
ホームページ >テクノロジー周辺機器 >AI >GPT-4 はグラフ推論のパフォーマンスが低いですか? 「水を放つ」後も命中率はわずか33%
GPT-4 はグラフ推論のパフォーマンスが低いですか? 「水を放つ」後も命中率はわずか33%

- 王林転載
- 2023-11-21 08:38:56864ブラウズ
GPT-4 の図形推論能力は人間の半分以下ですか?
米国のサンタフェ研究所による研究によると、GPT-4 の図形推論問題における精度はわずか 33% です。
GPT-4v はマルチモーダル機能を備えていますが、パフォーマンスは比較的低く、質問の 25% しか正しく答えることができません
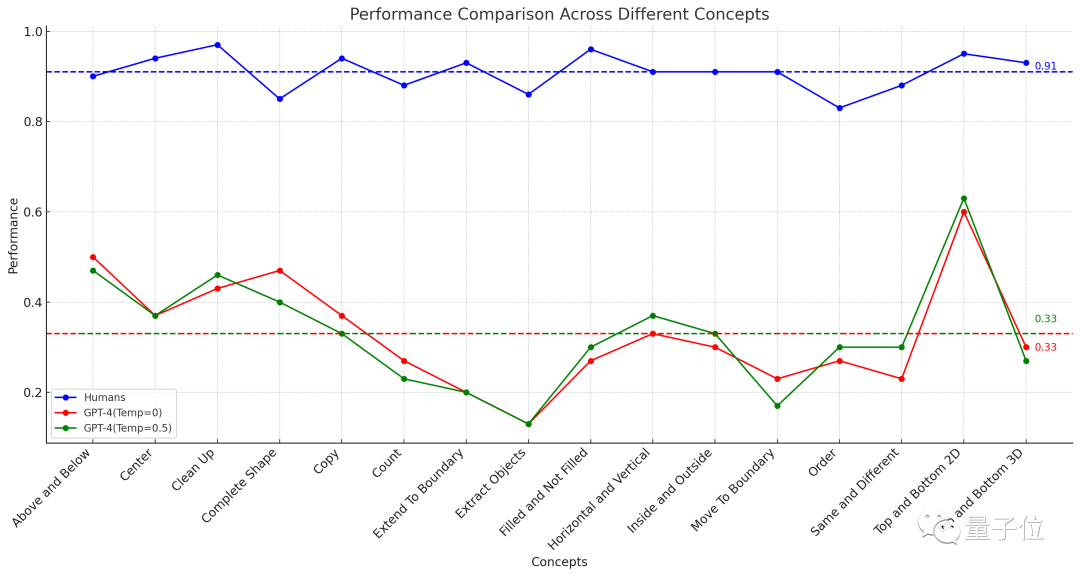
△点線16 タスクの平均パフォーマンスを示します
この実験の結果が発表されるとすぐに、YC に関する広範な議論が巻き起こりました
この結果を支持した一部のネチズンは、GPT は確かに処理能力に優れていると述べました抽象的なグラフィックス パフォーマンスが悪く、「位置」や「回転」などの概念を理解するのがより困難

しかし、一部のネチズンはこの結論に疑問を表明し、
この見解が間違っているとは言えませんが、完全に説得力があるとは言えません

次のように見解を簡単に要約できます。具体的な理由については、続きをお読みください。
GPT-4 の精度はわずか 33%です
これらのグラフィックス問題に対する人間と GPT-4 のパフォーマンスを評価するために、研究者らは今年 5 月に発売された ConceptARC データセットを使用しました。 year
ConceptARC には、グラフィカル推論問題 のサブカテゴリが合計 16 個含まれており、各カテゴリに 30 問、合計 480 問あります。

