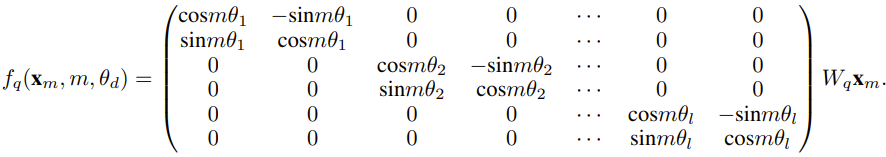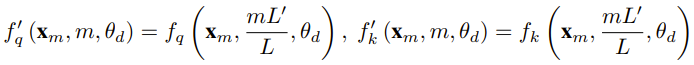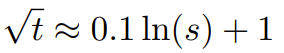Transformer ベースの大規模言語モデル (LLM) は、文脈学習 (ICL) を実行する強力な機能を実証しており、多くの自然言語処理 (NLP) タスクにとってほぼ唯一の選択肢となっています。 Transformer のセルフアテンション メカニズムにより、トレーニングを高度に並列化できるため、長いシーケンスを分散方式で処理できます。 LLM トレーニングに使用されるシーケンスの長さは、コンテキスト ウィンドウと呼ばれます。
Transformer のコンテキスト ウィンドウは、例を提供できるスペースの量を直接決定するため、ICL 機能が制限されます。 モデルのコンテキスト ウィンドウが限られている場合、ICL を実行するための堅牢なサンプルをモデルに提供する余地が少なくなります。さらに、モデルのコンテキスト ウィンドウが特に短い場合、要約などの他のタスクも大幅に妨げられます。 言語自体の性質の観点から、トークンの位置は効果的なモデリングにとって重要であり、セルフアテンションはその並列処理の位置により直接エンコードされません。情報。 Transformer アーキテクチャでは、この問題を解決するために位置エンコーディングを導入しています。 元の Transformer アーキテクチャでは絶対正弦波位置エンコーディングが使用されていましたが、これは後に学習可能な絶対位置エンコーディングに改良されました。それ以来、相対位置エンコード方式により、Transformer のパフォーマンスがさらに向上しました。現在、最も一般的な相対位置エンコーディングは、T5 Relative Bias、RoPE、XPos、および ALiBi です。 位置エンコーディングには、トレーニング中に表示されるコンテキスト ウィンドウに一般化できないという繰り返しの制限があります。 ALiBi などの一部のメソッドは、限定的な一般化を行う機能を備えていますが、事前にトレーニングされた長さよりも大幅に長いシーケンスに一般化できるメソッドはまだありません。 これらの制限を克服しようとする研究結果がいくつかあります。たとえば、一部の研究では、位置補間 (PI) を通じて RoPE をわずかに変更し、少量のデータを微調整してコンテキストの長さを延長することを提案しています。 2 か月前、Nous Research の Bowen Peng 氏が、高周波損失を組み込むことで「NTK を意識した補間」を実現するというソリューションを Reddit で共有しました。ここでの NTK は、ニューラル タンジェント カーネルを指します。 NTK 対応の拡張 RoPE は、微調整や複雑さに影響を与えることなく、LLaMA モデルのコンテキスト ウィンドウ (8k 以上) を大幅に拡張できると主張しています。また非常に小さい。 最近、彼と他の 3 人の共同研究者による関連論文が発表されました。
- 論文: https://arxiv.org/abs/2309.00071
- モデル: https: //github.com/jquesnelle/yarn
この論文では、NTK 対応の内挿に 2 つの改良を加えました。それぞれは異なる側面に焦点を当てています。
- 動的 NTK 補間方法は、微調整せずに事前トレーニングされたモデルに使用できます。
- 部分 NTK 内挿法。モデルは、少量の長いコンテキスト データで微調整すると最高のパフォーマンスを達成できます。
