
ホームページ >テクノロジー周辺機器 >AI >S-LoRA: 1 つの GPU で数千の大規模モデルを実行可能
S-LoRA: 1 つの GPU で数千の大規模モデルを実行可能

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-11-15 14:14:141407ブラウズ
一般に、大規模な言語モデルのデプロイメントでは、「事前トレーニング - 微調整」方法が採用されます。ただし、複数のタスク (パーソナライズされたアシスタントなど) に合わせて基礎となるモデルを微調整する場合、トレーニングとサービスのコストが非常に高くなります。 LowRank Adaptation (LoRA) は、効率的なパラメーター微調整方法であり、通常、基本モデルを複数のタスクに適応させるために使用され、それによって多数の派生 LoRA アダプターが生成されます
#書き換え: バッチ推論では、サービス提供中に多くの機会が提供され、このパターンは、アダプターの重みを微調整することによって、完全な微調整と同等のパフォーマンスを達成することが示されています。このアプローチにより、低遅延の単一アダプター推論とアダプター間でのシリアル実行が可能になりますが、複数のアダプターを同時に処理する場合、サービス全体のスループットが大幅に低下し、全体の遅延が増加します。したがって、これらの微調整されたバリアントの大規模なサービス問題を解決する方法はまだ不明です。
最近、カリフォルニア大学バークレー校、スタンフォード大学、およびその他の大学の研究者が、次のような方法を論文で提案しました。 S-LoRA の新しい微調整方法

- 論文アドレス: https://arxiv.org/pdf/2311.03285.pdf
