
ホームページ >テクノロジー周辺機器 >AI >FMCW レーダー位置認識をエレガントに実装する方法 (IROS2023)
FMCW レーダー位置認識をエレガントに実装する方法 (IROS2023)

- 王林転載
- 2023-10-26 11:13:011495ブラウズ
皆さん、こんにちは。私の名前はYuan Jianhaoです。IROS2023でレーダー位置認識に関する私たちの取り組みを共有するために、Heart of Autonomous Drivingプラットフォームに来ることができてとてもうれしく思います。
周波数変調連続波 (FMCW) レーダーを使用した測位は、困難な環境に対する固有の耐性により、関心が高まっています。ただし、レーダー測定プロセスの複雑なアーチファクトには、この有望なセンサー モダリティの安全で信頼性の高いアプリケーションを確保するために、適切な不確実性の推定が必要です。この研究では、さらなる位置特定のために、埋め込み空間で学習された分散特性に基づいて「最適な」マップを構築するマルチセッション マップ管理システムを提案します。同じ分散特性を使用して、不正確である可能性のある位置決めクエリを内省的に拒否する新しい方法も提案します。この目的を達成するために、我々は、走行経路に沿ったレーダーデータの短時間スケールの変動を利用し(データ拡張のため)、また、計量空間ベースの位置識別における下流の不確実性を予測する、堅牢なノイズ認識計量学習を適用します。私たちは、オックスフォード レーダー RobotCar および MulRan データセットに対する広範な相互検証テストを通じて、アプローチの有効性を実証します。ここでは、単一の最近傍クエリのみを使用して、レーダー位置識別およびその他の不確実性を認識する方法における現在の最先端技術を上回ります。また、不確実性に基づいてクエリを拒否すると、困難なテスト環境でパフォーマンスが向上することも示されました。これは、競合する不確実性を認識した位置認識システムでは観察されませんでした。
レーダーの出発点から外れる
位置の特定と位置特定は、ロボット工学と自律システムの分野における重要なタスクです。これにより、システムが理解して、その環境をナビゲートします。従来の視覚ベースの位置認識方法は、照明、天候、オクルージョンなどの環境条件の変化の影響を受けやすいことが多く、その結果、パフォーマンスが低下します。この問題に対処するために、この敵対的な環境で堅牢なセンサーの代替手段として FMCW レーダーを使用することへの関心が高まっています。
既存の研究では、FMCW レーダー位置認識のための手作りの学習ベースの特徴抽出方法の有効性が実証されています。既存の研究は成功しているにもかかわらず、自動運転などの安全性が重要なアプリケーションへのこれらの手法の導入は、校正の不確かさの推定値によって依然として制限されています。この分野では、次の点を考慮する必要があります:
- セキュリティでは、内省的な拒否を可能にするために、不確実性の推定値が誤検知率で適切に調整される必要があります。
- リアルタイム展開では、次のことが必要です。高速であること 単一スキャンの不確実性に基づく推論機能;
- 長期自律走行における繰り返しのルート走査には、オンラインでの継続的な地図メンテナンスが必要です。
VAE は一般に生成タスクに使用されますが、その確率的潜在空間は、位置認識のための効果的な計量空間表現として機能し、データ ノイズ分布に関するアプリオリな仮定を可能にし、標準化された偶発的空間も提供します。不確実性の推定。したがって、この論文では、自動運転におけるFMCWレーダーの信頼性と安全な展開を達成するために、変分対比学習フレームワークを利用し、統一された不確実性ベースのレーダー位置識別方法を提案します。
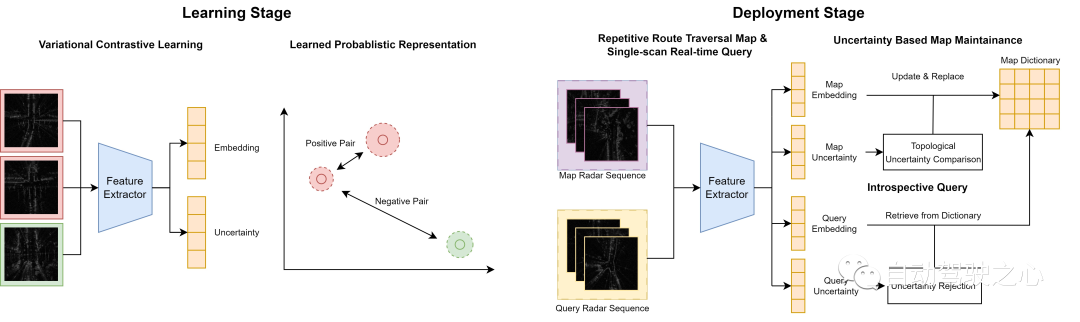 システム プロセスの概要
システム プロセスの概要
オフライン段階では、変分対比学習フレームワークを使用して、同様のトポロジ上の位置からのレーダーがスキャンに近いなど、推定の不確実性を伴う隠れた埋め込み空間を学習します。お互い、そしてその逆も同様です。オンライン段階では、推論と地図構築のために継続的に収集されたレーダー スキャンを処理するための 2 つの不確実性ベースのメカニズムを開発しました。同じルートを繰り返し通過する場合、不確実性の高いスキャンをより確実なスキャンに置き換えることにより、統合された地図辞書を積極的に維持します。不確実性が低いクエリ スキャンの場合、メトリック空間距離に基づいて辞書から一致するマップ スキャンを取得します。対照的に、不確実性の高いスキャンの予測は拒否されます。
オフ ザ レーダーの方法の紹介
この記事では、位置特定における不確実性を説明するために、レーダー位置特定のための変分コントラスト学習フレームワークを紹介します。主な貢献には以下が含まれます:
- 不確実性を認識するためのコントラスト学習フレームワーク。
- キャリブレーションの不確実性推定に基づく内省的なクエリ メカニズム。
- 環境の変化に対応するオンライン再帰的マップ メンテナンス。
変分対照学習
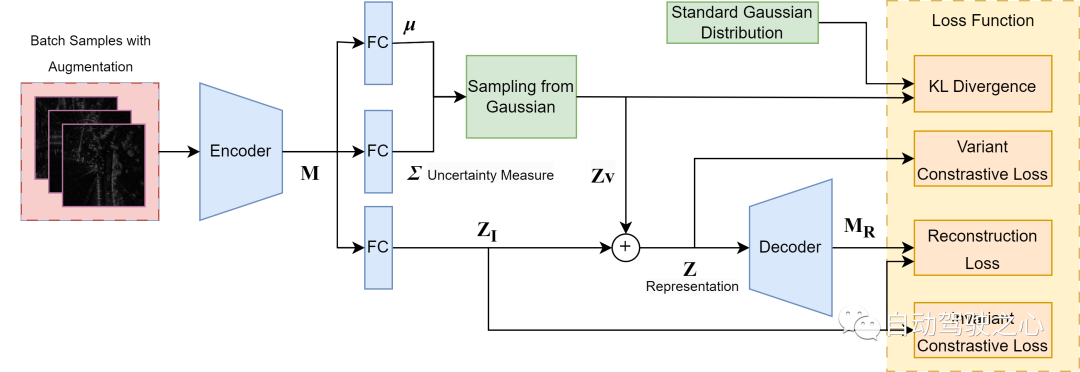
[^Lin2018dvml] に基づく変分対照学習フレームワークの概要。エンコーダ別- デコーダ構造は、2 つの再パラメータ化された部分を含む計量空間を学習します。認識のための決定論的埋め込みと、分散を不確実性の尺度として持つ多変量ガウス分布をモデル化するパラメータのセットです。全体的な学習は、再構築とコントラスト損失の両方によって推進され、レーダー スキャンの有益かつ識別可能な隠蔽表現を保証します。