研究者は、この論文が生まれる前に、一部のオープン ソース モデルに NTK 対応補間と動的 NTK 補間を使用している研究者がすでに存在していたと述べました。 。例としては、Code Llama (NTK 対応補間を使用) や Qwen 7B (動的 NTK 補間を使用) などがあります。 この論文では、NTK を意識した補間、動的 NTK 補間、および部分 NTK 補間に関する以前の研究結果に基づいて、研究者は YaRN (Yet another RoPE extensioN メソッド) を提案しました。 Rotary Position Embeddings (RoPE) を使用してモデルのコンテキスト ウィンドウを効率的に拡張できる方法で、LLaMA、GPT-NeoX、および PaLM シリーズ モデルに使用できます。この調査では、YaRN は微調整に元のモデルの事前トレーニング データ サイズの約 0.1% である代表的なサンプルのみを使用することによって、現時点で最高のコンテキスト ウィンドウ拡張パフォーマンスを達成できることがわかりました。 Rotary Position Embeddings (RoPE) は、論文「RoFormer: Enhanced」で最初に発表されました。回転位置埋め込みトランス」が導入され、YaRN の基礎にもなりました。簡単に言うと、RoPE は次の形式で記述できます。 固定コンテキストで事前トレーニングされた LLM の場合length。位置補間 (PI) を使用してコンテキストの長さを拡張する場合、次のように表すことができます。 PI がすべての RoPE 次元を均等に拡張することがわかります。研究者らは、PI 論文で説明されている理論的な内挿限界では、RoPE と LLM の内部埋め込み間の複雑なダイナミクスを予測するには不十分であることを発見しました。読者が YaRN のさまざまな新しい手法を解決する背景、原因、理由を理解できるように、研究者によって発見され解決された PI の主な問題を以下に説明します。 情報エンコーディングの観点からのみ見る場合RoPE では、ニューラル タンジェント カーネル (NTK) 理論によれば、入力次元が低く、対応する埋め込みに高周波成分が欠けている場合、ディープ ニューラル ネットワークが高周波情報を学習することが困難になります。 RoPE の補間を埋め込むときに高周波情報が失われる問題を解決するために、Bowen Peng は上記 Reddit 投稿で NTK 対応補間を提案しました。このアプローチでは、RoPE の各次元を均等に拡張するのではなく、高周波数をより少なく拡張し、低周波数をより多く拡張することによって、補間圧力を複数の次元に分散します。 研究者らはテストで、このアプローチが未調整モデルのコンテキスト サイズのスケーリングにおいて PI よりも優れていることを発見しました。ただし、このアプローチには重大な欠点があります。これは単なる補間スキームではないため、一部の次元が一部の「外部」値に外挿されるため、NTK 対応補間を使用した微調整は PI ほど効果的ではありません。 #さらに、「外部」値が存在するため、理論的な拡張係数はコンテキスト拡張の真の程度を正確に表すことができません。実際には、特定のコンテキスト長拡張の場合、拡張値 s は、予想される拡張値よりわずかに大きく設定する必要があります。 #相対ローカル距離の損失 - 部分的な NTK 補間
#RoPE 埋め込みについては、興味深い観察結果があります。 : コンテキスト サイズ L が与えられると、波長 λ が事前トレーニング段階で見られる最大コンテキスト長より長い (λ > L) いくつかの次元 d が存在します。これは、回転ドメインが不均一。
