
ホームページ >テクノロジー周辺機器 >AI >ICCV 2023 Oral | オープンワールドでテスト セグメント トレーニングを実施するにはどうすればよいですか?動的なプロトタイプ展開に基づく自己トレーニング手法
ICCV 2023 Oral | オープンワールドでテスト セグメント トレーニングを実施するにはどうすればよいですか?動的なプロトタイプ展開に基づく自己トレーニング手法

- 王林転載
- 2023-09-17 21:21:06720ブラウズ
視覚ベースの知覚手法の実装を推進する場合、モデルの汎化能力を向上させることが重要な基盤となります。テスト時トレーニング/適応 (テスト時トレーニング/適応) では、テスト フェーズ中にモデル パラメーターの重みを調整することで、モデルを未知のターゲット ドメインのデータ分布に適応させることができます。既存の TTT/TTA 手法は通常、閉じた環境でターゲット ドメイン データの下でテスト セグメントのトレーニング パフォーマンスを向上させることに重点を置いていますが、多くのアプリケーション シナリオでは、ターゲット ドメインは強力なドメイン外データ (強い OOD) の影響を受けやすくなります。 、意味的に無関係なデータ カテゴリなど。このケースはオープンワールド テスト セグメント トレーニング (OWTTT) とも呼ばれ、既存の TTT/TTA は通常、強力なドメイン外データを既知のカテゴリに強制的に分類し、最終的には次のような弱いドメイン外データ (弱い OOD) を妨害します。ノイズによって乱された画像の認識能力
最近、華南理工大学とA*STARチームは初めてオープンワールドテストセグメントトレーニングの設定を提案し、対応するトレーニング方法を開始しました

- 論文: https://arxiv.org/abs/2308.09942
- 書き直す必要がある内容は次のとおりです。コードリンク: https://github.com/Yushu-Li/OWTTT
- この記事ではまず、適応しきい値を使用した強力なドメイン外データ サンプル フィルタリング手法を提案します。これにより、ロバスト性のオープンワールドにおける自己トレーニング TTT メソッドのパフォーマンス。この方法はさらに、動的に拡張されたプロトタイプに基づいて強力なドメイン外サンプルを特徴付けて、弱い/強いドメイン外データ分離効果を改善する方法を提案します。最後に、自己トレーニングは分布の調整によって制約されます。
この記事の方法は、5 つの異なる OWTTT ベンチマークで最適なパフォーマンスを達成し、より堅牢な TTT 方法を探求するための TTT に関するその後の研究に新しい方向性を提供します。この研究は、ICCV 2023 の口頭論文として受理されました。
はじめにテスト セグメント トレーニング (TTT) は、推論フェーズ中にのみターゲット ドメイン データにアクセスし、分布シフトのあるテスト データに対してオンザフライ推論を実行できます。 TTT の成功は、人工的に選択された多数の合成的に破損したターゲット ドメイン データで実証されています。ただし、既存の TTT 手法の機能の限界は十分に調査されていません。
