
ホームページ >テクノロジー周辺機器 >AI >新しいタイトル: NVIDIA H200 リリース: HBM 容量が 76% 増加、大規模モデルのパフォーマンスが 90% 大幅に向上する最も強力な AI チップ
新しいタイトル: NVIDIA H200 リリース: HBM 容量が 76% 増加、大規模モデルのパフォーマンスが 90% 大幅に向上する最も強力な AI チップ

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-11-14 15:21:131428ブラウズ

11月14日のニュース、Nvidiaは現地時間13日朝の「Supercomputing 23」カンファレンスで新しいH200 GPUを正式にリリースし、GH200製品ラインをアップデートしました
その中で、H200 は依然として既存の Hopper H100 アーキテクチャに基づいて構築されていますが、人工知能の開発と実装に必要な大規模なデータ セットをより適切に処理するために、より多くの高帯域幅メモリ (HBM3e) が追加され、大規模なモデルの実行が可能になります。前世代のH100と比較して60%~90%向上しました。アップデートされた GH200 は、次世代の AI スーパーコンピューターにも搭載されます。 2024 年には 200 エクサフロップスを超える AI コンピューティング能力が稼働する予定です。
H200: HBM 容量が 76% 増加、大型モデルのパフォーマンスが 90% 向上
具体的には、新しい H200 は最大 141 GB の HBM3e メモリを提供し、実質的に約 6.25 Gbps で動作し、6 つの HBM3e スタックの GPU ごとに合計 4.8 TB/秒の帯域幅を実現します。これは、前世代の H100 (80GB HBM3 および 3.35 TB/秒の帯域幅を搭載) と比較して大幅な改善であり、HBM 容量が 76% 以上増加しています。公式データによると、大規模モデルを実行する場合、H200 は H100 と比較して 60% (GPT3 175B) ~ 90% (Llama 2 70B) の改善をもたらします


H100 の一部の構成では、2 つのボードをペアにして合計 188GB のメモリ (GPU あたり 94GB) を提供する H100 NVL など、より多くのメモリを提供しますが、H100 SXM バリアントと比較しても、新しい H200 SXM はまた、メモリ容量が 76% 増加し、帯域幅が 43% 増加します。
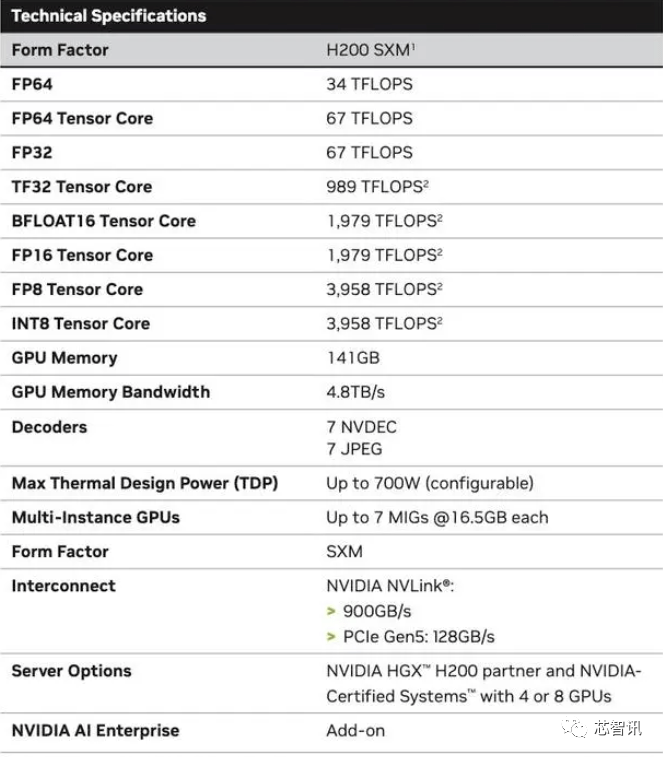
H200 の生のコンピューティング パフォーマンスはあまり変わっていないように見えることを指摘しておく必要があります。 Nvidia が示した唯一のスライドは、反映されたコンピューティング パフォーマンスが 8 つの GPU を使用した HGX 200 構成に基づいており、合計パフォーマンスが「32 PFLOPS FP8」であることを示しています。オリジナルの H100 は 3,958 テラフロップスの FP8 演算能力を提供しましたが、8 つのそのような GPU は約 32 PFLOPS の FP8 演算能力も提供します