これらの 16 のサブカテゴリには、位置関係、形状、操作、比較などが含まれます。
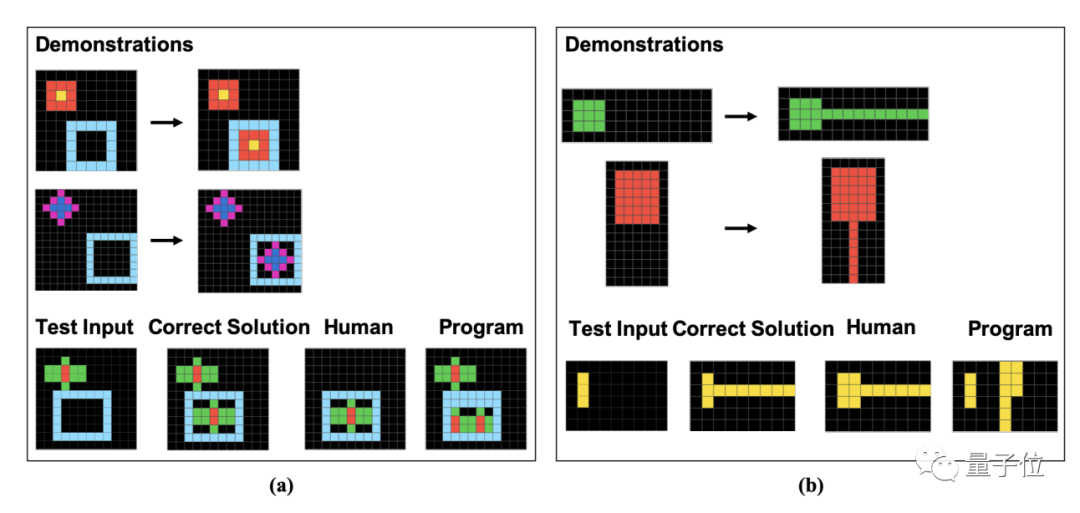
具体的には、これらの質問はピクセル ブロックで構成されています。人間と GPT は、与えられた例に基づいてパターンを見つけ、同じ方法で処理された画像の結果を分析する必要があります。
著者は、論文の中でこれら 16 のサブカテゴリの例をカテゴリごとに 1 つずつ具体的に示しています。



結果は、451 人の被験者の平均正解率が各サブ項目で 83% 以上であることを示しました。 . 16 個のタスクの平均を取ると、91% に達します。
問題が 3 回試行できる場合 (1 回正解すれば正解)、GPT-4 (単一サンプル) の最高精度は 60% を超えず、平均はわずか 33%
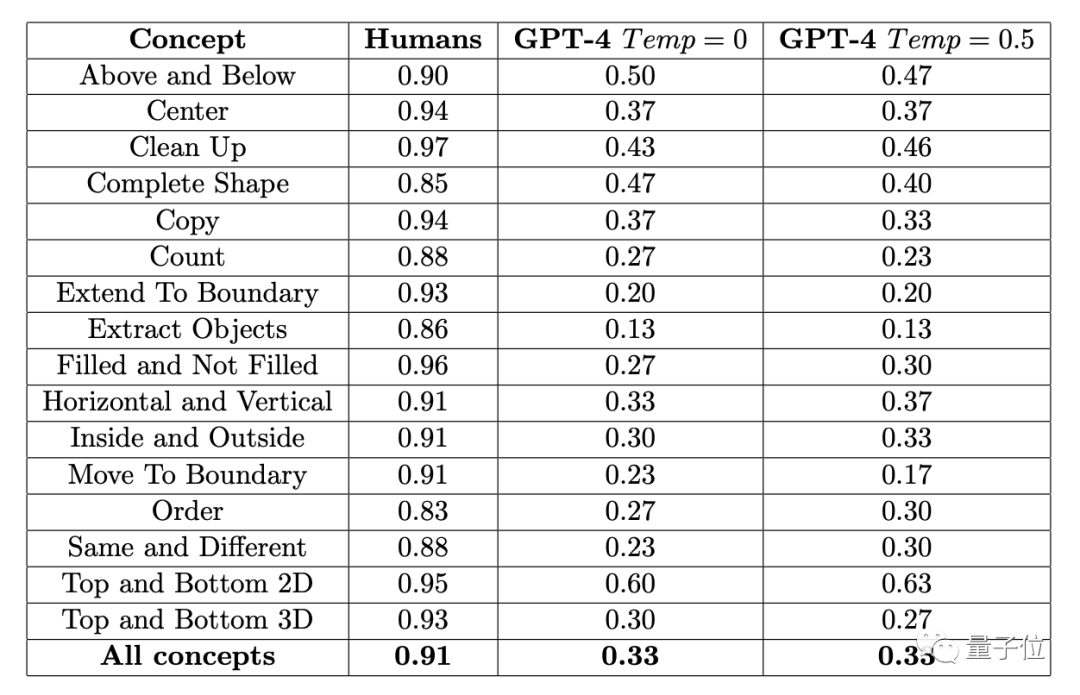
以前、この実験に参加した ConceptARC Benchmark の作成者も同様の実験を実施しましたが、GPT-4 では ゼロサンプルでしたテスト、16のタスクの平均正解率はわずか19%です。

