
ホームページ >テクノロジー周辺機器 >AI >より多用途かつ効果的な、Ant の自社開発オプティマイザー WSAM が KDD Oral に採用されました
より多用途かつ効果的な、Ant の自社開発オプティマイザー WSAM が KDD Oral に採用されました

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-10-10 12:13:09828ブラウズ
ディープ ニューラル ネットワーク (DNN) の汎化能力は、極値点の平坦性に密接に関係しているため、より平坦な極点を見つけて汎化能力を向上させるために、Sharpness-Aware Minimization (SAM) アルゴリズムが登場しました。 。この論文では、SAM の損失関数を再検討し、平坦性を正則化項として使用することでトレーニング極点の平坦性を改善する、より一般的で効果的な方法 WSAM を提案します。さまざまな公開データセットでの実験では、元のオプティマイザーである SAM およびそのバリアントと比較して、WSAM がほとんどの場合で優れた汎化パフォーマンスを達成することが示されています。 WSAM は、Ant の社内デジタル決済、デジタル金融、その他のシナリオでも広く採用されており、目覚ましい成果を上げています。この論文はKDD '23に口頭論文として受理されました。

- 論文アドレス: https: / /arxiv.org/pdf/2305.15817.pdf
- コードアドレス: https://github.com/intelligent-machine-learning/dlrover/tree/master /atorch/atorch/optimizers
#深層学習テクノロジーの発展に伴い、CV や NLP などのさまざまな機械学習シナリオで高度に過剰パラメータ化された DNN が使用されています。 . 大成功でした。過剰にパラメータ化されたモデルはトレーニング データを過剰適合する傾向がありますが、通常は優れた汎化機能を備えています。一般化の秘密はますます注目を集めており、深層学習の分野で人気の研究トピックとなっています。
最新の研究では、一般化能力が極点の平坦度と密接に関係していることが示されています。言い換えれば、損失関数の「ランドスケープ」に平坦な極点が存在することで、汎化誤差が小さくなる可能性があります。 Sharpness-Aware Minimization (SAM) [1] は、平坦な極点を見つけるための手法であり、現在最も有望な技術方向の 1 つであると考えられています。 SAM テクノロジーは、コンピューター ビジョン、自然言語処理、2 層学習などの多くの分野で広く使用されており、これらの分野における以前の最先端の手法を大幅に上回っています
より平坦な の最小値を探索するために、SAM は w における損失関数 L の平坦性を次のように定義します。
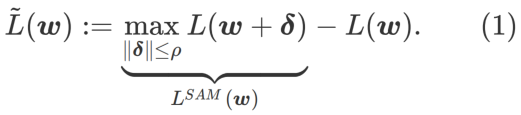
GSAM [2] は、 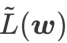 が局所極点におけるヘッセ行列の最大固有値の近似値であることを証明し、 が実際に平坦度 (急峻さ) の有効な尺度であることを示しています。ただし、
が局所極点におけるヘッセ行列の最大固有値の近似値であることを証明し、 が実際に平坦度 (急峻さ) の有効な尺度であることを示しています。ただし、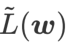 は最小点ではなく平坦な領域を見つけるためにのみ使用できるため、損失関数が (周囲の領域は平坦であるにもかかわらず) 損失値がまだ大きい点に収束する可能性があります。したがって、SAM は
は最小点ではなく平坦な領域を見つけるためにのみ使用できるため、損失関数が (周囲の領域は平坦であるにもかかわらず) 損失値がまだ大きい点に収束する可能性があります。したがって、SAM は 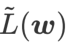