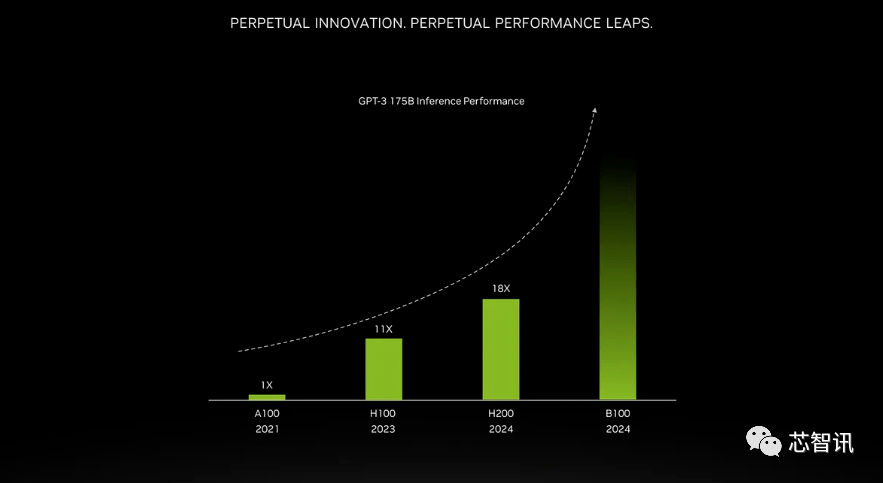
より高い帯域幅メモリによってもたらされる改善は、ワークロードによって異なります。大規模モデル (GPT-3 など) は、HBM メモリ容量の増加から大きな恩恵を受けます。 Nvidia によると、H200 は、GPT-3 を実行した場合、オリジナルの A100 よりも最大 18 倍優れたパフォーマンスを発揮し、H100 よりも約 11 倍高速になります。さらに、次期 Blackwell B100 のティーザーには、黒にフェードインする背の高いバーが含まれていることが示されています。これは、一番右の H200 のおよそ 2 倍の長さです
それだけでなく、H200とH100は相互に互換性があります。つまり、H100 トレーニング/推論モデルを使用している AI 企業は、最新の H200 チップにシームレスに切り替えることができます。クラウド サービス プロバイダーは、H200 を自社の製品ポートフォリオに追加する際に変更を加える必要はありません。
NVIDIA は、新製品を発売することで、人工知能モデルとサービスの作成に使用されるデータセットのサイズの増大に追いつきたいと述べています。強化されたメモリ機能により、H200 はソフトウェアにデータを供給するプロセスが高速化され、画像や音声の認識などのタスクを実行する人工知能のトレーニングに役立ちます。
「より高速で大容量の HBM メモリを統合することで、GPU の使用量と効率を最適化しながら、生成 AI モデルやハイパフォーマンス コンピューティング アプリケーションなどの計算負荷の高いタスクのパフォーマンスを向上させることができます。」
NVIDIA のデータセンター製品責任者、ディオン・ハリス氏は次のように述べています。「市場開発の傾向を見ると、これは当社がどのように最新かつ最高のテクノロジーを導入し続けているかを示す一例です。」メインフレーム コンピューター メーカーとクラウド サービス プロバイダーは、2024 年の第 2 四半期に H200 の使用を開始する予定です。 NVIDIA サーバー製造パートナー (Evergreen、Asus、Dell、Eviden、Gigabyte、HPE、Hongbai、Lenovo、Wenda、MetaVision、Wistron、Wiwing など) は、H200 を使用して既存のシステムを更新できますが、Amazon、Google、Microsoft、Oracle なども同様です。は、H200 を採用する最初のクラウド サービス プロバイダーになります。
NVIDIA AI チップに対する現在の強い市場需要と、より高価な HBM3e メモリを追加した新しい H200 を考慮すると、H200 の価格は間違いなくより高価になります。 Nvidiaは価格を公表していないが、前世代のH100の価格は2万5000ドルから4万ドルだった。
NVIDIA の広報担当者クリスティン内山氏は、最終的な価格は NVIDIA の製造パートナーによって決定されると述べました
H200 の発売が H100 の生産に影響を与えるかどうかについて、クリスティン内山氏は次のように述べています。「年間の総供給量は増加すると予想しています。」
