
ホームページ >テクノロジー周辺機器 >AI >GPT-3.5 または Jordan Llama 2、その他のオープンソース モデルを選択しますか?総合的に比較した結果、答えは次のようになります。
GPT-3.5 または Jordan Llama 2、その他のオープンソース モデルを選択しますか?総合的に比較した結果、答えは次のようになります。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-10-16 18:45:05620ブラウズ
さまざまなタスクで GPT-3.5 と Llama 2 のパラメーターを比較することで、どのような状況で GPT-3.5 が選択され、どのような状況で Llama 2 または他のモデルが選択されるかを知ることができます。
GPT-3.5 のトルク設定は非常に高価なようです。この論文では、手動トルク モデルが GPT-3.5 の数分の 1 のコストで GPT-3.5 のパフォーマンスに近づくことができるかどうかを実験的に検証します。興味深いことに、新聞はそうしました。
SQL タスクと関数表現タスクの結果を比較したところ、論文では次のことが判明しました:
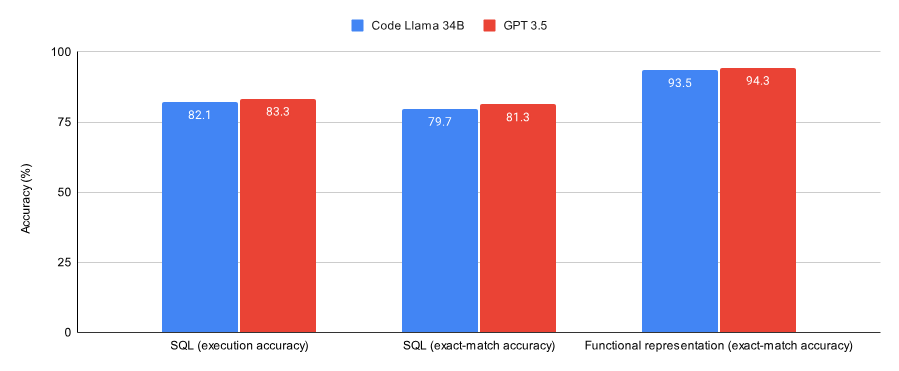
GPT-3.5 は 2 つのデータセット (Spider データのサブセット) で良好なパフォーマンスを示しました。セットおよび Viggo 関数表現データ セット)は、Lora を介した Code Llama 34B よりもわずかに優れています。
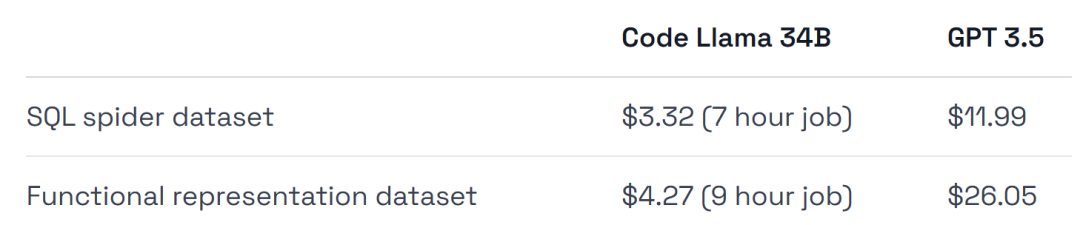
GPT-3.5 のトレーニング コストは 4 ~ 6 倍であり、導入コストも高くなります。
この実験の結論の 1 つは、初期の検証作業には GPT-3.5 が適しているが、その後は Llama 2 のようなモデルが最適な選択となる可能性があるということです。
検証を特定のタスク/データセットを解決するための正しい方法にしたい場合、または完全に管理された環境が必要な場合は、GPT-3.5 を調整します。
コストを節約し、データセットから最大のパフォーマンスを引き出し、インフラストラクチャのトレーニングとデプロイをより柔軟に行い、一部のデータが必要または保持したい場合は、オープンソースモデルを使用してください。ラマ2みたいに。
次に、この論文がどのように実装されるかを見てみましょう。
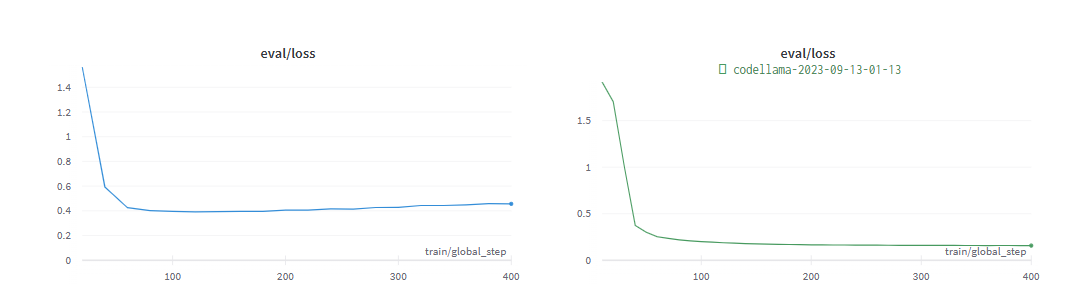
