
ホームページ >テクノロジー周辺機器 >AI >AIプロダクトマネージャー必読!機械学習アルゴリズムを始めるための初心者ガイド
AIプロダクトマネージャー必読!機械学習アルゴリズムを始めるための初心者ガイド

- 王林転載
- 2023-11-28 17:25:46813ブラウズ
興味深い機械学習アルゴリズムに関する内容は、次の記事のトピックです。この記事は AI プロダクト マネージャーの学生向けに共有されており、この分野に参入したばかりの学生に強くお勧めします。

以前、人工知能業界、プロダクト マネージャーの第 2 カーブ、および 2 つの立場の違いについてお話しましたが、今回はさらに一歩深く掘り下げて、機械学習アルゴリズムについて興味深い説明をします。
機械学習のアルゴリズムというと、少し理解できそうにないかもしれません。最初は私も含めて頭が痛くなる方も多いと思いますが、数式は使わず、事例のみで紹介するようにしています。全体から部分へ。
1. 機械学習アルゴリズムの概要
まず、機械学習アルゴリズムの基本概念を理解しましょう。
機械学習はコンピューターがデータを通じて学習し改善する方法であり、機械学習アルゴリズムはこの目標を達成するためのツールです
簡単に言えば、機械学習アルゴリズムは、入力データに基づいて学習し、学習した知識に基づいて予測や決定を行うことができる一連のルールまたはモデルです。
楽しい瞬間: あなたが神秘的な宝探しに参加していると想像してください。ゲームでは、宝の地図に基づいて宝の場所を見つける必要があります。この宝の地図はデータであり、あなたがしなければならないのはデータを分析して宝を見つけることだけです。実生活では、機械学習アルゴリズムを通じてこのタスクを達成できます。
機械学習アルゴリズムは、大量のデータからパターンを学習し、これらのパターンに基づいて予測や決定を行うことができる、インテリジェントな宝探しロボットのようなものです。機械学習アルゴリズムの中核的な目標は、データから結果へのマッピング エラーを削減し、それによって当社の製品をよりインテリジェントで正確なものにすることです。
機械学習アルゴリズムのアプリケーション シナリオは非常に幅広く、一般的なアプリケーションには、分類問題、クラスター分析、回帰問題などがあります。これら 3 つのアプリケーション シナリオには、実際の生活でも独自のアプリケーションがあります。次に、それぞれのアプリケーションシナリオと実際のアプリケーションを紹介します。
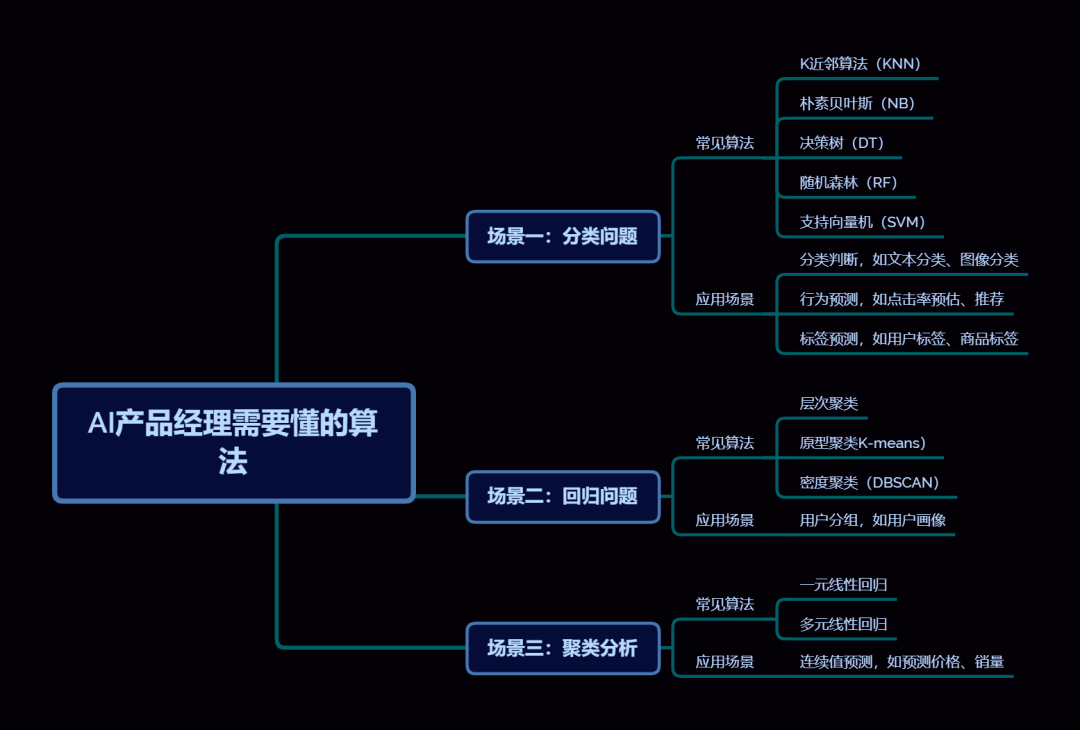
1) 応用シナリオ: 分類判定、ラベル予測、行動予測。
2) 解決原理: 既知のデータをトレーニングし、未知のデータを予測します (2 つの分類と複数の分類を含みます。たとえば、予測結果には「0/1」などの 2 つの離散値のみが含まれます) 「はい / いいえ」は 2 分類です。予測結果が「A/B/C」のように複数の離散値である場合は、多分類です)。
一般的な分類アルゴリズムには次のものがあります:
- デシジョン ツリー: デシジョン ツリーは、一連の質問を通じてデータを分類する、ツリー構造に基づく分類アルゴリズムです。
