



GPT-4V はターゲット検出用ですか?ネチズンによる実際のテスト: まだ準備ができていません。

#検出されたカテゴリには問題はありませんが、ほとんどの境界ボックスが間違って配置されています。
大丈夫、誰かが行動してくれるでしょう!
画像表示能力で GPT-4 を数か月上回った Mini GPT-4 がアップグレードされました ——MiniGPT-v2。

△ (GPT-4V は左側に生成され、MiniGPT-v2 は右側に生成されます)
これは単純なコマンドです: [グラウンディング] の詳細はこの画像で説明します が達成された結果です。
それだけでなく、さまざまな視覚的なタスクも簡単に処理できます。
オブジェクトを丸で囲み、プロンプト単語の前に [identify] を追加して、モデルがオブジェクトの名前を直接識別できるようにします。

もちろん、何も追加せずに尋ねることもできます~

MiniGPT-v2 は MiniGPT によって作成されます- 4 オリジナルチーム (KAUST キング・アブドラ科学技術大学) と Meta の 5 人の研究者によって開発されました。

前回の MiniGPT-4 は、登場時に大きな注目を集め、一時はサーバーがパンクする事態となりましたが、現在、GitHub プロジェクトのスター数は 22,000 を超えています。

このアップグレードにより、一部のネチズンはすでにそれを使い始めています~

複数のビジュアルタスクのための共通インターフェース
さまざまなテキスト アプリケーションの共通インターフェイスとして、大規模なモデルはすでに一般的になっています。これに触発されて、研究チームは、画像の説明や視覚的な質問応答など、さまざまな視覚的タスクに使用できる統一インターフェイスを構築したいと考えています。

「単一モデルの条件下で、シンプルなマルチモーダル命令を使用してさまざまなタスクを効率的に完了するにはどうすればよいか?」は、チームが解決する必要がある難しい問題となっています。
簡単に言うと、MiniGPT-v2 は、ビジュアル バックボーン、線形層、大規模言語モデルの 3 つの部分で構成されています。

モデルは ViT ビジュアル バックボーンに基づいており、すべてのトレーニング段階で変更されません。 4 つの隣接するビジュアル出力トークンが ViT から誘導され、線形層を介して LLaMA-2 言語モデル空間に投影されます。
チームは、大規模なモデルで各タスクの指示を簡単に区別し、各タスクの学習効率を向上させることができるように、トレーニング モデル内のさまざまなタスクに一意の識別子を使用することを推奨しています。
トレーニングは主に、事前トレーニング - マルチタスクトレーニング - マルチモード指導調整の 3 つの段階に分かれています。

最終的に、MiniGPT-v2 は、多くの視覚的な質問応答や視覚的なグラウンディングのベンチマークにおいて、他の視覚言語の一般的なモデルよりも優れたパフォーマンスを示しました。

最終的に、このモデルは、ターゲット オブジェクトの説明、視覚的な位置特定、画像の説明、視覚的な質問応答、指定された入力からの直接画像解析など、さまざまな視覚的なタスクを完了できます。テキスト、オブジェクト。

興味のあるお友達は、下のデモ リンクをクリックして体験してください:
https://minigpt-v2.github.io/
https://huggingface.co/spaces/Vision-CAIR/MiniGPT-v2
紙のリンク: https://arxiv.org/abs/ 2310.09478
GitHub リンク: https://github.com/Vision-CAIR/MiniGPT-4
以上が中国チームが制作した超人気のミニ GPT-4 のビジュアル機能は飛躍的に向上し、GitHub で 20,000 個のスターを獲得の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