この部分の作業は、私たちの中心的な貢献を実現する重要な要素であり、深変分計量学習とレーダー位置認識の新たな統合、および位置認識における不確実性を表現する新しい方法の両方です。図に示すように、レーダースキャン埋め込みを、予測とは無関係な不確実性源の分散を捉えるノイズ起因の可変部分と、シーン表現のための意味的に不変な部分に分解する構造を採用する。可変部分は、後で事前の多変量等二乗ガウス分布からサンプリングされ、不変部分に追加されて全体の表現が形成されます。変数出力は不確実性の尺度として直接使用されます。データの固有のあいまいさとランダム性によって引き起こされるモデル予測における偶発的な不確実性のみを不確実性の主な原因として考慮すると仮定します。特にレーダー スキャンの場合、スペックル ノイズ、飽和、一時的なオクルージョンが原因である可能性があります。標準的な計量学習方法は、選択された損失関数に関係なく、正の例のペア間の潜在的な分散を無視しながら、それらのペア間に同一の埋め込みを強制する傾向があります。ただし、これにより、モデルが小さな特徴に鈍感になり、トレーニング分布が過剰適合する可能性があります。したがって、ノイズ分散をモデル化するには、構造内の追加の確率的分散出力を使用して、偶然の不確実性を推定します。このようなノイズを意識したレーダー認識表現を構築するために、トレーニング全体をガイドするために 4 つの損失関数を使用します。
1) 決定論的表現 (Z_I) 上の不変コントラスト損失 により、タスクに無関係なノイズをレーダーのセマンティクスから分離し、不変埋め込みに十分な因果情報が含まれるようにします。および
2) 可変コントラスト損失全体の表現 (Z) 上で意味のある計量空間を確立します。両方のコントラスト損失は次の形式になります。
バッチの 1 つは、m 個のサンプルと、「回転」戦略を使用した合成回転の時間的に近似されたフレーム拡張で構成されます。これは、回転不変性のための回転拡張にすぎません。私たちの目標は、反転ケースの確率を最小限に抑えながら、拡張サンプルが元のインスタンスとして認識される確率を最大にすることです。
ここで、式 1) および 2) で説明されているように、埋め込み (Z) は (Z_I) または (Z) です。
3) カルバック・ライブラー (KL) 発散 学習されたガウス分布と標準の等方性多変量ガウス分布の間、これはデータ ノイズのアプリオリな仮定です。これにより、すべてのサンプルにわたって同じノイズ分布が保証され、変数出力の絶対値の静的参照が提供されます。