オープン シナリオで TTT アプリケーションを推進するために、研究の焦点は TTT 手法が失敗する可能性があるシナリオの調査に移ってきました。より現実的なオープンワールド環境で安定した堅牢な TTT 手法を開発するために多くの努力が払われてきました。この作業では、ターゲット ドメインに、ソース ドメインとは異なるセマンティック カテゴリや単なるランダム ノイズなど、大幅に異なる環境から抽出されたテスト データ分布が含まれる可能性がある、一般的だが見落とされているオープンワールド シナリオを掘り下げます。
上記のテスト データを強力な分布外データ (strong OOD) と呼びます。本作で弱いOODデータと呼んでいるのは、一般的な合成ダメージなどの分布シフトを伴うテストデータです。したがって、この現実の環境に関する既存の作業が不足しているため、テスト データが強力な OOD サンプルによって汚染されているオープン ワールド テスト セグメント トレーニング (OWTTT) の堅牢性の向上を検討する動機になります。
##書き換える必要がある内容は次のとおりです。 図 1: OWTTT 設定での既存の TTT メソッドの評価結果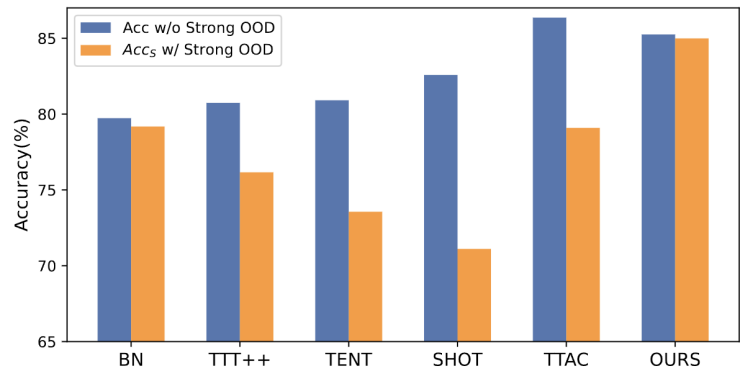
図によると1 示されているように、最初に OWTTT 設定の下で既存の TTT メソッドを評価し、自己トレーニングと分布調整による TTT メソッドが強い OOD サンプルの影響を受けることがわかりました。これらの結果は、オープンワールドで既存の TTT テクノロジーを適用しても安全なテスト トレーニングを達成できないことを示しています。失敗の原因は次の 2 つであると考えられます。セルフ トレーニング ベースの TTT では、テスト サンプルを既知のクラスに割り当てる必要があるため、強力な OOD サンプルを処理することが困難です。一部の信頼性の低いサンプルは、半教師あり学習で使用されるしきい値を適用することで除外できますが、すべての強力な OOD サンプルが除外されるという保証はまだありません。
- 分布調整に基づく方法は、ターゲット ドメインの分布を推定するために強力な OOD サンプルを計算するときに影響を受けます。グローバル分布アライメント [1] とクラス分布アライメント [2] の両方が影響を受け、不正確なフィーチャ分布アライメントにつながる可能性があります。
- 自己学習フレームワークの下でオープンワールド TTT の堅牢性を向上させるために、既存の TTT 手法が失敗する潜在的な理由を検討し、2 つのテクノロジーを組み合わせたソリューションを提案しました。
まず、自己トレーニングされたバリアントで TTT のベースラインを確立します。つまり、ソース ドメイン プロトタイプをクラスター センターとして使用してターゲット ドメインでクラスタリングします。偽の擬似ラベルによる自己学習に対する強い OOD の影響を軽減するために、強い OOD サンプルを拒否するハイパーパラメータフリーの方法を提案します。
弱い OOD サンプルと強い OOD サンプルの特性をさらに分離する、プロトタイプを許可します。分離された強力な OOD サンプルを選択することでプールが拡張されます。したがって、自己トレーニングにより、強力な OOD サンプルが、新しく拡張された強力な OOD プロトタイプの周囲に密なクラスターを形成できるようになります。これにより、ソース ドメインとターゲット ドメイン間の配布の調整が容易になります。さらに、確証バイアスのリスクを軽減するために、グローバルな分布の調整を通じて自己トレーニングを定期的に行うことを提案します。