- サポート ベクター マシン: サポート ベクター マシンは、データ空間内で最大マージン超平面を見つけることによって分類を実行する、幾何学的概念に基づく分類アルゴリズムです。
4) ケース: スパムの防止
スパム フィルタリングは典型的な分類問題です。この問題を解決するには、サポート ベクター マシン アルゴリズムを使用できます。モデルをトレーニングすると、メール内のキーワード、送信者、その他の情報に基づいて、メールがスパムであるか通常であるかを正確に判断できます。3. シナリオ 2: クラスター分析
1) アプリケーション シナリオ:ユーザー グループ化、ユーザー ポートレート
2) 解決原理:クラスター分析は、一連のデータをいくつかのカテゴリーに分割するプロセスです。これらのカテゴリは、データの固有の特性または類似性に基づいています。その特徴を一言で表すと「羽鳥が群がる」。
3) 一般的なクラスタリング アルゴリズムK 平均法クラスタリング: K 平均法クラスタリングは、距離ベースのクラスタリング アルゴリズムです。データ ポイント間の距離を繰り返し計算することで、データ ポイントを K 個のカテゴリに分割します。
- 階層的クラスタリング: 階層的クラスタリングは、距離ベースのクラスタリング アルゴリズムです。データ ポイント間の距離を計算することで、類似したデータ ポイントを 1 つのカテゴリに徐々に分割します。
顧客セグメンテーションには、一般的なクラスター分析アプリケーションです。 K 平均法クラスタリング アルゴリズムを使用して、消費量、購入頻度、その他の属性に基づいて顧客をさまざまなカテゴリにグループ化し、正確なマーケティング戦略を策定できます
4. シナリオ 3: 回帰問題
1) アプリケーション シナリオ:将来の価格と売上を予測します。
2) 解決原理:サンプルの分布に従ってグラフ (直線/曲線) を当てはめ、連立方程式を形成し、パラメーターを入力し、将来の特定の値を予測します。
3) 一般的な回帰アルゴリズム4) ケース株価予測 株価予測は典型的な回帰問題です。線形回帰またはサポート ベクター マシン回帰アルゴリズムを使用して、過去の株価データに基づいて将来の株価を予測できます。 5. 最後の言葉 要約すると、この記事の主な目的は、主流の機械学習アルゴリズムを紹介することです。次に、3 つのアプリケーション シナリオのアルゴリズムを 1 つずつ分析します。アルゴリズムの知識を知りたい場合は、コメント欄で共有してください。一緒に作成して共有することも歓迎です これがあなたにインスピレーションをもたらすことを願っています、さあ! この記事は転載しないでください。この記事は当初 @六星笑 Product onEveryone is a Product Manager without allowed で公開されたものです タイトル画像は、CC0 プロトコルに基づいた Unsplash からのものです
以上がAIプロダクトマネージャー必読!機械学習アルゴリズムを始めるための初心者ガイドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。