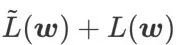 、つまり
、つまり 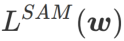 を損失関数として使用します。これは、より平坦な表面を見つけることと、 と
を損失関数として使用します。これは、より平坦な表面を見つけることと、 と 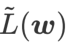
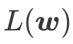 の間でより小さい損失値を見つけることとの間の妥協点と見なすことができ、両方に同じ重みが与えられます。
の間でより小さい損失値を見つけることとの間の妥協点と見なすことができ、両方に同じ重みが与えられます。
この記事では、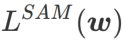 の構造を再考し、
の構造を再考し、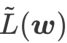 を正則化用語とみなします。私たちは、WSAM (Weighted Sharpness-Aware Minimization) と呼ばれる、より一般的で効果的なアルゴリズムを開発しました。このアルゴリズムの損失関数は、重み付き平坦性項
を正則化用語とみなします。私たちは、WSAM (Weighted Sharpness-Aware Minimization) と呼ばれる、より一般的で効果的なアルゴリズムを開発しました。このアルゴリズムの損失関数は、重み付き平坦性項 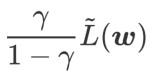 を通常の項として追加し、ハイパーパラメータ
を通常の項として追加し、ハイパーパラメータ 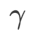 平面度の重みを制御します。手法の紹介の章では、
平面度の重みを制御します。手法の紹介の章では、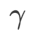 を使用して損失関数をガイドし、より平坦な、またはより小さい極値点を見つける方法を説明しました。私たちの主な貢献は次のように要約できます。
を使用して損失関数をガイドし、より平坦な、またはより小さい極値点を見つける方法を説明しました。私たちの主な貢献は次のように要約できます。
- 我々は、平坦性を正則化項として扱い、異なるタスク間で異なる重みを与える WSAM を提案します。現在のステップの平坦性を正確に反映することを目的として、更新式の正則化項を処理する「重みデカップリング」手法を提案します。基礎となるオプティマイザーが SGD ではない場合 (SGDM や Adam など)、WSAM の形式は SAM とは大きく異なります。アブレーション実験では、この技術によりほとんどの場合のパフォーマンスが向上することが示されています。
- 公開データセットの一般的なタスクにおける WSAM の有効性を検証しました。実験結果は、SAM およびそのバリアントと比較して、ほとんどの状況で WSAM の汎化パフォーマンスが優れていることを示しています。
予備知識
SAMとは、式(1)で定義される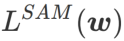 のミニマックス最適化問題を解く技術です。
のミニマックス最適化問題を解く技術です。
まず、SAM は、w の周りの一次テイラー展開を使用して、内層の最大化問題、つまり 、
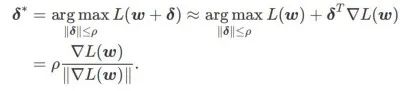 を近似します。
を近似します。
##2 番目に、SAM は の近似勾配を採用することで w を更新します。つまり、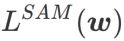
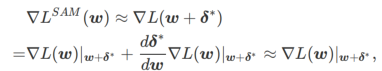