最後に、オープンワールド TTT シナリオを合成するために、CIFAR10-C、CIFAR100-C、ImageNet-C、VisDA-C、ImageNet-R、Tiny-ImageNet、MNIST、および SVHN データ セットを使用します。データセットは弱い OOD であり、他のセットはベンチマーク データ セットを確立するための強い OOD です。私たちはこのベンチマークをオープンワールド テスト セグメント トレーニング ベンチマークと呼び、これにより、より現実的なシナリオでのテスト セグメント トレーニングの堅牢性に焦点を当てた今後の作業が促進されることを期待しています。
方法
この論文は 4 つのパートに分かれて、提案された方法を紹介します。
1) オープンワールドでのテスト セクションの トレーニング タスクの設定の概要。
2) 使用方法の紹介プロトタイプ クラスタリングは、データ セット内のサンプルをさまざまなカテゴリにクラスタリングするために使用される教師なし学習アルゴリズムです。プロトタイプ クラスタリングでは、各カテゴリは 1 つ以上のプロトタイプによって表されます。プロトタイプは、データ セット内のサンプルであるか、またはいくつかのルールに従って生成されます。プロトタイプ クラスタリングの目標は、サンプルとそれらが属するカテゴリのプロトタイプとの間の距離を最小限に抑えてクラスタリングを達成することです。一般的なプロトタイプのクラスタリング アルゴリズムには、K 平均法クラスタリングと混合ガウス モデルが含まれます。これらのアルゴリズムは、データ マイニング、パターン認識、画像処理などの分野で広く使用されています。 TTT の実装と、オープンワールドのテスト時トレーニング用にプロトタイプを拡張する方法。
3) ターゲット ドメイン データを使用して書き換える必要がある内容は次のとおりです: 動的プロトタイプ拡張機能。
4)Distribution Alignment とプロトタイプ クラスタリングの導入は、データ セット内のサンプルをさまざまなカテゴリにクラスタリングするために使用される教師なし学習アルゴリズムです。プロトタイプ クラスタリングでは、各カテゴリは 1 つ以上のプロトタイプによって表されます。プロトタイプは、データ セット内のサンプルであるか、またはいくつかのルールに従って生成されます。プロトタイプ クラスタリングの目標は、サンプルとそれらが属するカテゴリのプロトタイプとの間の距離を最小限に抑えてクラスタリングを達成することです。一般的なプロトタイプのクラスタリング アルゴリズムには、K 平均法クラスタリングと混合ガウス モデルが含まれます。データマイニング、パターン認識、画像処理などの分野で広く使用されているこれらのアルゴリズムを組み合わせることで、強力なオープンワールドのテスト時トレーニングが可能になります。
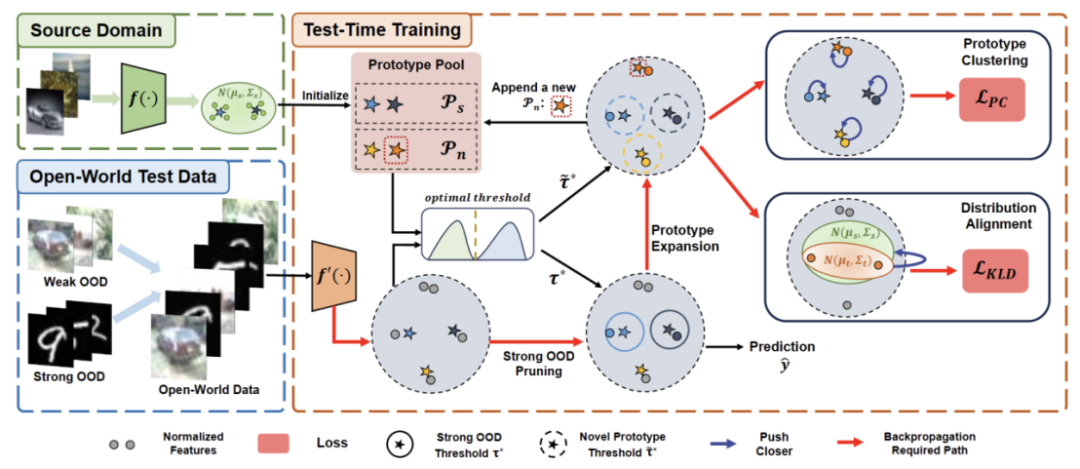