次の図は、SQL タスクと関数表現タスクで収束するようにトレーニングされた Code Llama 34B と GPT-3.5 のパフォーマンスを示しています。結果は、GPT-3.5 が両方のタスクでより高い精度を達成していることを示しています。
ハードウェア使用量に関しては、実験では A40 GPU を使用しました。これは約 0.475 米ドルです。
#さらに、この実験では、ひどい実験に非常に適した 2 つのデータ セットが列挙されています。Spider データ セットは、データ セットを表す Viggo 関数のサブセットです。
GPT-3.5 モデルと公平に比較するために、最小限のハイパーパラメーターを使用して Llama で実験が実行されました。
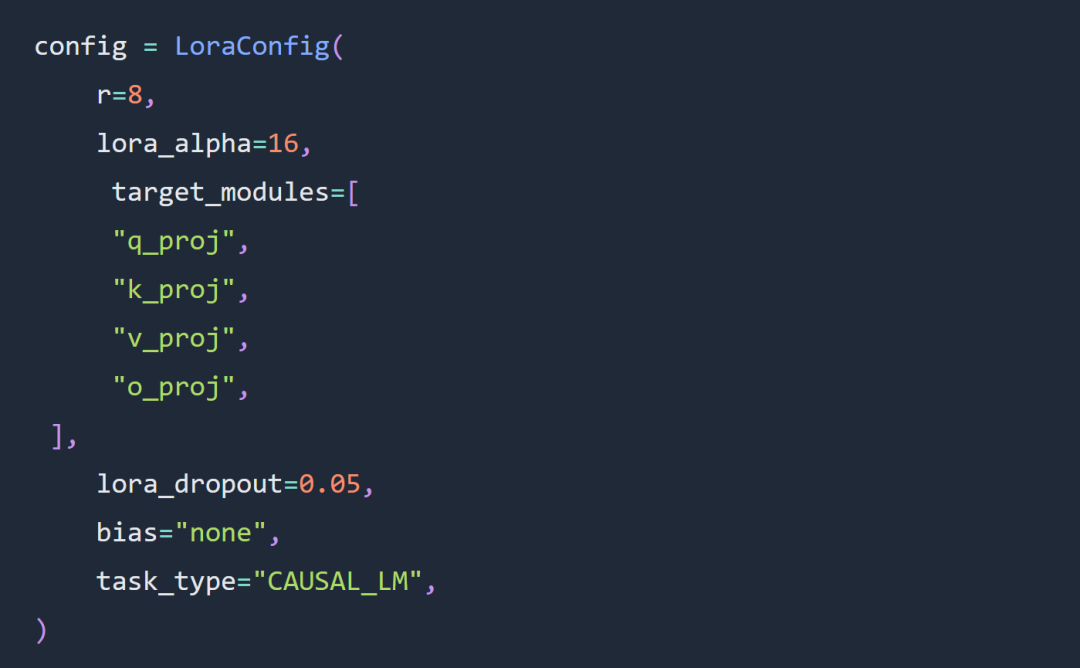
この記事の実験における 2 つの重要な選択肢は、フルパラメータ パラメータの代わりにコード Llama 34B および Lora パラメータを使用することです。
Lora ハイパーパラメータ設定のルールは、実験においてかなりの部分まで従われました。Lora の負荷は次のとおりです:
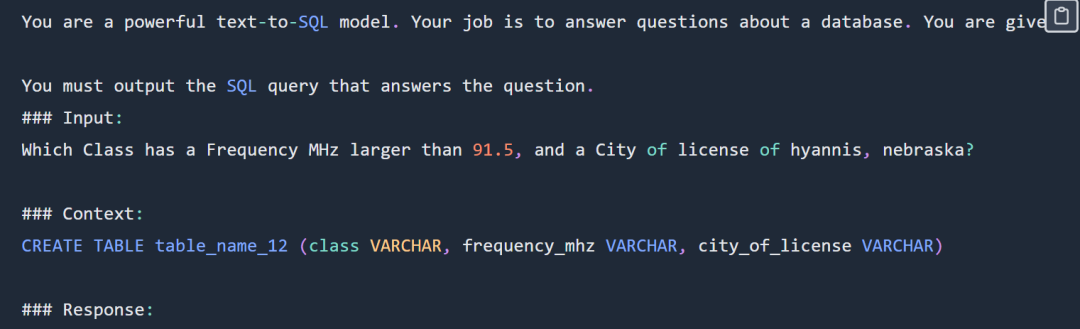
SQL プロンプトの例は次のとおりです。 :
# SQL リマインダー部分の表示については、元のブログを確認してください
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
SQL タスクのコードとデータ アドレス: https://github.com/samlhuillier/spider-sql -finetune
関数表現プロンプトの例は次のとおりです。 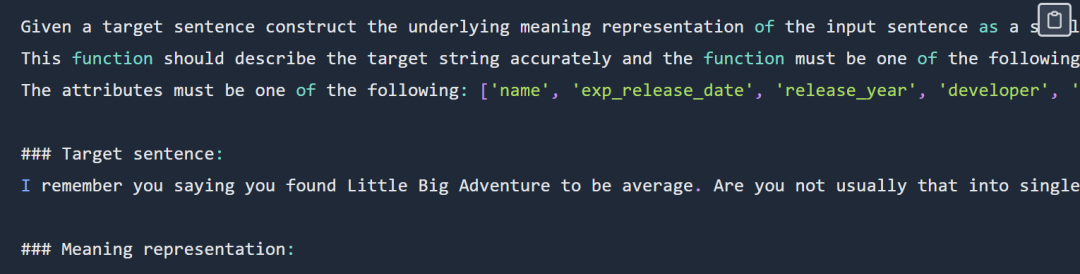
出力は次のとおりです。
verify_attribute(name[Little Big Adventure], rating[average], has_multiplayer[no], platforms[PlayStation])評価フェーズ中に、2 つの実験はすぐに収束しました。
元のリンク:
https://ragntune.com/blog/gpt3.5-vs-llama2 -finetuning?ContinueFlag=11fc7786e20d498fc4daa79c5923e198
###以上がGPT-3.5 または Jordan Llama 2、その他のオープンソース モデルを選択しますか?総合的に比較した結果、答えは次のようになります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。