- プロジェクトアドレス: https://github.com/S-LoRA/S-LoRA
S -LoRA は、多くの LoRA アダプターをスケーラブルに処理できるように設計されたシステムで、すべてのアダプターをメイン メモリに保存し、現在実行中のクエリで使用されているアダプターを GPU メモリにフェッチします。
S-LoRA は、統合メモリ プールを使用して、さまざまなレベルの動的アダプタの重みとさまざまなシーケンス長の KV キャッシュ テンソルを管理する「統合ページング」テクノロジを提案します。さらに、S-LoRA は、新しいテンソル並列処理戦略と高度に最適化されたカスタム CUDA カーネルを採用し、LoRA 計算の異種バッチ処理を可能にします。
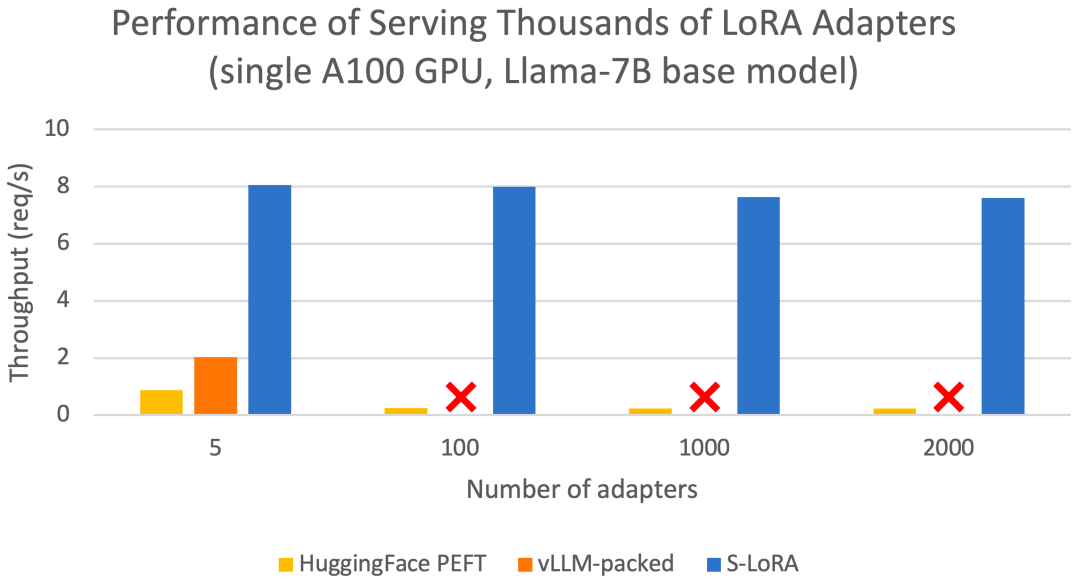
これらの機能により、S-LoRA は数分の 1 のコストで単一または複数の GPU 上で数千の LoRA アダプタ (同時に 2,000 のアダプタ) にサービスを提供でき、追加の LoRA 計算コストが最小限に抑えられます。対照的に、vLLM パックでは重みの複数のコピーを維持する必要があり、GPU メモリの制限により 5 つ未満のアダプターしか提供できません。
HuggingFace PEFT や vLLM とは異なります (状態との比較のみ) LoRA サービスなどの最新のライブラリ)、S-LoRA はスループットを最大 4 倍向上させることができ、サービス アダプタの数を数桁増やすことができます。したがって、S-LoRA は、多くのタスク固有の微調整モデルにスケーラブルなサービスを提供でき、微調整サービスの大規模なカスタマイズの可能性を提供します。
主な内容は次のとおりです:
バッチ処理
