
ホームページ >テクノロジー周辺機器 >AI >Zhiyuan は 3 億のセマンティック ベクトル モデルのトレーニング データを公開しており、BGE モデルは繰り返し更新され続けています。
Zhiyuan は 3 億のセマンティック ベクトル モデルのトレーニング データを公開しており、BGE モデルは繰り返し更新され続けています。

- 王林転載
- 2023-09-21 21:33:111514ブラウズ
大規模モデルの急速な開発と応用に伴い、大規模モデルの中核となる基本コンポーネントである埋め込みの重要性がますます高まっています。 Zhiyuan Company が 1 か月前にリリースした、オープンソースで商用利用可能な中国語 - 英語のセマンティック ベクトル モデル BGE (BAAI General Embedding) は、コミュニティで広く注目を集め、Hugging Face プラットフォームで数十万回ダウンロードされました。現在、BGE はバージョン 1.5 を迅速にリリースし、複数のアップデートを発表しています。その中で、BGE は 3 億個の大規模トレーニング データを初めてオープンソース化し、同様のモデルのトレーニングに役立つコミュニティを提供し、この分野の技術開発を促進しました
- #MTP データセット リンク: https://data.baai.ac.cn/details/BAAI-MTP
- BGE モデル リンク: https://huggingface.co /BAAI
- BGE コード リポジトリ: https:/ /www.php.cn/link /8944871f1c9865a77a3d9c92cadf124d
30 億の中国語と英語のベクトル モデル トレーニング データがオープン
業界初のオープンソースのセマンティック ベクトル モデル トレーニング データは 3 億件の中国語と英語のデータに達します
BGE の卓越した機能は、大規模で多様なトレーニング データに大きく由来しています。以前は、同業他社が同様のデータセットをリリースすることはほとんどありませんでした。今回のアップデートで、Zhiyuan は BGE トレーニング データを初めてコミュニティに公開し、このタイプのテクノロジーのさらなる開発の基礎を築きました。
MTPが今回公開したデータセットは、合計3億件の中国語と英語関連のテキストペアで構成されています。そのうち、中国語のレコードが 1 億件、英語のレコードが 2 億件あります。データのソースには、Wudao Corpora、Pile、DuReader、Sentence Transformer、およびその他のコーパスが含まれます。必要なサンプリング、抽出、洗浄を行った後、
# が得られます。詳細については、データハブ: https://data.baai.ac.cn# を参照してください。 ##MTP は、これまでで最大のオープンソースの中国語と英語関連のテキスト ペア データ セットであり、中国語と英語のセマンティック ベクトル モデルをトレーニングするための重要な基盤を提供します。
開発者コミュニティに応え、BGE 機能のアップグレード
コミュニティからのフィードバックに基づいて、BGE はバージョン 1.0 に基づいてさらに最適化されました。その性能はより安定し、優れています。具体的なアップグレード内容は以下の通りです。