2 番目の近似は次のとおりです。加速度を計算します。他の勾配ベースのオプティマイザー (ベース オプティマイザーと呼ばれる) は、SAM の一般的なフレームワークに組み込むことができます。詳細については、アルゴリズム 1 を参照してください。アルゴリズム 1 の 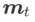 と
と 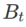 を変更すると、SGD、SGDM、Adam などのさまざまな基本オプティマイザーを取得できます (表 1 を参照)。基本オプティマイザーが SGD の場合、アルゴリズム 1 は SAM 論文 [1] の元の SAM にフォールバックすることに注意してください。
を変更すると、SGD、SGDM、Adam などのさまざまな基本オプティマイザーを取得できます (表 1 を参照)。基本オプティマイザーが SGD の場合、アルゴリズム 1 は SAM 論文 [1] の元の SAM にフォールバックすることに注意してください。


##WSAM の設計詳細
ここでは、規則的な損失と平坦性の項で構成される
の正式な定義を示します。式 (1) から、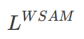
=0 の場合、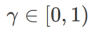 は通常の損失に退化します。
は通常の損失に退化します。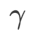 =1/2 の場合、
=1/2 の場合、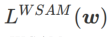 は # と等価です。 ## ;
は # と等価です。 ## ; 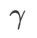 >1/2 の場合、 は平坦度をより重視するため、SAM と比較して損失値が小さいよりも曲率が小さい点を見つけやすくなり、その逆も同様です。 ; 同じく。
>1/2 の場合、 は平坦度をより重視するため、SAM と比較して損失値が小さいよりも曲率が小さい点を見つけやすくなり、その逆も同様です。 ; 同じく。 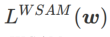
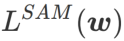
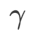 さまざまな基本オプティマイザーを含む WSAM の一般的なフレームワークは、さまざまな
さまざまな基本オプティマイザーを含む WSAM の一般的なフレームワークは、さまざまな 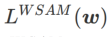 および
および
を選択することで実装できます。「アルゴリズム」を参照してください。 2.たとえば、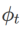 と
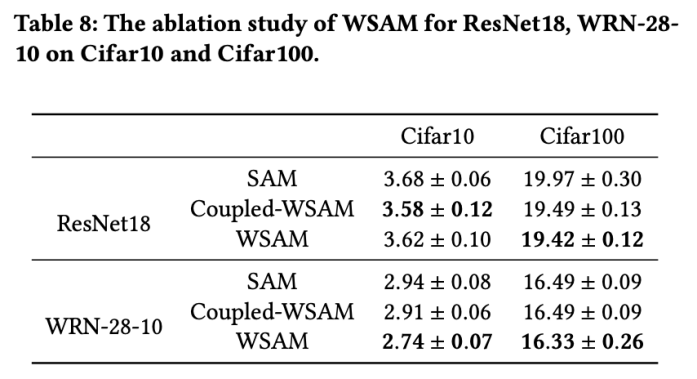
と 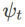 の場合、基本オプティマイザーが SGD である WSAM が得られます。アルゴリズム 3 を参照してください。ここでは、「重みデカップリング」手法を採用します。つまり、 平坦性項は、勾配の計算と重みの更新のために基本オプティマイザーと統合されず、独立して計算されます (アルゴリズム 2 の 7 行目の最後の項)。このように、正則化の効果は、追加情報なしで現在のステップの平坦性のみを反映します。比較のために、アルゴリズム 4 では、「重みデカップリング」を行わない WSAM (Coupled-WSAM と呼ばれる) が得られます。たとえば、基礎となるオプティマイザが SGDM である場合、結合 WSAM の正則化項は平坦性の指数移動平均です。実験セクションで示したように、「重みデカップリング」により、ほとんどの場合、汎化パフォーマンスが向上します。
