLM推理的解决方案,并且在一系列常见LLM上验证了其通用性以及展现了其相对于其他基于CPU的开源解决方案的性能优势。未来,我们还将进一步提升CPU张量库和跨节点并行性能。
欢迎您试用英特尔® Extension for Transformers[1],并在英特尔® 平台上更高效地运行LLM推理!也欢迎您向代码仓库(repository)提交修改请求 (pull request)、问题或疑问。期待您的反馈!
特别致谢
在此致谢为此篇文章做出贡献的英特尔公司人工智能资深经理张瀚文及工程师许震中、余振滔、刘振卫、丁艺、王哲、刘宇澄。
[a]根据表2 Baichuan-13B的首个token测试结果计算而得。
[b]根据表2 MPT-7B的下一个token测试结果计算而得。
[c]当输入大小为1024时,整体性能=首个token性能+1023下一个token性能;当输入大小为32时,整体性能=首个token性能+31下一个token性能。
以上がツールキットを使用して大規模モデルの推論パフォーマンスを 40 倍向上の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。