
ホームページ >テクノロジー周辺機器 >AI >Taotian GroupとAicheng Technologyが協力して、オープンソースの大規模モデルトレーニングフレームワークMegatron-LLaMAをリリース
Taotian GroupとAicheng Technologyが協力して、オープンソースの大規模モデルトレーニングフレームワークMegatron-LLaMAをリリース

- 王林転載
- 2023-09-19 19:05:07670ブラウズ
Taotian Group と Aicheng Technology は 9 月 12 日、大規模モデル トレーニング フレームワーク Megatron-LLaMA を正式にオープンソース化し、技術開発者が大規模言語モデルのトレーニング パフォーマンスをより便利に向上させ、トレーニング コストを削減できるようにすることを目指しています。 LLaMAコミュニティ。テストの結果、32 枚のカードのトレーニングでは、Megatron-LLaMA は HuggingFace から直接取得したコード バージョンと比較して 176% の高速化を達成でき、大規模なトレーニングでは、Megatron-LLaMA は 32 枚のカードと比較してほぼ直線的なスケーラビリティを有し、高い耐性を示します。ネットワークが不安定になるため。現在、Megatron-LLaMA はオープンソース コミュニティでオンラインになっています。
オープンソースアドレス: https://github.com/alibaba/Megatron-LLaMA
32 枚のカードのトレーニングでは、HuggingFace から直接取得したコード バージョンと比較して、Megatron-LLaMA は 176% の高速化を達成できます; DeepSpeed と FlashAttend の最適化されたバージョンを使用しても、Megatron-LLaMA はトレーニング時間を少なくとも 19% 削減できます。 大規模なトレーニングでは、Megatron-LLaMA は 32 枚のカードと比較して ほぼ線形のスケーラビリティ を実現します。たとえば、512 A100 を使用して LLaMA-13B のトレーニングを再現すると、Megatron-LLaMA のリバース メカニズムにより、精度を損なうことなく、ネイティブ Megatron-LM の DistributedOptimizer と比較して少なくとも 2 日を節約できます。 -
Megatron-LLaMA は、ネットワークの不安定性に対して高い耐性を示します。 4x200Gbps 通信帯域幅を備えた現在のコスト効率の高い 8xA100-80GB トレーニング クラスターでも (この環境は通常、混合展開環境であり、ネットワークは帯域幅の半分しか使用できません。ネットワーク帯域幅は深刻なボトルネックですが、レンタル価格は比較的低い)、Megatron-LLaMA は依然として 0.85 の線形膨張能力を達成できますが、Megatron-LM はこの指標で 0.7 未満しか達成できません。 Mega によってもたらされる高パフォーマンスの LLaMA トレーニングの機会を得るためにtron-LM テクノロジー LLaMA は現在大規模な言語モデルですオープンソースコミュニティは重要な任務です。 LLaMAは、LLMの構造にBPE文字エンコーディング、RoPE位置エンコーディング、SwiGLU活性化関数、RMSNorm正則化、Untied Embeddingなどの最適化技術を導入し、多くの客観的・主観的評価において優れた成果をあげています。 LLaMA は 7B、13B、30B、65B/70B バージョンを提供しており、大規模なモデルを必要とするさまざまなシナリオに適しており、開発者にも好まれています。