単一アダプターの場合、Hu et al. (2021) は、アダプターの重みを基本モデルの重みとマージして新しいモデルを取得するという推奨方法を提案しました。 (式 1 を参照)。この利点は、新しいモデルには基本モデルと同じ数のパラメーターがあるため、推論中にアダプターのオーバーヘッドが追加されないことです。実際、これは初期の LoRA 作業の特徴的な機能でもありました
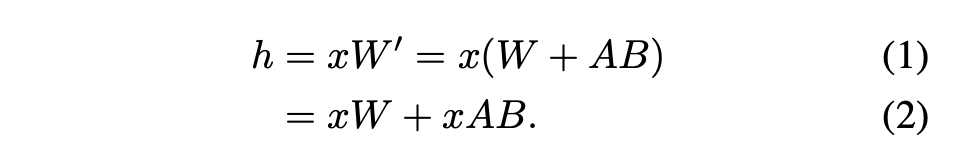 ##この記事では、LoRA アダプターを基本モデル Medium は、複数の LoRA 高スループット サービスのセットアップには非効率的です。代わりに、研究者らは、LoRA をリアルタイムで計算して xAB を計算することを提案しています (式 2 に示すように)。
##この記事では、LoRA アダプターを基本モデル Medium は、複数の LoRA 高スループット サービスのセットアップには非効率的です。代わりに、研究者らは、LoRA をリアルタイムで計算して xAB を計算することを提案しています (式 2 に示すように)。
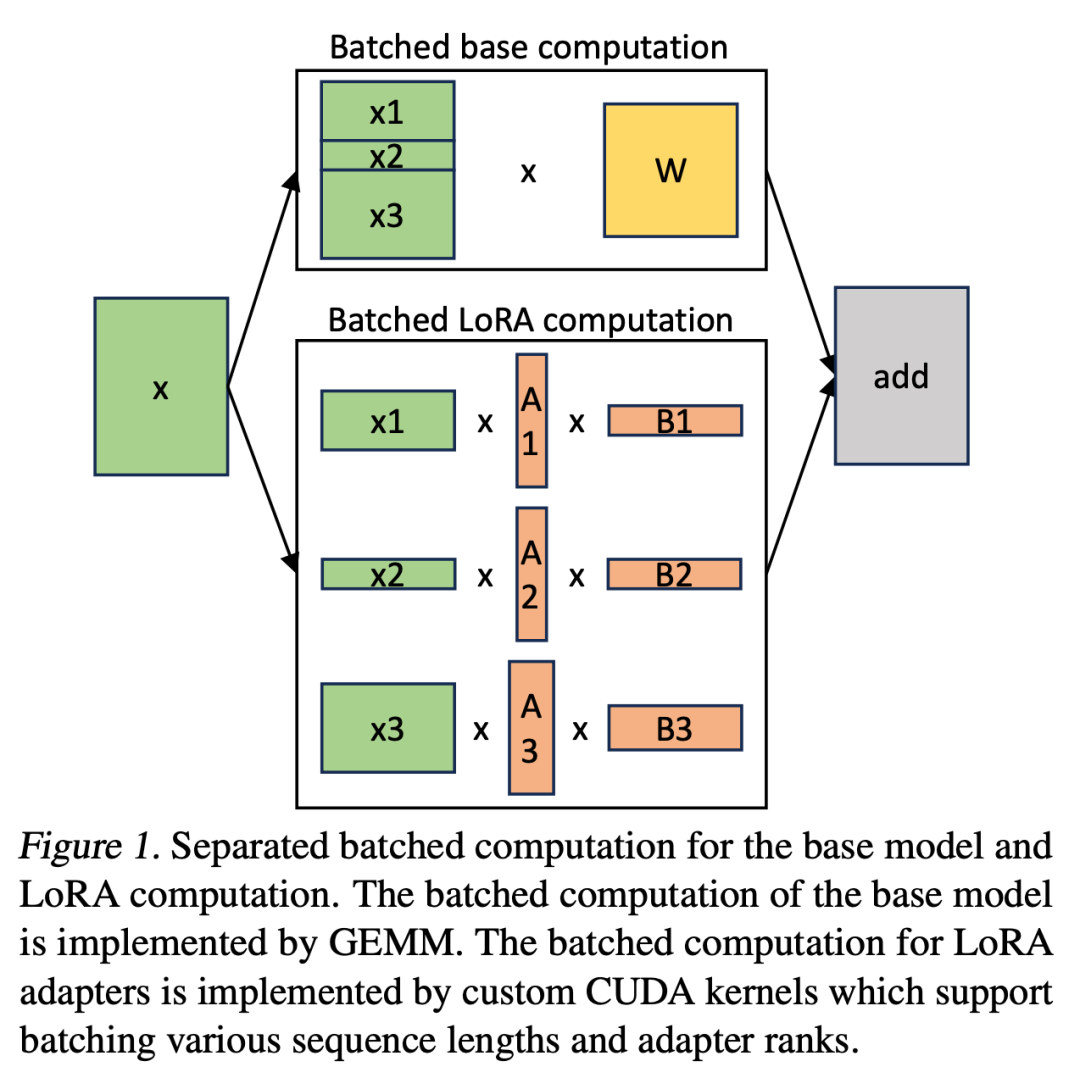
S-LoRA では、基本モデルの計算がバッチ処理され、カスタム CUDA カーネルを使用してすべてのアダプターに対して追加の xAB が個別に実行されます。このプロセスを図 1 に示します。 LoRA を計算するために BLAS ライブラリからのパディングとバッチ処理された GEMM カーネルを使用する代わりに、カスタム CUDA カーネルを実装してパディングなしでより効率的な計算を実現しました。実装の詳細はサブセクション 5.3 にあります。
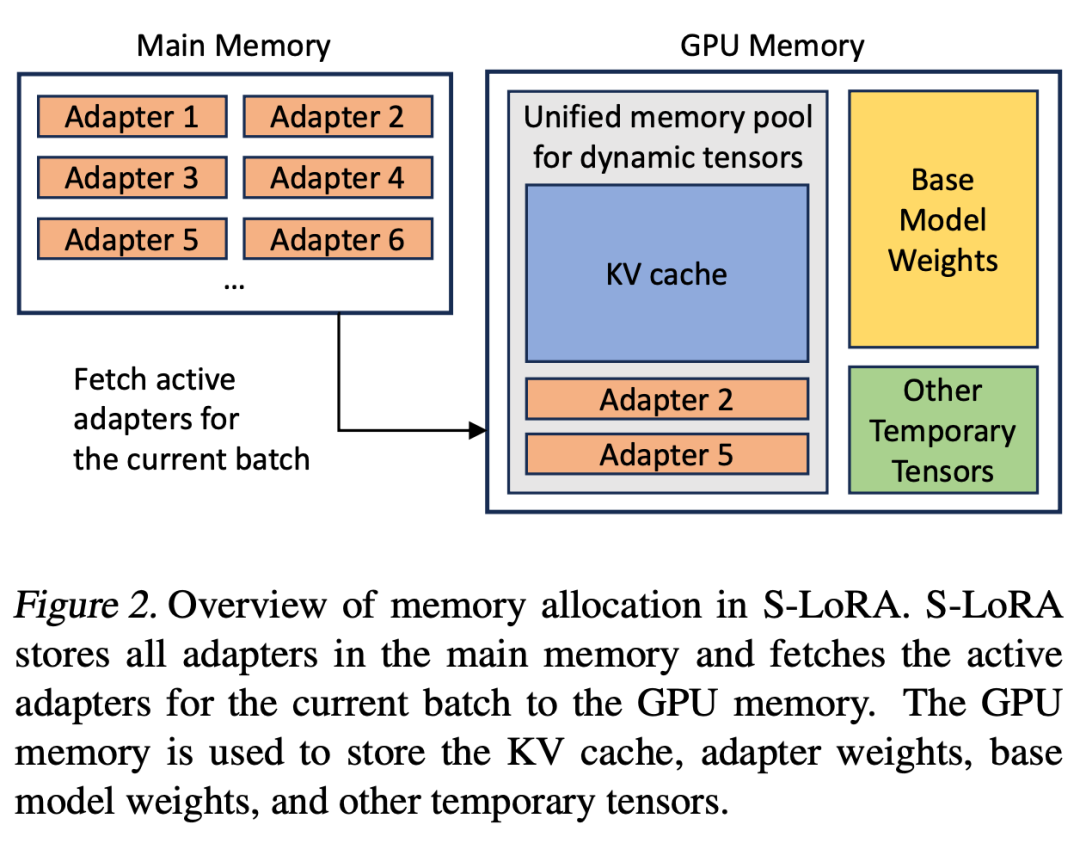