4) 再構成損失 抽出された特徴マップ (M) とデコーダー出力 (M_R) の間で、全体の表現 (Z) に元のレーダー スキャンからの十分な情報が含まれるようになります。再建。ただし、復号化プロセスの計算コストを削減するために、ピクセルレベルのレーダースキャン再構成ではなく、低次元の特徴マップのみを再構成します。
KL 発散と再構成損失のみによって駆動される通常の VAE 構造も潜在的な分散を提供しますが、よく知られている事後崩壊および分散消失問題の推定により、不確実性の下での使用には信頼性が低いと考えられています。この非効率性は主に、トレーニング中の 2 つの損失の不均衡によるものです。KL 発散が優勢な場合、事後潜在空間は強制的に事前空間と等しくなりますが、再構成損失が優勢な場合、潜在分散はゼロに押しやられます。ただし、私たちのアプローチでは、追加の正則化子として可変コントラスト損失を導入することで、より安定したトレーニングを実現します。分散は、計量空間内のクラスター中心間の堅牢な境界を維持するために駆動されます。その結果、レーダー知覚における潜在的な偶然の不確実性を反映する、より信頼性の高い潜在的な空間分散が得られます。私たちは、特徴量を増加させた損失設定での不確実性を学習するための特定のアプローチの利点を実証することを選択しました。この分野では、レーダー位置認識の最先端技術はすでに多くの (つまり 2 つ以上の) 負のサンプルによる損失を使用しているため、これをベースに拡張します。
継続的な地図メンテナンス
自動運転車の運行中に取得したスキャンデータを最大限に活用し、地図の継続的なメンテナンスを改善することを目的としているため、継続的な地図メンテナンスはオンライン システムの重要な機能です。マップを再帰的に作成します。新しいレーダー スキャンを以前に通過したスキャンで構成される親マップに結合するプロセスは次のとおりです。各レーダー スキャンは、隠れた表現と不確実性メトリックによって表されます。マージ プロセス中に、しきい値を下回るトポロジー距離を持つ新しいスキャンごとに、一致する陽性サンプルを検索します。新しいスキャンの不確実性が低い場合、そのスキャンは親マップに統合され、一致するスキャンと置き換えられます。そうでない場合は、破棄されます。
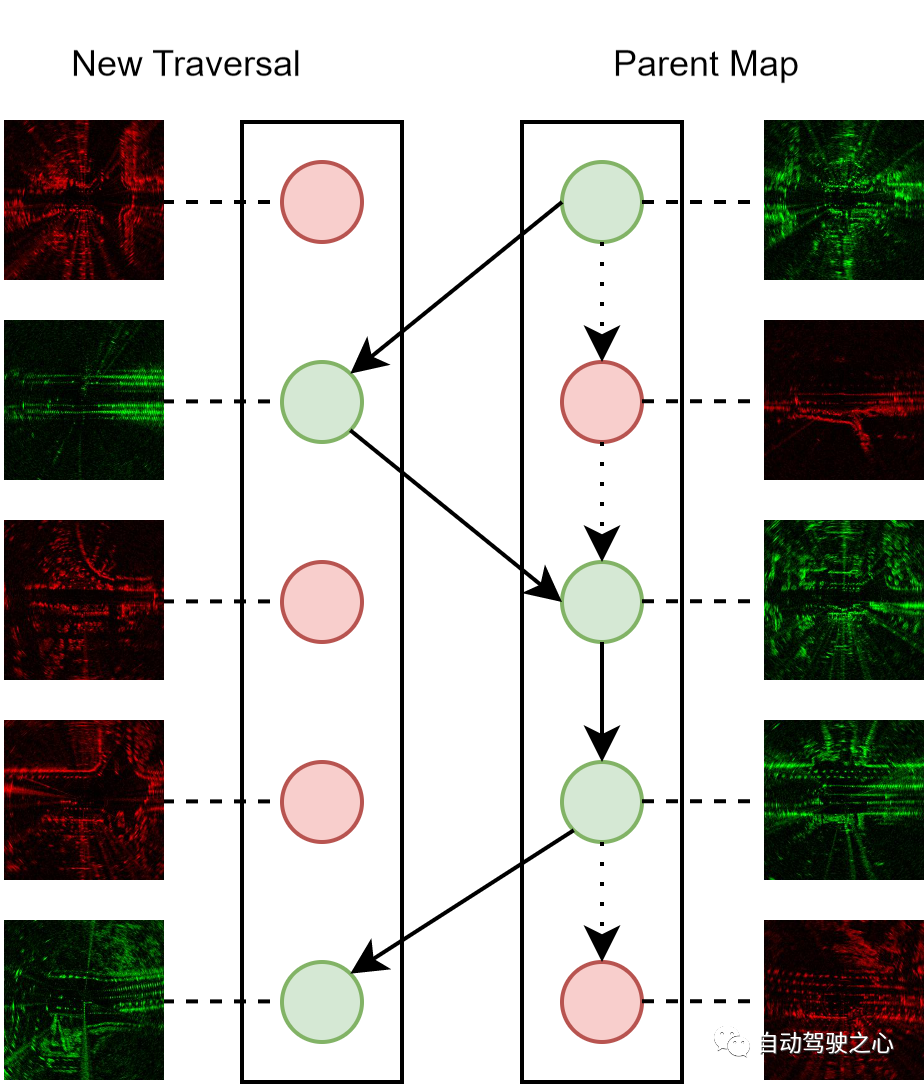
マップ メンテナンスの図: 赤と緑のノードは、それぞれ不確実性が高く、低いレーダー スキャンを表します。当社では、各位置の位置決め基準として、不確実性が最も低いスキャンのみで構成される親マップを常に維持しています。破線のエッジは親マップの初期状態を表し、実線のエッジは親マップの更新されたバージョンを表すことに注意してください。