多くのオープンソースの大規模モデルと同様、公式はコードの推論バージョンのみを提供するため、最小限のコストで効率的なトレーニングを実行する方法に関する標準パラダイムはありません。ただし、Megatron-LM に基づく開発は簡単ではなく、高価なマルチカード マシンでのデバッグと機能検証には非常にコストがかかります。 Megatron-LLaMA は、まず Megatron-LM フレームワークに基づいた LLaMA トレーニング コードのセットを提供し、さまざまなサイズのモデル バージョンをサポートし、HuggingFace 形式の Tokenizer の直接サポートなど、LLaMA のさまざまなバリアントをサポートするように簡単に適合させることができます。したがって、Megatron-LLaMA は、過剰な適応を行うことなく、既存のオフライン トレーニング リンクに簡単に適用できます。 LLaMA-7b および LLaMA-13b の中小規模のトレーニング/微調整シナリオでは、Megatron-LLaMA は業界をリードする 54% 以上のハードウェア使用率 (MFU) を容易に達成できます。
MEGATRON-LLAMA の逆プロセス最適化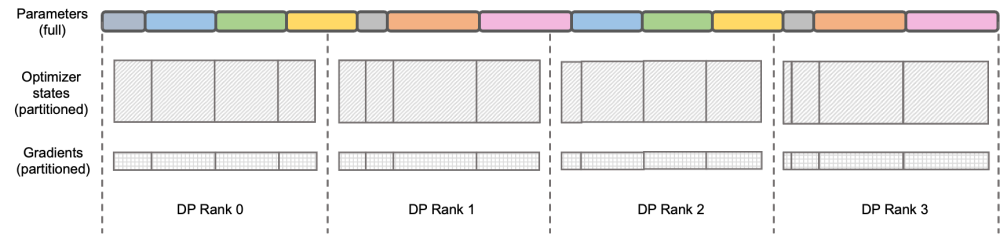 ## igue: DEEPSPEED ZERO Stage-2 DeepSpeed ZeRO は Microsoft が立ち上げた分散トレーニング フレームワークであり、そこで提案されたテクノロジはその後の多くのフレームワークに大きな影響を与えました。 DeepSpeed ZeRO Stage-2 (以下、ZeRO-2) は、計算や通信の負荷を追加することなくメモリ使用量を節約するフレームワークのテクノロジです。上の図に示すように、計算要件により、各ランクにはすべてのパラメータが必要です。ただし、オプティマイザ状態の場合、各ランクはその一部のみを担当し、すべてのランクが完全に繰り返される操作を同時に実行する必要はありません。したがって、ZeRO-2 では、オプティマイザーの状態を各ランクに均等に分割することを提案しています (各変数が均等に分割されているか、特定のランクに完全に保持されていることを保証する必要はないことに注意してください)。各ランクはトレーニング プロセス中にのみ使用する必要があります。 . オプティマイザのステータスと対応する部分のモデル パラメータを更新します。この設定では、この方法でグラデーションを分割することもできます。デフォルトでは、ZeRO-2 は Reduce メソッドを使用してすべてのランク間の勾配を逆に集計します。その後、各ランクは担当するパラメーターの一部を保持するだけで済みます。これにより、冗長な繰り返し計算が排除されるだけでなく、メモリも削減されます。使用法。 。
## igue: DEEPSPEED ZERO Stage-2 DeepSpeed ZeRO は Microsoft が立ち上げた分散トレーニング フレームワークであり、そこで提案されたテクノロジはその後の多くのフレームワークに大きな影響を与えました。 DeepSpeed ZeRO Stage-2 (以下、ZeRO-2) は、計算や通信の負荷を追加することなくメモリ使用量を節約するフレームワークのテクノロジです。上の図に示すように、計算要件により、各ランクにはすべてのパラメータが必要です。ただし、オプティマイザ状態の場合、各ランクはその一部のみを担当し、すべてのランクが完全に繰り返される操作を同時に実行する必要はありません。したがって、ZeRO-2 では、オプティマイザーの状態を各ランクに均等に分割することを提案しています (各変数が均等に分割されているか、特定のランクに完全に保持されていることを保証する必要はないことに注意してください)。