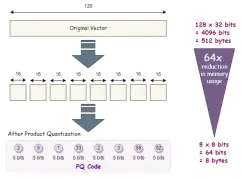 高次元データの高度なベクトルインデックス手法Apr 11, 2025 am 10:16 AM
高次元データの高度なベクトルインデックス手法Apr 11, 2025 am 10:16 AM高次元ベクトル検索:高度なインデックス作成手法のマスタリング 今日のデータ駆動型の世界では、推奨システム、画像認識、自然言語処理(NLP)、異常などのアプリケーションに高次元ベクトルが重要です
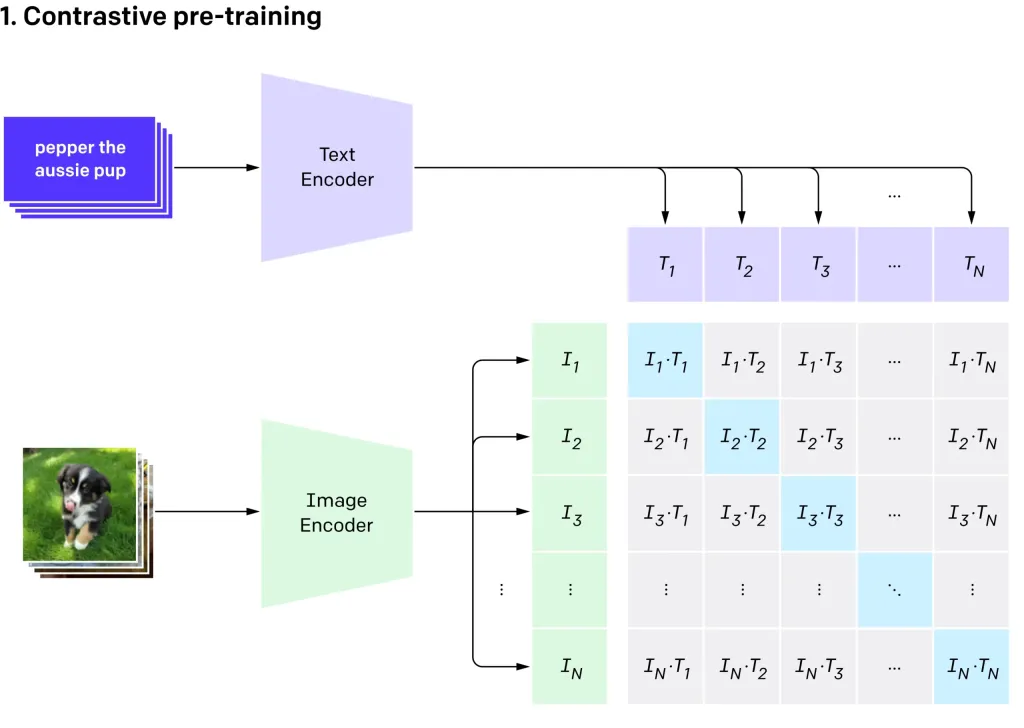 Openai'のクリップVIT-L14を使用したゼロショット画像分類Apr 11, 2025 am 10:04 AM
Openai'のクリップVIT-L14を使用したゼロショット画像分類Apr 11, 2025 am 10:04 AMOpenaiのクリップ(コントラスト言語 - イメージ前訓練)モデル、特にクリップVIT-L14バリアントは、マルチモーダル学習と自然言語処理の大幅な進歩を表しています。 この強力なコンピュータービジョンシステムは、RepreSeに優れています
 コードなしでAIエージェントを構築するための7つのステップ-AnalyticsVidhyaApr 11, 2025 am 10:03 AM
コードなしでAIエージェントを構築するための7つのステップ-AnalyticsVidhyaApr 11, 2025 am 10:03 AMWordwareを使用してAIエージェントのパワーを活用してください:楽なAIエージェント作成のためのノーコードプラットフォーム。 AIエージェントは、コンピューターとの対話方法、タスクの自動化、意思決定の合理化に革命をもたらしています。 このブログは、構築方法を示しています
 モバイルのLLMS:現在および将来の可能性 - 分析vidhyaApr 11, 2025 am 09:58 AM
モバイルのLLMS:現在および将来の可能性 - 分析vidhyaApr 11, 2025 am 09:58 AM生成AI:次のスマートフォンの戦場 スマートフォン業界は、高度な生成AIを統合するための競争である激しい競争に閉じ込められています。 ユーザーの相互作用の向上から生産性の向上まで、利害関係は高いです。 AppleのiPhone16
 2025年に続くトップ10の生成AIサブレッドディット - 分析vidhyaApr 11, 2025 am 09:51 AM
2025年に続くトップ10の生成AIサブレッドディット - 分析vidhyaApr 11, 2025 am 09:51 AM生成AI:10の必須redditコミュニティへのガイド 生成AIは急速に進化しており、新しいモデルが絶えず出現しています。 更新のままであることが重要であり、Redditはこの分野に特化した活気のあるコミュニティを提供しています。この記事はtを強調しています
 AIモデルの重要な課題と制限 - 分析VidhyaApr 11, 2025 am 09:44 AM
AIモデルの重要な課題と制限 - 分析VidhyaApr 11, 2025 am 09:44 AM導入 人工知能(AI)は、AIの研究開発への実質的な投資によって促進されたさまざまな職場に急速に統合されています。 AIのアプリケーションは、仮想アシスタントのような単純なタスクからcomまで、幅広い範囲に広がっています
 SQLでnull値を処理しますApr 11, 2025 am 09:37 AM
SQLでnull値を処理しますApr 11, 2025 am 09:37 AM導入 データベースの領域では、ヌル値はしばしば独自の課題を提示します。 欠落している、未定義、または未知のデータを表して、データ管理と分析を複雑にする可能性があります。顧客のフィードバックが欠落している販売データベースまたはORDEを検討してください
 Google GeminiをTableau Dashboardsに統合する方法は?Apr 11, 2025 am 09:27 AM
Google GeminiをTableau Dashboardsに統合する方法は?Apr 11, 2025 am 09:27 AMTableauでGoogle Geminiのパワーを利用するダッシュボード:AI駆動の強化 Tableauの堅牢な視覚化機能、データ準備(Tableau Prep Builder)、データストーリーテリング(Tableau Desktop)、およびCollaborative共有(Table


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

WebStorm Mac版
便利なJavaScript開発ツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