メンテナンス プロセスを繰り返し実行することで、統合された親マップの品質を徐々に向上させることができます。したがって、メンテナンス アルゴリズムは、同じルート トラバースの複数のエクスペリエンスを継続的に活用して認識パフォーマンスを向上させると同時に、親マップのサイズを一定に維持し、その結果、計算コストとストレージ コストの予算がかかるため、効果的なオンライン展開戦略として機能します。
イントロスペクション クエリ
標準ガウス分布からの測定によるモデルの不確実性により、すべての次元の推定分散は 1 に近くなります。したがって、2 つのハイパーパラメータ \Delta と N を使用して、不確実性除去のスケールと解像度を完全に定義できます。結果として得られるしきい値 T は次のように定義されます。
m 次元の潜在分散を伴うスキャンを考慮して、すべての次元で平均してスカラー不確実性の尺度を取得します
予測拒否
推論時に、内省的なクエリ拒否を実行します。定義されたしきい値を超える分散を持つクエリ スキャンは、識別のために拒否されます。 STUN や MC Dropout などの既存の方法では、サンプルのバッチの不確実性の範囲をしきい値レベルに動的に分割します。ただし、これには推論中に複数のサンプルが必要であり、特にサンプル数が少ない場合には、拒否パフォーマンスが不安定になる可能性があります。対照的に、当社の静的しきい値処理戦略は、サンプルに依存しないしきい値レベルを提供し、一貫した単一スキャンの不確かさの推定と拒否を提供します。運転中にレーダースキャンがフレームごとに取得されるため、この機能は位置認識システムのリアルタイム展開にとって重要です。
実験の詳細
この記事では、1) Oxford Radar RobotCar と 2) MulRan の 2 つのデータ セットを使用します。どちらのデータ セットも CTS350-X Navtech FMCW スキャニング レーダーを使用します。レーダー システムは 76 GHz ~ 77 GHz の範囲で動作し、解像度 4.38 cm で最大 3768 の範囲の読み取り値を生成できます。
ベンチマーク の認識パフォーマンスは、元の VAE、Gadd et を含むいくつかの既存の方法と比較することによって行われます。 al によって提案された最新のレーダー サイト識別方法 (BCRadar と呼ばれる)、および非学習ベースの方法 RingKey (ScanContext の一部、回転改良なし)。さらに、パフォーマンスは、不確実性を考慮した場所認識のベースラインとして機能する MC Dropout および STUN と比較されます。
アブレーション研究提案した内省的クエリ (Q) モジュールとマップ保守 (M) モジュールの有効性を評価するために、メソッドのさまざまなバリアントを比較することでアブレーション研究を実行しました。それぞれ次のように表されます。 OURS(O/M/Q/QM)、詳細は次のとおりです:
- O: マップ メンテナンスなし、イントロスペクション クエリなし
- M: マップ メンテナンスのみ
- Q: イントロスペクション クエリのみ
- QM: マップ メンテナンスとイントロスペクション クエリの両方 具体的には、O と M の間の認識パフォーマンスと、Q と QM の間の推定パフォーマンスの不確実性を比較しました。
共通設定 公平な比較を確保するために、すべての対比学習ベースの手法に共通のバッチ対比損失を採用し、その結果、ベンチマーク損失関数全体で一貫したパフォーマンスが得られます。
実装の詳細
スキャン設定
すべての方法で、A = 400 方位、B = 3768 セルの極座標が得られます。レーダースキャンはデカルトスキャンに変換され、各ボックスのサイズは 4.38 cm、辺の長さは W = 256、ボックスのサイズは 0.5 m でした。
トレーニング ハイパーパラメータ
VGG-19 [^simonyan2014very^] を背景特徴抽出器として使用し、線形レイヤーを使用して抽出された特徴をより低い埋め込み次元 d=128 に投影します。 。すべてのベースラインを Oxford Radar RobotCar で 10 エポック、 MulRan で 15 回反復し、学習率 1e{-5} でトレーニングしました。 、バッチサイズは 8 です。
評価指標
位置認識パフォーマンスを評価するには、 Recall@N (R@N) ##を使用します。 #Metric。N 個の候補のうち少なくとも 1 個の候補が GPS/INS によって示されるグランド トゥルースに近いかどうかを判断することによって決定される位置特定の精度です。これは、システムの偽陰性率の調整を反映するため、自動運転アプリケーションにおける安全性の保証にとって特に重要です。また、 平均精度 (AP) を使用して、すべての再現レベルにわたる平均精度を測定します。最後に、 F スコア と \beta=2/1/0.5 # を使用します。 ##全体的な認識性能を評価するための包括的な指標として、再現率の重要度を精度に割り当てます。 さらに、不確実性推定性能を評価するため。
Recall@RR を使用します。ここで、内省的なクエリ拒否を実行し、さまざまな不確実性しきい値レベル =1## で Recall@N を評価します。 #--スキャンの不確実性がしきい値より大きいクエリをすべて拒否します。結果として、クエリの 0 ~ 100% が拒否されます。 結果の概要
位置認識性能
オックスフォードレーダーロボットカー実験の表1に示すように、私たちの方法はメトリック学習モジュールのみを使用すると、すべてのメトリックで最高のパフォーマンスが達成されました。具体的には、
