
ホームページ >テクノロジー周辺機器 >AI >あなたの GPU は Llama 2 などの大規模なモデルを実行できますか?このオープンソース プロジェクトで試してみる
あなたの GPU は Llama 2 などの大規模なモデルを実行できますか?このオープンソース プロジェクトで試してみる

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-10-23 14:29:011494ブラウズ
コンピューティング能力が重要な時代において、GPU は大規模モデル (LLM) をスムーズに実行できますか?
多くの人は、この質問に正確に答えるのが難しく、GPU メモリの計算方法がわかりません。 GPU がどの LLM を処理できるかを確認するのはモデル サイズを見るほど簡単ではないため、モデルは推論中に大量のメモリ (KV キャッシュ) を占有する可能性があります。たとえば、llama-2-7b のシーケンス長は 1000 で、1GB のメモリが必要です。追加のメモリ。それだけでなく、モデルのトレーニング中、KV キャッシュ、アクティブ化、量子化により多くのメモリが占有されます。
上記のメモリ使用量を事前に知ることができるかどうか疑問に思わずにはいられません。最近、LLM のトレーニングまたは推論中に必要な GPU メモリの量を計算するのに役立つ新しいプロジェクトが GitHub に登場しました。それだけでなく、このプロジェクトの助けを借りて、詳細なメモリの配分と評価も知ることができます。量子化方法、処理されるコンテキストの最大長など、ユーザーが自分に合った GPU 構成を選択できるようにするための方法。
プロジェクトアドレス: https://github.com/RahulSChand/gpu_poor
それだけではありません, 以下に示すように、このプロジェクトは依然としてインタラクティブです。LLM の実行に必要な GPU メモリを計算できます。空白を埋めるだけで簡単です。ユーザーは必要なパラメータをいくつか入力し、最後に青いボタンをクリックするだけです。答えはアウトになります。
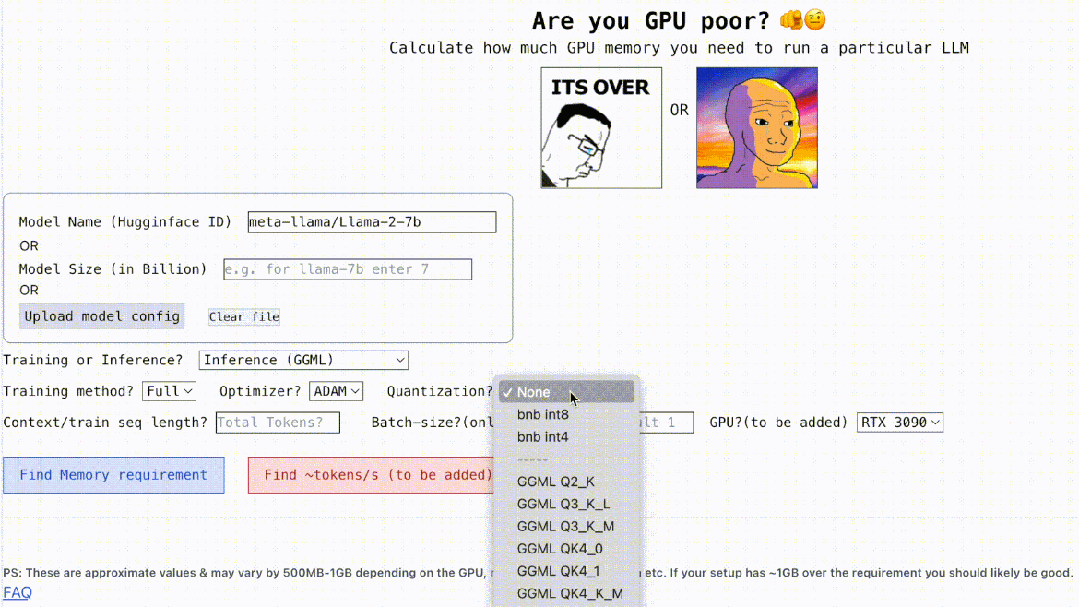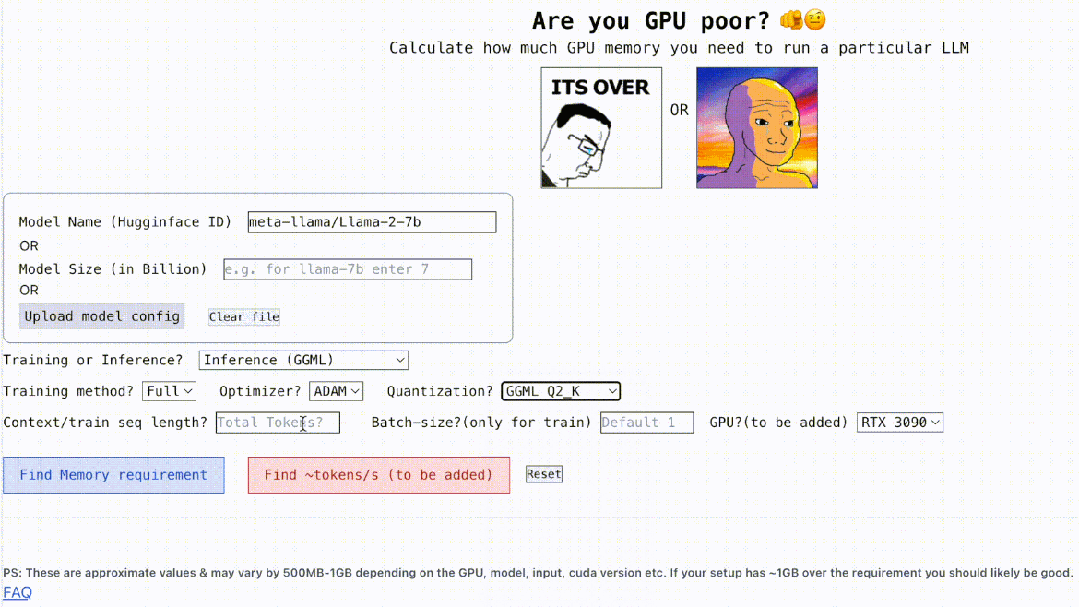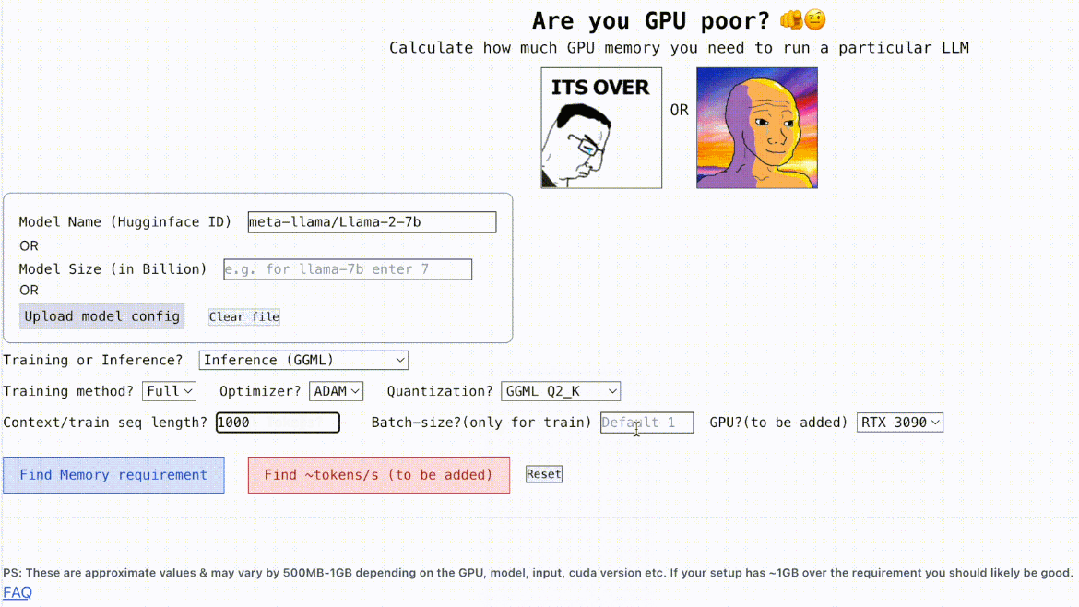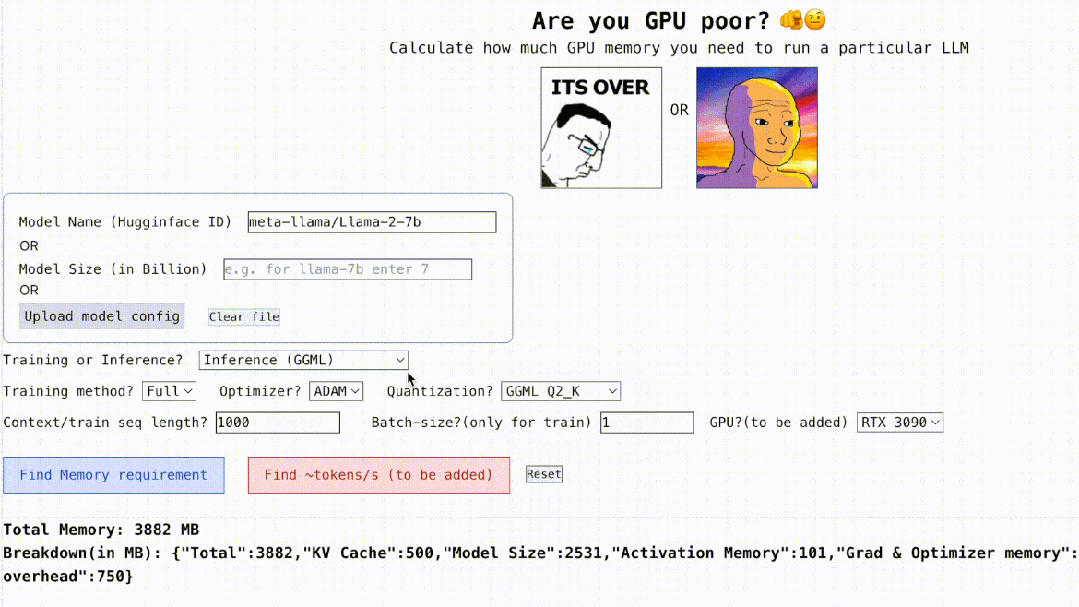
インタラクション アドレス: https://rahulschand.github.io/gpu_poor/
最終出力形式は次のとおりです:
{"Total": 4000,"KV Cache": 1000,"Model Size": 2000,"Activation Memory": 500,"Grad & Optimizer memory": 0,"cuda + other overhead":500}
このプロジェクトが行われた理由について、作者の Rahul Shiv Chand 氏は次のような理由があると述べています:
- GPU で LLM を実行する場合、モデルに適応させるためにどのような量子化方法を使用する必要がありますか;
- GPU が処理できるコンテキストの最大長はどれくらいですか;
- どのような微調整方法があなたにとってより適していますか?フル? LoRA? または QLoRA?
- 微調整中に使用できる最大バッチは何ですか;
- どのタスクがGPU?メモリ、LLM が GPU に適応できるように調整する方法。
それでは、どうやって使うのでしょうか?