各ランクはトレーニング プロセス中にのみ使用する必要があります。 . オプティマイザのステータスと対応する部分のモデル パラメータを更新します。この設定では、この方法でグラデーションを分割することもできます。デフォルトでは、ZeRO-2 は Reduce メソッドを使用してすべてのランク間の勾配を逆に集計します。その後、各ランクは担当するパラメーターの一部を保持するだけで済みます。これにより、冗長な繰り返し計算が排除されるだけでなく、メモリも削減されます。使用法。 。
Megatron-LM DistributedOptimizer
Native Megatron-LM は、DistributedOptimizer を通じて ZeRO-2 のような勾配とオプティマイザー状態のセグメンテーションを実装し、トレーニング中のビデオ メモリの使用量を削減します。上の図に示すように、DistributedOptimizer は、プリセット勾配によって集約されたすべての勾配を取得した後、ReduceScatter オペレーターを使用して、以前に蓄積されたすべての勾配を異なるランクに分配します。各ランクは、処理する必要がある勾配の一部のみを取得し、オプティマイザーの状態と対応するパラメーターを更新します。最後に、各ランクは AllGather を通じて他のノードから更新されたパラメーターを取得し、最終的にすべてのパラメーターを取得します。実際のトレーニング結果は、Megatron-LM の勾配とパラメーターの通信が他の計算と直列に実行されることを示しています。大規模な事前トレーニング タスクの場合、バッチ データの合計サイズを変更しないようにするには、通常、より大きな GA を開きます。したがって、マシンの増加に伴って通信の割合が増加しますが、このときシリアル通信の特性上、拡張性が非常に弱くなります。コミュニティ内でもそのニーズは深刻です。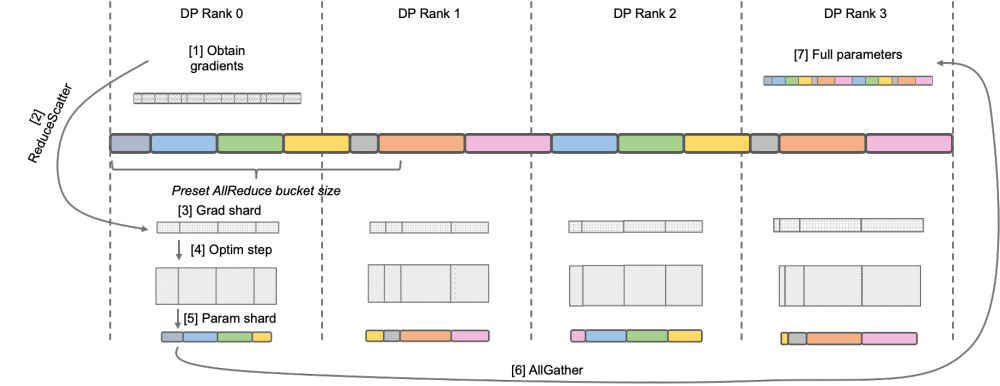 over ‐ over ‐‐ over‐ over‐‐‐‐‐‐ C S PC C _ ‐ ‐ L ‐ L's-M-‐‐‐‐‐'' の DistributedOptimizer を使用して勾配を伝達します。演算子は計算と並行して実行できます。特に、Megatron-LLaMA は、ZeRO の実装と比較して、よりスケーラブルな集合通信方式を使用し、並列処理を前提としたオプティマイザ分割戦略の賢明な最適化を通じてスケーラビリティを向上させます。OverlappedDistributedOptimizer の主な設計は、次の点を保証します: a) 単一セットの通信事業者のデータ量が、通信帯域幅を最大限に活用するのに十分な大きさであること、b) 新しい分割方法で必要な通信データ量が最小限に等しいことデータ並列処理に必要な通信データ量 c) 完全なパラメータまたは勾配およびセグメント化されたパラメータまたは勾配の変換プロセス中に、多すぎるビデオ メモリ コピーを導入することはできません。
over ‐ over ‐‐ over‐ over‐‐‐‐‐‐ C S PC C _ ‐ ‐ L ‐ L's-M-‐‐‐‐‐'' の DistributedOptimizer を使用して勾配を伝達します。演算子は計算と並行して実行できます。特に、Megatron-LLaMA は、ZeRO の実装と比較して、よりスケーラブルな集合通信方式を使用し、並列処理を前提としたオプティマイザ分割戦略の賢明な最適化を通じてスケーラビリティを向上させます。OverlappedDistributedOptimizer の主な設計は、次の点を保証します: a) 単一セットの通信事業者のデータ量が、通信帯域幅を最大限に活用するのに十分な大きさであること、b) 新しい分割方法で必要な通信データ量が最小限に等しいことデータ並列処理に必要な通信データ量 c) 完全なパラメータまたは勾配およびセグメント化されたパラメータまたは勾配の変換プロセス中に、多すぎるビデオ メモリ コピーを導入することはできません。 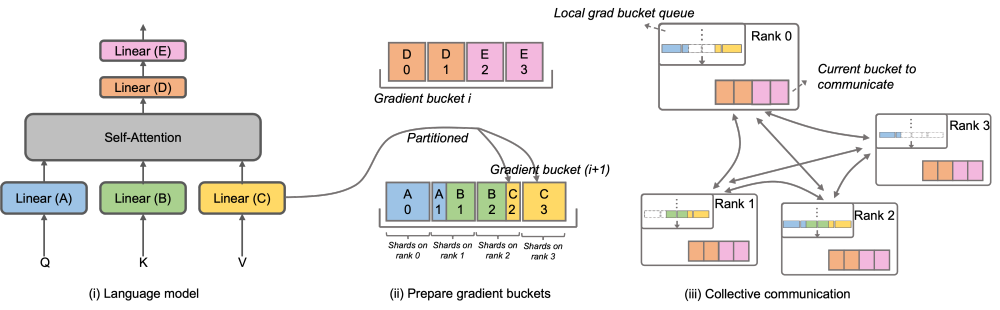