の場合、基本オプティマイザーが SGD である WSAM が得られます。アルゴリズム 3 を参照してください。ここでは、「重みデカップリング」手法を採用します。つまり、 平坦性項は、勾配の計算と重みの更新のために基本オプティマイザーと統合されず、独立して計算されます (アルゴリズム 2 の 7 行目の最後の項)。このように、正則化の効果は、追加情報なしで現在のステップの平坦性のみを反映します。比較のために、アルゴリズム 4 では、「重みデカップリング」を行わない WSAM (Coupled-WSAM と呼ばれる) が得られます。たとえば、基礎となるオプティマイザが SGDM である場合、結合 WSAM の正則化項は平坦性の指数移動平均です。実験セクションで示したように、「重みデカップリング」により、ほとんどの場合、汎化パフォーマンスが向上します。 
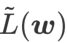

 #
#
図 1 は、さまざまな 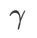 値での WSAM 更新プロセスを示しています。
値での WSAM 更新プロセスを示しています。 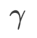 の場合、
の場合、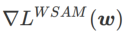 が
が 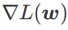 と
と 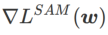 の間にあり、## となります。 # が増加すると、徐々に
の間にあり、## となります。 # が増加すると、徐々に 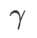
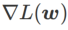 から外れます。
から外れます。

簡単な例
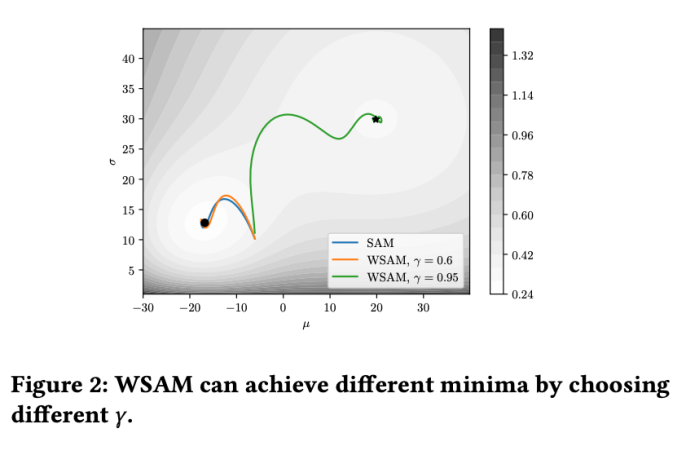
WSAM における γ の効果と利点をよりよく説明するために、次のようにします。 set これは簡単な 2 次元の例です。図 2 に示すように、損失関数には、左下隅に比較的不均一な極点 (位置: (-16.8, 12.8)、損失値: 0.28) があり、右上隅に平坦な極点 (位置: (19.8、29.9)、損失値: 0.36)。損失関数は次のように定義されます: 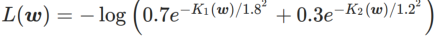 、ここで
、ここで 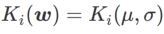 は、単変量ガウス モデルと 2 つの正規分布の間の KL 発散、つまり です。
は、単変量ガウス モデルと 2 つの正規分布の間の KL 発散、つまり です。 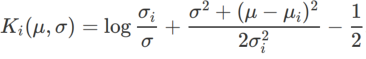 、ここで
、ここで 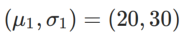 と
と 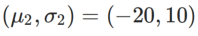 。
。
ベース オプティマイザーとしてモーメンタム 0.9 の SGDM を使用し、SAM と WSAM に 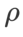 =2 を設定します。損失関数は、初期点 (-6、10) から開始して、学習率 5 を使用して 150 ステップで最適化されます。 SAM は、損失値がより低いもののより不均一になる極点に収束します。
=2 を設定します。損失関数は、初期点 (-6、10) から開始して、学習率 5 を使用して 150 ステップで最適化されます。 SAM は、損失値がより低いもののより不均一になる極点に収束します。 =0.6 の WSAM も同様です。ただし、#=0.95 では、損失関数が平坦な極値点に収束します。これは、より強力な平坦性正則化が役割を果たしていることを示しています。