Recall@1 の観点から、私たちのメソッド OURS(O) は、変分対比学習フレームワークを通じて学習された分散分離表現を示しています。 90.46%以上の認識性能。これは、表 2 に示すように、 MulRan 実験結果によってさらに裏付けられ、我々の方法は Recall@1 で最高のパフォーマンスを示します。全体的に F スコア と AP は他のすべての方法よりも優れています。 MulRan 実験では、VAE は Recall@5/10 において私たちの方法よりも優れていますが、私たちの方法は2 つの設定 F-1/0.5/2 および AP ## の中で最適な設定# は、この方法の精度と再現率が高く、より正確で堅牢な認識パフォーマンスを実現していることを示しています。
bold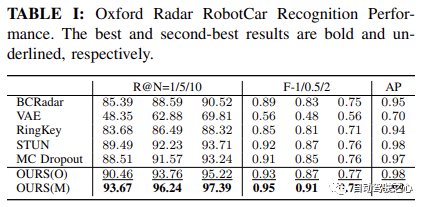 と __underline__ です。
と __underline__ です。
Mulran の認識パフォーマンス。形式は上記と同じです。
さらに、Oxford Radar RobotCar の継続的な地図メンテナンスをさらに活用することで、 Recall@1 を 93.67% にさらに向上させることができ、現在の最先端の方法である STUN は、これを 4.18% 上回っています。これは、効果的な不確実性尺度としての学習された分散の有効性と、場所認識パフォーマンスの向上における不確実性ベースの地図統合戦略の有効性をさらに示しています。
#不確実性推定のパフォーマンス
拒否される不確実なクエリの割合が増加すると、識別パフォーマンスが変化します。特に、 Recall@1, Oxford Radar RobotCar 実験の図 1 に示すように、 MulRan 実験 2 の図 1 に示すように。特に、私たちの方法は、両方の実験設定で不確実なクエリの拒否率が増加するにつれて、認識パフォーマンスが継続的に向上していることを実証する唯一の方法です。 MulRan 実験では、拒否率が増加するにつれて Recall@RR 指標を着実に改善し続ける唯一の方法は、OURS(Q) です。私たちの方法と同様にモデルの不確実性を推定する VAE や STUN と比較すると、OURS(Q) は Recall@RR=0.1/0.2/0.5 以内にあり、 (1.32/3.02/8.46)%の改善がみられましたが、VAEとSTUNはそれぞれ-(3.79/5.24/8.80)%と-(2.97/4.16/6.30)%減少しました。
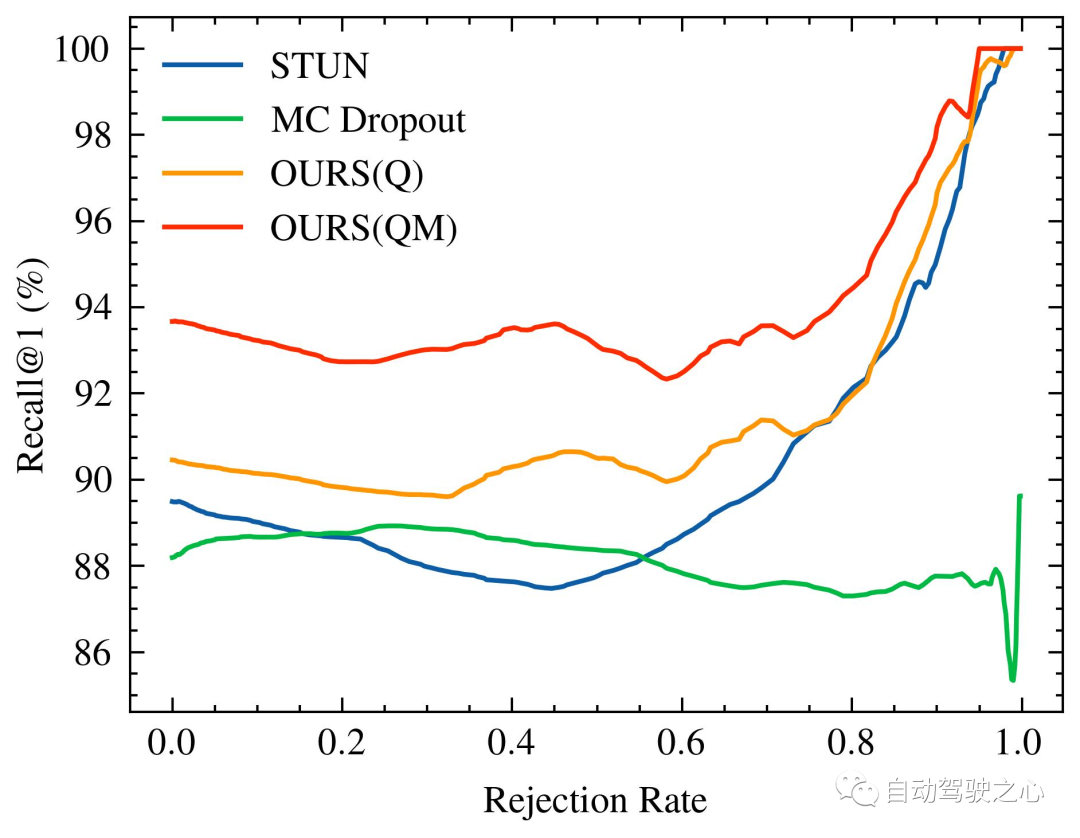
Recall@1 は、拒否された不定クエリの割合が増加するにつれて増加/減少します。 VAE のパフォーマンスは他の方法と比較して低いため (具体的には、Recall@RR=0.1/0.2/0.5 の (48.42/48.08/18.48)%)、視覚化は実行されませんでした。