LoRA アダプターがメイン メモリに保存されている場合、その数は大きくなる可能性がありますが、バッチを実行するために現在必要な LoRA アダプターの数は制御可能ですバッチサイズは GPU メモリによって制限されるためです。これを利用するために、すべての LoRA アダプターをメイン メモリに保存し、現在実行中のバッチを推論するときに、そのバッチに必要な LoRA アダプターのみを GPU RAM にフェッチします。この場合、サービス可能なアダプタの最大数はメイン メモリ サイズによって制限されます。図 2 は、このプロセスを示しています。セクション 5 では、効率的なメモリ管理の手法についても説明します
単一ベースのメモリ管理
サービス モデルでは、複数の LoRA アダプタ カードを同時にサービスすると、メモリ管理に新たな課題が生じます。複数のアダプタをサポートするために、S-LoRA はそれらをメイン メモリに保存し、現在実行中のバッチに必要なアダプタの重みを GPU RAM に動的にロードします。
このプロセスには、明らかな課題が 2 つあります。 1 つ目はメモリの断片化の問題です。これは、異なるサイズのアダプターの重みを動的にロードおよびアンロードすることによって発生します。 2 つ目は、アダプターのロードとアンロードによって発生する遅延オーバーヘッドです。これらの問題を効果的に解決するために、研究者は「統合ページング」の概念を提案し、アダプターの重みをプリフェッチすることで I/O と計算の重複を実現しました
統合ページング
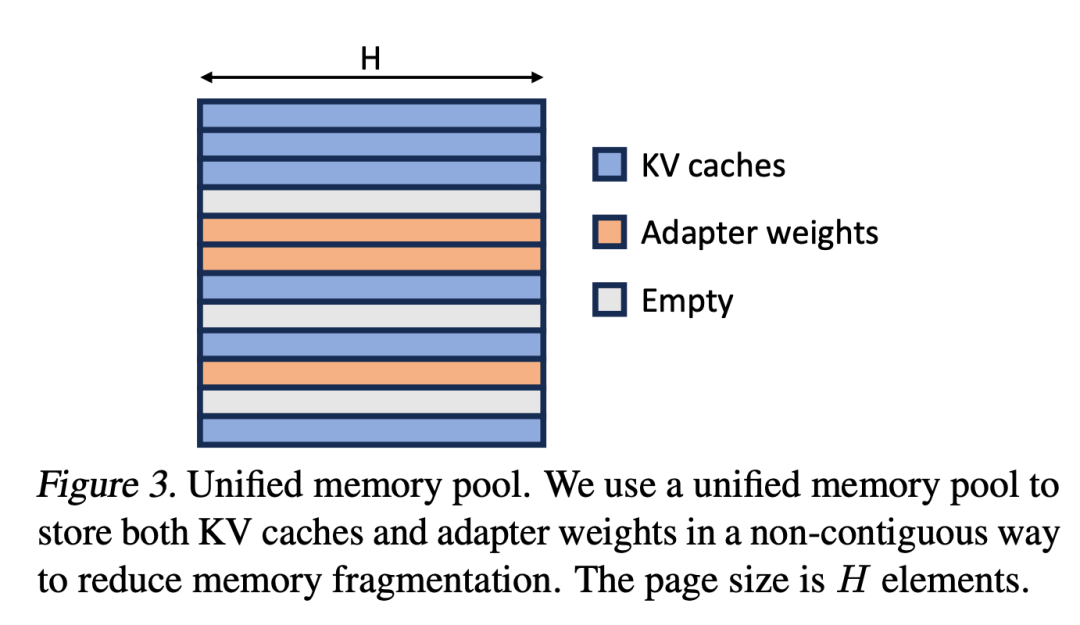