#書き直す必要がある内容は次のとおりです。 図 2: メソッドの概要図
TaskTTT を設定する目的は、ソース ドメインに対してターゲット ドメインの分布が変化する可能性がある場合に、ソース ドメインの事前トレーニング済みモデルをターゲット ドメインに適応させることです。標準のクローズドワールド TTT では、ソース ドメインとターゲット ドメインのラベル スペースは同じです。ただし、オープンワールド TTT では、ターゲット ドメインのラベル スペースにソース ドメインのターゲット スペースが含まれます。これは、ターゲット ドメインにまだ見たことのない新しいセマンティック カテゴリがあることを意味します。
TTT 定義間の混乱を避けるために、 TTAC [2] で提案されている Sequential Test Time Training (sTTT) プロトコルを採用し、評価します。 sTTT プロトコルでは、テスト サンプルが順次テストされ、テスト サンプルの小さなバッチを観察した後にモデルの更新が実行されます。タイムスタンプ t に到着するテスト サンプルの予測は、t k (k は 0 より大きい) に到着するテスト サンプルの影響を受けません。
プロトタイプ クラスタリングは、データ セット内のサンプルをさまざまなカテゴリにクラスタリングするために使用される教師なし学習アルゴリズムです。プロトタイプ クラスタリングでは、各カテゴリは 1 つ以上のプロトタイプによって表されます。プロトタイプは、データ セット内のサンプルであるか、またはいくつかのルールに従って生成されます。プロトタイプ クラスタリングの目標は、サンプルとそれらが属するカテゴリのプロトタイプとの間の距離を最小限に抑えてクラスタリングを達成することです。一般的なプロトタイプのクラスタリング アルゴリズムには、K 平均法クラスタリングと混合ガウス モデルが含まれます。これらのアルゴリズムは、データ マイニング、パターン認識、画像処理などの分野で広く使用されていますドメイン適応タスクでのクラスタリングを使用する作業 [3,4] に触発され、テスト セグメントのトレーニングを発見として扱います。ターゲット ドメイン データのクラスター構造。代表的なプロトタイプをクラスター中心として特定することにより、クラスター構造がターゲット ドメイン内で特定され、テスト サンプルをプロトタイプの 1 つの近くに埋め込むことが推奨されます。プロトタイプ クラスタリングは、データ セット内のサンプルをさまざまなカテゴリにクラスタリングするために使用される教師なし学習アルゴリズムです。プロトタイプ クラスタリングでは、各カテゴリは 1 つ以上のプロトタイプによって表されます。プロトタイプは、データ セット内のサンプルであるか、またはいくつかのルールに従って生成されます。プロトタイプ クラスタリングの目標は、サンプルとそれらが属するカテゴリのプロトタイプとの間の距離を最小限に抑えてクラスタリングを達成することです。一般的なプロトタイプのクラスタリング アルゴリズムには、K 平均法クラスタリングと混合ガウス モデルが含まれます。データ マイニング、パターン認識、画像処理などの分野で広く使用されているこれらのアルゴリズムの目標は、図に示すように、サンプルとクラスター中心間のコサイン類似度の負の対数尤度損失を最小限に抑えることとして定義されます。次の方程式。