=0.6 の WSAM も同様です。ただし、#=0.95 では、損失関数が平坦な極値点に収束します。これは、より強力な平坦性正則化が役割を果たしていることを示しています。 
WSAM の有効性を検証するために、さまざまなタスクについて実験を実施しました。
画像分類
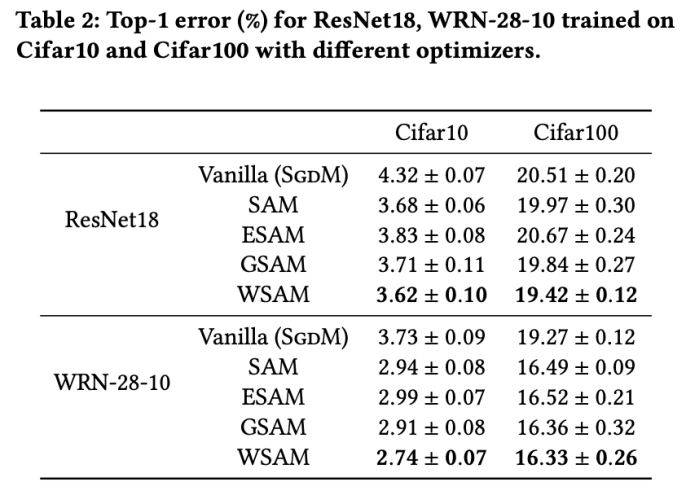
最初に、Cifar10 および Cifar100 データセットでトレーニング モデルに対する WSAM の効果を最初から調査しました。私たちが選択したモデルには、ResNet18 と WideResNet-28-10 が含まれます。 ResNet18 と WideResNet-28-10 に対してそれぞれ 128、256 の事前定義されたバッチ サイズを使用して、Cifar10 と Cifar100 でモデルをトレーニングします。ここで使用される基本オプティマイザーは、モーメンタム 0.9 の SGDM です。 SAM [1] の設定に従って、各基本オプティマイザーは SAM クラス オプティマイザーの 2 倍のエポック数を実行します。両方のモデルを 400 エポック (SAM クラス オプティマイザーの場合は 200 エポック) トレーニングし、コサイン スケジューラーを使用して学習率を下げました。ここでは、カットアウトや自動拡張などの他の高度なデータ拡張方法は使用しません。
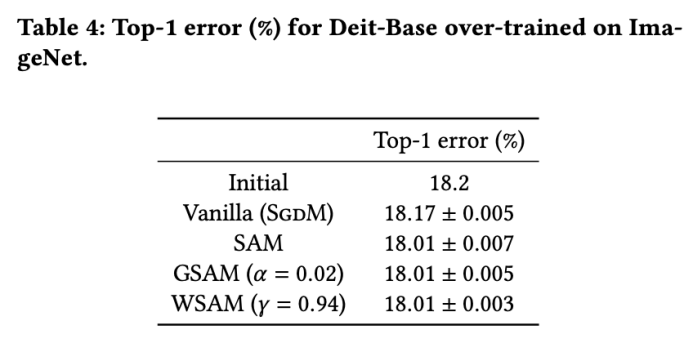
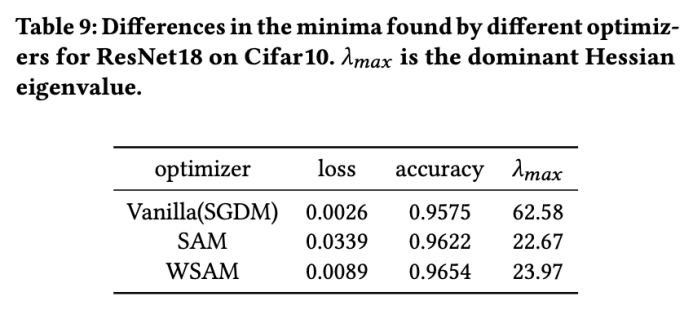
両方のモデルで、ジョイント グリッド検索を使用して基本オプティマイザーの学習率と重み減衰係数を決定し、次の SAM のようなオプティマイザー実験でそれらを一定に保ちます。学習率と重み減衰係数の検索範囲はそれぞれ {0.05, 0.1} と {1e-4, 5e-4, 1e-3} です。すべての SAM クラス オプティマイザーにはハイパーパラメーター 表 2 は、さまざまなオプティマイザーでの Cifar10 および Cifar100 での ResNet18 および WRN-28-10 のトップテスト結果を示しています (エラー率 1)。 SAM クラス オプティマイザーは、基本オプティマイザーと比較してパフォーマンスが大幅に向上すると同時に、WSAM は他の SAM クラス オプティマイザーよりも大幅に優れています。 ImageNet データセットの Transformers ネットワークで Data-Efficient Image をさらに使用します実験用の構造。事前にトレーニングされた DeiT ベースのチェックポイントを再開し、3 エポックの間トレーニングを続けます。モデルはバッチ サイズ 256 を使用してトレーニングされ、基本オプティマイザーは運動量 0.9 の SGDM、重み減衰係数は 1e-4、学習率は 1e-5 です。 4 枚のカード NVIDIA A100 GPU で実行を 5 回繰り返し、平均誤差と標準偏差を計算しました。 {0.05, 0.1, 0.5, 1.0,⋯ , 6.0} 最高の モデルの最初のトップ 1 エラー率は 18.2% で、さらに 3 エポック後のエラー率を表 4 に示します。 3 つの SAM に似たオプティマイザー間に大きな違いは見つかりませんでしたが、いずれも基本オプティマイザーよりも優れたパフォーマンスを示し、より平坦な極点を見つけ、より優れた汎化機能を備えていることを示しています。 以前の研究 [1、4、5] で示されているように、SAM クラス オプティマイザーはトレーニング セットにラベル ノイズが存在する場合でも良好に機能します。優れた堅牢性を実現します。ここでは、WSAM の堅牢性を SAM、ESAM、GSAM と比較します。 