具体的には、Megatron-LLaMA は DistributedOptimizer のメカニズムを改善し、新しいセグメンテーション手法と組み合わせてトレーニングにおける逆プロセスを最適化するために使用される OverlappedDistributedOptimizer を提案します。上の図に示すように、OverlappedDistributedOptimizer が初期化されると、すべてのパラメーターが、それらが属するバケットに事前に割り当てられます。バケット内のパラメータは完全です。パラメータは 1 つのバケットにのみ属します。バケットには複数のパラメータが存在する場合があります。論理的には、各バケットは連続的に P (P はデータ並列グループの数) の等しい部分に分割され、データ並列グループ内の各ランクがそのうちの 1 つを担当します。 #バケットは、通信順序を確保するためにローカル キュー (ローカル grad バケット キュー) に配置されます。トレーニングと計算中に、データ並列グループはバケット単位での集団通信を通じて必要な勾配を交換します。 Megatron-LLaMA のバケットの実装では、アドレス インデックスを可能な限り使用し、必要な値が変更された場合にのみ新たにスペースを割り当て、ビデオ メモリの無駄を回避します。 上記の設計と多数のエンジニアリング最適化を組み合わせることで、Megatron-LLaMA は大規模トレーニング中にハードウェアを最大限に活用し、ネイティブ Megatron よりも優れたパフォーマンスを実現できます。 -LM 加速が良くなります。 32 枚の A100 カードから 512 枚の A100 カードにトレーニングする場合でも、Megatron-LLaMA は、一般的に使用される混合ネットワーク環境で 0.85 の拡張率を達成できます。
MEGATRON-LLAMA の将来計画# MEGATRON-LLAMA は共同オープンソースであり、Taitian Group と Ai Orange Technology によってその後のメンテナンス サポートを提供します。トレーニングフレームワークは社内で広く使用されています。ますます多くの開発者が LLaMA のオープンソース コミュニティに集まり、お互いから学べる経験を提供するにつれて、将来的にはトレーニング フレームワーク レベルでより多くの課題と機会が生まれると私は信じています。 Megatron-LLaMA はコミュニティの発展に細心の注意を払い、開発者と協力して次の方向性を推進していきます: 適応型の最適な構成の選択 - その他のサポートモデル構造またはローカル設計変更の場合
よりさまざまな種類のハードウェア環境における究極のパフォーマンス トレーニング ソリューション
プロジェクト アドレス: https://github.com/alibaba/Megatron-LLaMA #
以上がTaotian GroupとAicheng Technologyが協力して、オープンソースの大規模モデルトレーニングフレームワークMegatron-LLaMAをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はjiqizhixin.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。