PI および NTK 対応の内挿では、すべての RoPE 非表示ディメンションが平等に扱われます (ネットワーク上で同じ効果があるかのように)。しかし、研究者らは実験を通じて、インターネットでは一部の次元が他の次元とは異なる方法で扱われることを発見しました。前に述べたように、コンテキスト長 L が与えられると、一部の次元は L 以上の波長 λ を持ちます。隠れ次元の波長が L 以上の場合、すべての位置ペアが特定の距離をエンコードするため、研究者らは絶対的な位置情報が保持されると仮説を立てていますが、波長が短い場合、ネットワークは相対的な位置情報しか取得できません。位置の情報をお知らせします。
拡張率 s または基本変更値 b' を使用してすべての RoPE 寸法を引き伸ばすと、より少ない量で引き伸ばされるため、すべてのトークンは互いに近づきます。 2 つの回転ベクトルの内積は大きくなります。この拡張により、LLM の内部埋め込み間の小さなローカルな関係を理解する能力が著しく損なわれる可能性があります。研究者らは、この圧縮によりモデルが近くのトークンの位置順序について混乱し、それによってモデルの能力が損なわれるのではないかと仮説を立てました。
研究者らの観察に基づいて、この問題を解決するために、彼らは高周波次元をまったく補間しないことを選択しました。 β の次元はまったく内挿されない (常に外挿される) ことを提案しました。
このセクションで説明する技術を使用して、部分 NTK 補間と呼ばれる方法が誕生しました。この改良された方法は、以前の PI および NTK 対応の内挿方法よりも優れており、未調整モデルと微調整モデルの両方で機能します。この方法では、回転ドメインが不均一に分布している場合の次元の外挿が回避されるため、以前の方法の微調整の問題がすべて回避されます。 動的スケーリング - 動的 NTK 補間
RoPE 使用時に微調整せずにコンテキストを拡張します。内挿メソッドのサイズを変更する場合、拡張子が目的の値を超えたときにコンテキスト サイズ全体にわたって完全に劣化するのではなく、より長いコンテキスト サイズにわたってモデルがゆっくりと劣化するようにしたいと考えています。動的 NTK 方式では、範囲 s が動的に計算されます。 推論中にコンテキスト サイズを超えると、拡張度 s が動的に変更されるため、すべてのモデルが突然崩壊するのではなく、ゆっくりとトレーニング コンテキスト制限 L 劣化に到達します。 長距離の平均最小コサイン類似度を増やす - YaRN解決してもローカル距離前述の問題では、外挿を回避するために、しきい値 α でより大きな距離を補間する必要もあります。直感的には、これは問題ではないようです。グローバル距離ではトークンの位置を区別するのに高い精度は必要ありません (つまり、ネットワークはトークンがシーケンスの先頭、中間、または最後にあるかどうかを大まかに知る必要があるだけです)。 ただし、研究者らは、トークンの数が増加するにつれて平均最小距離が近づくため、アテンションのソフトマックス分布がよりシャープになることを発見しました(つまり、平均アテンションソフトマックスのエントロピーは減少します)。言い換えれば、長距離減衰の影響が補間によって軽減されるため、ネットワークはより多くのトークンに「より注意を払う」ことになります。この分布の変化は、LLM 出力の品質の低下につながる可能性があります。これは、前の質問とは関係のない別の問題です。 RoPE 埋め込みをより長いコンテキスト サイズに補間すると、アテンション ソフトマックス分布のエントロピーが減少するため、このエントロピーの減少を逆転させることを目指します (つまり、「温度」を高めることです)。