
ホームページ >テクノロジー周辺機器 >AI >エンジニアリング効率の向上 - 拡張検索生成 (RAG)
エンジニアリング効率の向上 - 拡張検索生成 (RAG)

- 王林転載
- 2023-10-14 20:17:011572ブラウズ
GPT-3 などの大規模言語モデルの出現により、自然言語処理 (NLP) の分野で大きな進歩が見られました。これらの言語モデルには、人間のようなテキストを生成する機能があり、チャットボットや翻訳などのさまざまなシナリオで広く使用されています

ただし、専門化とカスタマイズとなると、アプリケーションシナリオで使用される場合、汎用の大規模言語モデルでは専門的な知識が不十分な場合があります。特殊なコーパスを使用してこれらのモデルを微調整するには、多くの場合、費用と時間がかかります。 「Retrieval Enhanced Generation」(RAG)は、プロフェッショナル アプリケーション向けの新しいテクノロジー ソリューションを提供します。
以下では、主に RAG がどのように機能するかを紹介し、製品マニュアルを専門的なコーパスとして使用し、GPT-3.5 Turbo を質疑応答モデルとして使用する実践例を使用して、その効果を検証します。
ケース: 特定の製品に関する質問に回答できるチャットボットを開発します。企業には独自のユーザー マニュアルがあります。
RAG の概要
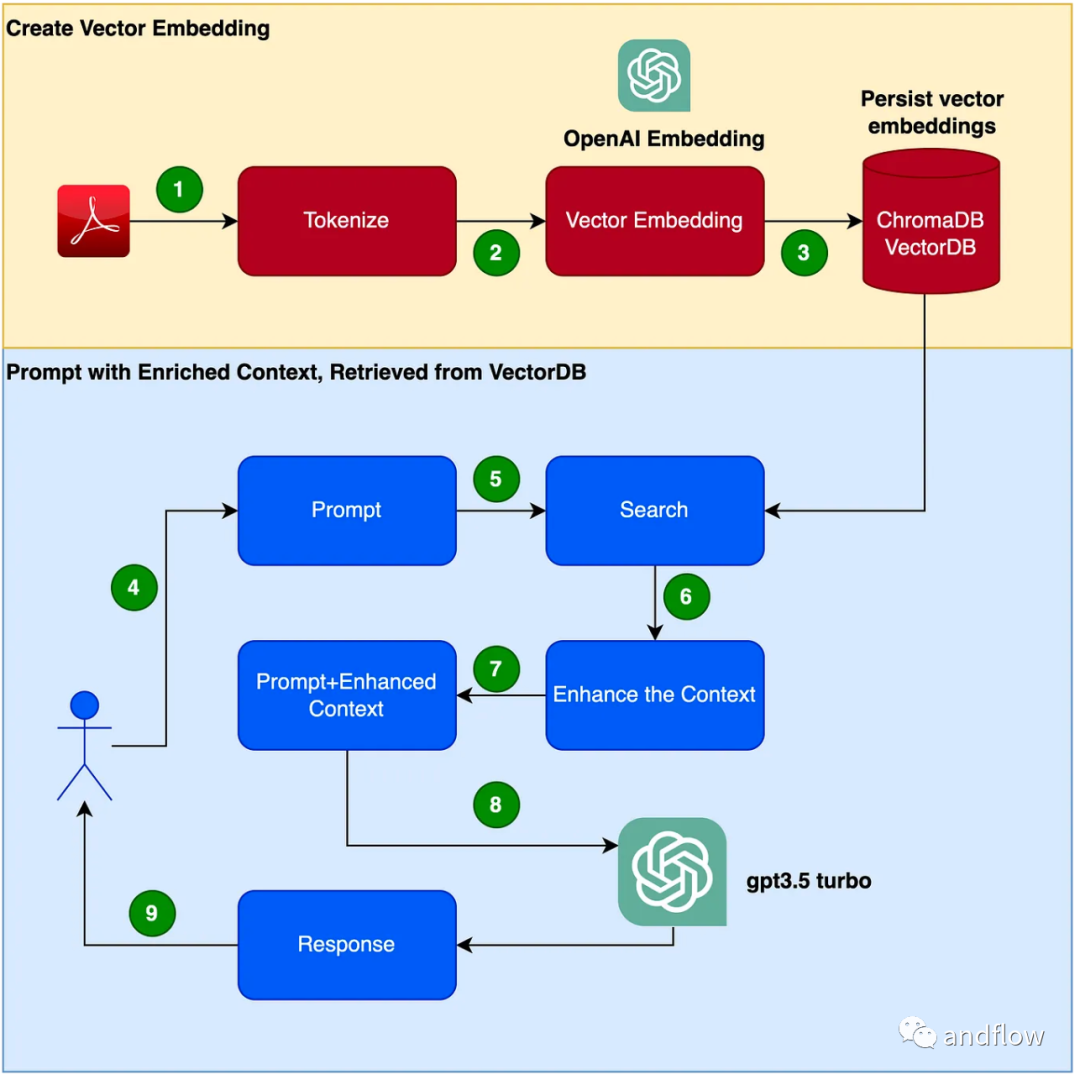
RAG は、ドメイン固有の質問と回答に対する効果的なソリューションを提供します。主に業界の知識を保存および検索用のベクトルに変換し、検索結果とユーザーの質問を組み合わせて迅速な情報を形成し、最後に大規模なモデルを使用して適切な回答を生成します。検索メカニズムと言語モデルを組み合わせることで、モデルの応答性が大幅に向上します。
チャットボット プログラムを作成する手順は次のとおりです。
- PDF を読む (ユーザー マニュアル PDF)ファイル) を使用し、chunk_size を使用して 1000 個のトークンをトークン化します。
- ベクターを作成します (OpenAI EmbeddingsAPI を使用してベクターを作成できます)。
- ベクトルをローカル ベクトル ライブラリに保存します。ベクトルデータベースとしてChromaDBを使用します(ベクトルデータベースはPineconeなどの製品でも置き換え可能です)。