研究者らは、PagesAttention の概念を Unified Paging に拡張しました。統合ページングは、KV キャッシュの管理だけでなく、アダプターの重みの管理にも使用されます。ユニファイド ページングは、ユニファイド メモリ プールを使用して、KV キャッシュとアダプタの重みを共同で管理します。これを達成するために、最初に大きなバッファをメモリ プールに静的に割り当てます。これにより、基本モデルの重みと一時的なアクティベーション テンソルを格納するために使用されるスペースを除くすべての利用可能なスペースが利用されます。 KV キャッシュとアダプターの重みはページ化された方法でメモリ プールに保存され、各ページは H ベクトルに対応します。したがって、シーケンス長 S の KV キャッシュ テンソルは S ページを占有し、R レベルの LoRA 重みテンソルは R ページを占有します。図 3 は、メモリ プールのレイアウトを示しています。KV キャッシュとアダプタの重みは、インターリーブされた非連続的な方法で格納されています。このアプローチにより断片化が大幅に軽減され、さまざまなレベルのアダプターの重みが構造的かつ体系的な方法で動的 KV キャッシュと共存できるようになります。
Tensor並列
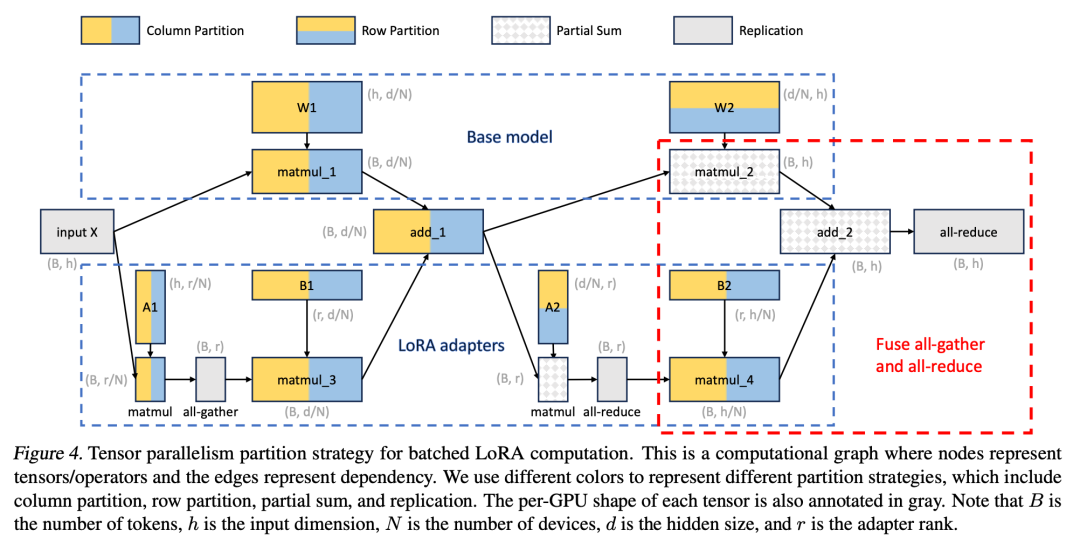
さらに、研究者らは、大規模な Transformer モデルのマルチ GPU 推論をサポートするバッチ LoRA 推論用の新しいテンソル並列戦略を設計しました。テンソル並列処理は、単一プログラム、複数データのパラダイムにより実装と既存システムとの統合が簡素化されるため、最も広く使用されている並列アプローチです。 Tensor 並列処理により、大規模なモデルを処理する際の GPU あたりのメモリ使用量とレイテンシーを削減できます。この設定では、追加の LoRA アダプターにより新しい重み行列と行列の乗算が導入され、これらの追加には新しい分割戦略が必要になります。
評価