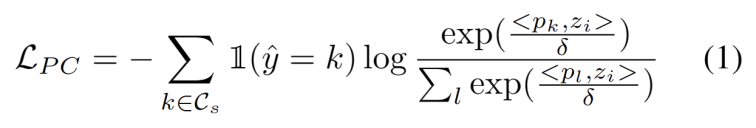 モデルの重みを調整することによる悪影響を回避するために、強力な OOD サンプルをフィルタリングして除外する、ハイパーパラメーターを使用しない方法を開発しました。具体的には、次の方程式に示すように、各テスト サンプルの強力な OOD スコア os を、ソース ドメイン プロトタイプとの最も高い類似性として定義します。
モデルの重みを調整することによる悪影響を回避するために、強力な OOD サンプルをフィルタリングして除外する、ハイパーパラメーターを使用しない方法を開発しました。具体的には、次の方程式に示すように、各テスト サンプルの強力な OOD スコア os を、ソース ドメイン プロトタイプとの最も高い類似性として定義します。 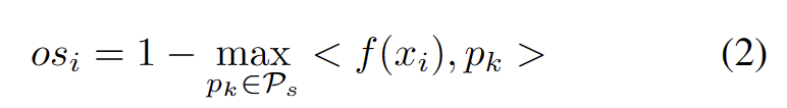
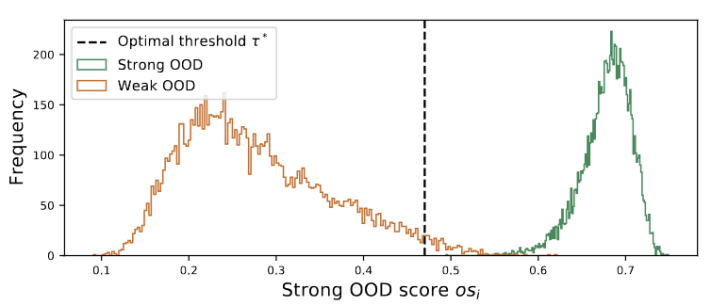
#外れ値は、図3に示すようにバイモーダル分布に従います。したがって、固定のしきい値を指定する代わりに、2 つの分布を分離する最良の値として最適しきい値を定義します。具体的には、この問題は外れ値を 2 つのクラスターに分割するものとして定式化でき、最適なしきい値は のクラスター内分散を最小化します。次の式の最適化は、0 から 1 までのすべての可能なしきい値を 0.01 刻みで徹底的に検索することで効率的に実現できます。
書き直す必要がある内容は次のとおりです: 動的プロトタイプ拡張機能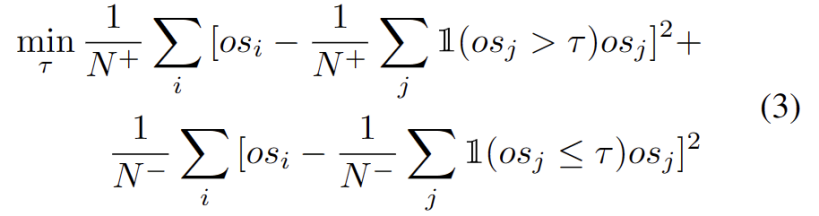
追加のハイパーパラメータを推定する困難を軽減するために、最初に、次のように、既存のソース ドメイン プロトタイプと強力な OOD プロトタイプに最も近い距離として、拡張された強力な OOD スコアを持つテスト サンプルを定義します。したがって、このしきい値を超えてサンプルをテストすると、新しいプロトタイプが構築されます。近くのテストサンプルを追加しないようにするために、このプロトタイプの拡張プロセスを段階的に繰り返します。
他の強力な OOD プロトタイプが特定されたので、テスト サンプルのプロトタイプを定義します。クラスタリングは、データセット内のサンプルを分類するための教師なし学習アルゴリズムであり、さまざまなカテゴリにクラスター化されます。プロトタイプ クラスタリングでは、各カテゴリは 1 つ以上のプロトタイプによって表されます。プロトタイプは、データ セット内のサンプルであるか、またはいくつかのルールに従って生成されます。プロトタイプ クラスタリングの目標は、サンプルとそれらが属するカテゴリのプロトタイプとの間の距離を最小限に抑えてクラスタリングを達成することです。一般的なプロトタイプのクラスタリング アルゴリズムには、K 平均法クラスタリングと混合ガウス モデルが含まれます。これらのアルゴリズムは、データマイニング、パターン認識、画像処理などの分野で広く使用されており、損失には 2 つの要素が考慮されます。まず、既知のクラスに分類されたテスト サンプルは、プロトタイプに近く、他のプロトタイプからは遠くに埋め込まれる必要があります。