Cifar10 データセット上で ResNet18 を 200 エポック間トレーニングし、ノイズ レベル 20%、40%、60%、80% の対称ラベル ノイズを注入します。基本オプティマイザーとして 0.9 の運動量、バッチ サイズ 128、学習率 0.05、重み減衰係数 1e-3、および学習率を減衰するコサイン スケジューラを持つ SGDM を使用します。各ラベル ノイズ レベルについて、範囲 {0.01, 0.02, 0.05, 0.1, 0.2, 0.5} 内の SAM でグリッド検索を実行し、共通の SAM クラス オプティマイザーは ASAM で使用できます [4 ] と SAM [5] などのフィッシャー技術を組み合わせて、探索された近傍の形状を適応的に調整します。 Cifar10 上の WRN-28-10 で実験を実施し、それぞれ適応情報法とフィッシャー情報法を使用した場合の SAM と WSAM のパフォーマンスを比較し、探査領域のジオメトリが SAM のようなオプティマイザーの一般化パフォーマンスにどのような影響を与えるかを理解します。 驚くべきことに、表 7 に示すように、ベースライン WSAM は複数の候補の間でもより優れた一般化を示しています。したがって、固定 このセクションでは、WSAM をより深く理解するためにアブレーション実験を実施します。 「重量デカップリング」テクノロジーの重要性。 WSAM の設計の詳細で説明したように、「重みデカップリング」なしの WSAM バリアント (アルゴリズム 4) 結合 WSAM を元の方式と比較します。 結果を表 8 に示します。ほとんどの場合、結合 WSAM は SAM よりも優れた結果を生成し、WSAM はほとんどの場合に結果をさらに改善し、「重みデカップリング」技術の有効性を示しています。 ここでは、WSAM オプティマイザーと SAM オプティマイザーによって検出された極点の違いを比較することで、WSAM オプティマイザーについての理解をさらに深めます。極点での平坦さ (急峻さ) は、ヘッセ行列の最大固有値によって説明できます。固有値が大きいほど、平坦ではなくなります。この最大固有値を計算するには、Power Iteration アルゴリズムを使用します。 表 9 は、SAM オプティマイザーと WSAM オプティマイザーによって検出された極値間の差異を示しています。バニラ オプティマイザーで見つかった極点は損失値が小さいものの平坦度が低いのに対し、SAM で見つかった極点は損失値が大きいものの平坦度が高く、汎化パフォーマンスが向上していることがわかります。興味深いことに、WSAM によって検出された極値ポイントは、SAM よりも損失値がはるかに小さいだけでなく、SAM に非常に近い平坦性も持っています。これは、極値点を見つけるプロセスにおいて、WSAM がより平坦な領域を検索しようとする一方で、より小さい損失値を確保することを優先していることを示しています。 SAM と比較して、WSAM には追加のハイパーパラメータ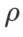 (近傍サイズ) があるため、次に SAM オプティマイザーで最適な
(近傍サイズ) があるため、次に SAM オプティマイザーで最適な 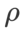 を検索し、他の SAM クラス オプティマイザーにも同じ値を使用します。
を検索し、他の SAM クラス オプティマイザーにも同じ値を使用します。 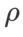 の検索範囲は {0.01, 0.02, 0.05, 0.1, 0.2, 0.5} です。最後に、他の SAM クラス オプティマイザーの固有のハイパーパラメーターを検索しました。検索範囲は、それぞれの元の記事の推奨範囲から得られました。 GSAM [2] の場合、{0.01, 0.02, 0.03, 0.1, 0.2, 0.3} の範囲で検索します。 ESAM [3] の場合、範囲 {0.4, 0.5, 0.6} 内の
