


大手モデルをベンチマーク評価に騙されないでください。テストセットは事前トレーニングにランダムに含まれており、スコアは誤って高く、モデルは愚かになります。


「大規模なモデルをベンチマーク評価に騙されないでください。」
これは、人民大学情報学部、ヒルハウス人工知能学部、イリノイ大学アーバナシャンペーン校による最新の研究のタイトルです。

調査によると、ベンチマーク テストの関連データが誤ってモデル トレーニングに使用されることがますます一般的になりつつあります。
事前学習コーパスには多くの公開テキスト情報が含まれており、評価ベンチマークもその情報に基づいているため、この状況は避けられません。
現在、大規模モデルがより多くの公開データを収集しようとしているため、問題は悪化しています。
この種のデータの重複によって引き起こされる害は非常に大きいことを知っておく必要があります。
これにより、モデルの一部のテスト スコアが誤って高くなるだけでなく、モデルの汎化能力が低下し、無関係なタスクのパフォーマンスが急激に低下することになります。実際のアプリケーションでは、大型モデルが「害」を引き起こす可能性もあります。
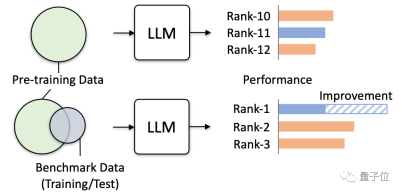
そこで、この研究は正式に警告を発し、特に複数のシミュレーションテストを通じて誘発される可能性のある実際の危険を検証しました。
大規模モデルが「質問を見逃す」ことは非常に危険です
この研究では、極端なデータ漏洩状況をシミュレートすることで、主に大規模モデルの影響をテストおよび観察しています。
データを極度に漏洩させる方法は 4 つあります。
- MMLU のトレーニング セットを使用します
- MMLU を除くすべてのテスト ベンチマークのトレーニング セットを使用します
- すべてのトレーニング セットを使用してプロンプトをテストします
- すべてのトレーニング セット、テスト セット、およびテスト プロンプトを使用します (これは最も極端なケースであり、単なる実験シミュレーションであり、通常の状況では起こりません)
その後、研究者らは 4 つの大規模モデルを「汚染」し、さまざまなベンチマークでパフォーマンスを観察し、主に質疑応答、推論、読解などのタスクにおけるパフォーマンスを評価しました。
使用されるモデルは次のとおりです:
- GPT-Neo (1.3B)
- phi-1.5 (1.3B)
- OpenLLaMA (3B)
- LLaMA-2 (7B)
LLaMA (13B/30B/65B) を対照グループとして使用します。
その結果、大規模モデルの事前トレーニング データに特定の評価ベンチマークのデータが含まれている場合、その評価ベンチマークではパフォーマンスが向上しますが、関連しない他のタスクではパフォーマンスが低下することがわかりました。
たとえば、MMLU データセットでトレーニングした後、MMLU テストでは複数の大規模モデルのスコアが向上しましたが、常識ベンチマーク HSwag と数学ベンチマーク GSM8K のスコアは低下しました。
これは、大規模モデルの汎化能力が影響を受けることを示しています。

一方で、無関係なテストで誤って高いスコアが得られる可能性もあります。
上記のように大規模モデルを「汚染」するために使用された 4 つのトレーニング セットには、少量の中国語データのみが含まれていますが、大規模モデルが「汚染」された後の C3 (中国語ベンチマーク テスト) のスコアは、全部高くなりました。
この増加は不合理です。