これが K クラス分類タスクを定義します。第 2 に、強力な OOD プロトタイプとして分類されたテスト サンプルは、K 1 クラス分類タスクを定義するソース ドメイン プロトタイプから遠く離れている必要があります。これらの目標を念頭に置いて、データセット内のサンプルを個別のカテゴリにクラスタリングするために使用される教師なし学習アルゴリズムであるクラスタリングのプロトタイプを作成しました。プロトタイプ クラスタリングでは、各カテゴリは 1 つ以上のプロトタイプによって表されます。プロトタイプは、データ セット内のサンプルであるか、またはいくつかのルールに従って生成されます。プロトタイプ クラスタリングの目標は、サンプルとそれらが属するカテゴリのプロトタイプとの間の距離を最小限に抑えてクラスタリングを達成することです。一般的なプロトタイプのクラスタリング アルゴリズムには、K 平均法クラスタリングと混合ガウス モデルが含まれます。これらのアルゴリズムはデータマイニング、パターン認識、画像処理などの分野で広く使われており、損失は次の式で定義されます。
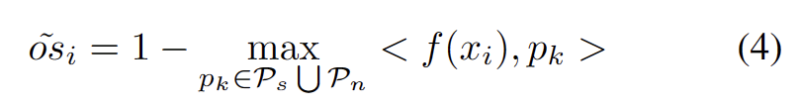
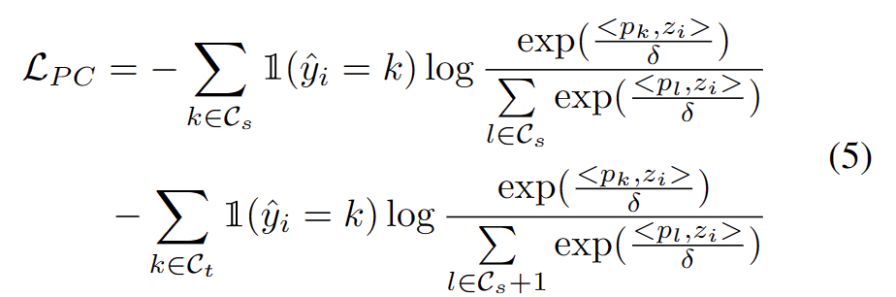
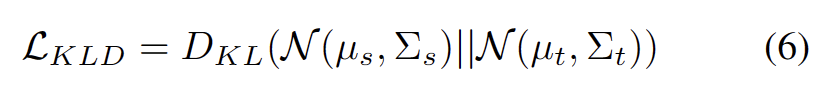
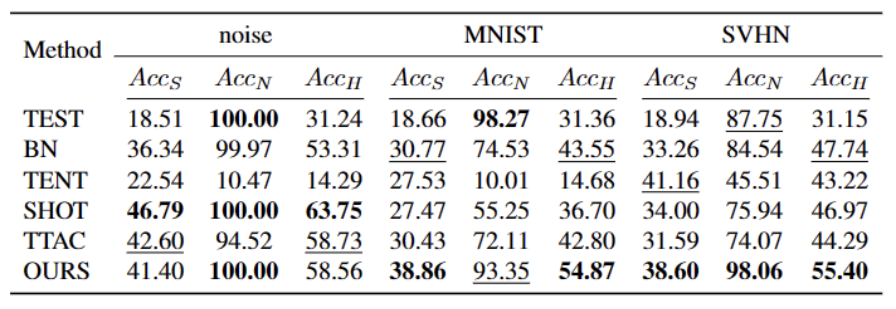
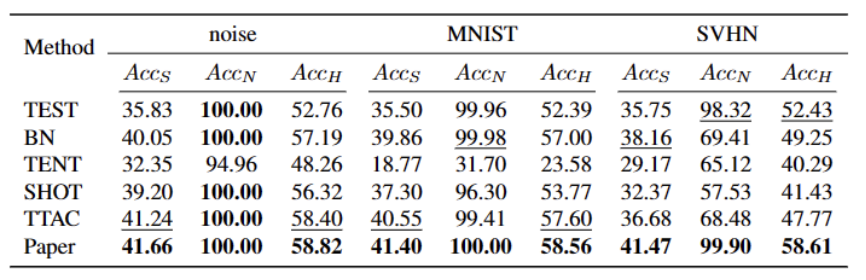
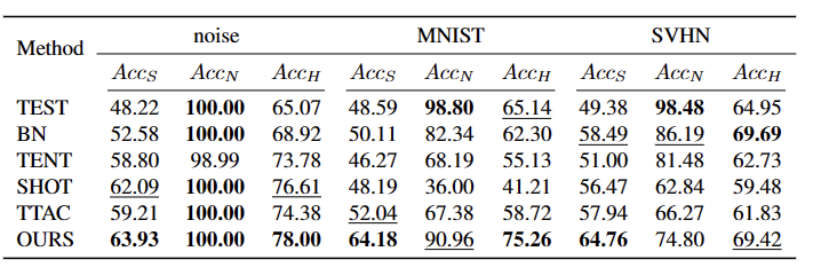
##5 つの異なる OWTTT ベンチマーク データセットで実験を実行しました。テストは次のとおりです。合成的に破損したデータセットやスタイルが異なるデータセットを含めて実行されました。実験では主に、弱OOD分類精度ACCS、強OOD分類精度ACCN、および2つのACCHの調和平均という3つの評価指標を使用します。 

参考文献:
[2] Yongyi Su、Xun Xu、および Kui Jia. 現実的再考テスト時トレーニング: アンカー クラスタリングによる逐次推論と適応、神経情報処理システムの進歩、2022.
[3] Tang Hui と Jia Kui。差別的な敵対的ドメイン適応。 In Proceedings of the AAAI Conference on Artificial Intelligence、volume 34、pages 5940-5947、2020
[4] 斉藤邦明、山本翔平、牛久義隆、原田達也 オープンセットドメインバックプロパゲーションによる適応。欧州コンピュータ ビジョン会議、2018.
[5] Brian Kulis と Michael I Jordan。 K 平均法の再考: ベイジアン ノンパラメトリック手法による新しいアルゴリズム。機械学習に関する国際会議にて、2012
以上がICCV 2023 Oral | オープンワールドでテスト セグメント トレーニングを実施するにはどうすればよいですか?動的なプロトタイプ展開に基づく自己トレーニング手法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。