最初はモデル名、ID、モデルサイズの処理です。 Huggingface にモデル ID を入力できます (例: metal-llama/Llama-2-7b)。現在、プロジェクトは、Huggingface で最もダウンロードされた上位 3000 個の LLM のモデル構成をハードコーディングして保存しています。
カスタム モデルを使用する場合、または Hugginface ID が利用できない場合は、json 構成をアップロードするか (プロジェクトの例を参照)、モデル サイズのみを入力する必要があります (例:ラマ-2-7b は 700 億) で十分です。
次に量子化です。現在、プロジェクトはビットサンドバイト (bnb) int8/int4 および GGML (QK_8、QK_6、QK_5、QK_4、QK_2) をサポートしています。後者は推論にのみ使用されますが、bnb int8/int4 はトレーニングと推論の両方に使用できます。
最後のステップは推論とトレーニングです。推論プロセス中に、HuggingFace 実装を使用するか、vLLM または GGML メソッドを使用して、推論に使用される vRAM を見つけます。トレーニング プロセス中に、vRAM を見つけます。または、LoRA (現在のプロジェクトでは LoRA 用にハードコードされた r=8 が構成されています) または QLoRA を使用して微調整します。
ただし、プロジェクトの作成者は、最終結果はユーザー モデル、入力データ、CUDA バージョン、定量化ツールによって異なる可能性があると述べています。実験では、これらの要素を考慮して、最終結果が 500MB 以内になるように努めました。以下の表は、著者が Web サイトで提供されている 3b、7b、および 13b モデルのメモリ使用量を、RTX 4090 および 2060 GPU で取得したメモリ使用量と比較してクロスチェックしたものです。すべての値は 500MB 以内です。
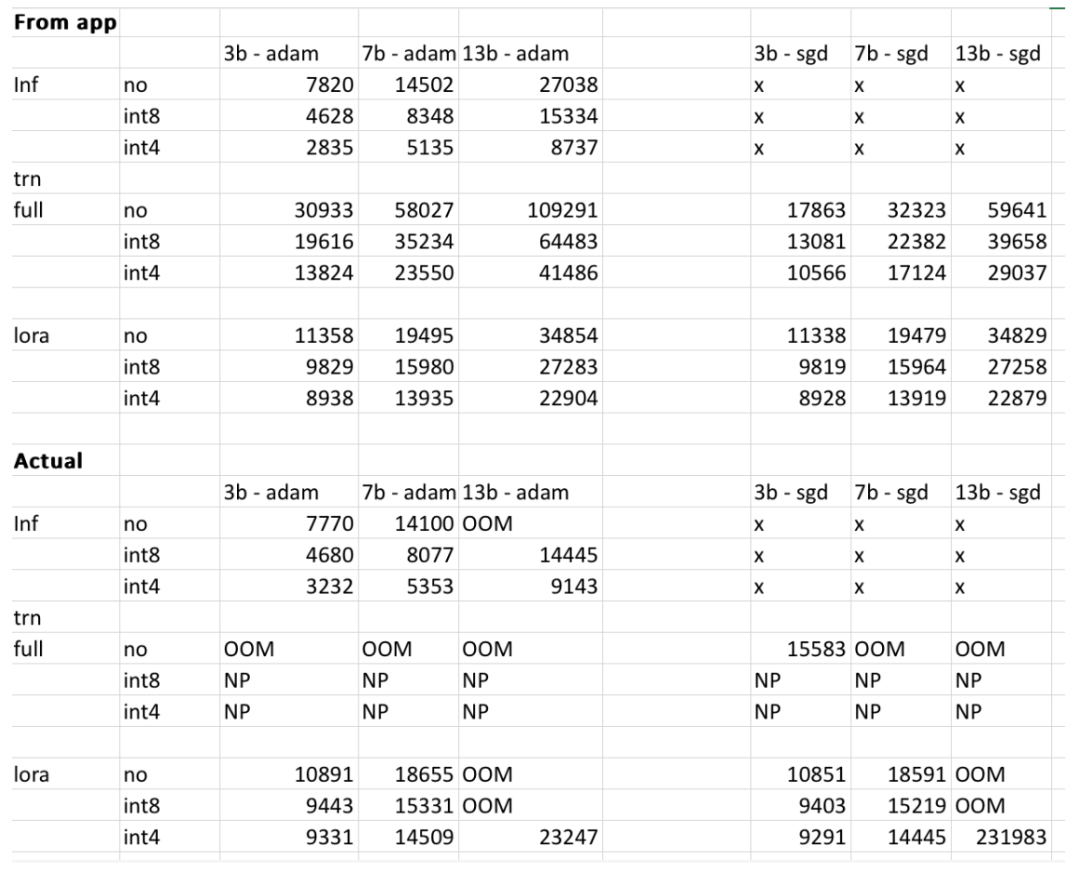
#興味のある読者は、自分でそれを体験できます。与えられた結果が不正確な場合、プロジェクトの作成者は、プロジェクトは最適化され、改善されると述べています。タイムリーなプロジェクトです。
以上があなたの GPU は Llama 2 などの大規模なモデルを実行できますか?このオープンソース プロジェクトで試してみるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。