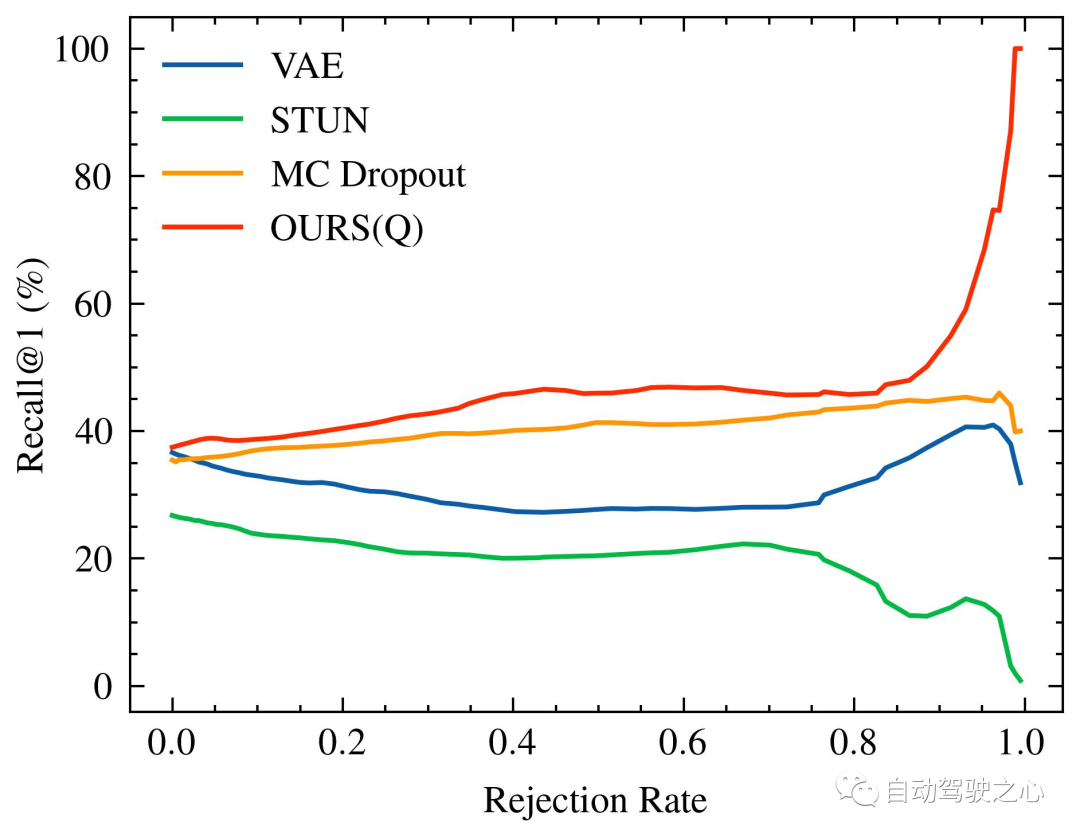
#Recall@1 は増加しましたが、そのパフォーマンスは全体的に当社のパフォーマンスよりも低く、拒否率がさらに上昇したため、大幅な改善を達成できませんでした。最後に、オックスフォード レーダー ロボットカー実験で OURS(Q) と OURS(QM) を比較すると、 Recall@RR の変化パターンが類似していることが観察されました。と彼らの間にはかなりの隔たりがあります。これは、内省的なクエリと地図の保守メカニズムが独立して場所認識システムに寄与し、それぞれが統合的な方法で不確実性の尺度を活用していることを示唆しています。
定性分析と可視化
レーダー知覚における不確実性を定性的に評価するには、不確実性の原因、私たちの方法を使用して推定された 2 つのデータセットにおける不確実性の高いサンプルと低いサンプルの視覚的な比較を提供します。図に示すように、不確実性の高いレーダー スキャンでは通常、大きなモーション ブラーとまばらな未検出領域が示されますが、不確実性の低いスキャンでは、ヒストグラムに強度が強い明確な特徴が含まれています。
具有不同不確定性等級的雷達掃描的可視化。左邊的四個範例來自Oxford Radar RobotCar Dataset,而右邊的四個範例來自MulRan。我們展示了具有最高 (頂部) / 最低 (底部) 不確定性的前10個樣本。雷達掃描以增強對比度的笛卡爾座標顯示。每個影像下方的直方圖顯示了從所有方位角提取的強度的RingKey描述子特徵。
這進一步支持了我們關於雷達感知中不確定性來源的假設,並作為我們的不確定性測量捕獲這種數據噪聲的定性證據。
資料集差異
在我們的基準實驗中,我們觀察到兩個資料集之間的辨識效能有相當大的差異。我們認為可用訓練資料的規模可能是合理的原因。 Oxford Radar RobotCar的訓練集包括超過300Km的駕駛經驗,而 MulRan資料集只包括大約120Km。然而,也考慮到RingKey描述符方法的效能下降。這表明雷達場景感知中可能存在固有的不可區分的特徵。例如,我們發現具有稀疏開放區域的環境通常會導致相同的掃描和次優的識別效能。我們在這個數據集上展示了在這些高不確定性的情況下我們的系統和各種基線發生了什麼。

原文連結:https://mp.weixin.qq.com/s/wu7whicFEAuo65kYp4quow
以上がFMCW レーダー位置認識をエレガントに実装する方法 (IROS2023)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。