注意ロジットの)。これは、ソフトマックスを適用する前に中間アテンション行列に温度 t > 1 を乗算することで実行できますが、RoPE 埋め込みは回転行列としてエンコードされるため、RoPE 埋め込みの長さを定数係数 √t で単純に拡張することができます。 。この「長さ拡張」技術により、アテンション コードを変更せずに研究が可能になり、既存のトレーニングおよび推論パイプラインとの統合が大幅に簡素化され、時間計算量はわずか O(1) になります。 この RoPE 補間スキームは RoPE の寸法を不均一に補間するため、膨張度 s に対して必要な温度スケール t の解析解を計算するのは困難です。 。幸いなことに、研究者らは実験を通じて、混乱の程度を最小限に抑えることで、すべての LLaMA モデルがほぼ同じ適合曲線に従うことを発見しました。 研究者らは LLaMA 7B に取り組みました。この式は次のとおりです。 13B、33B、65Bにあります。彼らは、この公式が、微妙な違いはあるものの、LLaMA 2 モデル (7B、13B、および 70B) でもうまく機能することを発見しました。これは、このエントロピー増加特性が共通であり、さまざまなモデルやトレーニング データに一般化されることを示唆しています。 この最後の修正により、YaRN メソッドが誕生しました。新しいメソッドは、推論コードを変更する必要がなく、微調整されたシナリオと調整されていないシナリオの両方で、以前のすべてのメソッドよりも優れたパフォーマンスを発揮します。最初に RoPE 埋め込みを生成するために使用されるアルゴリズムのみを変更する必要があります。 YaRN は非常にシンプルであるため、Flash Attendant 2 との互換性を含め、すべての推論およびトレーニング ライブラリに簡単に実装できます。 ##実験では、YaRN が LLM のコンテキスト ウィンドウを正常に拡張できることを示します。さらに、わずか 400 ステップのトレーニング後にこの結果を達成しました。これは、モデルの元のトレーニング前コーパスの約 0.1% であり、以前の研究から大幅に減少しました。これは、新しい方法が計算効率が高く、追加の推論コストがかからないことを示しています。
結果のモデルを評価するために、研究者らは長い文書の複雑さを計算し、既存のベンチマークでスコアを付けたところ、新しい方法が他のすべての方法よりも優れていることがわかりました。 。
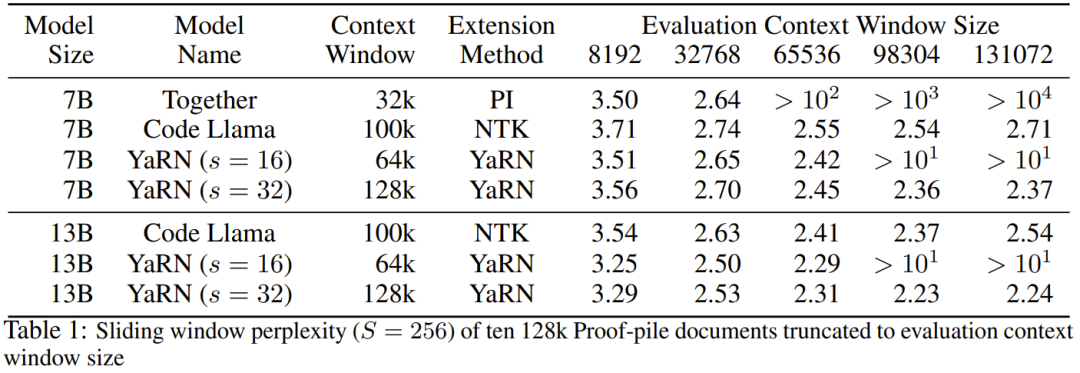
#まず、研究者らはコンテキスト ウィンドウが拡大されたときのモデルのパフォーマンスを評価しました。表 1 に実験結果をまとめます。
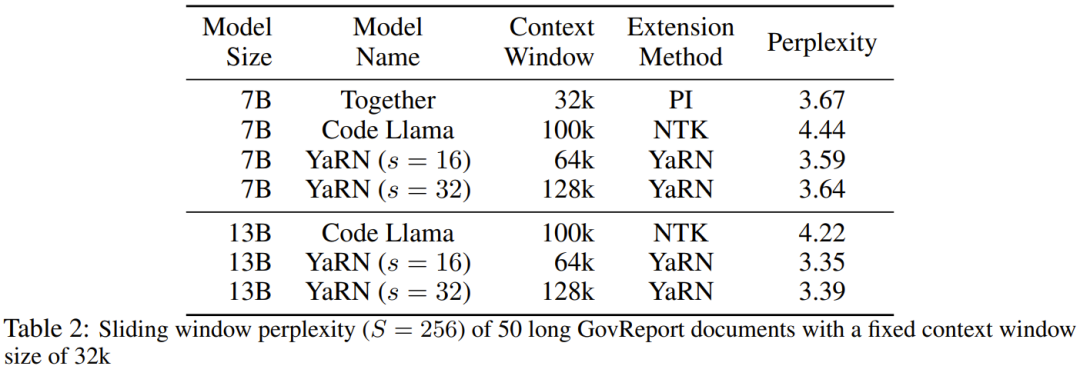
#表 2 は、50 の無検閲の GovReport 文書 (長さは少なくとも 16,000 トークン) に関する最終的な困惑を示しています。
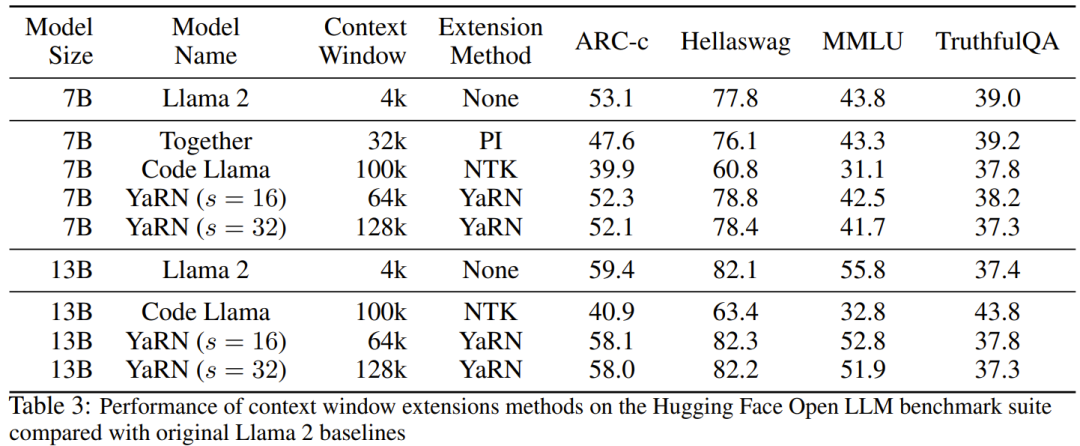
コンテキスト拡張を使用したときのモデルのパフォーマンスの低下をテストするために、研究者は Hugging Face Open LLM Leaderboard スイートを使用してモデルを評価し、LLaMA 2 ベースライン モデルと比較しました。 PI モデルと NTK 対応モデルの公開利用可能なスコアが比較されます。表 3 に実験結果をまとめます。
以上が大規模なモデルにプロンプトでより多くの例を学習させたい場合、この方法ではより多くの文字を入力できます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。