- ユーザーの問題には、クエリ/質問のプロンプトが表示されます。
- ユーザーの質問に基づいて、ベクトル データベースから知識コンテキスト データを取得します。この知識コンテキスト データは、後続のステップでキュー ワードと組み合わせて使用され、キュー ワードを強化します。これは、多くの場合、コンテキスト エンリッチメントと呼ばれます。
- ユーザーの質問を含むプロンプト単語は、拡張されたコンテキスト知識とともに LLM に渡されます。
- LLM は、このコンテキストに基づいて回答します。
ハンズオン開発
(1) Python 仮想環境をセットアップする バージョンや依存関係の競合を避けるために、Python をサンドボックス化する仮想環境をセットアップします。次のコマンドを実行して、新しい Python 仮想環境を作成します。
需要重写的内容是:pip安装virtualenv,python3 -m venv ./venv,source venv/bin/activate
書き換える必要がある内容は次のとおりです: (2) OpenAI キーの生成
GPT を使用するにはアクセスに OpenAI キーが必要です
- lanchain: LLM アプリケーションを開発するためのフレームワーク。
- chromaDB: これは永続的なベクトル埋め込み用の VectorDB です。
- 非構造化: Word/PDF ドキュメントの前処理に使用されます。
- tiktoken: トークナイザー フレームワーク
- pypdf: PDF ドキュメントを読み取り、処理するためのフレームワーク。
- openai: OpenAI フレームワークにアクセスします。
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openaiOpenAI キーを保存する環境変数を作成します。
export OPENAI_API_KEY=<openai-key></openai-key>(4) ユーザー マニュアル PDF ファイルをベクターに変換し、ChromaDB に保存します。使用する必要があるすべての依存ライブラリと関数をインポートします
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChainPDF を読み取り、ドキュメントをトークン化し、ドキュメントを分割します。
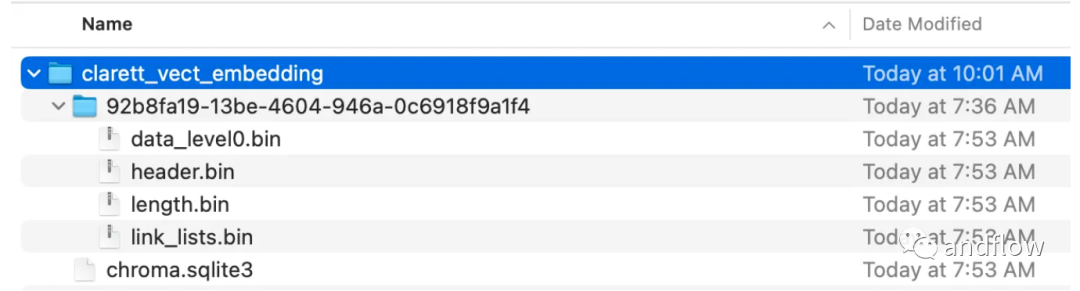