この種のトレーニング データの漏洩により、モデル テストのスコアが大規模モデルのパフォーマンスを異常に超える可能性もあります。
たとえば、phi-1.5 (1.3B) は、RACE-M および RACE-H で LLaMA65B よりも優れたパフォーマンスを発揮します。後者は前者の 50 倍のサイズです。
しかし、このようなスコアの増加は無意味です、それはただの不正行為です。
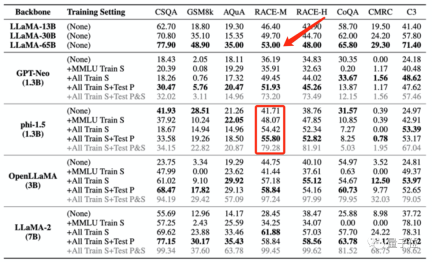
さらに深刻なのは、データ漏洩が発生していないタスクにも影響が及び、パフォーマンスが低下することです。
以下の表からわかるように、コード タスク HEval では、両方の大規模モデルのスコアが大幅に低下しています。
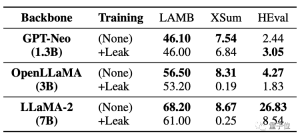
データが同時に漏洩した後、大規模モデルの 微調整の改善は、漏洩がなかった状況に比べてはるかに劣っていました。