の検索範囲は {0.01, 0.02, 0.05, 0.1, 0.2, 0.5} です。最後に、他の SAM クラス オプティマイザーの固有のハイパーパラメーターを検索しました。検索範囲は、それぞれの元の記事の推奨範囲から得られました。 GSAM [2] の場合、{0.01, 0.02, 0.03, 0.1, 0.2, 0.3} の範囲で検索します。 ESAM [3] の場合、範囲 {0.4, 0.5, 0.6} 内の  、範囲 {0.4, 0.5, 0.6} 内の
、範囲 {0.4, 0.5, 0.6} 内の 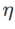 、および{0.4, 0.5, 0.6} の範囲内で
、および{0.4, 0.5, 0.6} の範囲内で 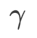 を検索します。 WSAM の場合、{0.5、0.6、0.7、0.8、0.82、0.84、0.86、0.88、0.9、0.92、0.94、0.96} の範囲で
を検索します。 WSAM の場合、{0.5、0.6、0.7、0.8、0.82、0.84、0.86、0.88、0.9、0.92、0.94、0.96} の範囲で 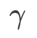 を検索します。異なるランダムシードを使用して実験を 5 回繰り返し、平均誤差と標準偏差を計算しました。シングルカードの NVIDIA A100 GPU で実験を行います。各モデルのオプティマイザのハイパーパラメータを表 3 にまとめます。
を検索します。異なるランダムシードを使用して実験を 5 回繰り返し、平均誤差と標準偏差を計算しました。シングルカードの NVIDIA A100 GPU で実験を行います。各モデルのオプティマイザのハイパーパラメータを表 3 にまとめます。 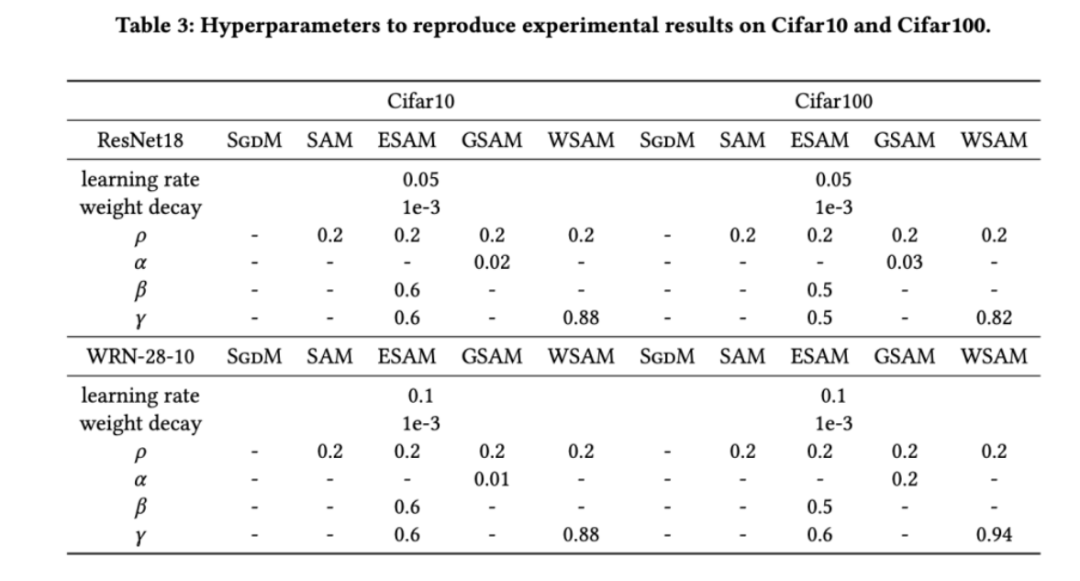
ImageNet に関する追加トレーニング
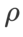 。最適な
。最適な 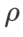 =5.5 は、他の SAM クラス オプティマイザーに直接使用されます。その後、{0.01, 0.02, 0.03, 0.1, 0.2, 0.3} で GSAM の最適な
=5.5 は、他の SAM クラス オプティマイザーに直接使用されます。その後、{0.01, 0.02, 0.03, 0.1, 0.2, 0.3} で GSAM の最適な  を検索し、ステップ サイズ 0.02 ## で 0.80 ~ 0.98 の範囲で WSAM の最適な WSAM を検索します。
を検索し、ステップ サイズ 0.02 ## で 0.80 ~ 0.98 の範囲で WSAM の最適な WSAM を検索します。 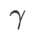 #。
#。 
ラベル ノイズに対する堅牢性
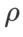 値を決定しました。次に、他のオプティマイザー固有のハイパーパラメーターを個別に検索して、最適な汎化パフォーマンスを見つけます。結果を再現するために必要なハイパーパラメータを表 5 に示します。表 6 に堅牢性テストの結果を示しますが、一般に WSAM は SAM、ESAM、GSAM よりも優れた堅牢性を持っています。
値を決定しました。次に、他のオプティマイザー固有のハイパーパラメーターを個別に検索して、最適な汎化パフォーマンスを見つけます。結果を再現するために必要なハイパーパラメータを表 5 に示します。表 6 に堅牢性テストの結果を示しますが、一般に WSAM は SAM、ESAM、GSAM よりも優れた堅牢性を持っています。 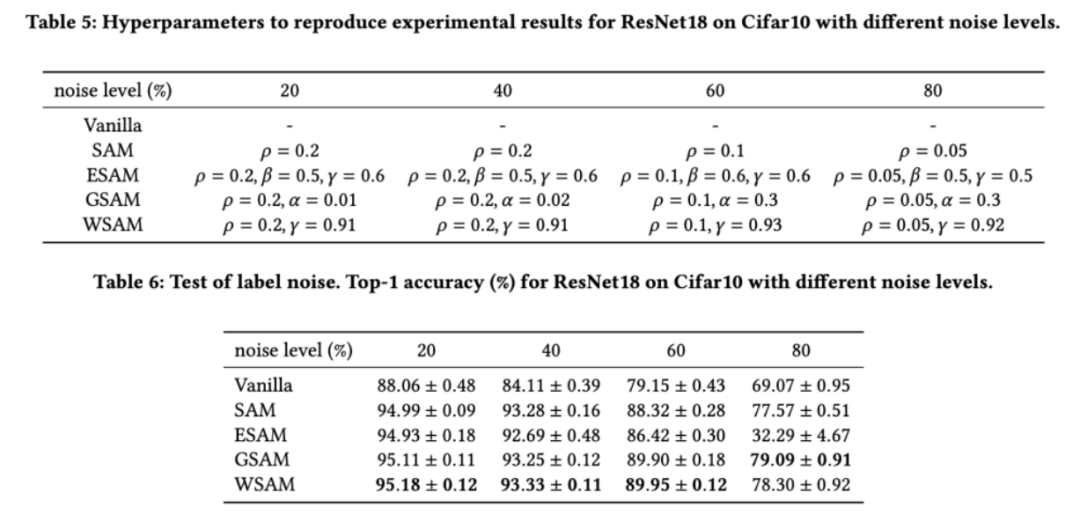