GPT-4v はマルチモーダル モデルですが、精度が低いです。 48 の質問で構成される小規模な ConceptARC データ セットでは、ゼロサンプル テストと単一サンプル テストの正解率はそれぞれわずか 25% と 23% でした。

研究者らは、間違った回答をさらに分析した結果、 いくつかの人的ミスは「不注意」によって引き起こされる可能性が高いことが判明しましたが、GPT は質問のルールをまったく理解していませんでした ## #。
ほとんどのネチズンはこれらのデータについて何の疑問も持っていませんが、この実験に疑問を持たせているのは、募集した被験者のグループとGPTに提供された入力方法です
被験者の選択方法に疑問が生じています
当初、研究者らは Amazon のクラウドソーシング プラットフォームで被験者を募集しました。
研究者は、導入テストとしてデータセットからいくつかの簡単な質問を抽出しました。被験者は正式なテストに入る前に、3つのランダムな質問のうち少なくとも2つに正しく答える必要があります 。
研究者らが発見した結果によると、一部の人は金銭欲だけを目的に入学試験を受け、要求通りに質問を完了しない人もいるということです。
研究者らは最後の手段として、 will テストに参加するための基準は、プラットフォーム上で 2,000 個以上のタスクが完了するまで引き上げられ、合格率は 99% に達する必要があります。 ただし、著者は合格率を使って人材を選別していますが、特定の能力に関しては、英語を話せることを被験者に要求することに加えて、
その他の専門家には「特別な要件はありません」。グラフィックスなどの能力 。 データの多様性を実現するために、研究者らは実験の後半で採用活動を別のクラウドソーシング プラットフォームに移行しました。最終的に、合計 415 人の被験者がこの実験に参加しました。
これにもかかわらず、実験のサンプルが「
十分にランダムではない」という疑問を抱く人もいました。 。
一部のネチズンは、研究者が被験者を募集するために使用している Amazon のクラウドソーシング プラットフォームに、 人間を装った大きなモデルがいたと指摘しました。 #。
人間を装った大きなモデルがいたと指摘しました。 #。
#GPT のマルチモーダル バージョンの操作は比較的簡単で、画像を直接入力し、対応するプロンプトの単語を使用するだけです。
 ゼロサンプル テストでは、対応する EXAMPLE 部分を削除するだけです
ゼロサンプル テストでは、対応する EXAMPLE 部分を削除するだけです
ただし、マルチモダリティのないプレーン テキスト バージョンの GPT-4 (0613) の場合は、画像をグリッド ポイントに挿入します。
色の代わりに数字を使用します
この操作に同意しない人もいます: 画像をデジタル マトリックスに変換すると、概念は完全に変わります
、人間ですら数字で表される「グラフィック」を見ても理解できないかもしれません
One More Thing偶然にも、中国の博士課程学生、ジョイ・スーさんスタンフォード大学では、幾何学データセットで GPT-4v のグラフ理解能力もテストしており、昨年、大規模モデルによるユークリッド幾何学の理解をテストするためのデータセットがリリースされました。 GPT-4v が開かれた後、Hsu はそのデータ セットを使用して再度テストしました。その結果、GPT-4v はグラフィックスを「人間とはまったく異なる方法で」理解しているようでした。

# #論文アドレス:
[1]https://arxiv.org/abs/2305.07141[2]https://arxiv.org/abs/2311.09247
以上がGPT-4 はグラフ推論のパフォーマンスが低いですか? 「水を放つ」後も命中率はわずか33%の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。