
ホームページ >テクノロジー周辺機器 >AI >LIDAR 点群の自己教師あり事前トレーニング SOTA に使用されます!
LIDAR 点群の自己教師あり事前トレーニング SOTA に使用されます!

- 王林転載
- 2023-09-15 09:53:071494ブラウズ

論文のアイデア:
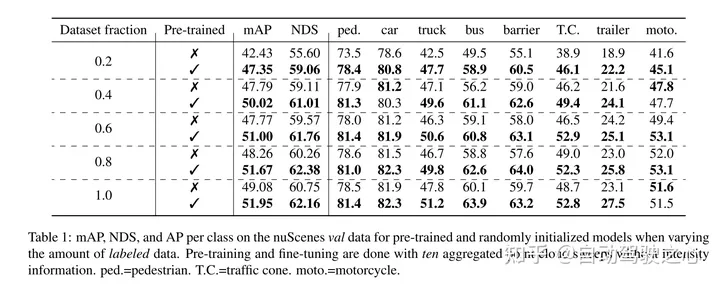
マスクされた自動エンコーディングは、テキスト、画像、そして最近では点群の Transformer モデルの事前トレーニング パラダイムとして成功しました。未加工の自動車データセットは、一般に 3D オブジェクト検出 (OD) などのタスクのアノテーションよりも収集コストが低いため、自己教師ありの事前トレーニングに適しています。ただし、点群用のマスクされたオートエンコーダーの開発は、合成データと屋内データのみに焦点を当ててきました。したがって、既存の方法では、その表現とモデルを、均一な点密度を備えた小さくて密な点群に調整しています。この研究では、自動車環境における点群のマスクされた自動エンコーディングを調査します。点群はまばらであり、その密度は同じシーン内の異なるオブジェクト間で大きく異なる可能性があります。この目的を達成するために、この論文では、ボクセル表現用に設計された単純なマスクされた自動エンコーディング事前トレーニング スキームである Voxel-MAE を提案します。この論文では、マスクされたボクセルを再構築し、空のボクセルと空でないボクセルを区別するために、Transformer ベースの 3D オブジェクト検出器バックボーンを事前にトレーニングします。私たちの方法では、困難な nuScenes データセット上で 3D OD パフォーマンスが 1.75 mAP および 1.05 NDS に向上しました。さらに、事前トレーニングに Voxel-MAE を使用することにより、ランダムな初期化を使用した同等のデータよりも優れたパフォーマンスを得るには、注釈付きデータが 40% のみ必要であることを示します。
主な貢献:
この論文は、Voxel-MAE (ボクセル化された点群上に MAE スタイルの自己教師あり事前トレーニングを展開する方法) を提案し、評価しました。大規模な自動車点群データセット nuScenes 上で。この記事の方法は、自動車用点群 Transformer バックボーンを使用した初の自己監視型事前トレーニング スキームです。
私たちはボクセル表現に合わせて手法を調整し、独自の再構成タスクのセットを使用してボクセル化された点群の特徴を捉えます。
この記事では、私たちの方法がデータ効率が高く、注釈付きデータの必要性が減少することを証明します。事前トレーニングを使用すると、この論文は、注釈付きデータの 40% のみを使用した場合、完全に教師ありのデータよりも優れたパフォーマンスを示しました。
さらに、この論文では、Voxel-MAE は、既存の自己教師あり手法と比較して、Transformer ベースの検出器のパフォーマンスが mAP で 1.75 パーセント ポイント、NDS で 1.05 パーセント ポイント向上することを発見しました。 2回。
ネットワーク設計:
この作業の目的は、MAE スタイルの事前トレーニングをボクセル化された点群に拡張することです。図 2 に示すように、中心的なアイデアは依然として、エンコーダーを使用して入力の部分的な観測から豊富な潜在表現を作成し、その後デコーダーを使用して元の入力を再構築することです。事前トレーニング後、エンコーダーは 3D オブジェクト検出器のバックボーンとして使用されます。ただし、画像と点群の間には基本的な違いがあるため、Voxel-MAE の効率的なトレーニングにはいくつかの修正が必要です。
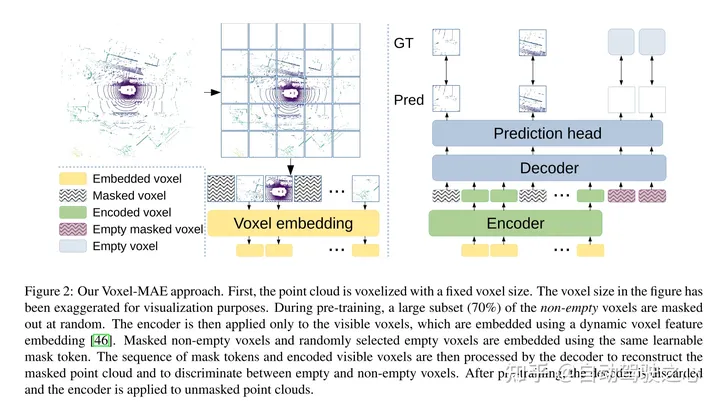
図 2: この記事の Voxel-MAE 法。まず、点群が固定のボクセル サイズでボクセル化されます。図内のボクセル サイズは、視覚化の目的で誇張されています。トレーニング前に、空ではないボクセルの大部分 (70%) がランダムにマスクされます。次に、エンコーダは可視ボクセルにのみ適用され、動的ボクセル特徴埋め込みを使用してこれらのボクセルを埋め込みます [46]。マスクされた空でないボクセルとランダムに選択された空のボクセルは、同じ学習可能なマスク トークンを使用して埋め込まれます。次に、デコーダはマスク トークンのシーケンスと可視ボクセルのエンコードされたシーケンスを処理して、マスクされた点群を再構築し、空のボクセルを空でないボクセルから区別します。事前トレーニング後、デコーダーは破棄され、エンコーダーがマスクされていない点群に適用されます。

図 1: MAE (左) は、画像を固定サイズの重複しないパッチに分割します。既存のマスクされた点モデリング手法 (中央) は、最遠点サンプリングと k 最近傍点を使用して、固定数の点群パッチを作成します。私たちの方法 (右) では、重複しないボクセルと動的ポイント数を使用します。 #########実験結果: ##################################### #
引用:
Hess G、Jaxing J、Svensson E、他。 LIDAR 点群での自己教師あり事前トレーニング用のマスクされたオートエンコーダ[C]//コンピューター ビジョンのアプリケーションに関する IEEE/CVF 冬季会議の議事録。 2023: 350-359.
以上がLIDAR 点群の自己教師あり事前トレーニング SOTA に使用されます!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。