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)クロマ コレクションとクロマ データを保存するローカル ディレクトリを作成します。次に、ベクター (エンベディング) を作成し、ChromaDB に保存します。
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData,embeddings,collection_name=collection_name,persist_directory=persist_directory)vectDB.persist()このコードを実行すると、ベクターを保存するために作成されたフォルダーが表示されるはずです。
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm(OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)langchan を初期化した後、チャット/QAに使用できます。以下のコードでは、ユーザーが入力した質問が受け入れられ、ユーザーが「done」と入力した後、質問が LLM に渡されて応答を取得し、出力されます。
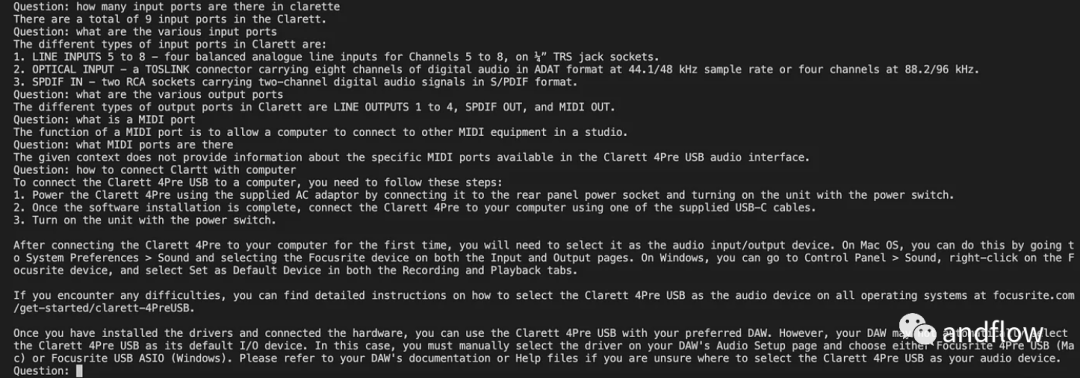
chat_history = []qry = ""while qry != 'done':qry = input('Question: ')if qry != exit:response = chatQA({"question": qry, "chat_history": chat_history})print(response["answer"])

つまり、
RAG は、GPT などの言語モデルの利点と情報検索の利点を組み合わせています。特定の知識コンテキスト情報を利用してプロンプトワードの豊富さを強化することにより、言語モデルはより正確な知識コンテキストに関連した回答を生成できます。 RAG は、「微調整」よりも効率的でコスト効率の高いソリューションを提供し、業界アプリケーションまたはエンタープライズ アプリケーション向けにカスタマイズ可能な対話型ソリューションを提供します。
以上がエンジニアリング効率の向上 - 拡張検索生成 (RAG)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。