#モデルアップデート。 BGE-*-zh-v1.5 は、トレーニング データをフィルタリングし、低品質のデータを削除し、トレーニング中の温度係数を 0.02 に増やすことで類似度分布の問題を軽減し、類似度の値をより安定させます。 ############ニューモデル。オープン ソースの BGE-reranker クロス エンコーダ モデルは、関連するテキストをより正確に検索でき、中国語と英語のバイリンガルをサポートします。ベクトルを出力する必要があるベクトル モデルとは異なり、BGE-reranker はテキスト ペア間の類似度を直接出力し、ランク付けの精度が高く、ベクトルの再現結果を並べ替えて、最終結果の関連性を向上させるために使用できます。
- 新機能。 BGE1.1では、ネガティブになりにくいサンプルマイニングスクリプトを追加 ネガティブになりにくいサンプルは、微調整後の検索効果を効果的に向上させることができます 微調整コードに微調整中の命令を追加する機能を追加 モデルの保存また、自動的に文変換形式に変換されるため、モデルの読み込みが容易になります。
- 最近、Zhiyuan と Hugging Face が、中国語のユニバーサル セマンティック ベクトル モデルを強化するために C-Pack を使用することを提案した技術レポートをリリースしたことは言及する価値があります。
- 《C-Pack: 一般的な中国語埋め込みを促進するためのパッケージ化されたリソース》
リンク: https://arxiv.org/pdf/2309.07597 .pdf
##開発者コミュニティで高い人気を獲得
BGE は、リリース以来、大規模なモデル開発者コミュニティの注目を集めています。ダウンロード数は数十万回に達し、有名なオープンソース プロジェクト LangChain、LangChain-Chachat、llama_index などに統合されて使用されています。
Langchain LangChainの共同創設者兼CEOのオフィシャル・ハリソン・チェイス氏、ディープ・トレーディングの創設者ヤム・ペレグ氏、その他のコミュニティの影響力者はBGEについて懸念を表明した。
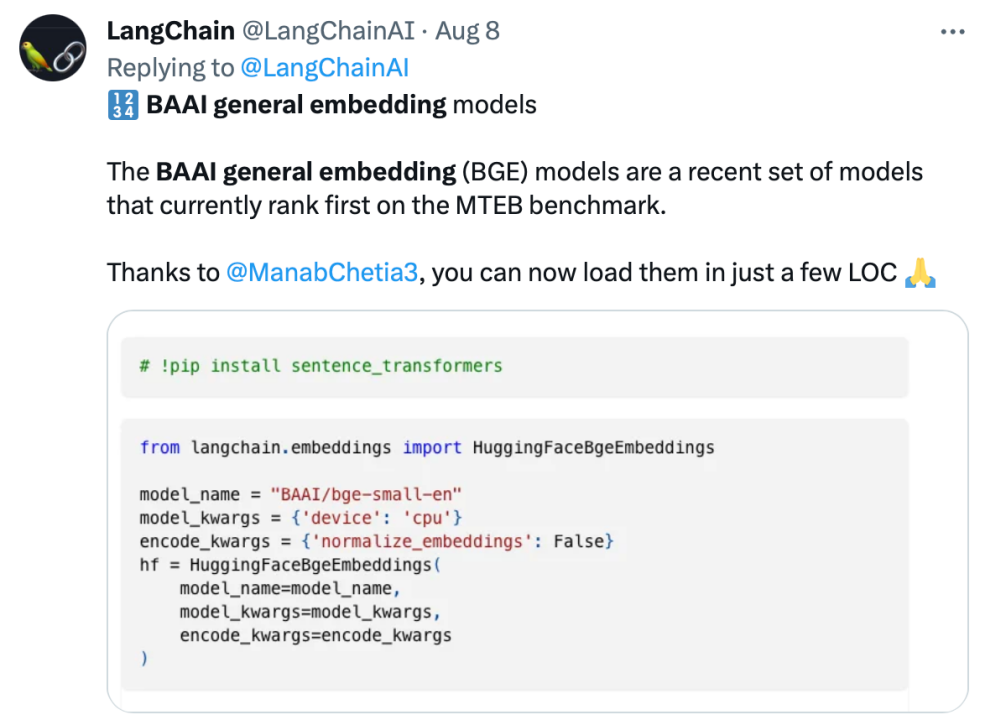
オープン ソースを遵守し、共同イノベーションを促進する Zhiyuan 大型モデル テクノロジ開発システム FlagOpen BGE は、埋め込みテクノロジとモデルに焦点を当てた新しい FlagEmbedding セクションを追加しました。BGE は、注目度の高いオープン ソース プロジェクトの 1 つです。 FlagOpen は、大型モデル時代の人工知能テクノロジー インフラストラクチャの構築に取り組んでおり、今後もより完全な大型モデルのフルスタック テクノロジーを学界や産業界に公開し続けます
以上がZhiyuan は 3 億のセマンティック ベクトル モデルのトレーニング データを公開しており、BGE モデルは繰り返し更新され続けています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- Tencent qqmail プラグインとはどのようなソフトウェアですか?
- AIでレイヤーを結合するためのショートカットキーは何ですか?
- GPT-4 論文には隠された手がかりがあります: GPT-5 はトレーニングを完了する可能性があり、OpenAI は 2 年以内に AGI に近づくでしょう
- Volcano Engine は、Shenzhen Technology が業界初の 3D 分子事前トレーニング モデル Uni-Mol をリリースするのに役立ちます
- NUS と Byte は業界を超えて協力し、モデルの最適化を通じて 72 倍高速なトレーニングを実現し、AAAI2023 の優秀論文を受賞しました。