Nvidia のハイエンド AI チップは、大量のデータを処理し、大規模な言語モデルと AI 生成ツールをトレーニングするのに最適な選択肢であると常に考えられています。しかし、H200 チップが発売されたとき、AI 企業はまだ市場で A100/H100 チップを必死に探していました。市場の注目は引き続き、エヌビディアが市場の需要を満たす十分な供給を提供できるかどうかにある。したがって、NVIDIA は、H200 チップが H100 チップと同様に供給不足になるかどうかについては答えていませんしかし、来年は GPU 購入者にとってより有利な時期となる可能性があります。8 月の Financial Times の報道によると、NVIDIA は 2024 年に H100 の生産を 3 倍に増やす計画であり、生産目標は 2023 年の約 500,000 から 2023 年までに増加する予定です。 2024年には200万人。しかし、生成 AI は依然としてブームであり、将来的には需要がさらに高まる可能性があります。
たとえば、新しく発売された GPT-4 は、約 10,000 ~ 25,000 個の A100 ブロックでトレーニングされます。 Meta の大規模 AI モデルのトレーニングには、約 21,000 個の A100 ブロックが必要です。スタビリティ AI は約 5,000 台の A100 を使用します。 Falcon-40B のトレーニングには 384 A100 が必要です
マスク氏によると、GPT-5 には 30,000 ~ 50,000 H100 が必要になる可能性があります。モルガン・スタンレーの見積もりは 25,000 GPU です。
Sam Altman 氏は GPT-5 のトレーニングを否定しましたが、「OpenAI では GPU が深刻に不足しており、当社の製品を使用する人が少なければ少ないほど良い」と述べました。
もちろん、NVIDIA に加えて、AMD や Intel も NVIDIA に対抗するために AI 市場に積極的に参入しています。 AMDが以前に発売したMI300Xは、192GBのHBM3と5.2TB/秒のメモリ帯域幅を搭載しており、容量と帯域幅の点でH200をはるかに上回ります。
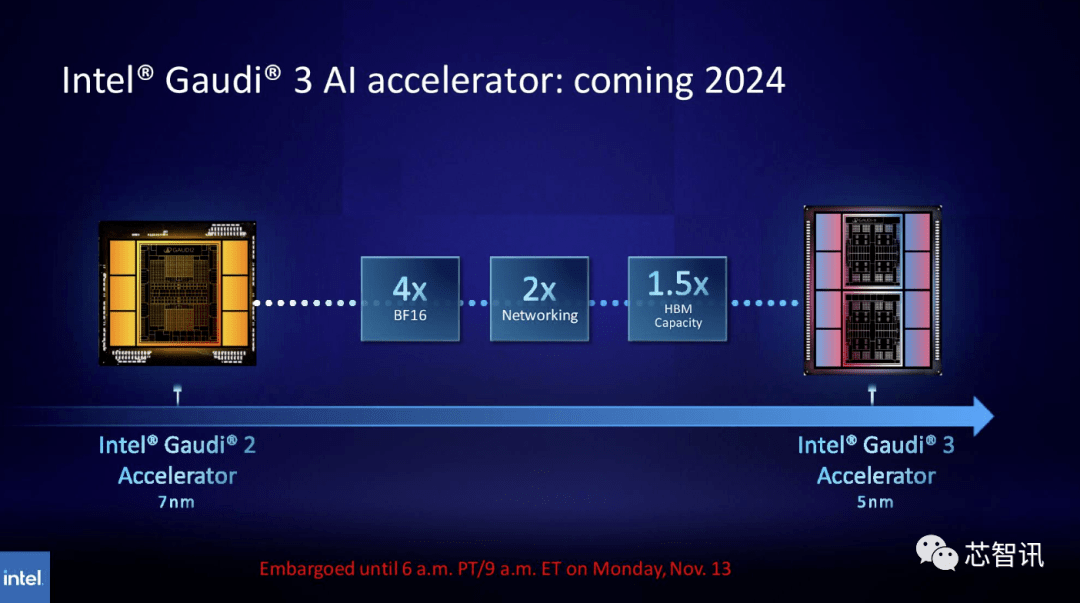
同様に、Intel は Gaudi AI チップの HBM 容量を増やすことを計画しています。最新のリリース情報によると、Gaudi 3 は 5nm プロセスを使用しており、BF16 ワークロードでのパフォーマンスは Gaudi 2 の 4 倍、ネットワーク パフォーマンスも Gaudi 2 の 2 倍になります (Gaudi 2 には 24 個の 100 個のプロセッサが内蔵されています) GbE RoCE NIC)。さらに、Gaudi 3 には Gaudi 2 の 1.5 倍の HBM 容量があります (Gaudi 2 の HBM2E は 96 GB)。下の写真からわかるように、Gaudi 3 は、Intel のシングルチップ ソリューションを使用する Gaudi 2 とは異なり、2 つのコンピューティング クラスターを備えたチップレット ベースの設計を使用しています
新しい GH200 スーパーチップ: 次世代の AI スーパーコンピューターを強化