幾何構造の影響の調査
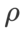 と
と 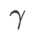 以外のパラメータを除き、画像分類での設定を再利用します。以前の研究 [4、5] によると、ASAM と Fisher SAM の
以外のパラメータを除き、画像分類での設定を再利用します。以前の研究 [4、5] によると、ASAM と Fisher SAM の 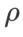 は通常より大きくなります。 {0.1, 0.5, 1.0,…, 6.0} で最適な
は通常より大きくなります。 {0.1, 0.5, 1.0,…, 6.0} で最適な 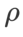 を検索します。ASAM と Fisher SAM の両方で最適な
を検索します。ASAM と Fisher SAM の両方で最適な 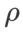 は 5.0 です。その後、ステップ サイズ 0.02 で 0.80 ~ 0.94 の WSAM の最適な
は 5.0 です。その後、ステップ サイズ 0.02 で 0.80 ~ 0.94 の WSAM の最適な 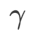 を検索しました。両方の方法の最適な
を検索しました。両方の方法の最適な 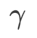 は 0.88 でした。
は 0.88 でした。 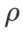 ベースラインを使用して WSAM を直接使用することをお勧めします。
ベースラインを使用して WSAM を直接使用することをお勧めします。 
アブレーション実験
極点分析
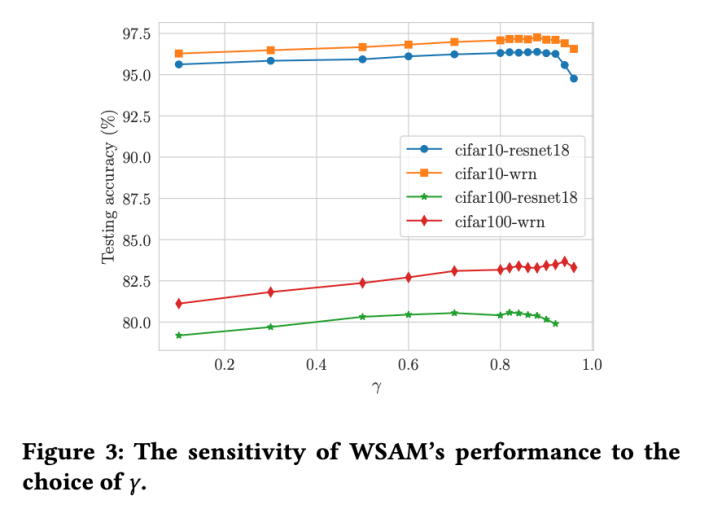
ハイパーパラメータの感度
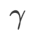 があります。平坦な (急な) 度項のサイズをスケールします。ここでは、このハイパーパラメータに対する WSAM の汎化パフォーマンスの感度をテストします。 Cifar10 および Cifar100 で WSAM を使用し、広範囲の
があります。平坦な (急な) 度項のサイズをスケールします。ここでは、このハイパーパラメータに対する WSAM の汎化パフォーマンスの感度をテストします。 Cifar10 および Cifar100 で WSAM を使用し、広範囲の 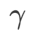 値を使用して ResNet18 および WRN-28-10 モデルをトレーニングしました。図 3 に示すように、結果は、WSAM がハイパーパラメーターの選択に影響を受けないことを示しています。また、WSAM の最適な汎化パフォーマンスは、ほとんどの場合、0.8 ~ 0.95 の間にあることもわかりました。
値を使用して ResNet18 および WRN-28-10 モデルをトレーニングしました。図 3 に示すように、結果は、WSAM がハイパーパラメーターの選択に影響を受けないことを示しています。また、WSAM の最適な汎化パフォーマンスは、ほとんどの場合、0.8 ~ 0.95 の間にあることもわかりました。 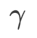
以上がより多用途かつ効果的な、Ant の自社開発オプティマイザー WSAM が KDD Oral に採用されましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。