この調査では、データの重複/漏洩が発生した場合のさまざまな可能性を分析します。
たとえば、大規模なモデルの事前トレーニング コーパスやベンチマーク テスト データは公開テキスト (Web ページ、論文など) を使用するため、重複は避けられません。
そして現在、大規模なモデルの評価はローカルで実行されるか、結果は API 呼び出しを通じて取得されます。この方法では、一部の異常な数値増加を厳密にチェックすることはできません。
と現在の大規模モデルの事前トレーニング コーパスは、すべての関係者によって中核的な秘密とみなされており、外部から評価することはできません。
これにより、大規模なモデルが誤って「汚染」されてしまいました。
この問題を回避するにはどうすればよいですか?研究チームはいくつかの提案も行った。
それを回避するにはどうすればよいですか?
研究チームは 3 つの提案を行いました:
まず、実際の状況ではデータの重複を完全に回避することは難しいため、大規模なモデルでは複数のベンチマーク テストを使用してより包括的な評価を行う必要があります。
第二に、大規模モデル開発者の場合、データの感度を下げ、トレーニング コーパスの詳細な構成を公開する必要があります。
第三に、ベンチマーク管理者に対しては、ベンチマーク データ ソースを提供し、データ汚染のリスクを分析し、より多様なプロンプトを使用して複数の評価を実施する必要があります。
ただし、研究チームは、この研究には依然として一定の限界があるとも述べています。たとえば、さまざまな程度のデータ漏洩を体系的にテストすることはなく、シミュレーションの事前トレーニングでデータ漏洩を直接導入することもできません。
この研究は、中国人民大学情報学部、ヒルハウス人工知能学部、イリノイ大学アーバナシャンペーン校の多くの学者が共同で行ったものです。
研究チームでは、データ マイニング分野の 2 人の巨人、Wen Jiron と Han Jiawe を発見しました。
Wen Jironong 教授は現在、ヒルハウス人工知能大学院の学部長および中国人民大学情報学部の学部長を務めています。主な研究方向は、情報検索、データマイニング、機械学習、大規模ニューラル ネットワーク モデルのトレーニングと応用です。
ハン ジアウェイ教授 ハン ジアウェイ教授は、データ マイニング分野の専門家で、現在イリノイ大学アーバナ校のコンピューター サイエンス学科の教授を務めています。 Champaign 氏は、米国コンピュータ協会の会員であり、IEEE 会員でもあります。
論文アドレス: https://arxiv.org/abs/2311.01964。
以上が大手モデルをベンチマーク評価に騙されないでください。テストセットは事前トレーニングにランダムに含まれており、スコアは誤って高く、モデルは愚かになります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Huggingface smollmであなたの個人的なAIアシスタントを構築する方法Apr 18, 2025 am 11:52 AM
Huggingface smollmであなたの個人的なAIアシスタントを構築する方法Apr 18, 2025 am 11:52 AMオンデバイスAIの力を活用:個人的なチャットボットCLIの構築 最近では、個人的なAIアシスタントの概念はサイエンスフィクションのように見えました。 ハイテク愛好家のアレックスを想像して、賢くて地元のAI仲間を夢見ています。
 メンタルヘルスのためのAIは、スタンフォード大学でのエキサイティングな新しいイニシアチブによって注意深く分析されますApr 18, 2025 am 11:49 AM
メンタルヘルスのためのAIは、スタンフォード大学でのエキサイティングな新しいイニシアチブによって注意深く分析されますApr 18, 2025 am 11:49 AMAI4MHの最初の発売は2025年4月15日に開催され、有名な精神科医および神経科学者であるLuminary Dr. Tom Insel博士がキックオフスピーカーを務めました。 Insel博士は、メンタルヘルス研究とテクノでの彼の傑出した仕事で有名です
 2025年のWNBAドラフトクラスは、成長し、オンラインハラスメントの成長と戦いに参加しますApr 18, 2025 am 11:44 AM
2025年のWNBAドラフトクラスは、成長し、オンラインハラスメントの成長と戦いに参加しますApr 18, 2025 am 11:44 AM「私たちは、WNBAが、すべての人、プレイヤー、ファン、企業パートナーが安全であり、大切になり、力を与えられたスペースであることを保証したいと考えています」とエンゲルバートは述べ、女性のスポーツの最も有害な課題の1つになったものに取り組んでいます。 アノ
 Pythonビルトインデータ構造の包括的なガイド-AnalyticsVidhyaApr 18, 2025 am 11:43 AM
Pythonビルトインデータ構造の包括的なガイド-AnalyticsVidhyaApr 18, 2025 am 11:43 AM導入 Pythonは、特にデータサイエンスと生成AIにおいて、プログラミング言語として優れています。 大規模なデータセットを処理する場合、効率的なデータ操作(ストレージ、管理、アクセス)が重要です。 以前に数字とstをカバーしてきました
 Openaiの新しいモデルからの代替案からの第一印象Apr 18, 2025 am 11:41 AM
Openaiの新しいモデルからの代替案からの第一印象Apr 18, 2025 am 11:41 AM潜る前に、重要な注意事項:AIパフォーマンスは非決定論的であり、非常にユースケース固有です。簡単に言えば、走行距離は異なる場合があります。この(または他の)記事を最終的な単語として撮影しないでください。これらのモデルを独自のシナリオでテストしないでください
 AIポートフォリオ| AIキャリアのためにポートフォリオを構築する方法は?Apr 18, 2025 am 11:40 AM
AIポートフォリオ| AIキャリアのためにポートフォリオを構築する方法は?Apr 18, 2025 am 11:40 AM傑出したAI/MLポートフォリオの構築:初心者と専門家向けガイド 説得力のあるポートフォリオを作成することは、人工知能(AI)と機械学習(ML)で役割を確保するために重要です。 このガイドは、ポートフォリオを構築するためのアドバイスを提供します
 エージェントAIがセキュリティ運用にとって何を意味するのかApr 18, 2025 am 11:36 AM
エージェントAIがセキュリティ運用にとって何を意味するのかApr 18, 2025 am 11:36 AM結果?燃え尽き症候群、非効率性、および検出とアクションの間の隙間が拡大します。これは、サイバーセキュリティで働く人にとってはショックとしてはありません。 しかし、エージェントAIの約束は潜在的なターニングポイントとして浮上しています。この新しいクラス
 Google対Openai:学生のためのAIの戦いApr 18, 2025 am 11:31 AM
Google対Openai:学生のためのAIの戦いApr 18, 2025 am 11:31 AM即時の影響と長期パートナーシップ? 2週間前、Openaiは強力な短期オファーで前進し、2025年5月末までに米国およびカナダの大学生にChatGpt Plusに無料でアクセスできます。このツールにはGPT ‑ 4o、Aが含まれます。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