最終的に、研究者たちはラマ-7B/13B/30B/のテストに合格しました。 70B S-LoRA の評価に役立つ
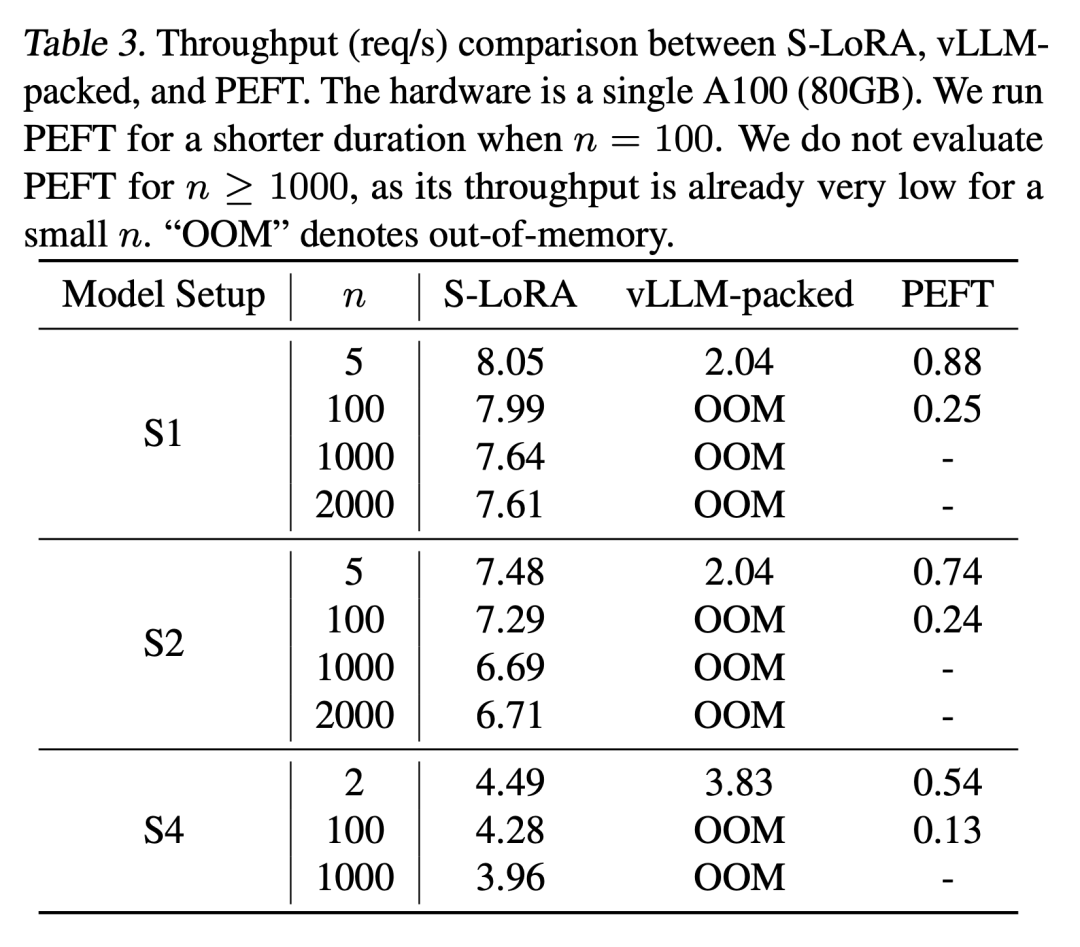
結果は、S-LoRA が単一 GPU または複数の GPU で数千の LoRA アダプターにサービスを提供できることを示しています。オーバーヘッドは非常に小さいです。 S-LoRA は、最先端のパラメータ効率の高い微調整ライブラリである Huggingface PEFT と比較して、最大 30 倍高いスループットを実現します。 S-LoRA は、LoRA サービスをサポートする高スループット サービス システム vLLM を使用する場合と比較して、スループットを 4 倍に向上させ、サービス アダプタの数を数桁増やすことができます。
研究の詳細については、元の論文を参照してください。
###以上がS-LoRA: 1 つの GPU で数千の大規模モデルを実行可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- Haimo スーパーコンピューティング センターの公式発表: 1,000 億のパラメーターを持つ大規模モデル、100 万クリップのデータ規模、トレーニング コストの 200 倍の削減
- メタ研究者が AI の新たな試みを行う:地図やトレーニングなしで物理的に移動するようにロボットに教える
- Pytorch を使用して自己教師あり事前トレーニング用の対照学習 SimCLR を実装する
- 言語モデル、グラフ ニューラル ネットワーク、テキスト グラフ トレーニング フレームワーク GLEM を効果的に統合して、新しい SOTA を実現します
- Microsoft Excelグラフにデータラベルを追加およびカスタマイズするにはどうすればよいですか?