
ホームページ >テクノロジー周辺機器 >AI >世界モデルが光る!これら 20 以上の自動運転シナリオ データの現実性は信じられないほどです...
世界モデルが光る!これら 20 以上の自動運転シナリオ データの現実性は信じられないほどです...

- PHPz転載
- 2023-10-09 15:01:20760ブラウズ
これは普通の退屈な自動運転ビデオだと思いますか?

このコンテンツの元の意味を変更する必要はありません。中国語に書き直す必要があります。
1 つのフレームも「本物」ではありません。

さまざまな道路状況、さまざまな気象条件、 20 を超える 状況をシミュレートでき、その効果は本物とまったく同じです。


90 億パラメータ の規模を持ち、4700 時間 の運転ビデオ トレーニングを使用して、ビデオ、テキスト、または操作を入力して自動運転を生成する効果を実現します。ビデオ。
最も直接的な利点は、将来のイベントをより正確に予測できることです。 20 以上のシナリオをシミュレーションできるため、自動運転の安全性がさらに向上し、コストが削減されます。
生成できます 。

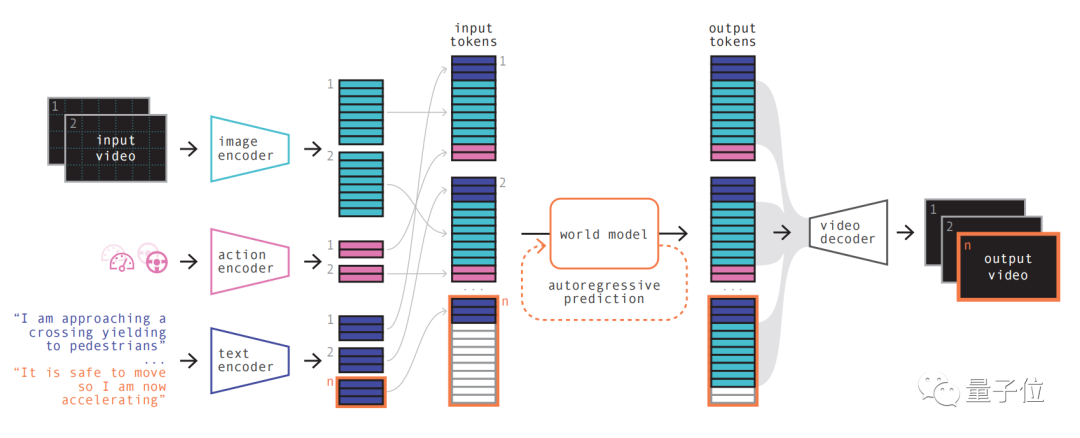
ワールド モデル が表示されます。
自己回帰トランスフォーマーとして、シーケンス内の次の画像トークンのセットを予測する機能があります。以前の画像トークンだけでなく、テキストやアクションのコンテキスト情報も考慮します。モデルによって生成されたコンテンツは、画像だけでなく、予測されたテキストやアクションとも一貫性を維持します チームによると、GAIA-1 の世界モデルのサイズは65 億パラメーター で、64 台の A100 で 15 日間トレーニングされました。
ビデオ デコーダとビデオ拡散モデルを使用することにより、これらのトークンは最終的にビデオに変換されます。 このステップは、ビデオの意味論的な品質、画像の精度、および時間的一貫性に関するものです。GAIA-1 のビデオ デコーダは 26 億パラメータ の規模を持ち、32 台の A100 を使用して 15 日間トレーニングされました。
GAIA-1 は原理的に大規模言語モデルと類似しているだけでなく、モデル規模が拡大するにつれて生成品質が向上するという 特性を示していることは注目に値します。



- 安全性
- 包括的なトレーニング データ
- ロングテール シナリオ
Wayve から提供されています。
Wayve はMicrosoft などの投資家とともに 2017 年に設立され、その評価額は Unicorn に達しています。
創設者は、現在の CEO である Alex Kendall と Amar Shah です (同社の公式 Web サイトのリーダーシップ ページには、もう彼らに関する情報はありません)。2 人ともケンブリッジ大学を卒業し、機械学習の博士号を取得しています

LINGO-1 もセンセーションを巻き起こしました。
この自動運転モデルは、運転中にリアルタイムで説明を生成できるため、モデルの解釈可能性がさらに向上します今年 3 月には、ビル ゲイツ氏も Wayve の Self-Driving に試乗しました。車の運転。
文書アドレス: https://arxiv.org/abs/2309.17080
 書き換える必要がある内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/bwTDovx9-UArk5lx5pZPag
書き換える必要がある内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/bwTDovx9-UArk5lx5pZPag
以上が世界モデルが光る!これら 20 以上の自動運転シナリオ データの現実性は信じられないほどです...の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。