新しい H200 GPU のリリースに加えて、NVIDIA は GH200 スーパー チップのアップグレード バージョンも発売しました。このチップは、NVIDIA NVLink-C2C チップ相互接続テクノロジを使用し、最新の H200 GPU と Grace CPU (アップグレード バージョンかどうかは不明) を組み合わせています。各 GH200 スーパー チップには合計 624 GB のメモリも搭載されます

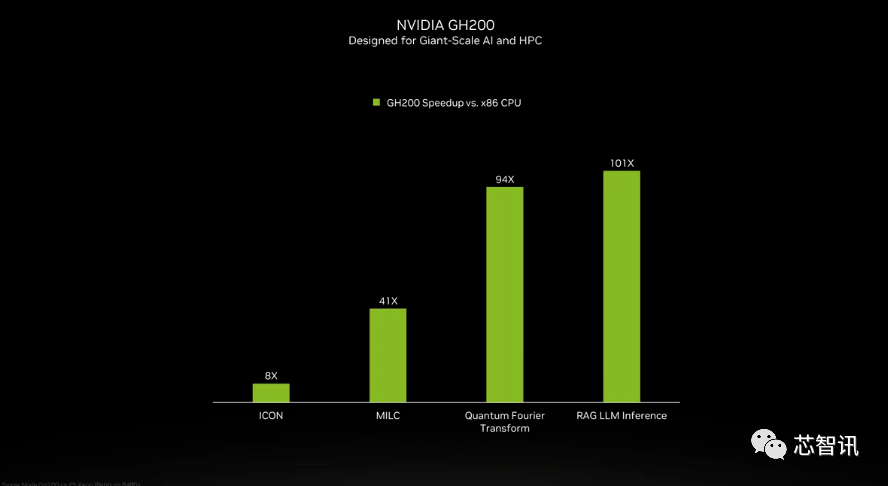
NVIDIA は GH200 スーパー チップの Grace CPU の詳細を紹介しませんでしたが、NVIDIA は GH200 と「最新のデュアルソケット x86 CPU」との比較をいくつか提供しました。 GH200 は ICON のパフォーマンスを 8 倍向上させ、MILC、量子フーリエ変換、RAG LLM 推論などは数十倍、さらには数百倍の向上をもたらしていることがわかります。
新しい GH200 は、新しい HGX H200 システムでも使用されます。これらは既存の HGX H100 システムと「シームレスな互換性」があると言われており、HGX H200 を同じインストールで使用して、インフラストラクチャを再設計することなくパフォーマンスとメモリ容量を向上させることができます。
報道によると、スイス国立スーパーコンピューティング センターの Alpine スーパーコンピューターは、来年使用される GH100 ベースの Grace Hopper スーパーコンピューターの最初のバッチの 1 つになる可能性があります。米国で運用を開始する最初の GH200 システムは、ロス アラモス国立研究所の Venado スーパーコンピューターとなります。テキサス アドバンスト コンピューティング センター (TACC) Vista システムも、発表されたばかりの Grace CPU と Grace Hopper スーパーチップを使用しますが、それらが H100 と H200 のどちらをベースにするかは不明です

現在、設置される最大のスーパーコンピューターは、ジュリッヒ スーパーコンピューティング センターの Jupiter スーパーコンピューターです。これには「ほぼ」24,000 個の GH200 スーパーチップが搭載され、合計 93 エクサフロップスの AI コンピューティング (おそらく FP8 を使用しますが、ほとんどの AI は依然として BF16 または FP16 を使用しています)。また、従来の FP64 コンピューティングの 1 エクサフロップスも提供します。 GH200スーパーチップを4個搭載した「Quad GH200」ボードを採用する。
NVIDIA が今後 1 年ほどで設置する予定のこれらの新しいスーパーコンピューターは、合計で 200 エクサフロップスを超える人工知能の計算能力を実現します
元の意味を変更する必要がない場合は、内容を中国語に書き直す必要があり、元の文を表示する必要はありません
以上が新しいタイトル: NVIDIA H200 リリース: HBM 容量が 76% 増加、大規模モデルのパフォーマンスが 90% 大幅に向上する最も強力な AI チップの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。