
ホームページ >テクノロジー周辺機器 >AI >安定したビデオ拡散が登場、コードウェイトはオンラインに
安定したビデオ拡散が登場、コードウェイトはオンラインに

- PHPz転載
- 2023-11-22 14:30:481525ブラウズ
AI描画で有名なStability AIが、ついにAI生成動画業界に参入しました。
今週火曜日、安定拡散に基づくビデオ生成モデルである安定ビデオ拡散が開始され、AI コミュニティはすぐに議論を開始しました
#「やっと待った」という声が多く聞かれました。
#今、既存の静止画像を使用して数秒のビデオを生成できます
Stability AI のオリジナルの Stable Diffusion グラフ モデルに基づいて、Stable Video Diffusion はオープン ソースまたは商用化されました。業界では数少ないビデオ生成モデル。


導入によると、Stable Video Propagation は、マルチビュー データセットを微調整することによる単一画像からのマルチビュー合成など、さまざまなダウンストリーム タスクに簡単に適応できます。 Stable AIは、Stable Proliferationを中心に構築されたエコシステムと同様に、この基盤を構築および拡張するさまざまなモデルを計画していると述べています


外部評価では、Stability AI がこれらのモデルを確認しました。ユーザー嗜好調査において主要なクローズドソース モデルを上回るパフォーマンス:


安定したビデオ伝送は、安定した AI オープンソース モデル ファミリーのメンバーです。現在、同社の製品は画像、言語、オーディオ、3D、コードなどの複数のモダリティをカバーしているようですが、これは人工知能の向上に対する同社の取り組みを完全に示しています
安定したビデオの普及技術レベル
高解像度ビデオの潜在的な普及モデルとしての安定したビデオ普及モデルは、テキストからビデオへ、または画像からビデオへの SOTA レベルに達しています。最近、2D 画像合成でトレーニングされた潜在拡散モデルは、時間レイヤーを挿入し、小規模な高品質ビデオ データセットを微調整することにより、生成ビデオ モデルに変換されました。ただし、トレーニング方法は文献によって大きく異なり、ビデオ データ キュレーションの統一戦略についてはまだこの分野で合意されていません。
論文「安定したビデオの普及」では、安定性 AI は成功したビデオを特定して評価します。トレーニング ビデオ 潜在拡散モデルの 3 つの異なる段階: テキストから画像への事前トレーニング、ビデオの事前トレーニング、および高品質ビデオの微調整。また、高品質のビデオを生成するために慎重に準備された事前トレーニング データセットの重要性を実証し、字幕やフィルタリング戦略を含む強力な基本モデルをトレーニングするための体系的なキュレーション プロセスについても説明します。
Stability AI は、論文の中で、高品質データに対するベース モデルの微調整の影響についても調査し、クローズドソースのビデオ生成に匹敵するテキストからビデオへのモデルをトレーニングします。このモデルは、画像からビデオの生成やカメラのモーション固有の LoRA モジュールへの適応性などの下流タスクに強力なモーション表現を提供します。さらに、このモデルは、マルチビュー拡散モデルの基礎として使用できる強力なマルチビュー 3D プリアを提供することもできます。モデルは、オブジェクトの複数のビューをフィードフォワード方式で生成します。必要な計算能力はわずかであり、パフォーマンスも画像ベースの方法よりも優れています。
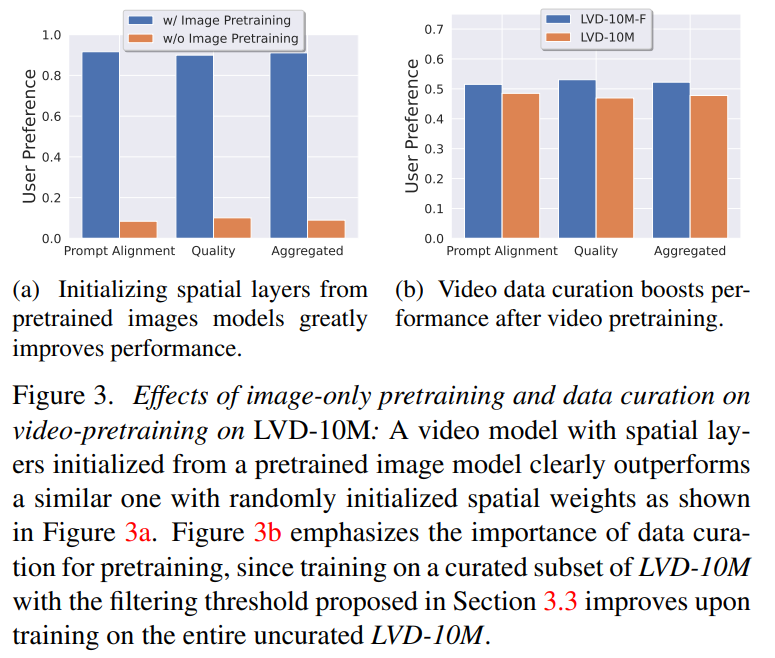
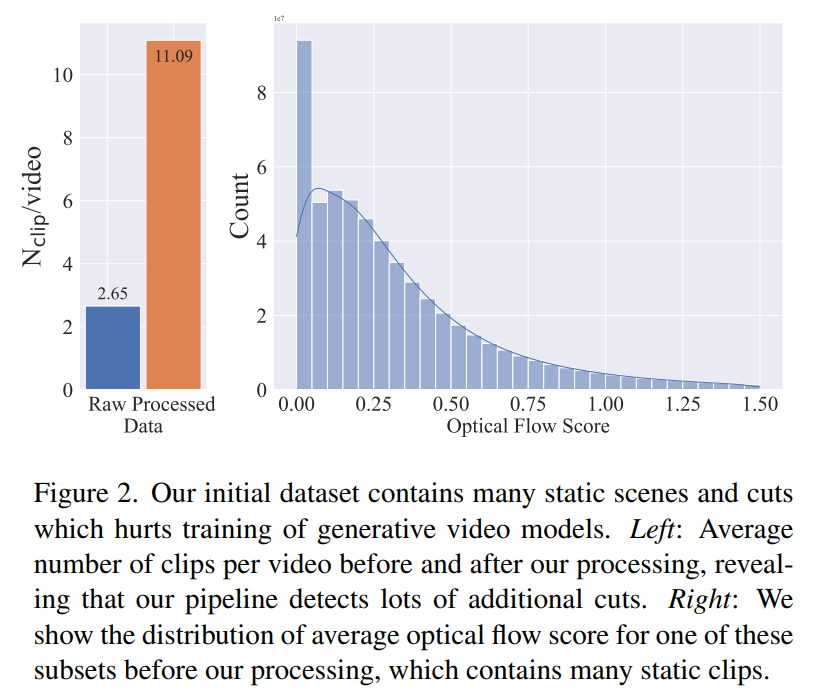
フェーズ 1: 画像の事前トレーニング。 この記事では、画像の事前トレーニングをトレーニング パイプラインの最初の段階とみなし、Stable Diffusion 2.1 上に初期モデルを構築して、ビデオ モデルに強力な視覚的表現を装備します。画像の事前トレーニングの効果を分析するために、この記事では 2 つの同一のビデオ モデルもトレーニングして比較します。図 3a の結果は、品質とキュー追跡の両方の点で、画像の事前トレーニングされたモデルが好ましいことを示しています。 この記事は、適切な事前トレーニング データセットを作成するためのシグナルとして人間の好みに依存しています。この記事で作成したデータセットは LVD (Large Video Dataset) で、5 億 8,000 万ペアの注釈付きビデオ クリップで構成されています。 さらなる調査により、生成されたデータセットには、最終的なビデオ モデルのパフォーマンスを低下させる可能性のある例がいくつか含まれていることが判明しました。したがって、この論文では、高密度オプティカル フローを使用してデータ セットに注釈を付けます
最終段階におけるビデオ事前トレーニングの影響を分析するために、この論文では、初期化のみが異なる 3 つのモデルを微調整します。図 4e に結果を示します。 
 #さらに、この論文では、光学式文字認識を適用して、大きなデータ セットを削除します。テキストクリッピングの数。最後に、CLIP 埋め込みを使用して、各クリップの最初、中間、最後のフレームに注釈を付けます。次の表は、LVD データセットの統計を示しています。
#さらに、この論文では、光学式文字認識を適用して、大きなデータ セットを削除します。テキストクリッピングの数。最後に、CLIP 埋め込みを使用して、各クリップの最初、中間、最後のフレームに注釈を付けます。次の表は、LVD データセットの統計を示しています。 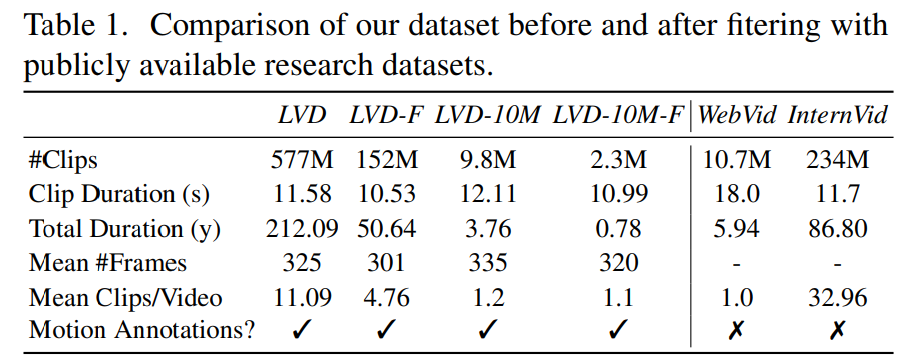
 これは良いスタートのようです。 AI を使用して直接ムービーを生成できるようになるのはいつですか?
これは良いスタートのようです。 AI を使用して直接ムービーを生成できるようになるのはいつですか?
以上が安定したビデオ拡散が登場、コードウェイトはオンラインにの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。